

Authors

Imagine a world where all of your organization’s unstructured data lies at your fingertips. A mere prompt and your LLM application unlocks deep insights from a labyrinth of documents, emails, and reports. This isn’t a distant sci-fi dream; the technology exists, but how do you get there?
In the heart of every modern organization lies unimaginably large troves of data, spread across data sources and formats. We're not just talking about well-structured databases or cleanly formatted CSVs. Unstructured and semi-structured data is vast and varied, encompassing everything from casually written emails to complex technical manuals.
Simply traversing this data is daunting enough, but how do you make it usable for LLMs? Over the past year the data science community has made progress maturing Retrieval Augmented Generation (RAG) architectures, which introduce a retriever module to query prompt-relevant data and provide that as context to an LLM. The challenge over the coming year will be productionizing these systems, ensuring that all of an enterprise's data is available to foundation models, while operating efficiently at scale. This is where new approaches to data ingestion and preprocessing are absolutely critical. Effectively preprocessing and structuring this data is essential not only for making it accessible to your foundation models, but dramatically impacting the efficacy of end-user applications for accelerating and enhancing workflows.
In this article, we unpack the core issues associated with data ingestion and preprocessing for LLMs and RAG architectures. We first outline key considerations for transforming your unstructured data into RAG-ready data. We then step through the design and functionality of enterprise-grade workflow orchestration, operating at scale. Finally, we discuss key features to consider for evaluating LLM preprocessing tooling and where Unstructured fits in.
“What does it mean to be RAG-ready”
To fully leverage LLMs, it's essential to convert unstructured and semi-structured documents into a format that is machine-readable and optimized for use with LLMs. First we need to extract the text from a file and convert it into a predefined, structured format with associated metadata. This constitutes the Transform stage. Transformation is not enough, though; making documents truly RAG-ready also involves Cleaning, Chunking, Summarizing, and Generating embeddings. In the following section, we'll detail each of these critical steps.
Transform
Extract. This step involves pulling a representation of the document's content out of the source document file. The complexity varies depending on the document type.
Partition. This entails breaking the document down into smaller, logical units by semantically meaningful context. Whereas some preprocessing solutions simply provide the extracted content as a "wall of text," we recommend classifying documents into the *smallest* possible logical units (which we call elements). Elements provide a solid, atomic-level foundation that we can use to prepare data for a range of machine learning use cases. We leverage them for fine-grained cleaning and chunking strategies. We also generate novel element-level metadata that’s useful for cleaning as well as retrieval.
Structure. This involves writing the partitioned results to a structured format like JSON, which enables more efficient manipulation by code in subsequent preprocessing stages. JSON also has the virtue of being human readable, facilitating manual inspection and analysis of the interim or final results. Critical for enterprise scale RAG is to render data into a common data schema, irrespective of the original file format (e.g. .docx, .xml, .xlx, .pdf, etc.)
Clean
Cleaning data involves removing unwanted content (like headers, footers, duplicative templates, or irrelevant sections) that is costly to process and store and increases the likelihood polluting context windows with unnecessary or irrelevant data. Historically, data scientists have had to hard code hundreds or thousands of regular expressions or integrate custom Python scripts into preprocessing pipelines to clean their data—a laborious approach prone to breaking if document layouts or file formats change. With Unstructured, data scientists can instead use element metadata to efficiently curate large text corpuses.
Chunk
Chunking refers to breaking down a document into segments. Often, chunking is done naively, dividing extracted "wall of text" by arbitrary character count to generate the segments or relying on natural delimiters such as period marks to chunk by sentence. At Unstructured, we favor using logical, contextual boundaries—a technique known as smart-chunking. Storing data in this fashion enhances the performance of RAG applications by allowing more relevant segments of data to be retrieved and passed as context to the LLM. This can be accomplished by using an LLM API or using Unstructured’s built-in tooling (which is more efficient and accurate). We will discuss this more later.

Summarize
Generating summaries of chunks has emerged as a powerful technique to improve the performance of Multi-Vector Retrieval systems, which use data distillation to improve retrieval and the full text in chunks for answer synthesis (for more detail, see this previous post). In such systems, summaries provide a condensed yet rich representation of the data that enable efficient matching of queries with the summarized content and the associated raw data. In the case of images and tables, as demonstrated in that post, summarization can also greatly improve discoverability and retrieved context.
Not all preprocessing systems can identify and individually extract document text, images, and tables to capitalize on this technique. But Unstructured can.
Generate Embeddings
This process involves using ML models to represent text as vector strings, known as embeddings, which are lists of floating point numbers that encode semantic information about the underlying data. Embeddings allow for text to be searched based on semantic similarity, not just keyword matching, and are central to many LLM applications.Developers need flexibility to experiment with various combinations of chunking techniques and embedding models to identify the combination best suited for specific tasks (considering factors like speed, data specialization, and language complexity). At Unstructured we support a number of embedding model hosts (including major services: Hugging Face, AWS Bedrock, and OpenAI), allowing users to specify their model and parameters, and let us handle the rest.
The Preprocessing Workflow
So far, we've discussed the journey of rendering a single file RAG-ready. In practice, developers want to unlock the ability to continuously preprocess an ever-changing and ever-growing repository of files. For these production use cases, developers require a robust preprocessing solution—a solution that systematically fetches all of their files from their various locations, ushers them through the document processing stages described above, and finally writes them to one or more destinations. The comprehensive sequence now looks like this: Connect (sources) → Transform → Clean/Curate → Chunk → Summarize → Generate Embeddings → Connect (destinations).
We've already discussed those middle steps. Now, let’s turn to the initial and final connection stages, which account for fetching source documents from upstream data sources and writing results to downstream locations.
Source Connectors. Organizations store files in dozens of locations, such as S3, Google Drive, SharePoint, Notion, and Confluence. Connectors are specialized components that connect to these sources and ingest documents into the preprocessing pipeline. They play a pivotal role in ensuring a smooth, continuous data flow by maintaining the state of ingested documents and processing many documents in parallel for high-volume datasets.
Enterprise-grade source connectors need to capture and embed source metadata elements so they can be leveraged within the preprocessing workflow or in the broader application it powers. For instance, a workflow might use version metadata to determine whether upstream sources have been updated since a previous run and require re-processing. Metadata like source url and document name allows an LLM to directly cite and link to sources in its response. Document creation date and last modified metadata also are helpful when filtering or searching for content from a document by name.
Additionally, these connectors must be resilient to interruptions, able to handle tens or hundreds of thousands of files, and designed to be computationally efficient. Finally, developers must plan for how to support these connectors once they’ve moved them into production. In some cases, community supported open source connectors will be adequate but in the majority of instances, developers prefer to have SLAs attached to these connectors to ensure minimal down time when connectors inevitably break.
Destination Connectors. At the other end of the workflow, destination connectors write RAG-ready document elements and their corresponding metadata to target storage systems or databases. A destination connector should explicitly handle all available metadata, ensuring it's indexed and available for searching and filtering in downstream applications. When writing to a vector database, the destination connector should also leverage available embeddings to enable semantic search across the data. As with source connectors, in most cases developers prefer that these connectors be maintained (and fixed) by a third party to minimize the risk of downtime when they inevitably break.
Orchestration. Beyond just connecting to sources and destinations, a preprocessing platform should also handle workflow orchestration, including automation, scheduling, scaling, logging, error handling, and more. Orchestration is particularly important when moving RAG prototypes to production settings. In most cases, organizations won’t rely on a single batch upload of data to a vector database; rather, as new files are created and existing ones updated the system automatically updates vector stores. Production RAG requires scheduling to routinely discover and process/reprocess net new data. Scalability is also an important consideration. A workflow may need to be capable of processing files in parallel to handle large repositories in a timely manner. Effective pipeline orchestration and scalability are fundamental for maintaining an up-to-date, efficient data preprocessing system that can adapt to the dynamic nature of enterprise raw data stores.
Unstructured's Unique Edge in the LLM Preprocessing Market
So far we have defined the key components of RAG-ready data and stepped through a high-level view of orchestrating data preprocessing at scale with workflows. Now, let’s dig into the features that matter most for LLM ingestion and preprocessing and how Unstructured stacks up.
Number of File Types Supported

This may seem obvious, but your preprocessing solution should support the full range of file types and document layouts your organization produces. While images and pdfs often share a single pattern, and the file level, for preprocessing, there's a world of other document types out there (EPUB, PPTX, HTML, XML, and DOCX, to name just a few). Without a comprehensive suite of file transformation pipelines, there will be gaps in content ingested and provided to your LLM-powered application. Thoughtful support also requires carefully considering the format of each file type at every stage of processing. For instance, an XML document has nested tags that can be leveraged to derive hierarchy, while a DOCX file has text styles like Headers that can be leveraged to infer element type/category (title, subtitle, etc). It’s critical that production grade preprocessing solutions render all of these file types and document layouts into a common file type with a consistent schema. Without it, developers will encounter incredibly costly and time intensive bottlenecks in their RAG architecture.
Low-Latency Pipelines
One solution often suggested for supporting varied file types is to simply convert them to images and pass them through a single pipeline. In addition to at-best, mediocre performance, a major downside to that approach is that it relies on expensive and slow model inference. When cost and speed matter, it’s important to incorporate low-latency pipelines. For extraction and preprocessing, Unstructured offers multiple pipelines that optimize speed and performance for a given file type. For example, our Fast Strategy is roughly 100x faster than leading image-to-text models.
Number of Element Types
Some preprocessing tools, such as Azure Document Intelligence, for certain file formats, are capable of classifying text at the document element level of analysis (e.g. body text). Unstructured is capable of doing this for all file types, more cheaply, and across a broader range of categories.
Generating document elements enables developers to group related elements (e.g., body text with a corresponding title). They also facilitate cleaning, where certain elements, like Header or Footer, may represent noise and be removed altogether. Conversely, in some circumstances, explicitly extracting, classifying, and preserving Header and Footer content may be essential to core information security requirements. Downstream, element types can also help power more advanced retrieval methods like "hybrid search" or metadata filtering by allowing the range of queried documents to be focused or expanded based on element types. Shown in the graph above, Unstructured detects and labels elements as one of thirty different categories. This provides users fine-grained classification of their content and, by extension, that much more control in all of the mentioned applications.
Reading Order Detection
Accounting for reading order in preprocessing is critical to generating coherent text chunks, and by extension, semantically meaningful embeddings. Incorrectly ordering text or failing to align text with relevant context undermines the performance of RAG systems. At Unstructured, we utilize a range of techniques–from machine learning models to RegExs–to ensure that data is extracted and rendered accurately.

Hierarchy
Files naturally include hierarchical information (e.g. Title, SubTitle, Body Text, etc.). Irrespective of whether hierarchical metadata is included in the file or inferred by our vision transformer models, we generate a consistent schema of document hierarchy metadata that we attach to each document element. For example, a developer could decide to group elements by hierarchy (which implies contextual relevance) for their chunking strategy. Additionally, they may leverage this metadata for retrieval, filtering on parent and child chunks.
Language Detection
Language Detection plays a particularly important role in extraction when we rely on OCR to pull characters from an image. At Unstructured, we rely on language detection in order to route processing to the proper OCR strategy. This approach significantly enhances the overall quality and accuracy of the extracted text.
We also provide a list of all languages detected at a per-element level, irrespective of file type, allowing users to index and query against this metadata in their end-application.
Element Coordinates and Predicted Bounding Boxes
Knowing where content occurs on a page is valuable information for cleaning and curation. Unstructured provides XY coordinates of this metadata per-element, creating additional options for enhanced retrieval consuming applications to process with atomic-level precision.
GPU and CPU Tiering
Support for CPU and GPU processing tiers is key to enabling effective balancing of performance, cost, and resource availability. GPUs offer powerful parallel processing capabilities that significantly accelerate especially image-processing tasks and may be required for certain computation-intensive processing solutions. However, this performance comes with higher costs and potential resource constraints (see recent GPU shortages). Meanwhile, a CPU tier, while generally slower, offers a more affordable and consistently available option for processing. This is crucial for businesses operating at scale, where cost-efficiency becomes paramount. At Unstructured, our fast and hi-resolution strategies are configurable and can be optimized to run on and fully leverage either CPU or GPU.
Image + Form + Table Extraction
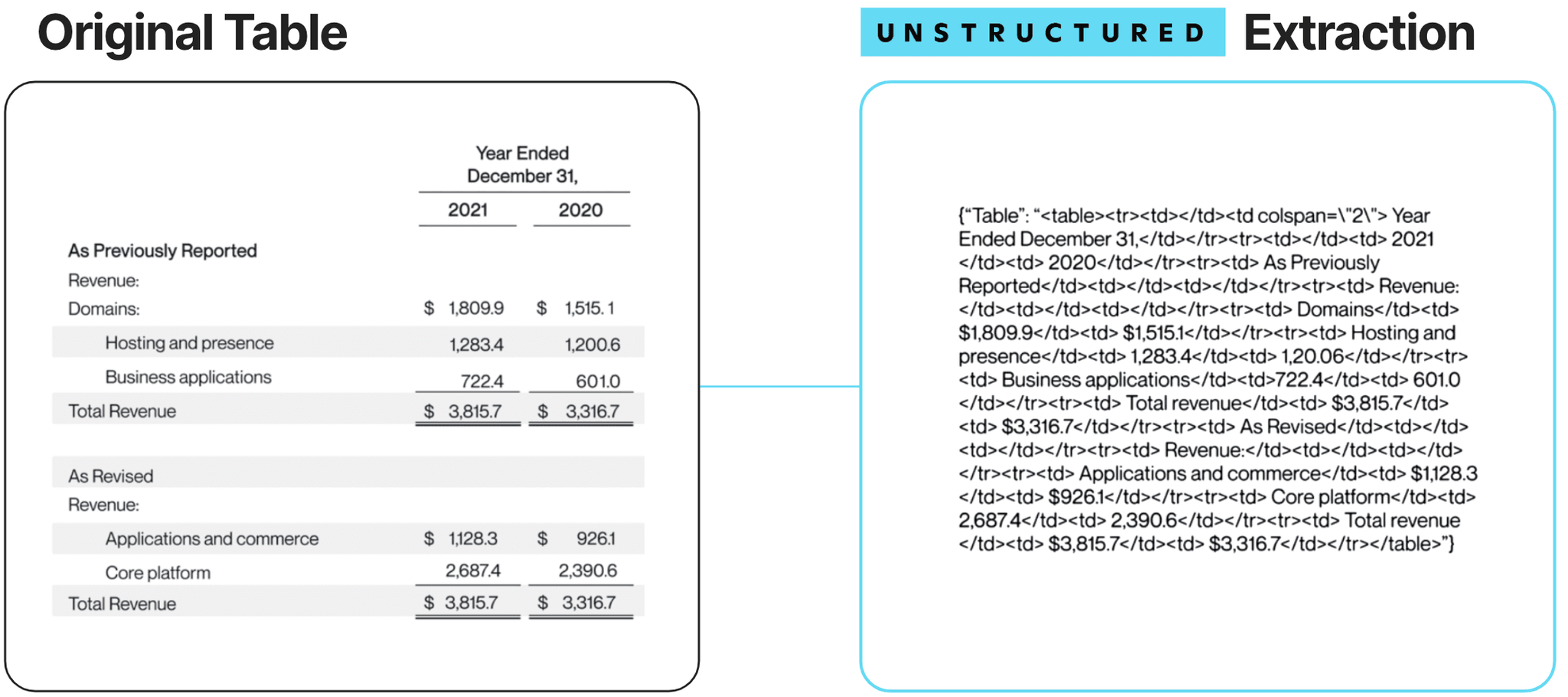
Text isn't the only content that might be in your documents. Extraction should also account for other elements like images and tables. Images may be extracted and encoded in results as byte data or written separately to external files. In either case, raw images may be retrieved and passed to a multimodal LLM for answer synthesis and/or may be summarized and leveraged for traditional text embedding and retrieval. Faithfully and accurately extracting and representing tables is incredibly challenging and a key point of failure when moving RAG prototypes into production. They often contain concentrated, high-value information otherwise scattered about or potentially missing from the text. Tables also range widely in complexity, where in extremes they have misaligned content, merged cells, and multi-level headers–making extraction non-trivial. At Unstructured we are focused on delivering state of the art performance for form and table extraction, irrespective of file type.
Smart-Chunking

Mentioned earlier, smart-chunking involves breaking a document down into logical units of contextually-linked content rather than naive and arbitrary character-count segments. Why does this matter? Smart chunking allows downstream applications to retrieve denser, more relevant content in response to queries and then feed that content to an LLM for synthesis, reducing computational cost and improving output accuracy.
At Unstructured, we're able to create smart chunks thanks to our atomic-level approach to element partitioning and the metadata we generate with it (element type, hierarchy, etc.). For example, our chunk_by_title strategy creates new chunks per Title element and groups the Title element with succeeding elements (related content for which the title describes). Because we combine content at an element-level, our chunks are always logically complete entities (no critical, missing content).
Scheduling/Workflow Automation
Unlike many other competitors in the market, Unstructured is not only a powerful tool for the core extraction and transformation of unstructured or semi-structured documents, it also hosts end to end capabilities to support full preprocessing workflows. Our open source library hosts our 25+ source connectors and 10 destination connectors. We package all of this in our Enterprise Platform (currently in private beta) which, via a no-code UI dashboard, allows users to create and manage workflow orchestration. It's a turnkey solution that supports horizontal scaling as well as scheduling, all entirely automated.
What We’ll Cover in Subsequent Posts:
- Caching and Vector Syncing
- Speech-to-text and Image-to-text
- PII Redaction
- SaaS vs On Prem
- And more…
Final Thoughts
LLM ingestion and preprocessing for RAG-architectures is complex and incredibly challenging in production settings. It involves not just converting files into RAG-ready formats but also requires orchestrating entire workflow automations to operate at scale.
Fortunately, Unstructured has already done the hard work for you. Even better, we have solutions to meet you wherever you are in your journey. If you're prototyping, try our open source Python library, our prebuilt containers, or give our free API a test drive. If you're headed for production and need a service to process your documents, sign up for the Azure/AWS Marketplace API or our hosted SaaS API. In addition to abstracting away the infrastructure management, these services also host enhanced models for precise table extraction, advanced chunking capabilities and document hierarchy detection, and early access to fresh features. If you're looking for these same features but in an end-to-end platform, that’s also available. Our Platform is currently in private beta, so just reach out. Regardless of where you are, we'd love to hear from you and connect. Chat with us directly in our community Slack or email us at hello@unstructured.io


