
Authors

Most people think about training data as a volume problem: more data = better model. We used to as well. Then we tried combining two high quality document datasets to improve our layout detection model and watched performance drop across every metric we track. Detection quality slipped, table structure got worse, reading order regressed. We had more data than before, yet the model was performing worse.
What we found became the subject of our new paper on annotation inconsistency, the hidden problem that corrupts model finetuning even when your data looks perfectly fine. The solution we built is an agentic label harmonization workflow that reconciles how data is labeled across different sources before training ever begins.
The Problem
Initially, the loss converged normally, the metrics looked reasonable, and there was nothing in the training run that flagged something was wrong. But the issue was sitting in the data the whole time. Datasets that look compatible at the label level can still encode completely different assumptions about how things should be spatially annotated. Take paragraphs for example. One dataset annotated them as tight boxes aligned to the text but another one drew a coarse block that included all the surrounding whitespace. Same label but completely different spatial meaning. The same kind of discrepancy showed up across titles, tables, forms, captions, and list structures.
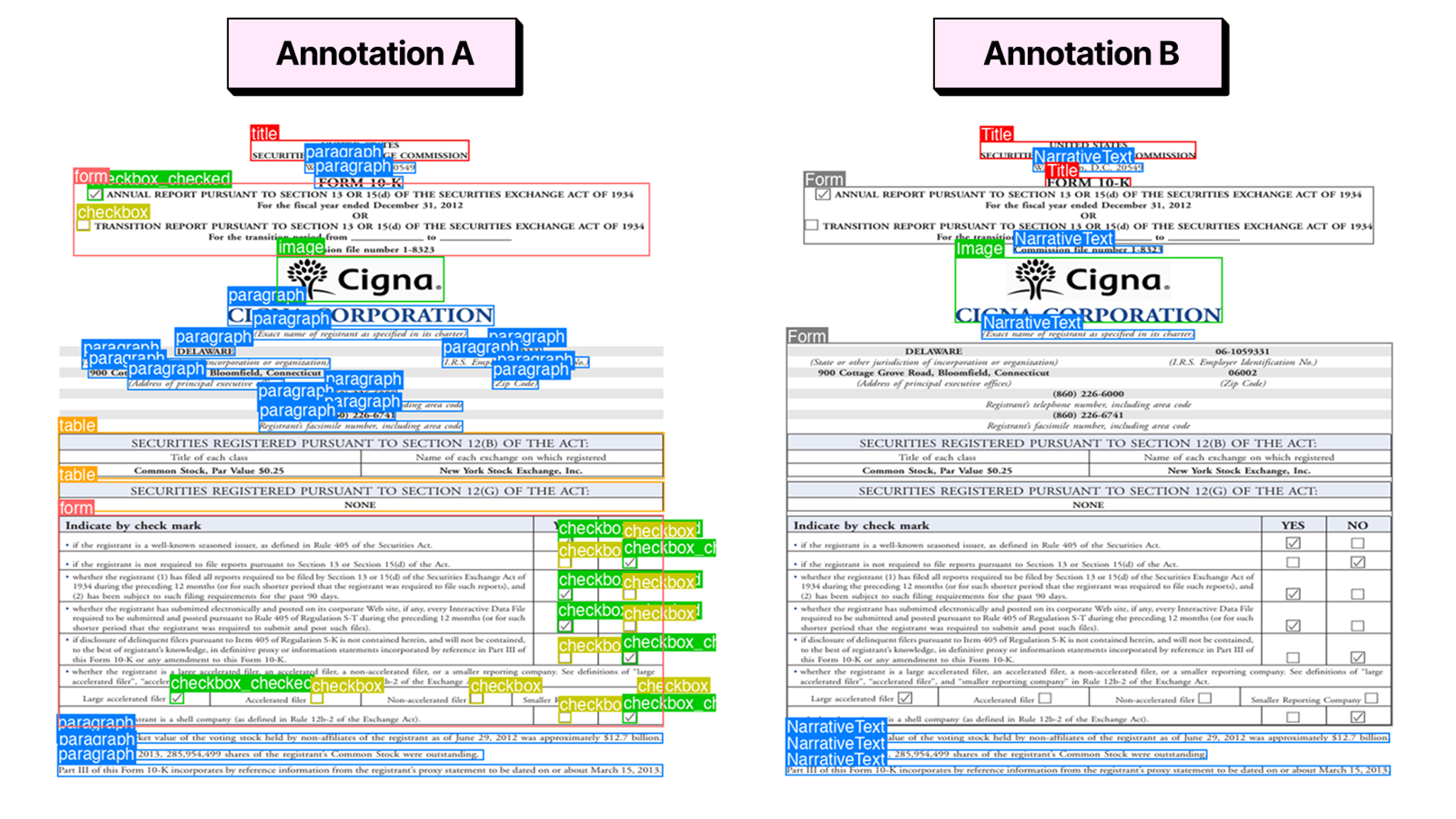
When you combine datasets like this, the model receives conflicting definitions of the same thing and has no way to resolve them. It just absorbs both as ground truth. The more it trains, the more confused it gets. That's what was happening to us.
What We Built
Most approaches assume the model will simply eventually learn to reconcile conflicting supervision on its own. Our experience showed it doesn't, it just absorbs both signals and becomes confused.
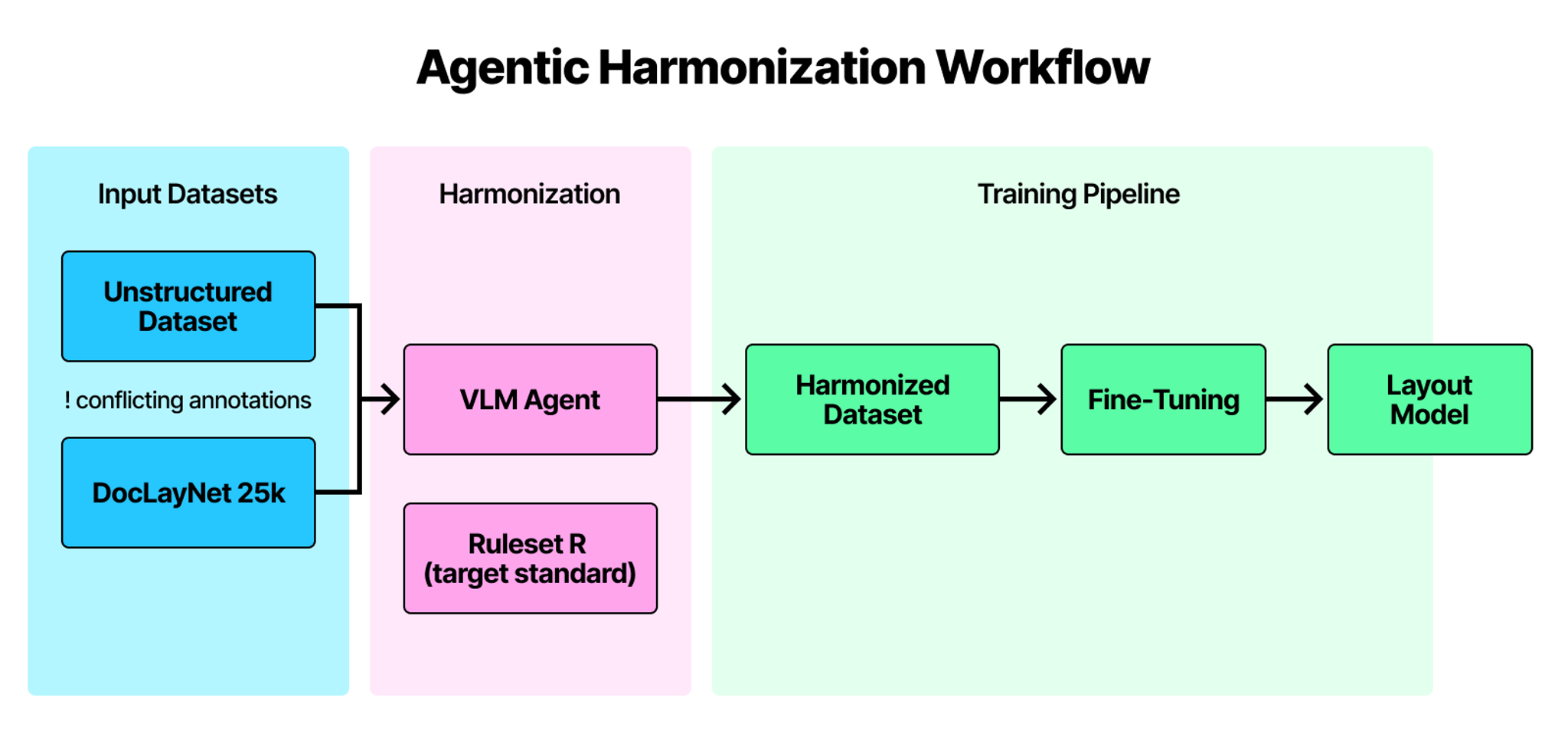
So we built agentic harmonization. Before any training begins, a VLM agent processes each document page alongside its existing annotations, looks at the actual visual layout, and reconciles everything to a single consistent standard. The agent can merge annotations that belong together, adjust boundaries that are misaligned, or reassign categories where needed. It cannot hallucinate new regions or discard existing ones. This gives us a training set where every annotation, regardless of which dataset it came from, speaks the same language.
Results
We ran all three models through SCORE-Bench, our open benchmark for end-to-end document parsing quality. The harmonized model came out ahead on 14 of 17 metrics. The harmonized model came out ahead on 14 of 17 metrics. More importantly, the naïve fine-tuning on the mixed dataset made things worse compared to the baseline we started with. Adding more data without fixing the annotation conflict actively degraded the model.
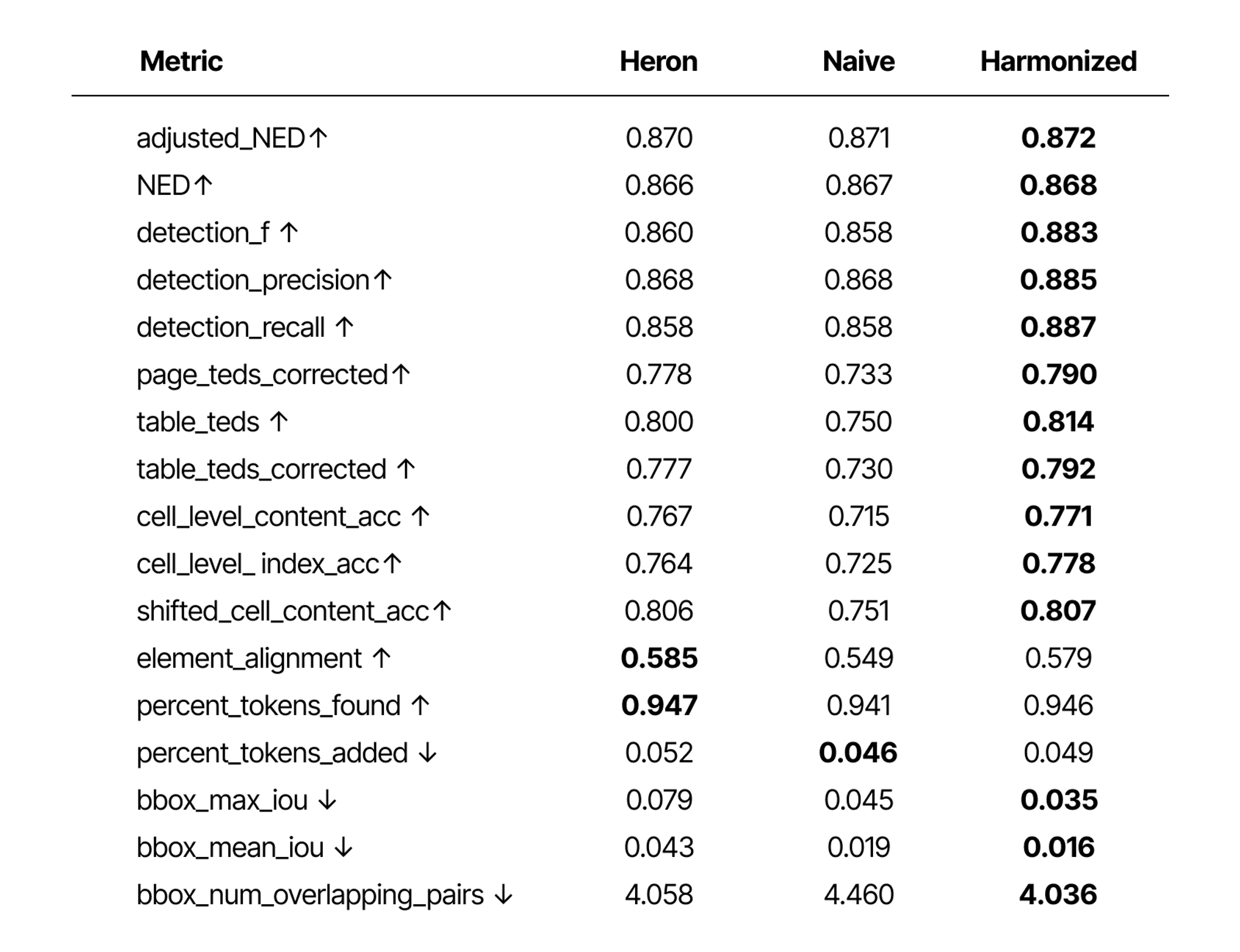
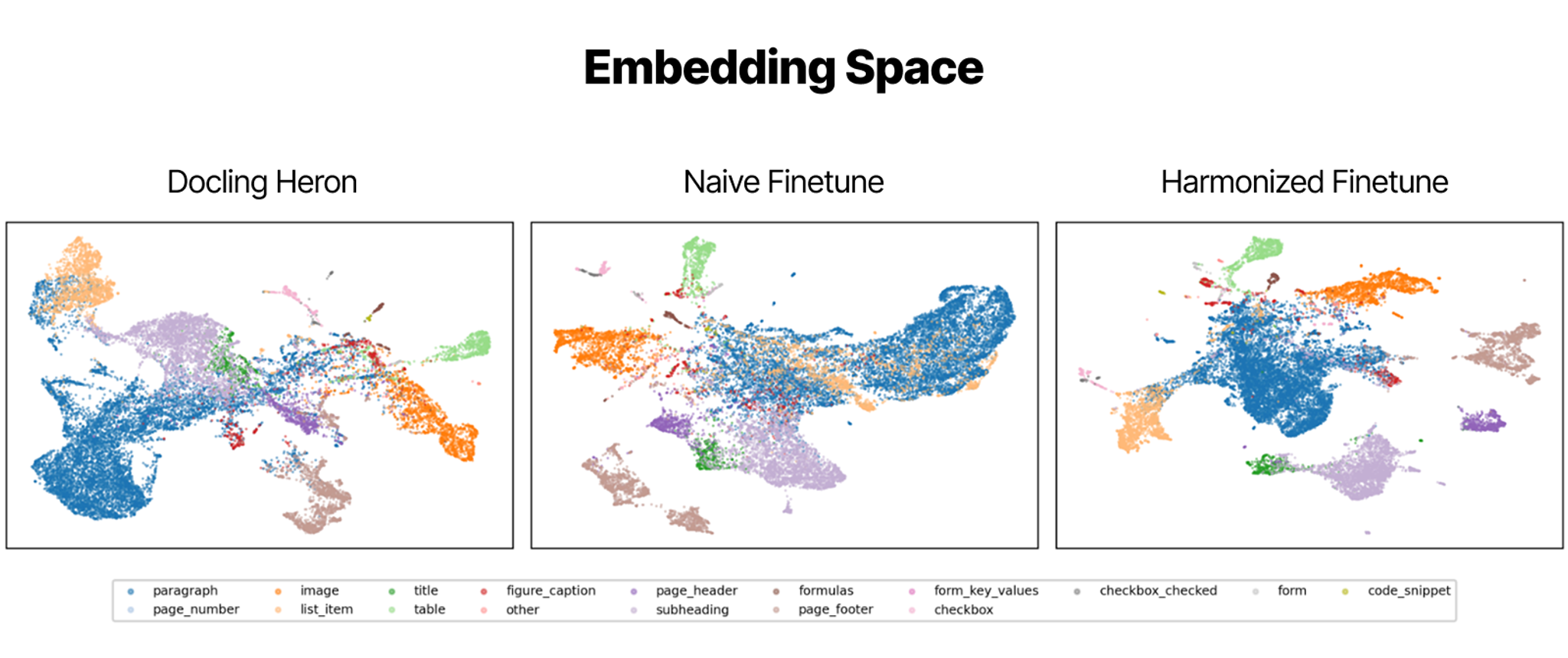
Table TEDS improved from 0.800 to 0.814, detection F-score from 0.860 to 0.883, and mean bounding box overlap dropped 2.6x from 0.043 to 0.016, all with zero changes to architecture, compute, or the training policies, just from a cleaner supervision signal. We also looked inside the model itself, visualizing the post-decoder embedding space across all three training regimes. After naïve fine-tuning, clusters became messier and categories bled into each other. After harmonization the picture was noticeably cleaner, tighter clusters and clearer separation between categories.
What This Means
Annotation inconsistency isn't specific to document AI or our particular datasets. Anyone combining independently curated sources for fine-tuning is likely dealing with some variation of this problem. The assumption that compatible label names mean compatible supervision is almost always wrong to some degree. Supervision consistency is a variable worth taking seriously before training starts. The quality of what a model learns is shaped not just by how much data you give it but by how coherently that data defines the things you're asking it to understand.

Read the full paper → https://arxiv.org/pdf/2604.11042


