
Authors

There’s a specific kind of document that doesn’t work well with most LLM pipelines — not because it’s unstructured, but because it’s too structured. Think 10-Qs, earnings releases, or technical briefs packed with tables. These documents don’t just contain useful data, the data is the document. And it usually lives inside multi-row, layout-heavy tables.
But when you run these PDFs through standard chunk-and-embed workflows, all of that structure gets lost. Tables are flattened into text, layout is stripped away, and you’re left with a blob that’s hard to render and harder to retrieve.
That’s a problem if you're building anything downstream:
- An agent that needs to reason over financials
- A UI that needs to display results cleanly
- A QA system that needs to reference exact numbers, not paraphrased ones
In this post, we’ll walk through a workflow that fixes this. It doesn’t just summarize tables. It preserves them semantically, structurally, and visually. And it makes them retrievable using natural language, with formatting intact.
You can follow along with the notebook here.
Prerequisites
This pipeline relies on 3 external systems. Each one requires a minimal set of credentials that you’ll need to set up ahead of time.
Unstructured
To start transforming your documents with Unstructured, you’ll need an API key. Contact us to get set up — we’ll get you provisioned with access and walk you through the next steps.
AWS S3
This is where your source documents will come from. You’ll need a few things to get started:
- An AWS access key ID
- An AWS secret access key
- The full S3 path to your source location — this can point to a specific folder inside your bucket (s3://my-bucket/my-folder/) or just the root (s3://my-bucket/)
- Some documents in that bucket — PDFs, DOCX, HTML, etc. (full list of supported types)
These credentials allow Unstructured to connect to your S3 bucket and pull raw documents into the pipeline.
Astra DB
This is where your processed and embedded document chunks will be stored. You’ll need:
- An application token with database write access
- Your Astra DB API endpoint: available in the Database settings tab
- The keyspace where you want the collection to live
- A collection name: this must be created with an embedding dimension of 3072, which matches OpenAI’s text-embedding-3-large
These credentials allow Unstructured to push enriched chunks into AstraDB for retrieval.
If you haven’t created a collection yet, you can do it manually in the Astra dashboard. Just make sure:
- You enable vector search
- You set the embedding dimension to 3072
Need help finding your credentials? You can follow the full setup steps in the official docs.
Defining the Pipeline
With our connectors in place, we’re ready to build the pipeline itself.
Unstructured workflows are built out of nodes. Each node represents a distinct operation and together, they define the full shape of your pipeline.
You can think of this like a DAG, but linear: one node feeds into the next.
In this pipeline, we’re using five core nodes:
Partitioner
This is the heart of the whole system. We use Unstructured’s hi_res partitioning strategy, which extracts high-fidelity elements from PDFs — including layout, structure, and block types.
Critically, we enable:
- infer_table_structure: to preserve multi-row tables as HTML
- extract_image_block_types: so we can optionally summarize visuals later
- pdf_infer_table_structure: which handles table boundaries across PDF layouts
This ensures we don’t just extract text, we extract structure.
Image and Table Summarization
In many documents, visual context matters especially if you’re building a system that needs to reason over trends, captions, or summaries. These two nodes use foundation models to describe:
- Images: using OpenAI’s GPT-4o to describe images
- Tables: using Anthropic’s Claude 3.5 Sonnet to summarize tables
You can skip these if your downstream task doesn’t require retrieval over non-textual elements. But when included, they enrich each visual block with natural language descriptions. This is useful for agents or UIs that rely on semantic cues.
Chunker
The chunker breaks the document into overlapping text blocks. Ours is configured to:
- Create new chunks every N characters
- Respect section titles (e.g. “Operating Summary”)
- Retain ~M characters of overlap between chunks
This improves retrieval precision by keeping related content together and avoiding hard breaks mid-table or mid-sentence.
Embedder
Each chunk is embedded using text-embedding-3-large, hosted via Azure. This model produces 3072-dimensional vectors, giving high recall and precision across complex queries including numeric phrases, business terms, and table content.
Together, these nodes form the pipeline. You can add more (NER, classifier, etc.) or remove some depending on your use case. Our goal here is clear:
Preserve the document’s structure. Enrich the content where needed. Chunk it cleanly. Embed it meaningfully.
Running the Pipeline
Once the pipeline is defined, running it is simple. When you trigger this workflow, each document in your S3 bucket is pulled into the Unstructured pipeline and pushed through the full sequence of transformations. That means:
- Partitioning: Each PDF is parsed using Unstructured’s hi_res strategy. This step infers the structure of each page, identifying tables, images, headers, and narrative text blocks and preserves them in a structured form. Unlike traditional PDF parsers that flatten everything into plain text, Unstructured outputs rich semantic elements with positional metadata and block types.
- Summarization: Visual elements like charts or large tables will get captioned using LLMs. These summaries are especially useful for retrieval if your queries involve intent like “show me a chart of year-over-year cloud revenue growth”, the captions give the retriever something to match against.
- Chunking: Next, the document is broken into overlapping text chunks using a title-aware chunker. This ensures that each chunk has enough context, doesn’t exceed token limits, and keeps related content grouped together.
- Embedding: Every chunk is embedded using OpenAI’s text-embedding-3-large model. This produces high-dimensional vector representations that capture semantic meaning across paragraphs, rows, or even headers.
- Storing in Astra DB: Finally, the pipeline writes each enriched chunk into a collection in your Astra DB instance. What gets stored isn’t just the text, it’s the full HTML-rendered layout, the chunk’s vector, and any associated metadata (block type, section title, page number, and more).
Once the job completes, your collection in Astra is fully populated with semantically chunked, vectorized, and layout-preserving versions of the original documents.
These aren’t blobs of plain text. They’re structured building blocks you can now search, filter, and render with precision.
Want the exact table from Alphabet’s Q2 earnings showing Google Cloud’s revenue growth? It’s in there as a chunk, searchable via natural language, and renderable as clean HTML.
In other words: running the pipeline gets your documents understood. Structure is preserved, semantics are enriched, and retrieval becomes far more accurate than any flatten-and-embed workflow could offer.
Now What?
At this point, you’re sitting on a structured index of your documents, fully chunked, embedded, and stored in Astra DB. But the real payoff isn’t just in the processing, it’s in what that structure enables afterward.
In most pipelines, you’d stop here. The docs are vectorized. Great. But if the content was flattened along the way, you’ll run into problems the moment you try to use them:
- A query like “What was Google Cloud’s Q2 revenue?” might return paraphrased fragments, or miss the answer entirely.
- An agent asked to compare growth across segments could hallucinate numbers, or mix up rows and columns.
- A UI trying to display results might spit out unreadable markdown instead of a clean table.
Because we preserved structure, layout, semantics, HTML formatting and now, we can retrieve answers in a way that’s directly usable.
The first capability we unlock is semantic search. Using the same embedding model (
text-embedding-3-large) that we used to index chunks, we can now embed a user query and find the most relevant matches.
A query like:
“Show me Q2 segment results for Alphabet.”
…will return exactly the table you're looking for. Each result is a full HTML chunk, ready to render as-is in your app, pass into an agent, or use in further processing.
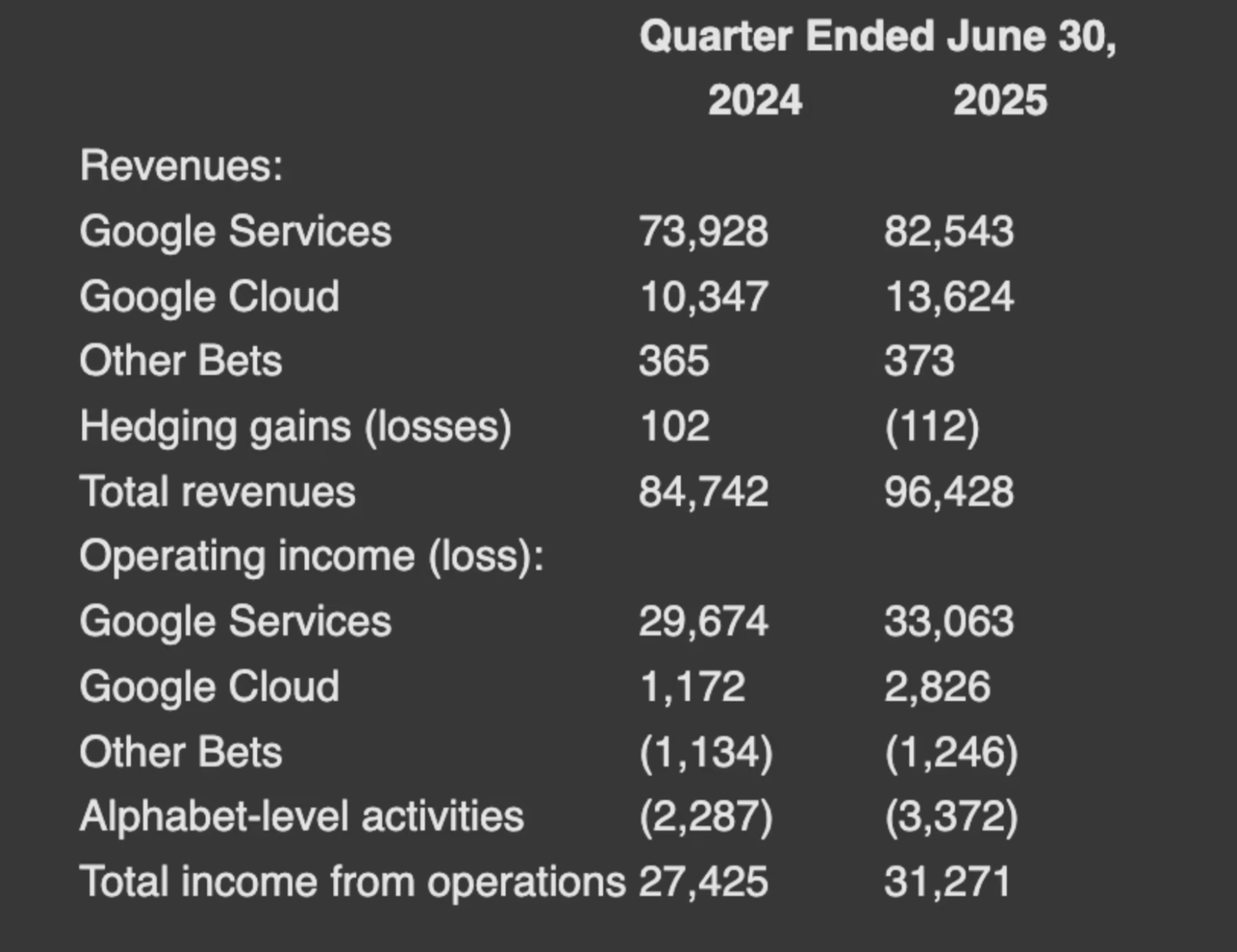
Retrieved HTML Rendered Table
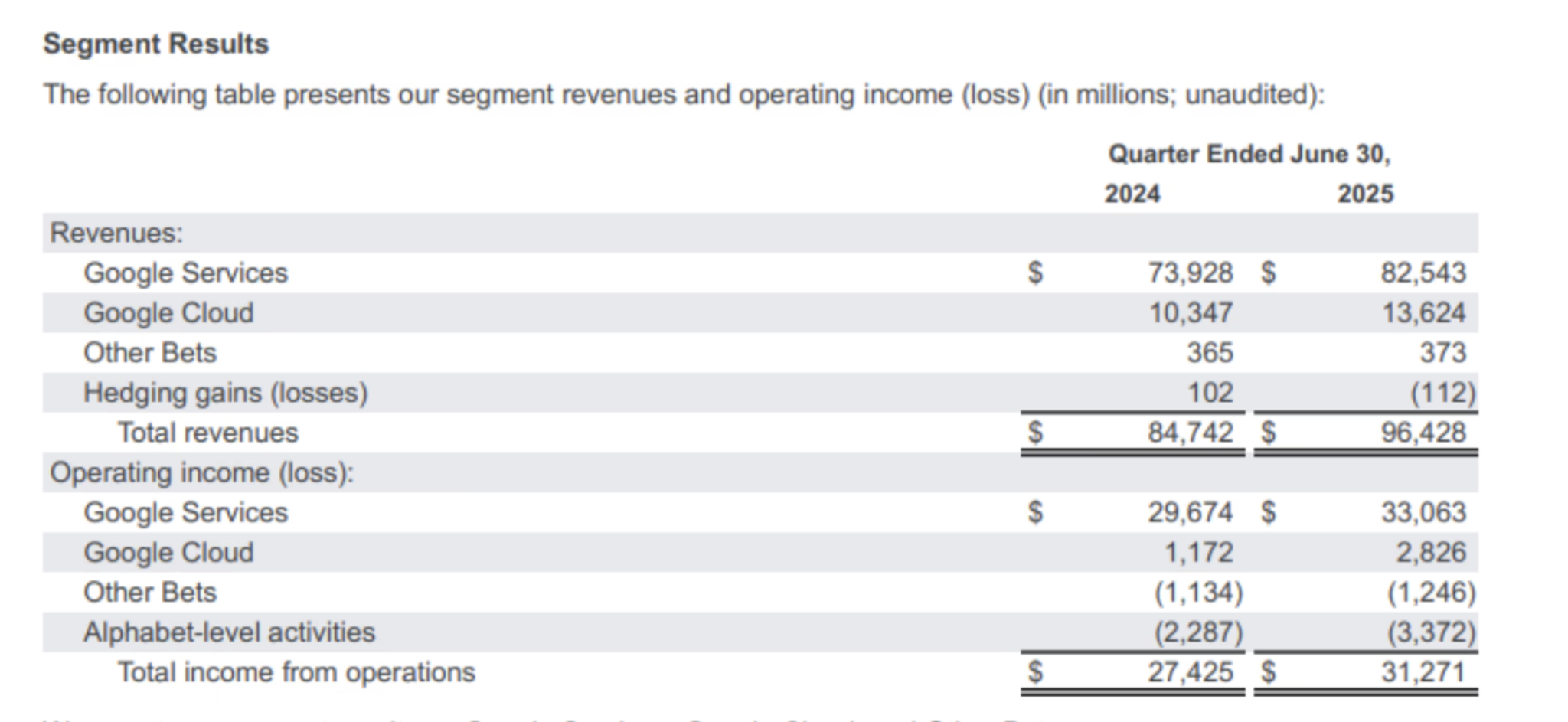
Original Table
What You Can Build on Top
Once you have structured and retrievable chunks, especially those that include full tables, you can start building downstream tools that understand and preserve the original format:
- Agents that reason over rows and compute deltas, ratios, or aggregates
- Dashboards that render HTML tables cleanly with zero transformation
- QA Systems that cite exact financial figures from source documents
- Auditing Tools that trace answers back to their structured origin
Each chunk includes metadata such as section titles, block types, and page numbers.
Why It Matters
Most RAG pipelines lose structure early in the process. Tables get turned into plain text. Layout and formatting are stripped away. By the time the data reaches a retriever, it no longer looks or behaves like the original document.
This pipeline takes a different approach.
It keeps tables intact. Each one is extracted as structured HTML with all of its rows, headers, and formatting preserved. At the same time, we generate a short summary of the table using a language model. That summary is what gets embedded and used for retrieval. But the full table stays attached to the chunk.
This gives you both a searchable description and the original structure to work with. You can retrieve exact figures, show clean tables in a UI, or pass structured data into an agent for follow-up analysis.
Structured documents like earnings reports and technical briefs are common. In many workflows, they are the most important ones. If your pipeline flattens them, you lose a lot of value.
Preserving structure makes the data easier to search, easier to display, and easier to trust.
If you're building RAG pipelines in production or looking for a simpler way to process and index unstructured content, we can help. Reach out to get onboarded to Unstructured. For enterprises with more advanced requirements, we also offer tailored deployments and white-glove support. Contact us to learn how Unstructured can fit into your architecture.
FAQ
Why do standard chunk-and-embed pipelines struggle with table-heavy documents?
Most PDF parsers flatten document content into plain text during extraction, which destroys the row-column relationships that give tables their meaning. When that flattened text gets chunked and embedded, retrievers have no way to reconstruct the original structure, making it difficult to return accurate figures or render clean results downstream.
What is the difference between embedding a table summary versus embedding the raw table content?
Embedding raw table content often produces poor retrieval results because vector models are optimized for natural language, not structured data formats. Embedding a natural language summary of the table instead gives the retriever something meaningful to match against, while the full HTML table stays attached to the chunk so the original structure is available for display or further processing.
What downstream use cases become possible once tables are preserved as structured chunks?
When tables are stored as HTML with associated metadata like section titles and page numbers, they can be rendered directly in a UI without transformation, passed to an agent for row-level reasoning, or used in QA systems that need to cite exact figures rather than paraphrased approximations. Auditing tools also benefit because answers can be traced back to their precise structured origin.
How does Unstructured's hi_res partitioning strategy handle tables in PDFs?
Unstructured's hi_res strategy uses layout inference to identify table boundaries, headers, and multi-row structures within PDF pages rather than treating the page as a flat stream of text. When configured with options like infer_table_structure and pdf_infer_table_structure, it outputs each table as structured HTML with positional metadata and block type labels, preserving the original formatting for downstream use.
How does Unstructured's pipeline handle both semantic retrieval and visual rendering of tables at the same time?
Unstructured generates a natural language summary of each table using a language model, which is what gets embedded and used for retrieval. The full HTML-rendered table remains attached to the chunk as stored metadata in the destination, so when a query returns a result, the application receives both a semantically matched chunk and the original structured table ready to render or pass to an agent.


