
Authors

Introduction
While a lot of ink has been spilled on requirements for getting your data RAG-ready, less has been detailed on a less sexy part of the tech stack: connectors. Our users often ask what requirements their connectors should meet for enterprise RAG use cases. LangChain, LlamaIndex, ourselves and others did early work in this area starting in 2023 with the introduction of open source document loaders. However, enterprise deployment introduced new compliance, scaleability, and other requirements, which many of the early document loaders don’t meet. Additionally, it’s never been straightforward for all the GenAI builders in this area to take an off-the-shelf Fivetran, Airbyte, Boomi, etc. connectors (traditionally used predominantly for structured data) and plug it into their architectures (for reasons we’ll get to later in this piece). With that context, we sought to make an initial contribution to this area by breaking down the connector features and requirements we’ve heard are essential for moving POCs into production.
We recently published a blog post highlighting what makes our connectors special. Now, we are doing an initial deep dive: a side-by-side, feature-by-feature comparison of our connectors with those of other leading production-grade ETL providers: AirByte, Boomi, and FiveTran. The reason we haven’t included LlamaIndex or LangChain data loaders is that we view those as being perfect for prototyping, but those companies haven’t positioned them as being production grade. That said, we plan to dive deeper on the nuances of open source data loaders vs the production grade connectors in future blogs. Over the coming weeks, we’ll continue to explore the ETL landscape and break down what matters most for GenAI workflows.
Provided in this analysis is:
1 - A comparison of specific connectors that are critical for RAG and GenAI pipelines.
2 - Feature-based evaluations across the most important criteria (we came up with this criteria because we couldn’t find a better one) for connectors in GenAI applications.
Methods
We sourced information from other vendor’s websites and API documentation to generate this analysis. These charts outline the essential features needed to effectively utilize your unstructured data in a GenAI architecture—whether your goal is RAG, building a knowledge graph, generating reports, or something else entirely. Think of it as your GenAI ETL connector field guide: clear, data-driven, and designed to help you make informed decisions.
Disclaimer: We’ve done our best to ensure accuracy, but if you spot any errors or want us to include additional vendors, email us, and we’ll update the blog accordingly. Have ideas for connectors or features that would enhance our product? Fill out our feedback form — we’re always listening and prioritizing user needs.
Why Connectors Matter for GenAI
Not all connectors are created equal, especially in the GenAI ecosystem. That’s why we focused on the ones that matter most:
- Sources: Cloud storage, collaboration platforms, business applications, databases, communication platforms, document storage, development tools, streaming platforms, and more.
- Destinations: Vector stores, search services, cloud storage, traditional databases, specialized vector databases, graph databases, and data management platforms.
While providers like AirByte, Boomi, and FiveTran boast hundreds of connectors, we have narrowed focus here on those critical for GenAI applications - particularly connectors designed to handle unstructured data and seamlessly integrate it into vector databases. These connectors are not interchangeable with classic ETL connectors—not only in their design and maintenance requirements, but also in their ability to provide advanced transformation capabilities and no-code customization tailored to the unique needs of GenAI applications.
Which Features Matter for GenAI
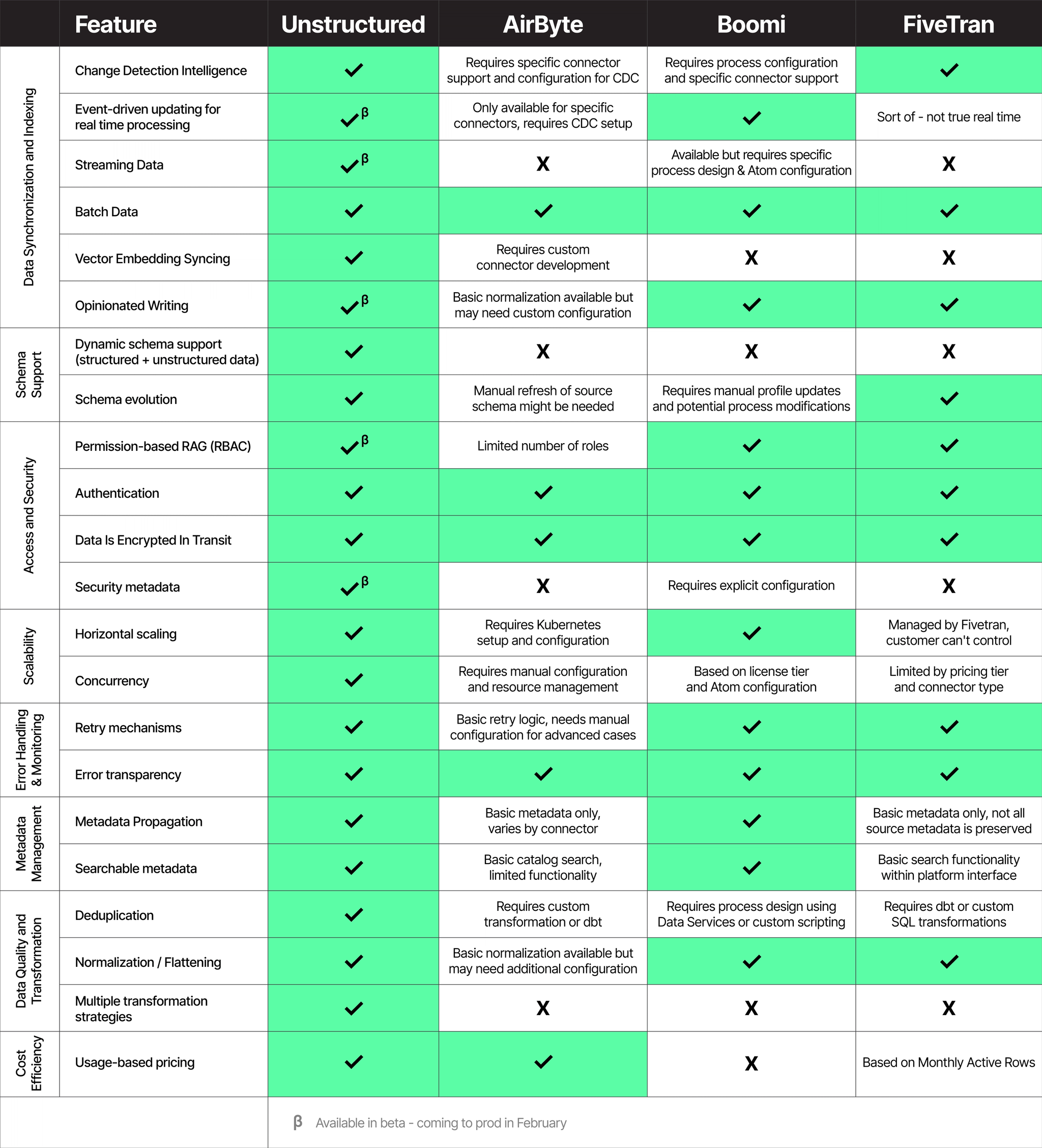
We’ve conducted a detailed comparison of Unstructured, AirByte, FiveTran, and Boomi across several key dimensions for both source and destination connectors. The feature domains and specific criteria are outlined below.
Feature Comparison Domains
- Data Synchronization and Indexing
- Schema Flexibility
- Access and Security
- Scalability
- Error Handling and Monitoring
- Metadata Management
- Data Quality and Transformation
- Cost Efficiency
The specific features we evaluated are:
- Data synchronization and Indexing
This is critical for keeping GenAI systems up to date with your latest changes in your data, and only changing what you need to in your upstream destination connectors.
- Change Detection Intelligence: The ability to efficiently sync only new or changed data within a page, minimizing overhead.
- Event-driven updating for real time processing: Minimal latency to propagate changes from the source to the vector database.
- Streaming data: Support for real-time streaming updates.
- Batch data: Support for bulk data ingestion.
- Vector Embedding Syncing: Performance in embedding creation, transformation, and syncing for large datasets.
- Opinionated writing: Setting up your destination connector with the right schema and embedding dimensions for the data you are transforming.
- Schema Flexibility
Of the ETL providers we compared, Unstructured is the only one that will be compatible with all of your unstructured data. Our schema flexibility allows us to support enrichments (both structured and unstructured).
- Dynamic Schema Support: Compatibility with structured, semi-structured, and unstructured data.
- Schema Evolution: Ability to handle changes in source schema without breaking downstream pipelines.
- Access and Security
- Role-Based Access Control (RBAC): Granular control over who can access what data in both the source and destination.
- Authentication: Integration with enterprise-grade authentication systems (OAuth, SSO, API keys).
- Data Encryption: End-to-end encryption during transit. and at rest.
- Security Metadata: Comprehensive and automatic security metadata preservation and propagation with your data
- Scalability
In addition to our hosted scalability, we offer self-hosted offerings on AWS, or Azure, GCP, or bare metal. We are the only provider to offer this choice: let us scale it for you, or customize scalability as you wish.
- Horizontal Scaling: Ability to handle increases in data volume by adding resources.
- Concurrency: Support for multiple simultaneous sync jobs.
- Error Handling and Monitoring
- Retry Mechanisms: Automated retries for transient failures.
- Error Transparency: Detailed logs and metrics for debugging including open telemetry integration with observability systems.
- Metadata Management
Our metadata offering is unrivaled, allowing you to search and filter with metadata in your destination connector.
- Metadata Propagation: Ability to pass source metadata (timestamps, tags, etc.) to the destination.
- Searchable Metadata: Indexing metadata alongside content to improve retrieval.
- Data Quality and Transformation
- Deduplication: Prevention of duplicate records during sync.
- Data Normalization: Transformation pipelines for standardizing data formats.
- Multiple transformation strategies: Transformation options suitable for different types and qualities of unstructured data: text-based, OCR-based, or VLM.
- Cost Efficiency
- Usage-based pricing: Transparent and scalable pricing models.
Results
For ease of readability, We have used this legend:
- ✓ to indicate a connector that exists,
- X to indicate a connector that does not,
- symbols/text to indicate a caveat - with a symbol explained below, or an alternative subset within the same provider
Note that we maintain and provide support for all of our connectors, and we build additional connectors at no additional cost if there is demonstrated market demand for them.
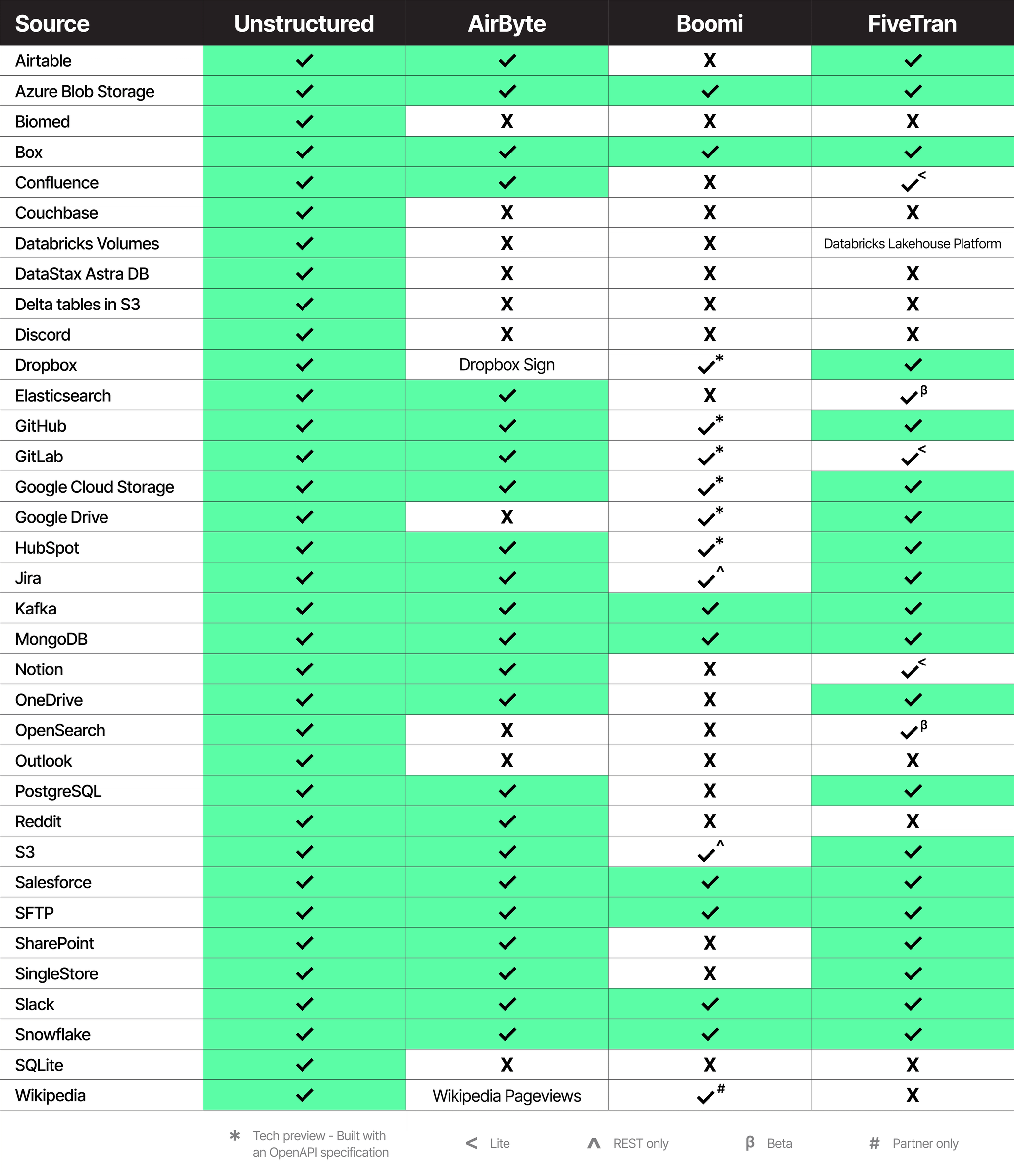
Source Connectors
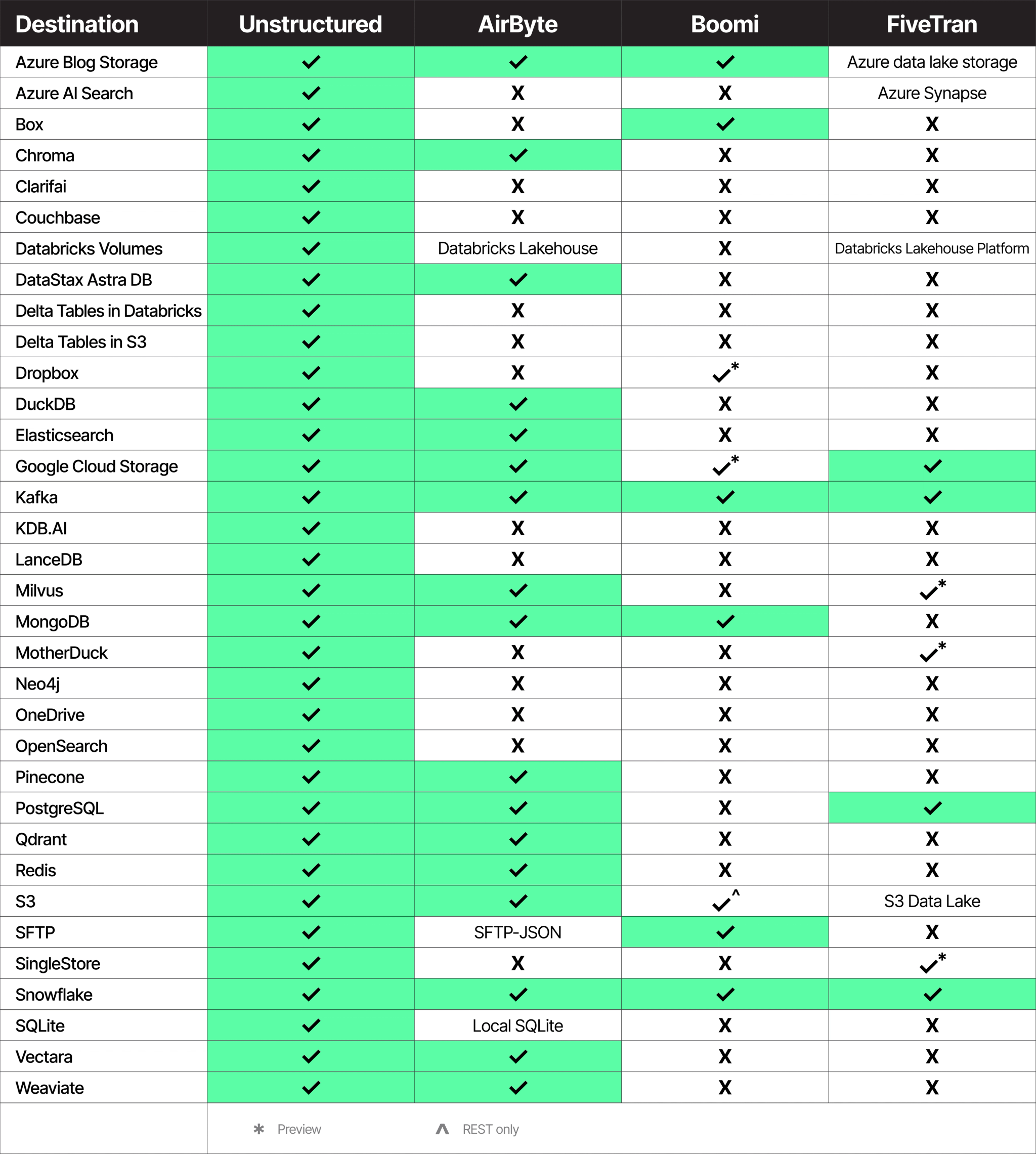
Destination Connectors
Features
Conclusion
We hope you found this comparison useful! This breakdown should let you easily see which connectors and features you need for your ETL, and help you choose an ETL provider. There are some features listed that are really critical to orchestrate within one system for efficient ETL for GenAI: change detection and event-driven updating to only sync your new data, when you have new data. And deduplication to keep this updating from adding duplicates to your destination. Best software deployment practices for production: retries, errors, scaling, and concurrency. And security metadata propagation to best facilitate RBAC in your destinations. If you want to learn more about Unstructured Platform, reach out today.


