
Authors

The Case for HTML as the Canonical Representation in Document AI
In the world of document AI, nearly every vendor defaults to JSON, plain text, or lightweight markdown as their output. We went with a different approach. We believe that—for enterprises that demand fidelity, reliability, and semantic richness: HTML is—and should be—the canonical layer of document representation.
Why HTML?
Our North Star is simple: “If you parse a document and delete the original source, would you still have all the information you could ever need in the parsed output?” With a high enough fidelity HTML, the answer is often yes.
1. Structural Fidelity That Matters
HTML captures and represents essential document elements—page numbers, headers, footers, multi-column or custom layouts, figures, captions, links—all with precision. These features don't just make documents look right—they power search, compliance, page-specific indexing, and audit trails.
2. Semantic Granularity
HTML encodes document meaning, not just presentation. It provides native elements and attributes for hierarchy and discrete sections (<section>, <article>, headings <h1>–<h6>), enabling a machine-derived outline rather than a lossy, visual approximation from which the form must be inferred.
Tabular semantics are first-class. Data tables distinguish header vs. data cells (<th>/<td>), support structural regions (<thead>, <tbody>, <tfoot>), captions (<caption>), and explicit header–data associations via scope, id, and headers—critical for complex, multi-level headers and accessibility.
Rich, typed blocks exist beyond prose. Figures and captions (<figure>, <figcaption>), time-typed content (<time>), citations (<cite>), and other semantic tags preserve function, not just formatting—supporting reliable downstream processing, application features, and audit.
Machine-readable annotations live in the markup. Microdata/RDFa allow entity- and relationship-level semantics directly in HTML, making content programmatically interpretable for search, compliance, and analytics.
3. Aligned with Vision-Language Models
VLMs have been trained on billions of HTML–visual pairings across the web. Their latent embedding spaces intuitively map visual structures to markup. By outputting HTML, you’re speaking the model’s native language—yielding higher accuracy and lower hallucination. In a sense, VLMs already think in HTML.
4. Enterprise-Ready Interoperability
HTML is a universal standard. It renders in any browser, chunks easily with CSS selectors or XPath, diffs cleanly in version control, and validates with DOM-aware tooling. It’s as human-friendly as it is machine-friendly.
5. Flexible, Not Rigid
Need a lighter-weight representation? HTML can be downscaled to Markdown with mature libraries in seconds. Going the other way—from Markdown back to full-fidelity HTML—is lossy and incomplete. Starting with HTML means fidelity without sacrificing flexibility.
A Diagram-Rich Document in Practice: From Pixels to Canonical HTML
To see the power of treating HTML as the canonical layer, consider a common but messy real-world case: a technical document page with a diagram.
This page might include:
- A title and subtitle in the header
- A diagram representing a decision flow
- A caption bound directly to the figure, not floating as unanchored text
- Footnotes explaining the diagram, linked back with
<sup>references - A page number tied to its source position for auditability
Source Document

Unstructured's HTML Representation:
<div class="Page" data-page-number="83">
<header class="Header">
<h1 class="Title">
Climate risk in the financial statements
</h1>
<h2 class="Subtitle">
8. Power purchase agreements
</h2>
<span class="PageNumber">
83
</span>
</header>
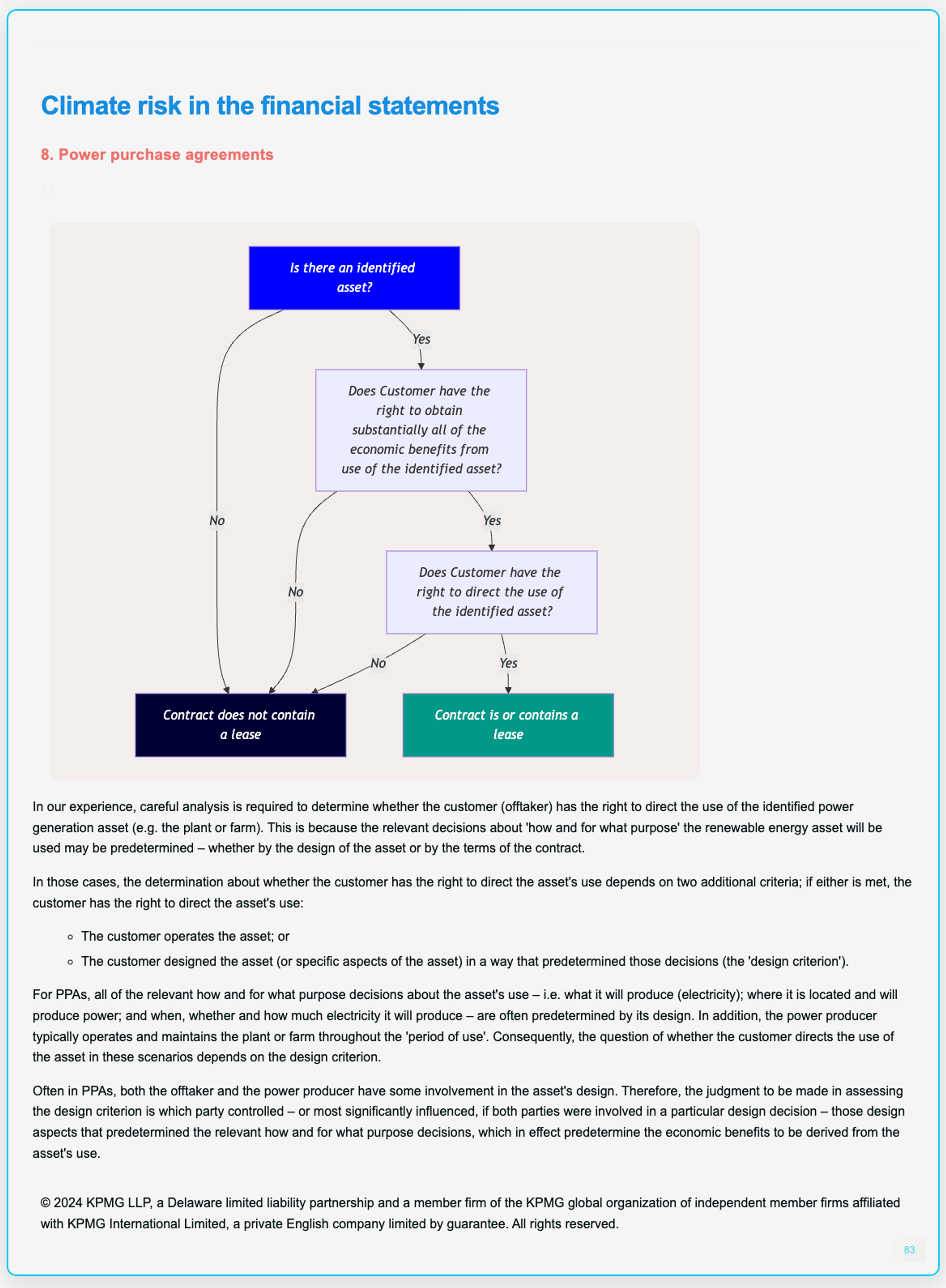
<figure class="Figure">
<pre class="mermaid">graph TD
A[Is there an identified asset?] -->|No| B[Contract does not contain a lease]
A -->|Yes| C[Does Customer have the right to obtain substantially all of the economic benefits from use of the identified asset?]
C -->|No| B
C -->|Yes| D[Does Customer have the right to direct the use of the identified asset?]
D -->|No| B
D -->|Yes| E[Contract is or contains a lease]
style A fill:#0000FF,color:#FFFFFF
style B fill:#000033,color:#FFFFFF
style E fill:#009988,color:#FFFFFF</pre>
</figure>
<p class="NarrativeText">
In our experience, careful analysis is required to determine whether the customer (offtaker) has the right to direct the use of the identified power generation asset (e.g. the plant or farm). This is because the relevant decisions about 'how and for what purpose' the renewable energy asset will be used may be predetermined – whether by the design of the asset or by the terms of the contract.
</p>
<p class="NarrativeText">
In those cases, the determination about whether the customer has the right to direct the asset's use depends on two additional criteria; if either is met, the customer has the right to direct the asset's use:
</p>
<ul class="UnorderedList">
<li class="ListItem">
The customer operates the asset; or
</li>
<li class="ListItem">
The customer designed the asset (or specific aspects of the asset) in a way that predetermined those decisions (the 'design criterion').
</li>
</ul>
<p class="NarrativeText">
For PPAs, all of the relevant how and for what purpose decisions about the asset's use – i.e. what it will produce (electricity); where it is located and will produce power; and when, whether and how much electricity it will produce – are often predetermined by its design. In addition, the power producer typically operates and maintains the plant or farm throughout the 'period of use'. Consequently, the question of whether the customer directs the use of the asset in these scenarios depends on the design criterion.
</p>
<p class="NarrativeText">
Often in PPAs, both the offtaker and the power producer have some involvement in the asset's design. Therefore, the judgment to be made in assessing the design criterion is which party controlled – or most significantly influenced, if both parties were involved in a particular design decision – those design aspects that predetermined the relevant how and for what purpose decisions, which in effect predetermine the economic benefits to be derived from the asset's use.
</p>
<footer class="Footer">
<p class="NarrativeText">
© 2024 KPMG LLP, a Delaware limited liability partnership and a member firm of the KPMG global organization of independent member firms affiliated with KPMG International Limited, a private English company limited by guarantee. All rights reserved.
</p>
</footer>
</div>Unstructured's HTML Representation, Rendered:
When rendered in a browser, as you can see above, this HTML output is clearly recognizable as a derivative of the original PDF page. The diagram comes alive instantly via a single <script> include for mermaid.js (via a CDN link), headers and footers retain their proper positions, page numbers stay anchored, and every list, caption, and figure is preserved as a first-class element.
The result isn’t just extracted text—it’s a complete, auditable, and visually faithful reconstruction of the source document. If the original file disappeared tomorrow, you’d still have all the information and the structure you need for compliance, retrieval, or automation.
That’s the essence of HTML as the canonical layer: no semantic information gets lost.
How Unstructured Elevates This Vision
A. Our 70-Element Ontology
We didn’t just pick HTML and stop there—we paired it with an expressive ontology covering 70 document elements, from paragraphs and captions to signatures, citations, and watermarks. That ensures structure isn’t just captured, it’s understood by interpreting it through the lens of a well defined ontology.
B. Multimodal Strategy, Page by Page
We don’t force every page through a VLM-heavy pipeline. Instead, our dynamic router evaluates each page and chooses the most efficient strategy:
- Rules-based extraction when digital layout is present — lightning-fast, single-digit millisecond processing.
- Object detection + OCR/VLM when structure must be reconstructed.
- Pure VLM → HTML when nuance and fidelity are paramount.
This tiered approach slashes compute, preserves quality, and scales seamlessly.
C. Grounded Outputs You Can Act On
Our HTML outputs with rich metadata enable:
- Precise chunking for RAG retrieval
- Anchorable spans for grounding prose back to visual elements
- Audit trails across every element, from tables to notes—critical for compliance and traceability
The Vision: Document AI Elevated
HTML is not simply another serialization choice. It is a representational super language that preserves both visual structure and semantic intent in a way that aligns with how modern models are trained and how enterprises must govern their information. By constraining it through our well-formulated document element ontology, we can guarantee that documents and essential page metadata are captured in a consistent, auditable form.
The evidence from years of large-scale evaluation is clear: when structural fidelity and semantic clarity are preserved at the document layer, downstream systems—from structured information extraction to retrieval-augmented generation—operate with greater accuracy, lower cost, and fewer blind spots.
This is why we’ve made a deliberate bet: treating HTML as the canonical representation is not just a technical convenience, but a principled foundation for the future of document AI.


