Defining the Autonomous Enterprise: Reasoning, Memory, and the Core Capabilities of Agentic AI
Nov 12, 2025
Authors

This is the second post in our ongoing series on architecting for the agentic enterprise. Our first blog post established the massive business opportunity and the critical insight that data architecture is the primary bottleneck preventing agentic pilots from reaching production.
Today we’ll illuminate the architectural features of robust agentic systems that lay the foundations for closing that gap. Knowing that architects coming to this blog series will have varying levels of experience with these systems, this post will effectively serve as a crash course in agentic systems, as it spans everything from a description of a basic agent, in terms of its features and core capabilities, all the way to reference architectures of fully featured enterprise agentic systems. Mastering these concepts is the prerequisite for tackling the more advanced topics of data connectivity and security that we will cover in further posts.
Defining the Enterprise Agent: A New Class of System Actor
AI agents represent a profound leap in humanity’s long drive to externalize the mind through its technology. This progression can be seen from the simple calculator to the computer program and then from neural networks (including LLMs) to the simulated agency of today. This is not just an academic curiosity; a pragmatic takeaway follows from the observation that with each wave of advancement, our technologies are evolving from extensions of the mind into independent embodiments of it. It seems inevitable that the progression will continue at least to the effective parity of these systems with the capabilities of the human mind. At that point, there will be an economic imperative for organizations to bestow more and more trust and governance on these systems. The enterprise architect, therefore, must build for this future. We cannot design systems merely for the state of AI of today; we must engineer frameworks that anticipate the far more autonomous AI agents of tomorrow.
With that mandate established, let us align on a functional definition of the enterprise AI agent:
An enterprise AI agent is a software 3.0 system, powered by a Large Language Model (LLM) as its core reasoning engine, that can autonomously pursue complex goals on behalf of a user or another system within the enterprise. It achieves this by iteratively perceiving its environment, reasoning to form a plan, and executing a sequence of actions through a set of available tools. Finally, agents effectively learn and improve from their experiences by implementing a memory system to manage both short-term and long-term information.
To extract from the above definition and reiterate, an agent is fundamentally defined by four capabilities:
- perception via multi-modal inputs;
- cognitive abilities provided by an LLM (or multimodal model);
- system action enabled by its ability to execute connected tools; and
- iterative improvement enabled by short-term and long-term memory.
Unlike traditional programs that mechanistically follow deterministic, pre-programmed logic, agents dynamically and iteratively generate and subsequently follow their own plans of action. Given an objective, an agent autonomously and stochastically determines the best course of action required to achieve it, adapting its approach based on environmental feedback and accumulated experience. Thus, agents represent a new class of non-human, non-deterministic actors that operate within the enterprise ecosystem. To understand these entities better, let us take a closer look at their internal mechanisms and develop a better sense of the nature of their autonomy.
The LLM as the Agentic Reasoning Engine
The recent and rapid emergence of sophisticated agentic capabilities is a direct consequence of recent cognitive ability breakthroughs within Large Language Models (LLMs), specifically the ability of these models to exhibit strong reasoning capabilities. The first of many LLMs to tout this ability was the o1 model, pioneered by OpenAI and released on December 5, 2024. OpenAI purportedly developed the model by fine-tuning on good reasoning examples using multi-stage Reinforcement Learning (RL). Yet despite these advances, today’s LLMs simulate reasoning linguistically rather than compute it logically, producing persuasive language pathways rather than genuinely reasoned conclusions. They can also still hallucinate or err when deprived of grounding data. In any case, the reasoning-capable LLM serves as the agent's core cognitive component—its "brain" or logical decision-making engine. It provides the foundational ability to understand complex, natural language instructions, reason about them, and decompose them into a sound plan of action. It is the LLM that endows modern agentic software programs with the flexible, general-purpose intelligence that distinguishes them from rule-based programs.
The Spectrum of Agentic Autonomy in LLM Applications
To better understand the agency levels (and corresponding risk levels) of LLM-powered applications, the following spectrum of autonomy is a more functional framework for architects than relying on ambiguous terms like 'assistant,' 'agent,' or 'bot.' It can be used to classify initiatives based on risk, complexity, and the level of human oversight required. The degree to which an LLM, versus a human or hard-coded logic, controls the application's flow determines its level of autonomy. As illustrated in the diagram below, the autonomy spectrum can be broken down into six distinct levels, categorized by the degree to which its steps are human-determined vs agent-determined.
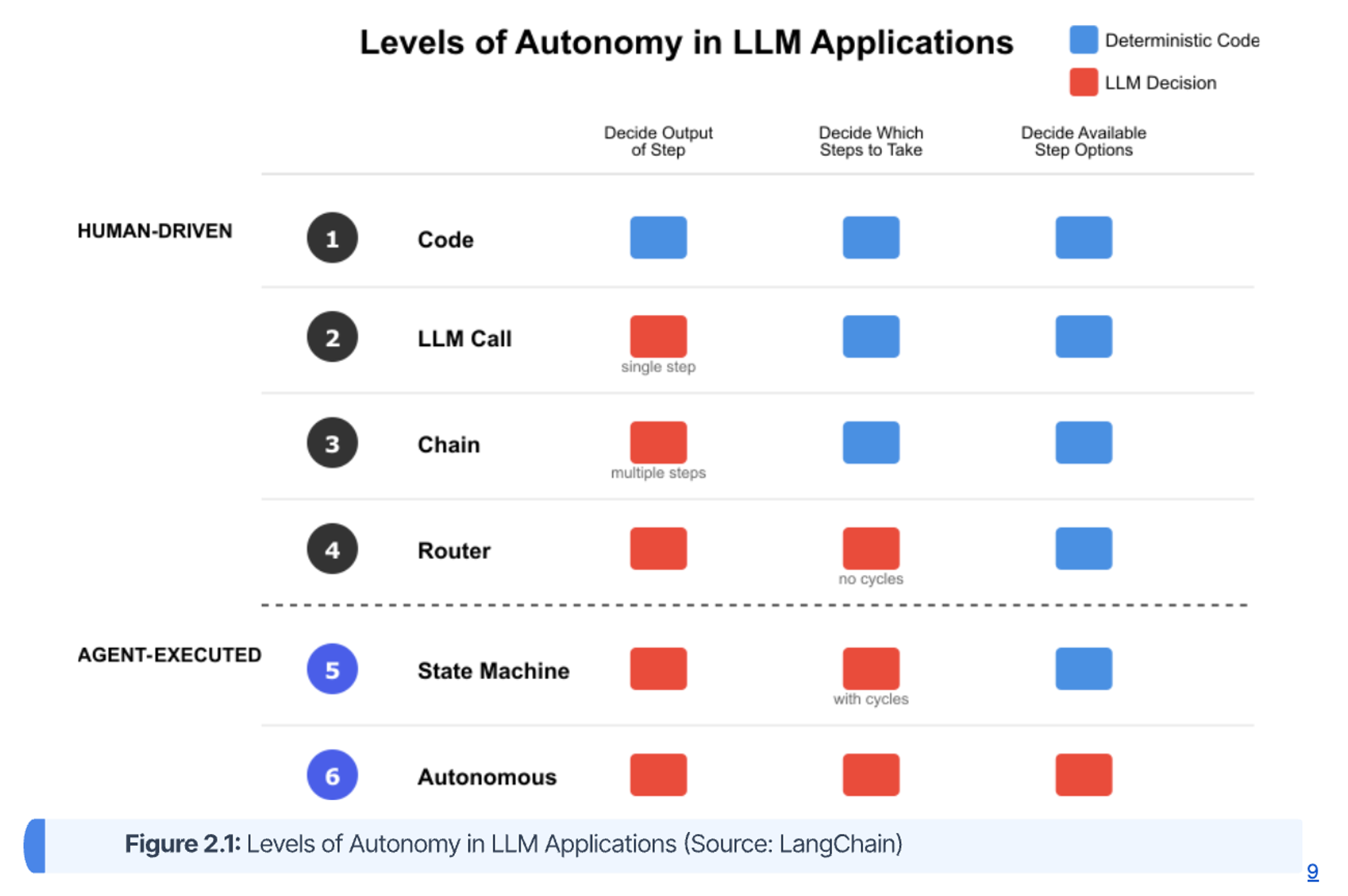
The human-constrained autonomy levels, as can be seen above the dotted line in Figure 2.1, are as follows:
- Level 1: Code: This is the baseline rules-driven system with no autonomy. The application's logic is entirely hard-coded and deterministic. A human developer decides the output, the steps to take, and what steps are available.
- Level 2: LLM Call: The first step toward autonomy. The LLM is used to decide the output of a single, predefined step. The human still defines the sequence of operations. A simple example is using an LLM to summarize a fixed piece of text.
- Level 3: Chain: The LLM determines the output across multiple, predefined steps. The sequence is still fixed by the developer, but the LLM's output from one step is passed as input to the next. Typically Retrieval-Augmented Generation (RAG) pipelines fall into this category.
- Level 4: Router: At this level, the LLM begins to influence the control flow. The LLM decides not only the output of a step but also which step to take next from a set of predefined options. The key limitation is that these paths are acyclic (they do not form loops).
The LLM-executed autonomy levels, as can be seen below the dotted line in Figure 2.1, are as follows:
- Level 5: State Machine: This is the first true level of agent-like behavior. Although a human again predefines the steps, the LLM decides which step to take next, and the workflow can include cycles or loops. This allows the system to retry steps, ask for clarification, or iterate on a task until a condition is met. This level (and sometimes even the previous Router pattern level) is often referred to as “flow engineering”.
- Level 6: Autonomous: This represents the highest level of autonomy. The LLM decides the output, the next step to take, and can even determine what steps or tools are available to it. The guardrails are removed, and the agent has the freedom to define its own course of action to achieve a goal.
This framework provides architects with a clear model for risk assessment. Applications at Levels 1-4 operate with predictable, human-defined guardrails. However, an application at Level 5 or 6, with its capacity for cyclic and autonomous action, represents a new category of risk. Classifying an initiative as "Agent-Executed" is a signal that traditional governance and security models are insufficient. It mandates a shift toward more robust architectural patterns for security, comprehensive observability to understand non-deterministic behavior, and robust control mechanisms like sandboxing, human-in-the-loop approval gates, and emergency "kill switches".
Common LLM Application Workflow Patterns
This section outlines some of the most common LLM application workflow patterns of varying levels of agency, illustrating several levels of the above autonomy taxonomy. The patterns are visualized in Figure 2.2, as well as described below. These atomic patterns still play a heavy role in agentic engineering.
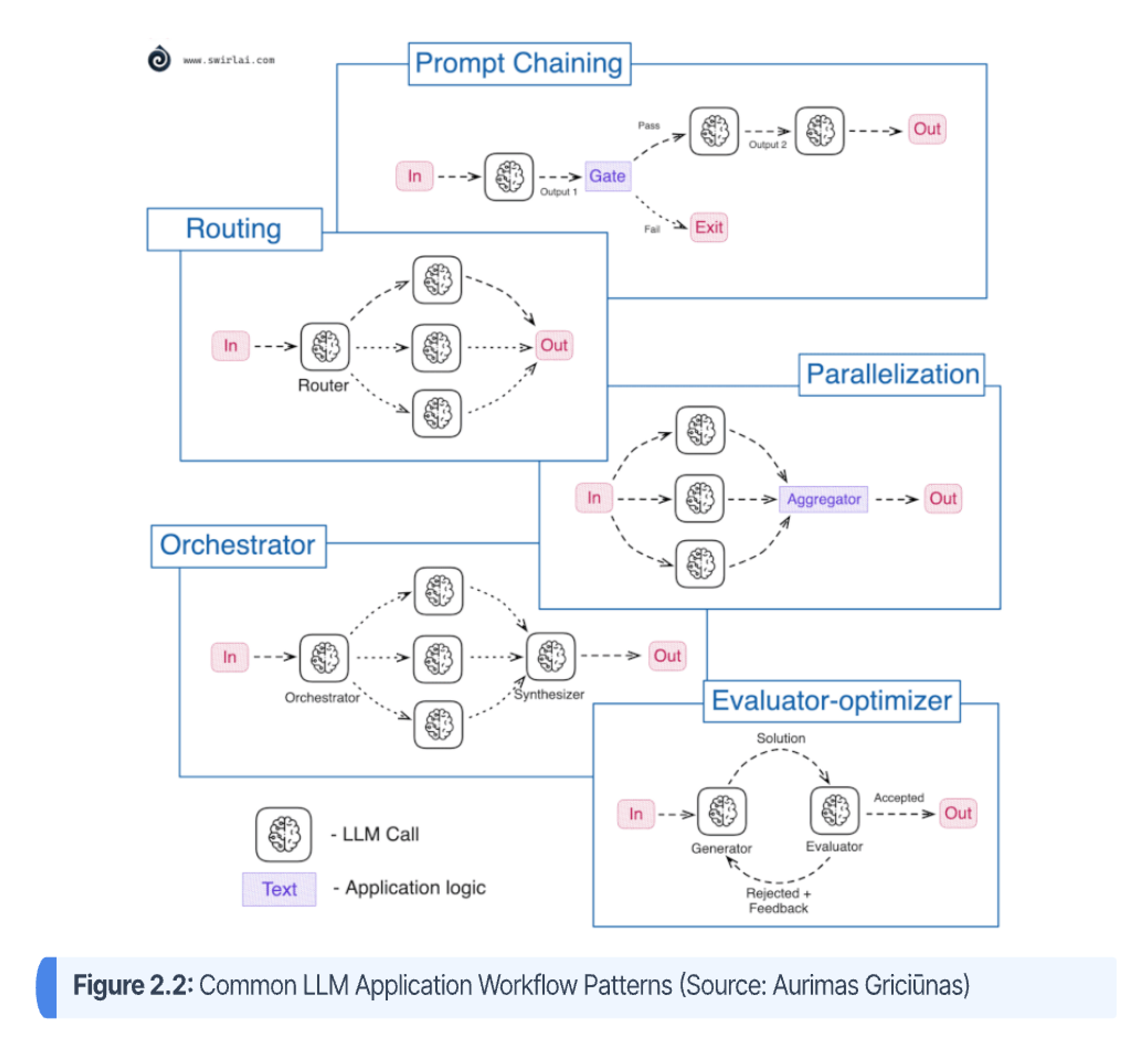
- Prompt Chaining: This (level 3) pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an input to another.
- Routing: In this (level 4) pattern, the input is classified into multiple potential paths and the appropriate is taken.
- Parallelization: In this (level 4) pattern, the initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer.
- Orchestrator: An orchestrator workflow (can range between levels 4-6) dynamically breaks down tasks and delegates to other LLMs or sub-workflows.
- Evaluator-Optimizer: In this (levels 5-6) pattern, the generator LLM call produces a result that the Evaluator LLM call evaluates and then provides feedback for further improvement if necessary.10
Now that we have established a basic understanding of the levels of autonomy of LLM applications and common agentic workflow patterns, we are ready to explore the anatomy of an agent.
The Anatomy of an Agent: Core Capabilities
We defined an enterprise agent previously as a software system endowed with cognitive abilities and memory, allowing for the perception of inputs, the ability to reason and plan, and the ability to take system action via tools. We will now explore in detail how these abilities work together. An effective agent has a cognitive architecture, leveraging the raw intelligence of an LLM for the purposes of perception, reasoning, planning, evaluation, and more. While many aspects of the LLM’s cognitive abilities are important, the two most essential for agentic systems are reasoning and planning. It is the integration of reasoning, planning, memory, and tool use that enables robust, autonomous behavior. As shown in Figure 2.3, these pillars do not operate in isolation, but rather form a synergistic system where reasoning and memory informs planning; planning coordinates tool use; and the results of tool use populate memory—creating a virtuous cycle of learning and improvement. We will discuss each of these capabilities in detail to follow, but in summary:
- Reasoning enables agents to analyze situations, evaluate alternatives, and make decisions—the cognitive foundation for autonomous operation.
- Planning enables agents to decompose complex goals into executable subtasks, determine optimal sequences, and dynamically adapt when circumstances change.
- Memory enables agents to maintain context across interactions, learn from past experiences, and access organizational knowledge—the difference between stateless tools and systems that improve with use.
- Tool Use transforms agents from isolated reasoning engines into systems that act on the world through MCP (Model Context Protocol) Servers, APIs, databases, enterprise applications, and other agents.
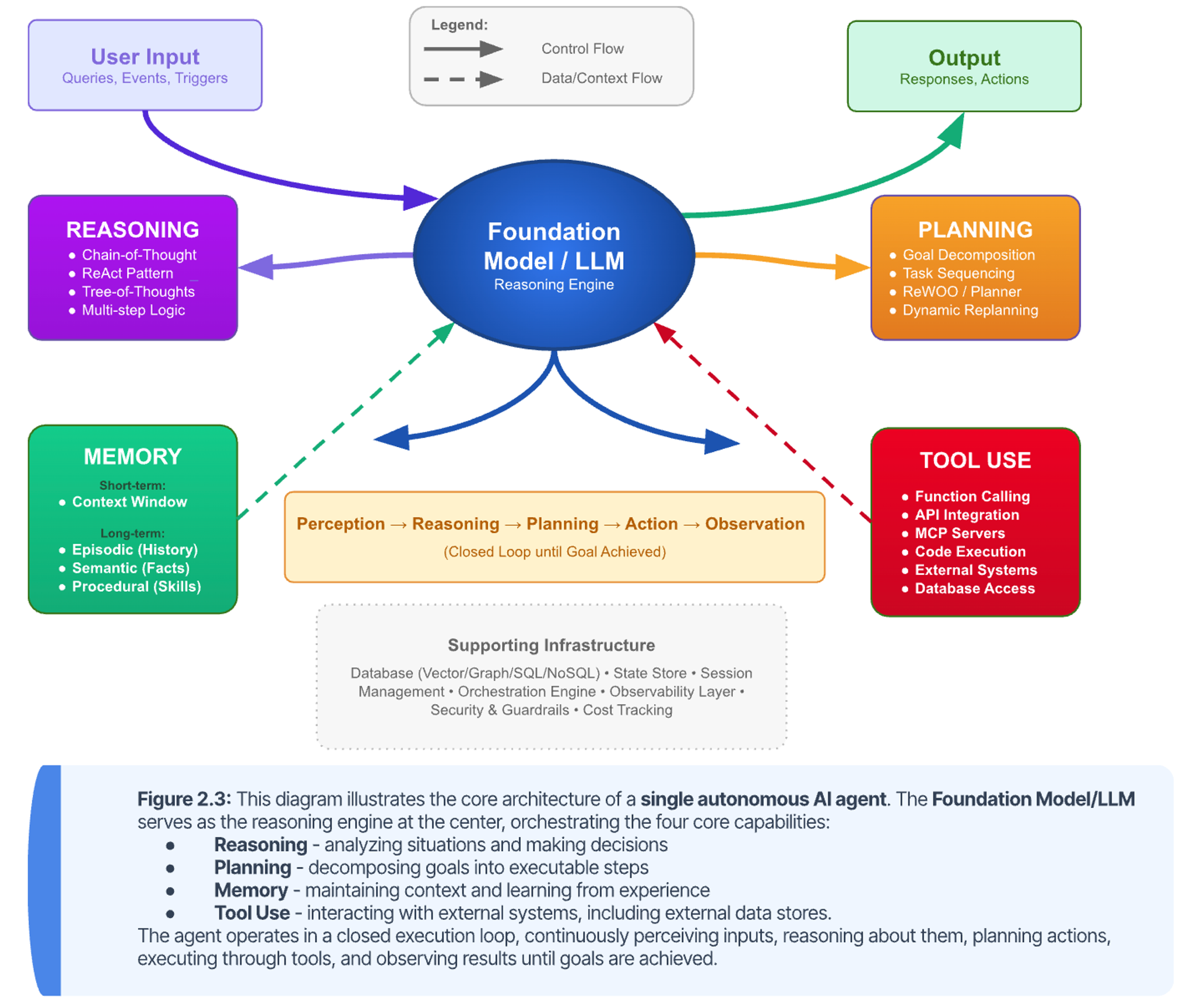
If you intend to actually build agents, the following deep-dive about the above four components is provided to fully explain the atomic agent. Otherwise you can skip the remainder of this section and continue with From Single Agents to Multi-Agent Ecosystems.
1-2) Reasoning and Planning: The Cognitive Core
Reasoning and planning form the agent's cognitive core, enabling it to transform a high-level goal into a concrete, executable strategy. This process begins with goal definition, where the agent clarifies its objective, and state representation, where it builds a model of its current environment based on available data. The central step is task decomposition, a process where the LLM's reasoning capabilities are used to break down a complex goal into a hierarchical series of smaller, manageable sub-tasks. In the reasoning step, agents are often instructed to employ any number of proven effective reasoning patterns, including Chain-of-Thought (CoT), Self-Consistency with Chain-of-Thought (CoT-SC), Tree-of-Thought (ToT), and more.
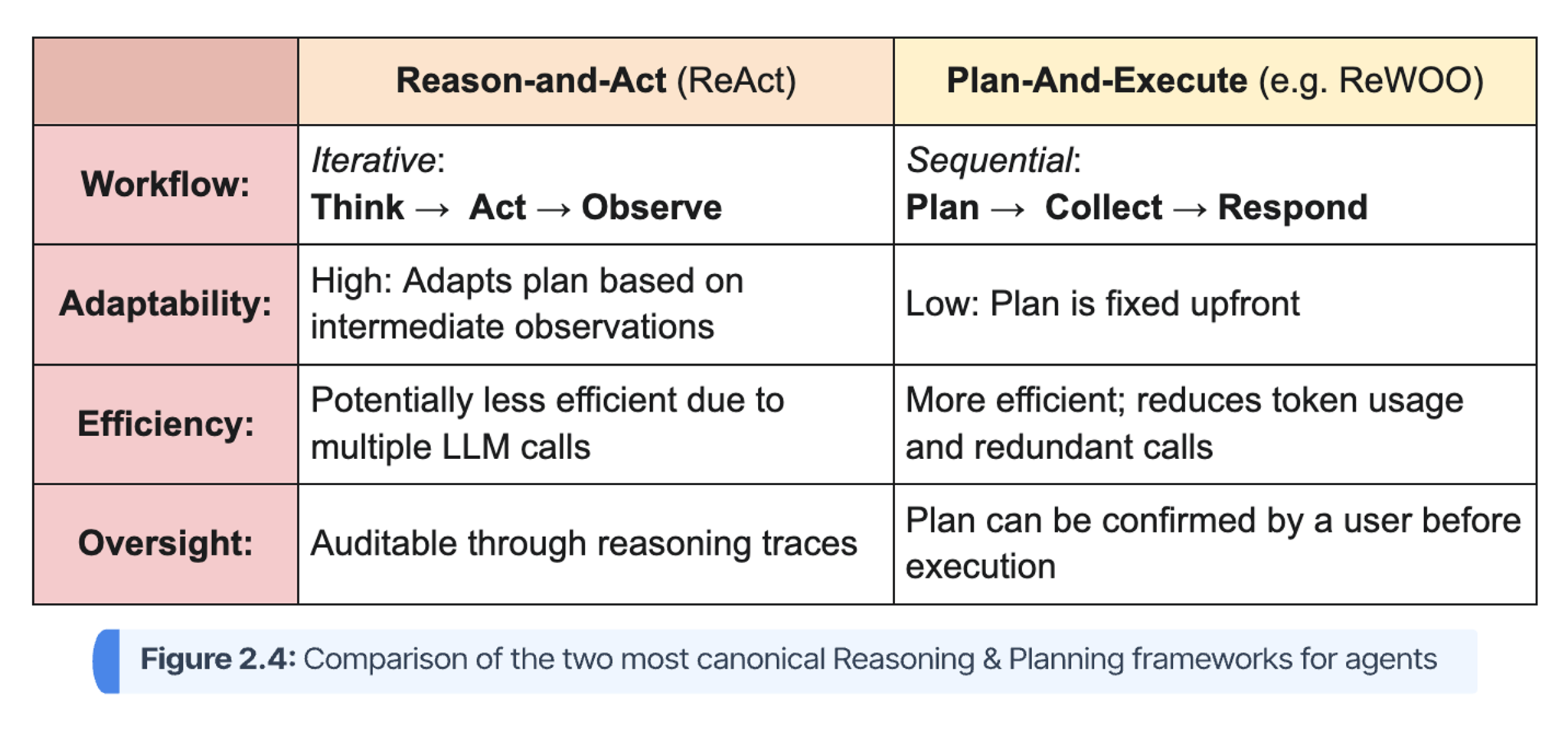
Two prevalent and effective implementation patterns for the overall cognitive loop are the Reason-and-Act (ReAct) framework and the Plan-and-Execute approach, the latter exemplified by the ReWOO (Reasoning Without Observation) framework.
The ReAct framework is the most widely adopted implementation pattern for building effective agents. It creates a powerful synergy between cognition and action through an iterative Think → Act → Observe enrichment loop. The agent first generates a verbal reasoning trace ("Thought"), then formulates a call to an external tool ("Action"), and finally incorporates the result ("Observation") into its context for the next thought. This continuous cycle grounds the agent in real-world data, significantly reducing the risk of hallucination and producing more reliable, auditable outcomes.
In contrast, the Plan-and-Execute approach, such as in the ReWOO framework, separates these stages. It first generates a complete plan of all necessary tool calls, then executes them all at once to collect information, and finally uses the plan and the collected results to formulate a response. This "plan-ahead" approach can be more efficient and allows for user confirmation before execution, but it is less adaptable to dynamic environments where intermediate results might change the optimal course of action.
A visual, comparative summary of the two approaches is provided below:
3) Memory: The Foundation for Context and Learning
Memory is the capability that elevates an agent from a stateless transaction processor to a stateful, learning entity. It allows the agent to maintain context across interactions, recall past events, learn from feedback, and personalize its behavior, making it more effective and intelligent over time. Architecturally, agent memory is implemented across two distinct layers: short-term memory and long-term memory. An overview of these two systems is provided visually in Figure 2.5, as well as the corresponding descriptions immediately following.
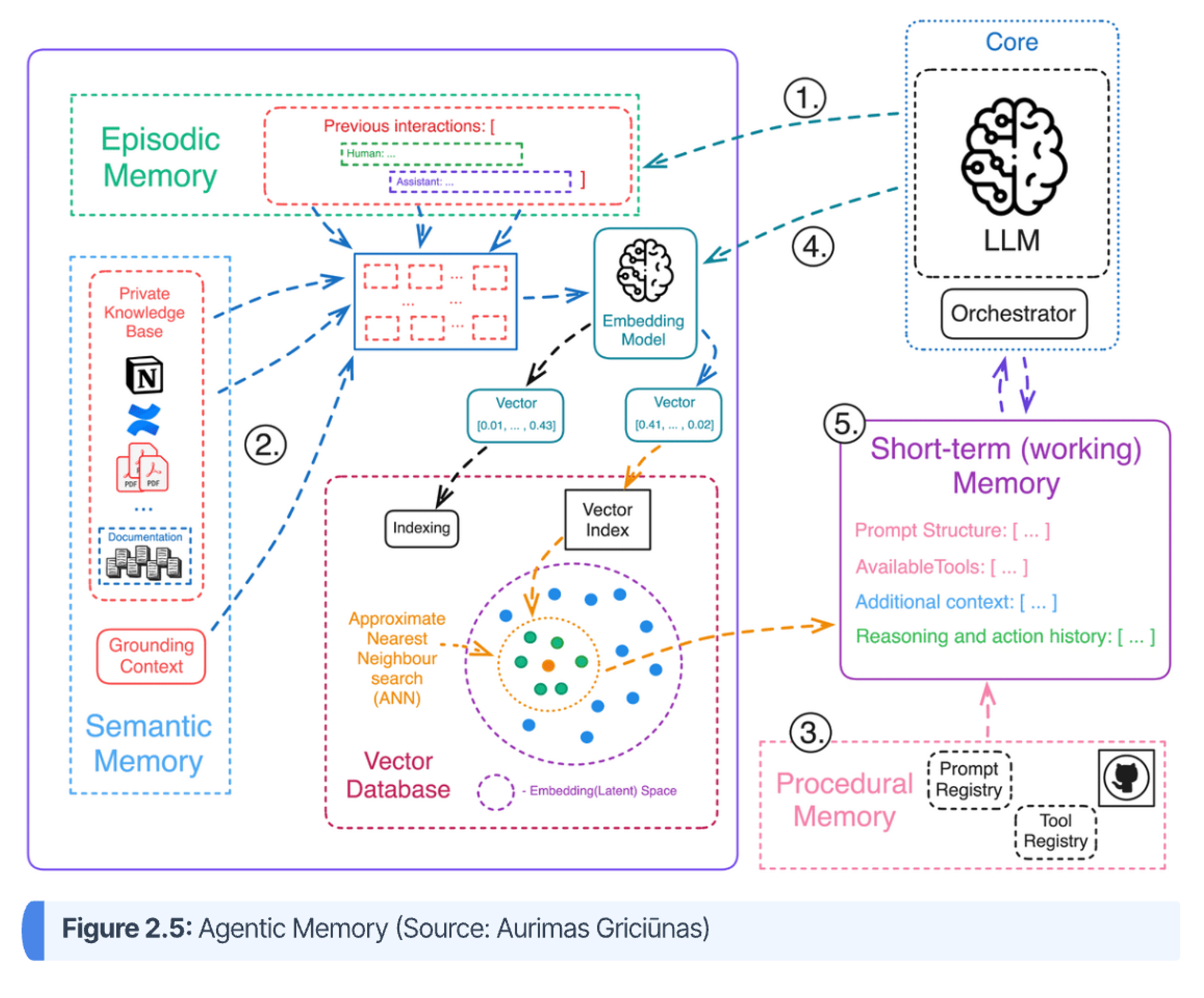
- Short-Term Memory (Context Window): This is the agent's working memory, holding relevant details for an ongoing task or conversation. Architecturally, this is managed within the LLM's context window—the set of tokens the model can "see" at any given moment. While modern LLMs have large context windows, they are still finite and can be overwhelmed by long histories or large tool outputs, leading to "context rot" where performance degrades. Effective context engineering, using techniques like trimming or summarizing older parts of the conversation, is crucial for managing this limited resource efficiently.
- Long-Term Memory: This is a durable storage layer that allows an agent to retain and recall information across different sessions, enabling true learning and personalization. Long-term memory can be categorized into three types that mirror human cognition:
- Episodic Memory (Previous Interactions): This is the memory of specific past experiences, events, and interactions, like a diary of what the agent has done or discussed. It allows an agent to learn from past successes and failures.
- Semantic Memory (Facts & Knowledge): This is the agent's repository of structured, factual knowledge—the things it "knows" about the world, a specific domain, or a user's preferences. Unlike episodic memory, which stores experiences, semantic memory stores generalized information like facts, definitions, and rules.
- Procedural Memory (Skills & Capabilities): This is the “what-to-do” and "how-to-do-it" memory that allows an agent to learn and automate skills or sequences of actions. Through experience, often using reinforcement learning, an agent can distill successful trajectories into reusable procedures. This allows the agent to perform complex, multi-step tasks more efficiently over time without having to reason from scratch each time. It also handles systemic memory, like prompt & tool registries.
As is depicted in Figure 2.5, both episodic and semantic memory are commonly implemented using Retrieval-Augmented Generation (RAG), where past interactions and knowledge, respectively, are stored, often as vector embeddings in a vector database. When a new query arrives, the most relevant past episodes are retrieved based on semantic similarity and provided to the agent as context. Additionally, both knowledge graphs and SQL databases can also be used for RAG, as will be discussed in the next blog post.
4) Tool Use: Interacting with the Enterprise Landscape
Tools are the agent’s hands, enabling it to take action in the enterprise world — calling APIs, querying databases, or executing code. The Model Context Protocol (MCP) has emerged as the de facto standard for this interaction layer, defining how large language models securely and predictably connect to external systems. MCP was introduced to solve the "N x M integration problem," where N AI applications each required custom-coded connectors for M data sources, creating a quadratically scaling maintenance nightmare. MCP establishes a universal, "plug-and-play" protocol that reduces this complexity from N×M to N+M implementations. An MCP server exposes a system's capabilities through standardized primitives—Tools, Resources, and Prompts—that are designed to be discoverable and interpretable by an agent's LLM. Its significance is underscored by its rapid, cross-industry adoption since its introduction by Anthropic in November 2024. By mid-2025, all major AI and cloud providers—including OpenAI, Google DeepMind, AWS, and Microsoft Azure—had announced support, cementing its role as a foundational component of the modern AI stack.
In MCP, tools are exposed to the agent through MCP servers, which advertise a manifest of available capabilities. Each tool in that manifest is described by three essential components:
- Name — A unique identifier for the operation (e.g., get_inventory_level).
- Description — A natural-language explanation of what the tool does and when to use it (e.g., “Use this tool to get the current stock level for a given product SKU.”). This is crucial context that enables the model to select the correct tool from among many.
- Schema — A formal definition, typically expressed in JSON Schema, that specifies the tool’s required parameters and expected input types.
During its reasoning loop, the agent’s LLM consults this manifest and, guided by the tool descriptions, emits a structured MCP call (a JSON payload specifying the tool name and arguments). The MCP runtime then executes the corresponding enterprise function — whether that’s an internal API, SQL query, or code action — and returns the result as a standardized observation.
This closes the sense–think–act loop: the LLM plans the action, the MCP layer executes it safely and deterministically, and the observation is fed back into the model for the next reasoning step. MCP thus provides the unified interface layer between reasoning systems and the broader enterprise technology landscape.
From Single Agents to Multi-Agent Ecosystems
Understanding the components of a single agent is a necessary starting point, but insufficient for enterprise-scale design. Architects must also master the patterns for organizing these agents into coherent and effective systems. The evolution from single, monolithic agents to complex, multi-agent systems mirrors a familiar journey for enterprise architects: the shift from monolithic applications to microservices. This analogy provides a powerful mental model for grasping the associated benefits and trade-offs.
A single, monolithic agent, much like a monolithic application, attempts to be a jack-of-all-trades. It is often simpler to prototype and deploy for narrow use cases but struggles to scale. As its responsibilities grow, it becomes a performance bottleneck, its logic becomes brittle and difficult to maintain, and a failure in one of its functions can compromise the entire system.
In contrast, a multi-agent system, analogous to a microservices architecture, decomposes a large, complex problem into a collection of smaller, specialized, and independently deployable agents. This approach delivers significant architectural advantages, including:
- Specialization and Performance: Each agent can be optimized for a specific domain or task, leading to higher performance and accuracy.
- Modularity and Extensibility: New agents can be added or existing ones updated independently, promoting agility and simplifying maintenance.
- Resilience and Fault Tolerance: The failure of a single agent does not necessarily bring down the entire system; the orchestrator can route around the failure or invoke a redundant agent.
However, this distribution of logic also introduces challenges familiar from the world of microservices, namely the need for robust orchestration, reliable inter-agent communication protocols, and sophisticated end-to-end observability and debugging.
Multi-Agent System Patterns
For complex, enterprise-scale problems that span multiple domains or require diverse skill sets, a multi-agent architecture is the superior approach. The key architectural decision in designing such a system is choosing the coordination model that governs how the agents interact.
- Hierarchical (Coordinator-Worker) Pattern: This is the most common pattern for enterprise workflows. A central "orchestrator" or "leader" agent is responsible for receiving a high-level goal, decomposing it into a plan of sub-tasks, and delegating each sub-task to an appropriate specialized "worker" agent. The worker agents execute their tasks and report back to the orchestrator, which synthesizes the results and manages the overall workflow. This top-down model provides clear lines of accountability, simplifies orchestration, and is highly effective for processes that can be broken down into a predictable sequence of steps.
- Example: A financial analysis system where an orchestrator agent receives the goal "Analyze Q4 performance for Company X." It delegates tasks to a "SEC Filings Agent" to retrieve financial documents, a "Market News Agent" to gather relevant news, and a "Data Analyst Agent" to process the numbers, before finally passing the synthesized information to a "Report Writer Agent."
- Collaborative (Peer-to-Peer) Pattern: In this model, a group of specialized agents work together to solve a problem without a central, static coordinator. Communication and task allocation are more dynamic and distributed. This can manifest in several ways:
- Sequential Collaboration: Agents work in a predefined sequence, like an assembly line, where the output of one agent becomes the input for the next. The CrewAI framework popularizes this role-based approach.
- Debate or Critique: Multiple agents can generate and critique potential solutions in a structured debate, with a final decision made by consensus or by a designated "judge" agent. This is useful for complex problem-solving where multiple perspectives are valuable.
- Swarm Intelligence: A decentralized model where agents interact based on simple local rules, leading to emergent, intelligent global behavior.
Collaborative patterns offer greater adaptability and resilience in dynamic and unpredictable environments but introduce significantly more complexity in managing communication, resolving conflicts, and ensuring coherent group behavior.
Example: A software development "swarm" of agents, including a 'Product Manager Agent' to define requirements, a 'Developer Agent' to write code, a 'Tester Agent' to write and run tests, and a 'Code Reviewer Agent' to check for quality. These agents might pass work back and forth in a dynamic loop until the task is successfully completed.
A Reference Architecture for the Agentic Enterprise
Synthesizing the concepts of agent capabilities and organizational patterns, we can now define a comprehensive, vendor-agnostic reference architecture for an enterprise-grade multi-agent system. This blueprint provides a structured model for architects to design, build, and govern robust agentic systems that are secure, scalable, and observable.
The architecture is composed of approximately six distinct but interconnected layers, designed to separate concerns and promote modularity. A user request flows through these layers, managed by an orchestrator that delegates tasks to specialized executors, all while being supported by common services for memory, tooling, and governance.

Architectural Layers and Components
- Interaction Layer: This is the system's entry point, providing the interface for users or other automated systems to submit goals. This layer is responsible for capturing the initial request and passing it to the Orchestration Layer. It can be implemented as a chat-based user interface, a REST API or MCP gateway, or a message queue consumer that triggers workflows from enterprise events. In Figure 2.6, the interaction layer is represented by the blue-colored boxes.
- Orchestration Layer (The "Root" Agent): This layer, depicted by the yellow box in Figure 2.6, acts as the central nervous system of the multi-agent system. It is typically embodied by a single, high-level orchestrator agent.
- Function: It receives the goal from the Interaction Layer and uses its core LLM to perform intent recognition and task decomposition. It formulates a high-level plan and then acts as a dispatcher, delegating sub-tasks to the appropriate specialized agents in the Execution Layer. It is responsible for managing the state of the overall workflow, synthesizing results from worker agents, and handling errors or exceptions.
- Key Components: Intent Recognition Module, Planning & Task Decomposition Engine, Task Delegation & Routing Engine.
- Execution Layer (Specialized "Executor" Agents): This layer, represented by the orange boxes in Figure 2.6, consists of a fleet of specialized, domain-expert agents.
- Function: Each executor agent is designed with a narrow focus and a limited set of tools to perform a specific function with high proficiency (e.g., a "Data Query Agent," a "Customer Communications Agent," or a "Code Execution Agent"). They receive task assignments from the Orchestrator, execute them, and return the results.
- Communication: Communication between the Orchestrator and Executors, and potentially between Executors themselves, should occur over a standardized protocol. The emerging Agent-to-Agent (A2A) protocol, which allows agents to advertise their capabilities via "agent cards," is a promising standard for enabling this dynamic discovery and interaction.
- Memory Layer: This is a centralized, shared service that provides both short-term and long-term memory capabilities to all agents in the system. It is depicted by the red-colored databases in Figure 2.6.
- Function: It manages the state of ongoing conversations and long-running tasks (short-term memory) and provides a persistent repository for learned knowledge, historical interactions, and user preferences (long-term memory). This ensures that context is not lost as tasks are handed off between agents and that the system as a whole can learn over time.
- Key Components: A Session/State Management Service (e.g., using Redis) for short-term context, and a hybrid database service combining a Vector Database and a Knowledge Graph for robust long-term memory. Meanwhile, procedural memory, sometimes referred to as an AI Asset Registry, stores system prompts and learns behavioral adjustments through its experiences.
- Tooling & Integration Layer: This layer, represented by the purple boxes in Figure 2.6, serves as a secure and standardized gateway between the agentic system and the broader enterprise landscape of data sources, applications, and APIs.
- Function: It abstracts the complexity of connecting to disparate enterprise systems. Instead of each agent managing its own connections, it calls tools exposed by this central layer.
- Implementation: A best practice is to implement this layer as a Model Context Protocol (MCP) server. An MCP server provides a standardized interface that allows agents to dynamically discover and invoke available tools, such as querying a database or calling an external API, without needing to be hard-coded with connection details.
- Governance & Observability Layer: This is a critical, cross-cutting layer that ensures the entire system operates securely, reliably, and transparently. It is depicted by the green boxes in Figure 2.6.
- Function: It is responsible for managing agent identity, enforcing access controls (the principle of least privilege), logging every decision and action for auditability, tracing requests end-to-end as they propagate through the multi-agent system, and providing mechanisms for performance evaluation and human-in-the-loop oversight.
- Key Components: An Agent Registry to manage agent identities and capabilities, an Identity and Access Management (IAM) module, a centralized Logging and Tracing service (ideally using open standards like OpenTelemetry), and an Evaluation & Feedback service.
Workflow in Action: A Supply Chain Example
To illustrate how these layers interact, consider a supply chain use case, in which the orchestrator agent receives a request to "Replenish inventory for men's backpacks.”
- Request Initiation: A supply chain manager submits the request through a web UI in the Interaction Layer.
- Orchestration and Planning: The Orchestrator Agent receives the goal. It recognizes the intent as "inventory replenishment" and decomposes it into a plan: (1) check current stock levels, (2) if low, identify the primary supplier, (3) place a purchase order, and (4) create a tracking ticket. It delegates the first task to the "Order Agent" in the Execution Layer.
- Execution (Task 1 - Inventory Check): The Order Agent is invoked. It calls the get_inventory tool via the Tooling & Integration Layer (MCP Server). The MCP server translates this into a SQL query against the BigQuery data warehouse. The result (e.g., "5 units remaining") is returned to the Order Agent, which passes it back to the Orchestrator.
- Orchestration (Decision and Delegation): The Orchestrator's plan logic determines that 5 units is below the reorder threshold. It proceeds to the next step and delegates the task "place purchase order for SKU BKPK-M-01" to the "Distributor Agent."
- Execution (Task 2 - Place Order): The Distributor Agent, which has specialized knowledge of suppliers, uses the Tooling Layer to call the place_order tool, which is an API wrapper for the supplier's external ordering system. It receives a confirmation number in response.
- Handoff and Finalization: The Distributor Agent reports success and the confirmation number to the Orchestrator. The Orchestrator then delegates the final task, "track order," to the "Tracking Agent," passing along the necessary order details.
- Governance and Memory: Throughout this entire workflow, the Governance & Observability Layer logs every action: the Orchestrator's plan, each tool call made by the Executor agents, and the final outcome. The state of this multi-step process is persisted in the Memory Layer, allowing the manager to check on its status later or for the system to recover from a partial failure.
Conclusion: Laying the Architectural Foundation
In this blog post we have established the fundamental architectural principles of agentic systems. We have moved from ambiguous terminology to a precise, functional definition of the enterprise agent, distinguishing it from simpler LLM applications through the critical lens of autonomy. We have deconstructed the anatomy of a single agent into its core capabilities—perception, reasoning, planning, memory, and tool use—and examined the technical patterns, such as the ReAct loop and function calling, that coordinate these capabilities into an effective automation workflow.
Furthermore, we have presented the primary architectural blueprints for organizing these agents into multi-agent ecosystems. By drawing a parallel to the familiar evolution from monoliths to microservices, we have provided a strategic framework for understanding the trade-offs between hierarchical and collaborative coordination models. Finally, these concepts were synthesized into a comprehensive, six-layer reference architecture for an enterprise-grade multi-agent system, providing a concrete blueprint for designing resilient, scalable, and governable solutions.
A mastery of these foundational concepts is crucial for success in the agentic era. The architect who deeply understands this material is equipped to move beyond isolated pilots and begin the strategic work of designing the intelligent, secure, and responsive enterprise of the future. The subsequent blog posts will cover data connectivity, orchestration, and security, and will build directly upon this architectural groundwork. Stay tuned!
FAQ
What is the difference between a Level 4 Router and a Level 5 State Machine in LLM application design?
A Level 4 Router uses the LLM to select from predefined, acyclic paths, meaning the workflow always moves forward without looping back. A Level 5 State Machine introduces cycles, allowing the agent to retry steps, request clarification, or iterate until a condition is met, which is the threshold at which traditional governance models become insufficient and more robust controls are required.
How does the ReAct framework reduce hallucination in agentic systems?
ReAct structures the agent's cognitive loop as an iterative Think, Act, Observe cycle, where each reasoning step is followed by a real tool call and the result is fed back into the model's context before the next step. This continuous grounding in external, real-world data prevents the model from reasoning in isolation, which is the primary driver of hallucination in ungrounded LLM applications.
Why does unstructured data create a bottleneck for agentic AI systems?
Agents rely on accurate, retrievable knowledge to reason, plan, and act effectively, but the majority of enterprise information lives in formats like PDFs, presentations, and scanned documents that are not directly consumable by LLMs or vector databases. Without a reliable pipeline to parse, chunk, and structure that content, agents either lack the context they need or retrieve low-quality data that degrades decision-making across the entire workflow.
How does Unstructured support the Memory Layer in an enterprise agentic architecture?
Unstructured processes raw documents from sources like SharePoint, S3, and Confluence into clean, structured, and semantically chunked content that can be embedded and stored in vector databases or knowledge graphs. This directly feeds the semantic and episodic memory stores that agents query at runtime, ensuring that retrieval-augmented generation returns accurate, well-formed context rather than noisy or malformed text extracted from complex document layouts.
How does Unstructured fit into the Tooling and Integration Layer of a multi-agent system?
Unstructured functions as the data preparation backbone behind the MCP servers and APIs that agents call when they need to access enterprise knowledge. By normalizing content from over 25 file types into structured formats before it reaches the integration layer, Unstructured ensures that the tools agents invoke return reliable, high-fidelity information rather than raw, unparsed content that would require additional processing mid-workflow.


