
Authors

This is the third post in our ongoing series on architecting for the agentic enterprise. Find earlier posts here:
Connecting autonomous agents to the enterprise data landscape creates a fundamental tension between the immense productivity opportunity and the profound risks to the enterprise. On one hand, data-connected agents promise to unlock unprecedented efficiencies and create new avenues for value creation. On the other hand, they introduce a dramatically expanded attack surface, creating significant risks of data leakage, compliance violations, and runaway operational costs. The enterprise architect’s primary role is to navigate this tension, building systems that capture the business upside while rigorously mitigating the potential downside.
The Canonical Two Data Provisioning Patterns
Before we can discuss how to connect enterprise data to an agentic application, it is necessary to understand a fundamental truth about an agent's core reasoning engine: in terms of functionality, a Large Language Model (LLM) is simply a static, stateless, token transformer; input tokens → {static, stateless model} → output tokens. The LLM possesses no inherent memory, no persistent knowledge of the enterprise, and no intrinsic understanding of a given task beyond the information it is provided at the moment of inference. All of the meaningful work an agent performs is dictated entirely by (1) the data assembled within its context window for each specific operation, in conjunction with (2) the static, universal knowledge embedded within the LLM itself during its pre-training.
What follows from that fact is that–from the broadest perspective–there exist only two canonical patterns for providing enterprise data to agents. The fundamental architectural decision is: Do you bring the knowledge on demand to the model, or do you embed the enterprise knowledge within the model itself? The first approach is called context engineering, short for context window engineering, whereas the latter option is called model fine-tuning, wherein the model’s parameters are effectively modified during an offline training process. Many large enterprises may ultimately leverage both approaches, though by far the most practical, prevalent, and secure approach is context engineering. Understanding these two high-level patterns and their trade-offs is important to informing sound architectural decisions when it comes to solutioning for different use cases, so we will discuss these distinctions from a high level below.
Pattern 1: Context Engineering — The Bridge Between Data Connectivity and Agentic Action
In terms of a formal definition:
Context engineering is the discipline within agentic systems engineering of intelligently orchestrating all the required contextual inputs—data, instructions, metadata, and tool interactions—within an LLM’s context window to optimize the model’s ability to perform its designated tasks effectively, securely, and efficiently.
This orchestration happens externally to the model, though in agentic systems, it is often guided by the LLM's own outputs in a recursive, continuous loop. While context engineering as a discipline is quickly developing into a unique, specialized field of expertise, it can be approximately conflated to the joint discipline of prompt engineering and data engineering. Context engineering overlaps with data engineering in that the former is highly concerned with assembling high-precision data into the context window, which requires data discovery, retrieval, & security—all areas of focus within data engineering.
Context engineering’s primary architectural advantage stems from the fact it enables the principle of separation of concerns. It keeps the agent's reasoning engine (the LLM) distinct from the enterprise's dynamic knowledge base. Instead of relying on static information baked into a model’s parameters, an agent "looks up" relevant, up-to-date information from enterprise data sources at inference time and uses that information as context to formulate its response. This separation is the key to achieving the data freshness, governability, and explainability that enterprises demand. It allows knowledge to be managed where it belongs—in the data layer, under the purview of existing governance tools—while the LLM is treated as a powerful but stateless reasoning component.
While context engineering is conceptually simple—often reduced to "assembling a prompt"—it has matured into a complex field. This complexity stems from the various sub-disciplines that have necessarily emerged in order to improve the effectiveness of agent behavior.
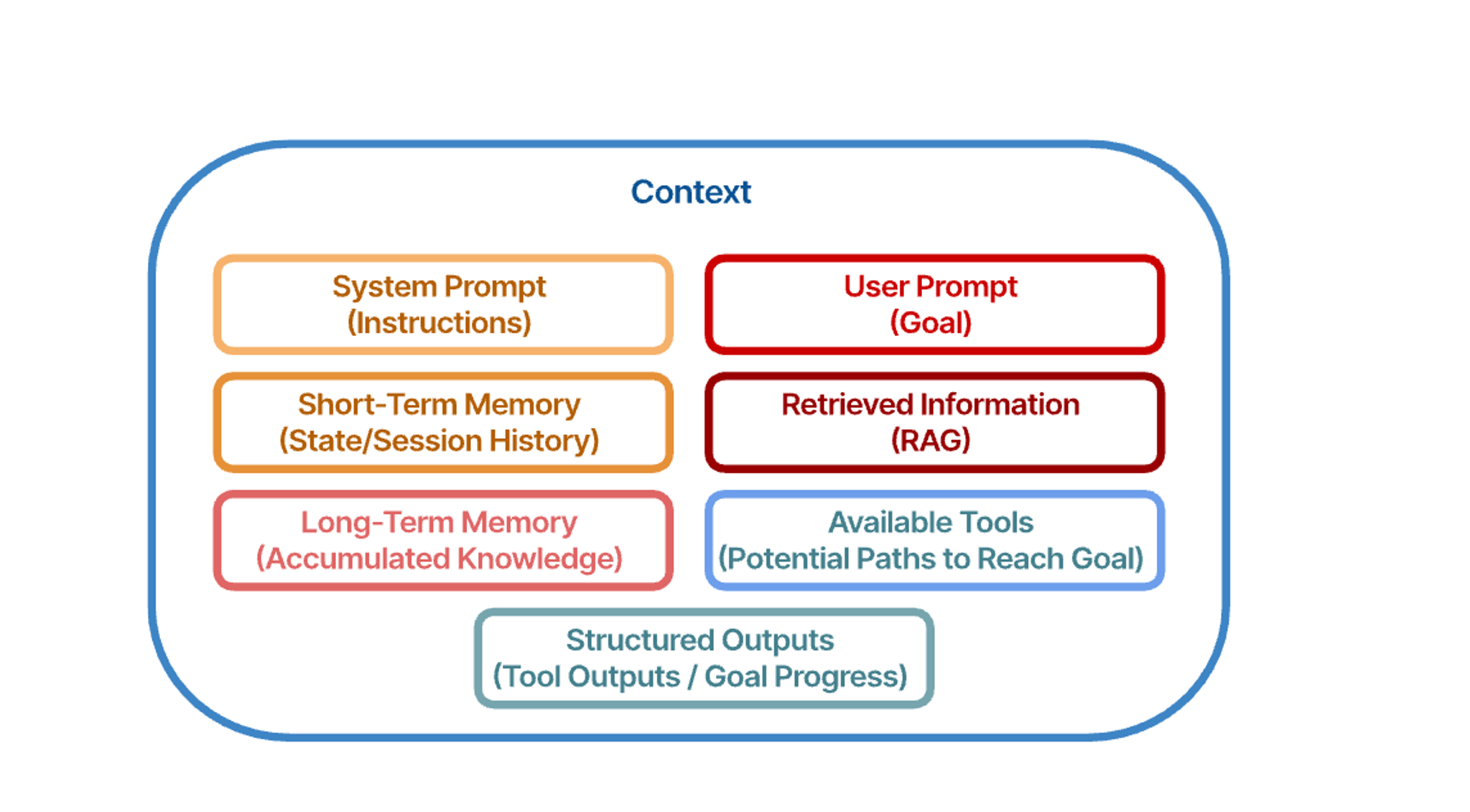
As illustrated in the figure above, the context window of an effective agentic system is a dynamic synthesis of several critical information sources. It is anchored by the System Prompt, which provides the core operational instructions, and the User Prompt, which defines the current objective. Situational awareness is maintained through Short-Term Memory, capturing the immediate session history and state. The agent's potential actions are represented by the Available Tools, outlining the paths it can take to achieve the goal. To ensure informed decision-making, this context is enriched with accumulated knowledge drawn from Long-Term Memory and dynamically Retrieved Information (e.g. via RAG). Finally, Structured Outputs from previous actions are included, enabling the agent to track its progress and plan subsequent steps iteratively. The careful orchestration of these elements is the essence of effective context engineering.
Given the intrinsic limitations of model fine-tuning, as will be discussed in the next section, and given that context engineering satisfies both data security and separation of concerns requirements, context engineering will be the right architectural choice for 95% of enterprise use cases. For that reason, after the next section covering model fine-tuning, the remainder of this blog post will focus exclusively on the different methodologies for providing data to agents within the context of context engineering.
Pattern 2: Fine-Tuning — Engineering Model Behavior and Base Knowledge
Fine-tuning takes the opposite approach from context engineering by embedding knowledge directly into the model's internal parameters through a process of supervised learning on a domain-specific dataset. While it is a powerful tool for teaching a model specialized knowledge in a hyper-specialized domain like medicine or coding, it is most often used to adapt an agent's behavior, style, or fluency in a specific format or jargon. Appropriate use cases include training a model on a company's marketing materials to adopt a corporate voice or on legal contracts to generate consistently formatted documents.
However, depending on the nature of the intended training data involved, this pattern can introduce significant and often unacceptable security and governance risks. The most critical flaw is the risk of sensitive information disclosure through model memorization, where a model inadvertently memorizes and later reproduces proprietary data it was trained on. Furthermore, the fine-tuning process can degrade a model's fundamental safety alignment. Research has shown that fine-tuning can dramatically reduce a model's resilience to attack; in one striking example, a model's safety score against prompt injection attacks plummeted from 0.95 to just 0.15 after being fine-tuned on a domain-specific dataset. This degradation makes the model more vulnerable to risks like Prompt Injection (LLM01), creating an opaque and difficult-to-govern asset that is antithetical to modern enterprise data management principles.
Given the high costs and risks of retraining an entire model, the industry has overwhelmingly shifted toward more practical methods. For architects, the decision landscape is generally ranked as follows:
- Parameter-Efficient Fine-Tuning (PEFT) with LoRA/QLoRA: This is the most popular and practical approach for most enterprise needs. Instead of retraining all parameters, LoRA (Low-Rank Adaptation) and QLoRA (Quantized Low-Rank Adaptation) freeze the base model and train only tiny, new "adapter" layers, representing less than 1% of the model's size. This drastically reduces cost and training time, often allowing a powerful model to be tuned on a single GPU. The output is a small, portable adapter file that can be loaded on demand.
- Use Case: This is the default choice for teaching a model a new skill, style (e.g., brand voice), or structured output format (e.g., JSON).
- Full Supervised Fine-Tuning (SFT): This traditional method updates all of the model's parameters. It remains the most powerful option for embedding deep, specialized domain knowledge but is also extremely expensive, requiring significant compute clusters and time.
- Use Case: Reserved for critical, high-stakes applications with large budgets and datasets, such as creating a base model for a specialized field like medicine or finance.
- Behavioral Alignment (DPO): This is a distinct type of fine-tuning focused on how a model behaves, not what it knows. Techniques like DPO (Direct Preference Optimization) are used after initial fine-tuning to make a model more helpful, harmless, and better at following rules.
- Use Case: Used to control a model's tone, improve its safety, or enforce specific conversational rules (e.g., "always provide three bullet points").
While this covers the most common enterprise approaches, other specialized methods like continued pre-training for deep domain adaptation or the more complex Reinforcement Learning from Human Feedback (RLHF) also exist, as well as others. Ultimately, fine-tuning is a powerful but specialized tool that is generally less preferred than context engineering for providing knowledge to agents. The core reasons boil down to cost prohibitiveness and practical architectural limitations. From the practical side of things, fine-tuning creates static knowledge that quickly becomes stale in domains where knowledge is evolving or accumulating. Also, another downside for many use cases is that the training process collapses source data access controls, which can lead to embedding potentially sensitive data directly into the model's weights with no mechanism to enforce proper access control governance. This is in stark contrast to context engineering, which keeps data in its governed, source-of-record systems, allowing for real-time updates and the enforcement of granular, identity-aware security policies at the moment of retrieval.
The Intersection of Context Engineering, Memory Engineering, and Data Engineering
To enable informed action, agentic systems require robust mechanisms for accessing and managing information.

The figure above illustrates a detailed mental model where Context Engineering is realized through the synthesis of Memory Engineering and MCP Tool Engineering. Memory Engineering defines the comprehensive architecture for information persistence and access within the agent, extending far beyond mere data storage. This includes Short-Term Memory for managing the immediate state and working context, and Shared Memory to facilitate multi-agent coordination. Crucially, it also encompasses Long-Term Memory (LTM), which houses not only the agent's Semantic (factual knowledge) and Episodic (past experiences) stores, but also its Procedural Memory—the repository of configurations, instructions, and learned skills that dictate how the agent operates. MCP Tool Engineering complements this by providing the mechanisms to act, compute, and access these memories. Specifically, the "Information Access & Management" tools utilize various RAG techniques and external APIs to dynamically retrieve information from both internal LTM and external sources, ensuring the agent's working memory is populated with the necessary data for informed action.
Deep Dive: Architectural Patterns for Context Engineering
Given the reality that context engineering has become the standard way to provide data to agents in the vast majority of use cases, this elevates context engineering to the central, motivating discipline that demands and shapes a strong agentic data architecture. This section details the specific data architectural patterns used to implement context engineering, tailored to the different categories of enterprise data.
To effectively engineer context that is grounded in enterprise data, an architect must first understand the landscape of data sources. Enterprise data is highly diverse and fragmented, but from a high level, it can be grouped into four distinct categories, each requiring a different approach:
- Unstructured Knowledge: The vast majority (80-90%) of enterprise information, including documents, presentations, emails, and wikis stored in systems like SharePoint, Confluence, and network drives. This data is rich in institutional knowledge but lacks a predefined data model.
- Structured Operational Data: The transactional backbone of the enterprise, residing in SQL databases, data warehouses, CRMs, and ERPs. This data is highly organized but requires precise querying to access.
- Connected Entity Data: Information where the relationships between entities or data points are as important as the data itself, such as organizational charts, product catalogs, or dependency maps, often modeled in knowledge graphs.
- Real-Time Event Data: Continuous streams of information from application logs, IoT sensors, or financial market tickers, typically flowing through platforms like Apache Kafka. This data enables proactive agentic behavior.
Regardless of the data source, several core principles guide the architect's work in context engineering:
- Precision and Relevance: The context window is a finite and expensive resource. The primary goal is to retrieve only the most relevant information, filtering out noise that can distract the model or lead to "context poisoning".
- Separation of Concerns: Keep the agent's reasoning engine (the LLM) distinct from the enterprise's dynamic knowledge and data sources. This is fundamental to security, governance, and maintainability.
- Identity-Awareness: The context provided to an agent must always respect the permissions of the user on whose behalf it is acting. The question of how much access an agent should be granted on behalf of the user is still a matter of debate, however. Also, given it is a semi-independent actor, should an agent possess its own identity, e.g. Agent IAM? This topic will be explored at length in Part III of this book. Until then, in short, as a principle, data access must be filtered at the retrieval stage by a deterministic system, not left to the discretion of an LLM.
- Auditability and Traceability: Every piece of information provided as context should be traceable to its source, enabling explainability and compliance.
As we illustrated earlier, modern context engineering involves orchestrating a wide array of components. However, a full exploration of each is beyond the scope of this blog. The topics of Memory Engineering (both short-term state and long-term persistence) and Prompt Engineering (including the governance of system prompts via an Asset Registry) are complex subjects in their own right, and we will cover them in detail in later blogs. This post instead focuses specifically on the architectural data patterns for connecting agents with data that is external to the immediate agentic system. This is the core of data connectivity: how to retrieve enterprise data from its various applications and systems of record. We will now explore the three primary methods for this: retrieval mechanisms for accessing data-at-rest (e.g., RAG, GraphRAG), tool integrations for interacting with live data and executing actions (e.g., MCP, API wrappers), and event-driven triggers for streaming data.
Retrieval from Unstructured Knowledge (RAG)
The most common pattern for context engineering is Retrieval-Augmented Generation (RAG). It is crucial to understand RAG not as a synonym for context engineering, but as a specific and powerful implementation pattern primarily used for retrieving information from unstructured data sources like documents, presentations, and wikis.
A canonical enterprise RAG pipeline consists of two distinct phases: an offline indexing phase for preparing knowledge and an online retrieval phase for answering queries:
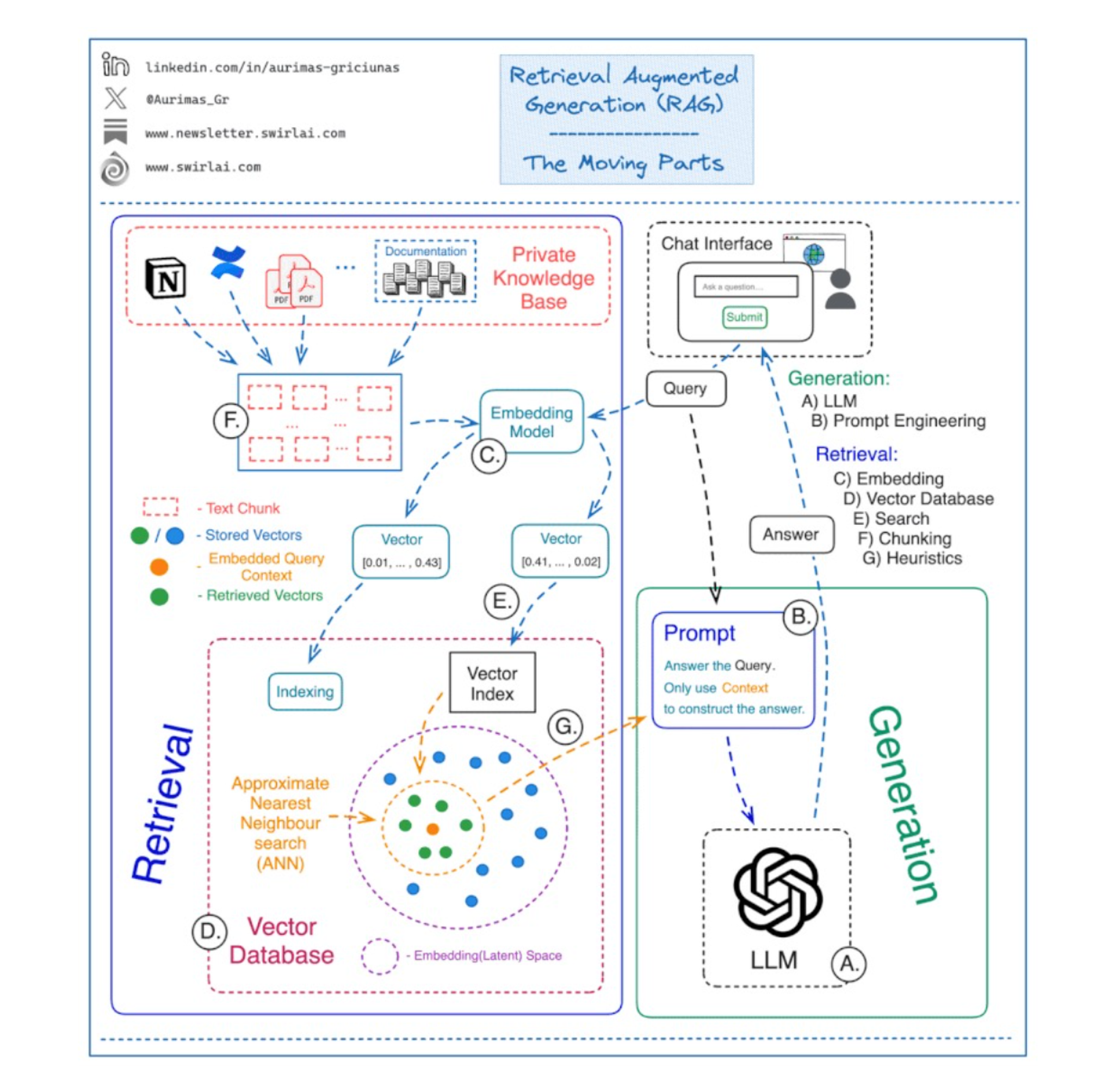
Offline Indexing Pipeline:
- The process begins with various Enterprise Data Sources (e.g., Confluence, SharePoint, S3 buckets).
- An Ingestion & Preprocessing Layer connects to these sources. This layer performs three key steps: Parsing (extracting text and structure), Cleaning (removing irrelevant artifacts), and Chunking (breaking documents into smaller, semantically coherent pieces).
- The processed chunks are then fed into an Embedding Model, which generates a numerical vector representation for each chunk.
- Finally, these embeddings are stored and indexed in a Vector Store (e.g., Pinecone, Weaviate, Redis) for an efficient similarity search.
Online Retrieval & Generation Pipeline:
- A User submits a query to the agentic application.
- The Retriever component takes the query and passes it through the same Embedding Model to create a query vector.
- It then performs a Similarity Search against the Vector Store to find the most relevant document chunks.
- The retrieved chunks are combined with the original query into an Augmented Prompt.
- This prompt is sent to the LLM, which generates a final, contextually grounded Response for the user.
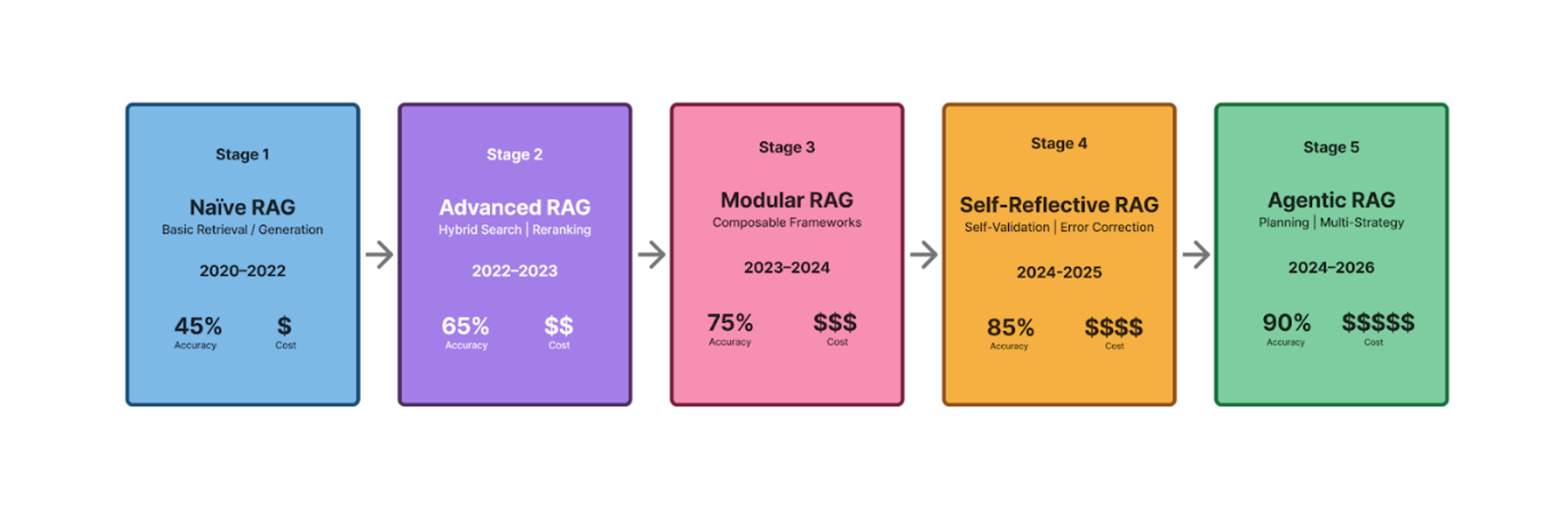
RAG has evolved significantly over the years, moving from simple retrieval-based approaches to sophisticated, multi-stage systems that reason and plan dynamically. Early implementations between 2020–2022 are now referred to as naïve RAG systems—straightforward pipelines that embedded documents, retrieved the top-k chunks, and concatenated them with a user query. These systems were elegant but brittle, often plagued by poor context alignment, which would result in model hallucinations during the generation step.
By 2022–2023, advanced RAG emerged, introducing hybrid retrieval strategies that combined dense and sparse search, reranking, and query expansion. These advances yielded measurable accuracy gains (up to 80%) but also introduced greater implementation complexity.
The next phase, modular RAG (2023–2024), was marked by the rise of frameworks like LangChain and LlamaIndex, which made RAG pipelines composable—but also parameter-heavy and difficult to optimize. This was followed in 2024 by self-reflective RAG, where systems began to evaluate and correct their own retrieval errors through feedback loops, improving multi-hop reasoning at the cost of higher compute demands.
Finally, today’s agentic RAG (2024–now) transcends static retrieval entirely. It incorporates reasoning, planning, and execution into multi-step research strategies, exemplified by systems like Microsoft’s GraphRAG and OpenAI’s agentic frameworks. These architectures treat retrieval not as a single step, but as part of a broader process of cognitive orchestration—where agents learn, reflect, and act upon information dynamically.
Ultimately, the single greatest challenge in building an enterprise RAG system is the "first mile" of the pipeline: ingesting and processing the vast and messy landscape of unstructured enterprise documents. Given the massive complexity of designing and maintaining a RAG system from scratch, compounded by how quickly it is evolving, a third-party platform approach is strongly recommended to solve this problem at scale. Solutions such as the Unstructured ETL+ platform are designed specifically for this challenge, providing broad connectivity to enterprise systems, intelligent transformation that preserves document structure, and advanced chunking strategies that maintain critical context.
Retrieval from Connected Data (GraphRAG)
A primary limitation of standard vector-based RAG is its inability to comprehend the relationships between pieces of information. It struggles with queries that require multi-hop reasoning or an understanding of a global knowledge structure. GraphRAG addresses this by using a knowledge graph as the retrieval backbone, modeling information as a network of entities and their relationships. This allows an agent to answer complex questions by traversing the graph, gathering a far more comprehensive and contextually rich set of information than a standard similarity search could provide. The figure below provides an example of such a scenario as compared to traditional RAG.
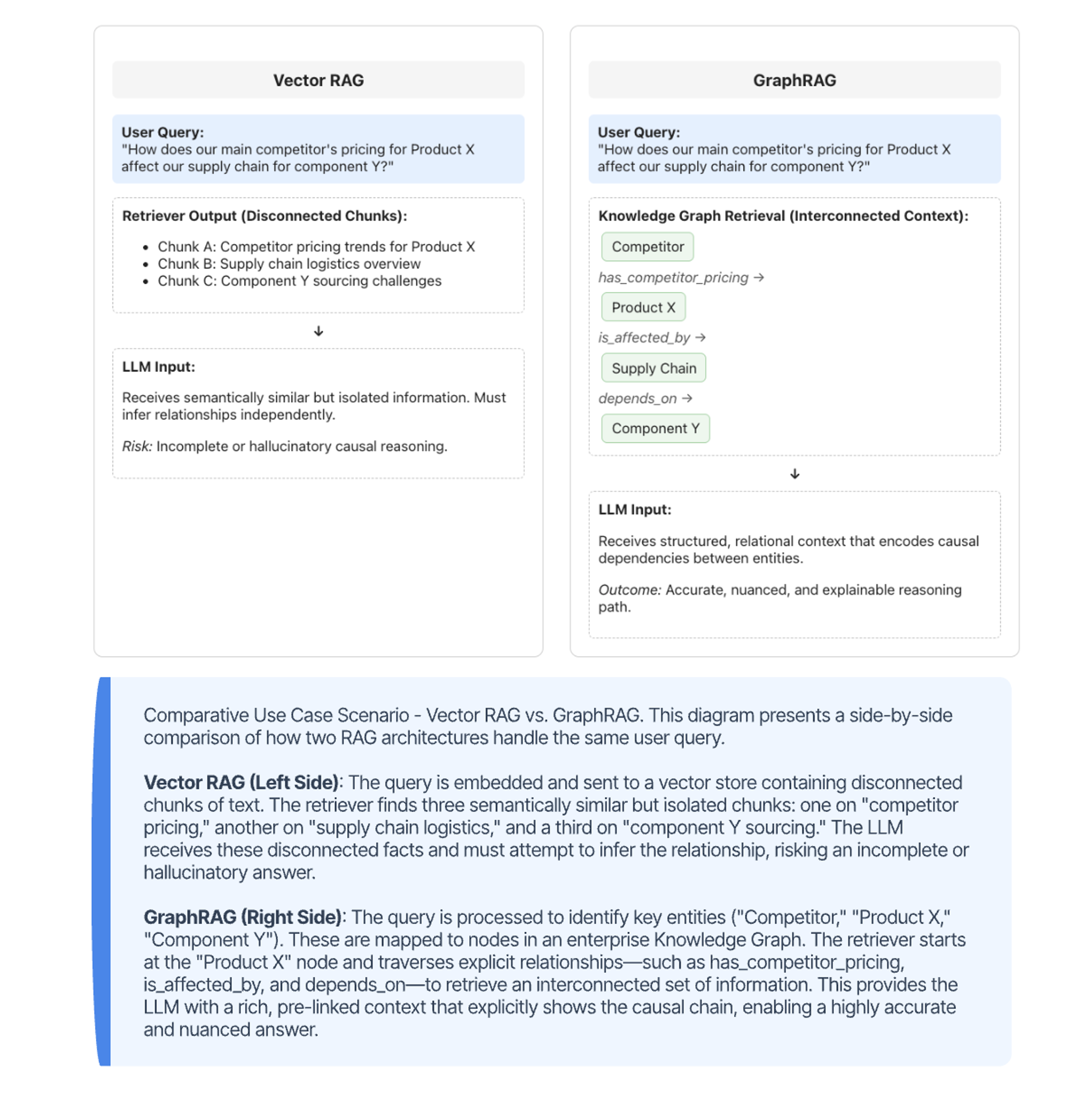
While GraphRAG introduces a powerful relational retrieval paradigm, it is not without trade-offs. Building and maintaining a knowledge graph requires significant upfront effort in schema design, entity extraction, entity resolution, and relationship curation— tasks that can be costly and brittle at enterprise scale. Unlike vector-based RAG, which can dynamically ingest and embed arbitrary unstructured content, GraphRAG relies on structured representations that must be kept synchronized with source data. This makes it less adaptive to fast-changing or high-volume document streams. Moreover, its performance depends heavily on graph completeness and edge quality: missing or incorrect relationships can mislead the retrieval process as much as missing embeddings can in vector search. For these reasons, GraphRAG is often used as a complementary layer rather than a replacement — combining graph-based reasoning for relational understanding with vector retrieval for semantic breadth, achieving a balance between precision and coverage.
Retrieval from Structured Data (Agentic Text-to-SQL/NoSQL)
Retrieving information from structured data systems like enterprise data warehouses introduces a distinct challenge: the model must understand the structure of the data itself before it can query it intelligently. Unlike unstructured retrieval, where semantic similarity is enough, Text-to-SQL and Text-to-NoSQL depend on precise awareness of table names, column types, and relationships. Without this context, even the most capable model will fail.
In practice, this means large amounts of schema context must be supplied to the agent — including table and column definitions, key relationships, data types, and sometimes even example rows. Many production systems expose this information through a metadata catalog or knowledge graph that indexes database documentation, lineage, and business definitions. The agent retrieves just the relevant subset of this schema context for the user’s query before attempting to generate code.
Modern implementations use an agentic, iterative workflow rather than a single LLM call:
- Context Retrieval: The agent first gathers schema-level metadata, constraints, and table relationships, often by querying a metadata store or graph.
- Query Generation: Using that context, it constructs a dialect-specific SQL or NoSQL query designed to answer the natural language prompt.
- Execution and Self-Correction: The query is executed in a controlled environment. If an error occurs, the agent analyzes the error message, retrieves missing context if necessary, and refines the query in subsequent attempts until it runs successfully.
This iterative, self-correcting loop has proven far more reliable than static query generation, with leading systems achieving strong execution accuracy on benchmarks like Spider and BIRD. However, real-world deployments remain constrained by practical issues: keeping schema metadata current, handling ambiguous joins across multiple databases, and ensuring compliance through access controls and query governance.
Ultimately, these agentic Text-to-SQL/NoSQL systems succeed not because the LLM “knows” the database — but because they are given the right amount of context to reason about it, and the operational scaffolding to try, fail, and self-correct safely.
Tool Use for Live Data and Actions (Direct Integration)
While retrieval patterns excel at accessing indexed knowledge, some use cases require accessing live, operational data or executing state-changing operations. This is achieved through direct integration or tool use. This pattern gives agents "hands" to interact with live enterprise systems through APIs. This also enables external data acquisition patterns such as querying the internet.
As stated above, the MCP tool approach can be used to directly access an enterprise’s vendor applications data, such as from Teams, Slack, Github, Google Drive, etc. via their corresponding MCP servers. One limitation of this approach, however, is that not all such applications provide an effective semantic search capability over their data. Thus, it is important to analyze and test the capabilities of this approach vs pre-indexing the data from these applications via some form of RAG pattern. Finally, with the widespread adoption of MCP, a common approach has emerged of packaging RAG systems as MCP tools. This enables cleaner Agentic RAG patterns, where the agent can iteratively call the RAG system (or even multiple RAG systems) as an MCP tool in order to retrieve the information it needs.
The Event-Driven Agent
This pattern transforms agents from purely reactive systems into proactive entities that can respond to events as they occur across the enterprise. A data streaming platform, such as Apache Kafka, serves as the enterprise's central nervous system. Business-critical events are published as messages to specific topics, and specialized agents subscribe to these topics. When a relevant message appears, it triggers the agent to begin its reasoning and action loop, applying context engineering patterns to gather information and execute tasks. This architecture enables agents to operate autonomously and proactively, driven by the real-time flow of data within the enterprise.
Conclusion: From Connectivity to Zero-Trust to Production
In this blog we went over the essential architectural blueprints for connecting autonomous agents to the enterprise data landscape. We established a clear verdict: context engineering is the foundational approach for providing agents with knowledge and the ability to act, with Retrieval-Augmented Generation (RAG) being the dominant pattern for knowledge retrieval and MCP emerging as the standard pattern for not only direct API integration, but also as a wrapper for RAG systems.
Mastering these patterns is the necessary prerequisite for building any effective agentic system. However, the true enterprise-grade challenge lies not in connecting a single agent, but in managing and securing systems of agents operating at scale. Now that we know how to connect a single agent, how do we coordinate data access and manage dependencies when multiple, specialized agents must collaborate to achieve a complex business goal? This question of inter-agent communication and workflow management is the central focus of our next blog: Orchestrating Data Access in Multi-Agent Systems.
The journey from a promising pilot to a secure, production-ready agentic system requires moving beyond the connectivity patterns of a single agent to solve the challenges of multi-agent orchestration and implement a comprehensive, Zero-Trust security framework. These are the subjects of the next two blog posts in this series. Stay tuned!
FAQ
What is an agentic data fabric?An agentic data fabric is the architectural framework that connects autonomous AI agents to enterprise data sources through context engineering, retrieval mechanisms like RAG, and tool integrations like MCP, enabling agents to access and act on information while maintaining security and governance controls.
What is the difference between context engineering and model fine-tuning?Context engineering assembles relevant data into an LLM's context window at inference time, keeping knowledge separate from the model, while fine-tuning embeds knowledge directly into the model's parameters through training. Context engineering is generally preferred for enterprise use cases because it supports better security, data freshness, and governance without requiring model retraining.
How does RAG work in enterprise agentic systems?RAG operates through two phases: an offline indexing pipeline that parses, chunks, and embeds documents into a vector store, and an online retrieval pipeline that searches for relevant chunks based on user queries and feeds them to the LLM as context for generating grounded responses. The quality of retrieval depends heavily on how well source documents are parsed and structured before indexing.
How does Unstructured support the data ingestion layer of an agentic data fabric?Unstructured connects to over 50 enterprise data sources, including SharePoint, S3, Confluence, and Google Drive, and transforms unstructured content like PDFs, HTML, and PPTX into clean, structured data ready for downstream indexing. This means AI agents can operate on accurately parsed, consistently formatted content rather than raw, noisy documents that degrade retrieval quality.
How does Unstructured handle document chunking for RAG pipelines?Unstructured offers multiple chunking strategies, including basic, by-title, and by-page approaches, that can be configured based on document type and retrieval requirements. Because chunking happens after document elements are extracted and classified, chunks respect the semantic structure of the source content rather than splitting arbitrarily across headings, tables, or list items.


