
Authors

There's a conversation happening in almost every boardroom right now. It goes something like this: we've invested in AI, built the infrastructure, hired the team. So why aren't the agents working? The answer is the data.
The Knowledge Your Agents Cannot Reach
Incomplete context produces results that look correct until someone acts on them. Your agents aren't failing loudly. They're failing quietly, on 80% of your organization's knowledge they were never given access to. (IDC,2024)
Your organization runs on PDFs, contracts, email threads, call recordings, scanned documents, slide decks, and spreadsheets. That's where your decisions live. That's where your institutional knowledge accumulates. That's where the context your agents need is locked.
Structured data in clean tables represents maybe 20% of what your organization actually knows. The rest sits in files your models cannot touch. Every Agentic pipeline running on that incomplete foundation produces incomplete answers.
This is the problem the industry has been quietly working around.
The Lakehouse Is the Right Foundation. Feed It Everything.
Databricks built the hard part. Delta tables, Unity Catalog, Databricks AI Search and Agent Bricks - combined they give enterprises a governed, scalable foundation for data and AI.
The opportunity is making sure everything your organization produces actually gets there. Databricks already parses documents natively, and if you've run ai_parse_document, you've seen what's possible: PDFs becoming queryable tables inside Unity Catalog. But parsing works on files that have already arrived, in a handful of formats. Most of your organization's knowledge hasn't made that trip. The 200-page contract from 1997 sits in SharePoint. The scanned invoice with a handwritten correction sits in an email thread. Last Tuesday's sales call sits in a recording platform. That content holds the decisions and context your agents need, and moving it into the Lakehouse in a form agents can use is where most enterprises get stuck.
Many teams try to close that gap themselves; custom parsers, extraction scripts, edge case handling, constant rebuilding every time a source system changes. It's solvable that way, but it's expensive, fragile, and pulls engineering focus away from building the things that matter. There's a more direct path.
Why One Pipeline Beats Four Tools
Making a PDF useful to an agent requires four things: accurate extraction of content, tables, and structure; intelligent chunking so the right pieces surface for the right queries; metadata enrichment so agents retrieve specific facts rather than just semantically similar text; and embedding so it lands in Databricks AI Search in a form agents can query.
Most tools handle one of those well.
Unstructured handles all four in a single pipeline pass, for 65+ file types, connected to the sources your organization already runs on: SharePoint, Object Storage, Confluence, Salesforce, Google Drive, email, and databases.
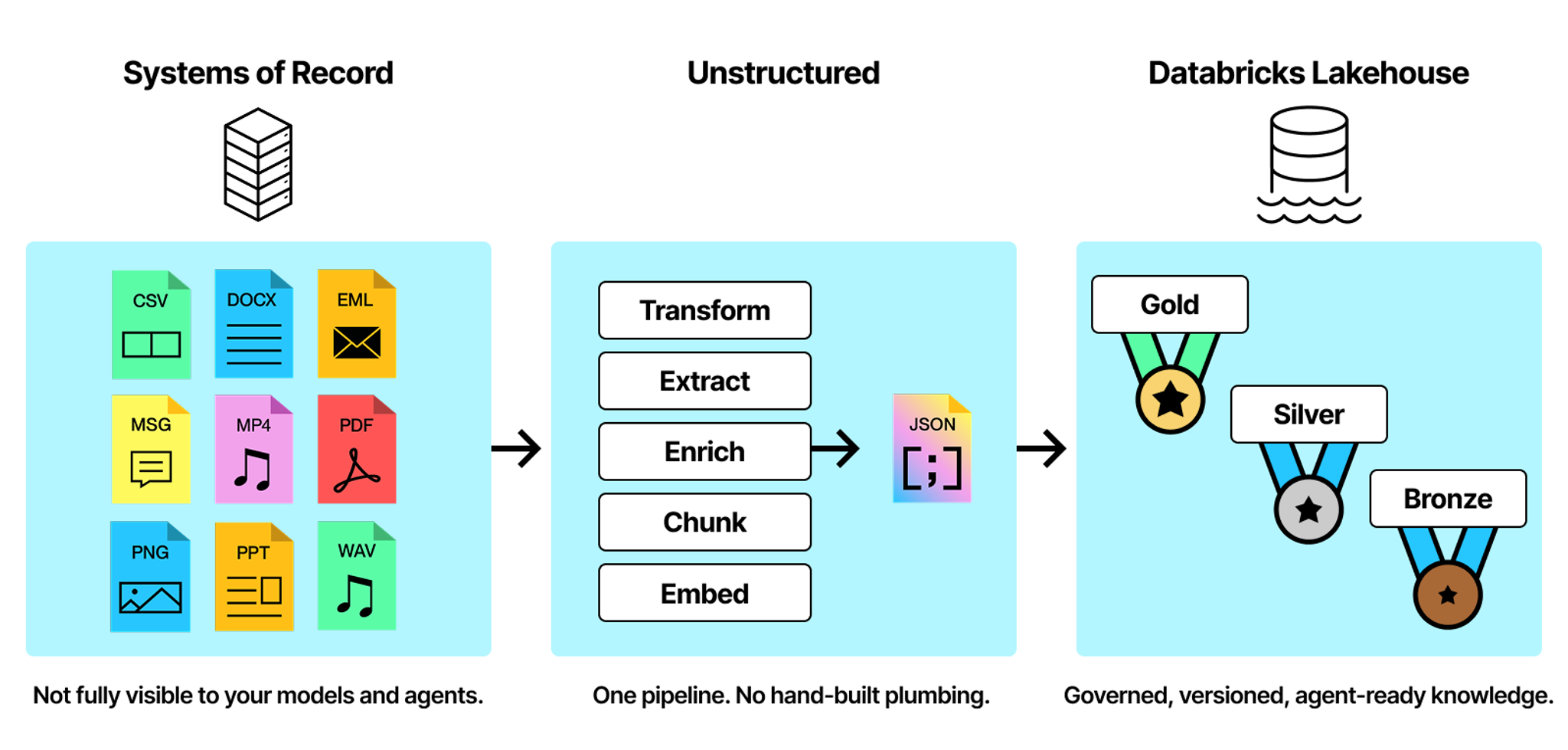
You can map Unstructured output to the medallion architecture the way you already run it. We write to whichever layer your pipeline needs - all governed in Unity Catalog from ingestion.
- Bronze holds the raw output; extracted elements, or the JSON key values from structured extraction that are ready for flattening - all kept as an auditable record of what was delivered.
- Silver is the transformed, enriched, chunked content that is model agnostic - ready for vectorization, or for distribution into the gold layer datamarts.
- Gold is the serving layer, and its shape depends on the use case. Agentic RAG gets embedded content synced to Databricks AI Search, ready for agents to query. Structured extraction gets a datamart your finance team or BI tools can access directly. That includes Iceberg tables where open format and interoperability matter. Iceberg isn't ready for RAG yet (no vector datatype support), but for extraction use cases it fits well.
Unstructured fits into your architecture rather than asking you to fit ours - wherever unstructured data you have that needs processing, that's the role we take.
The Governance Question Is the Right One to Ask
Beyond asking whether we can process Unstructured files, our most sophisticated buyers are asking: where does the data go, how do we audit it, and what happens when something breaks.
Unstructured deploys in the model that fits your security posture: SaaS, Hybrid SaaS, VPC, or bare metal. For private deployments, all traffic routes over PrivateLink. Nothing touches the public internet. SOC 2 Type 2, ISO 27001, HIPAA, FedRAMP, and GDPR compliances cover every stage of the pipeline.
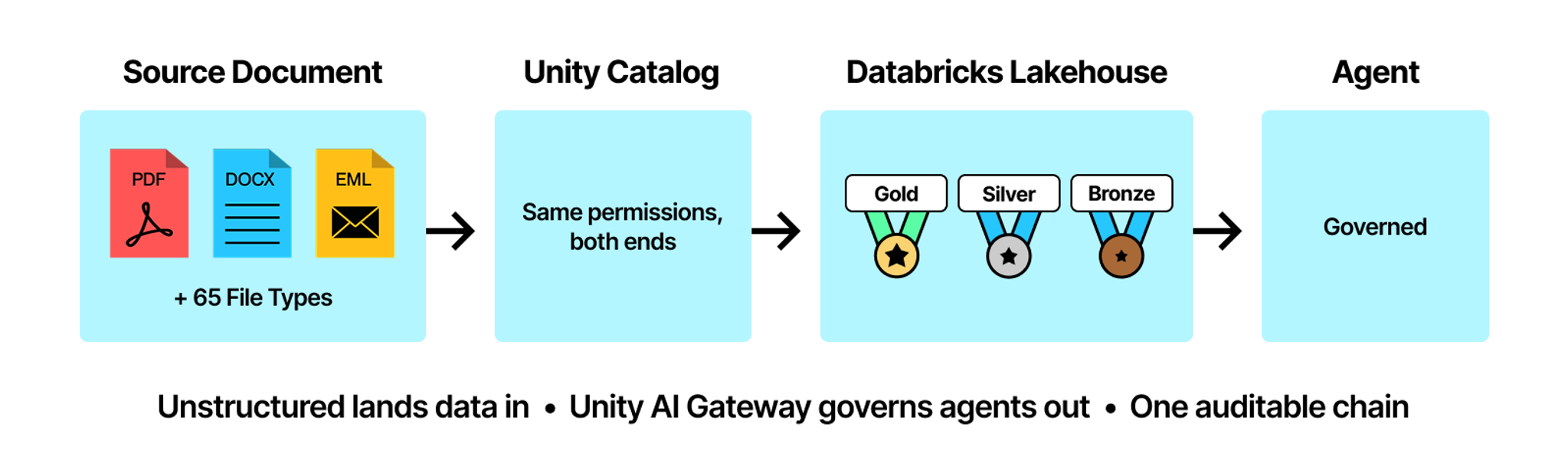
The deeper governance story is what happens inside Databricks. Because Unstructured writes into Unity Catalog, your unstructured data inherits the governance your team already built. There's no separate access control layer for documents, or parallel audit trails for ingested content. The governance model you trust extends automatically.
That governance needs to extend to your agents too beyond data. When Databricks introduced Unity AI Gateway earlier this year, bringing LLM governance, MCP control, and agent observability into Unity Catalog, it completed a chain that Unstructured starts. Unity AI Gateway governs agents out. Unity Catalog enforces the same permissions at both ends. One auditable path from raw document to production agent.
What Changes When You Get This Right
We talk to CDOs and VPs of AI who've invested heavily in their Databricks environment and are frustrated that AI initiatives keep stalling. The infrastructure is right, the talent is there, and the use cases are identified.
What's missing is the layer that connects the content your organization creates every day to the AI agents you're trying to put to work.
When that connection exists, things start moving. Data initiatives stop getting stuck because the information is finally accessible. Agents can work with the full context of your business i.e. policies, contracts, decisions, and institutional knowledge. Engineering teams spend more time building and less time stitching systems together. And from day one, every document is governed, versioned, and traceable.
You don’t have to disrupt what you've already built. Unstructured works alongside your existing infrastructure. The Databricks Lakehouse stays exactly as it is. Your agents finally get to use all of it.
The Practical Starting Point
If you're at Databricks Data + AI Summit June 15-18, bring us your messiest use case. If your data is spread across different systems and locked away in years-old scanned PDFs, you're dealing with the exact problem our platform was designed to address.
You've built the Lakehouse. Let's make sure your agents can read all of it.
Unstructured is the ETL+ platform for unstructured data. We help enterprises turn every document, email, and file into agent-ready knowledge in their Databricks Lakehouse, governed, versioned, and ready for production AI.


