Leveraging Enterprise Specific Data With LLMs: How Unstructured Unlocked 100k+ Pages of IRS Manuals
Apr 13, 2023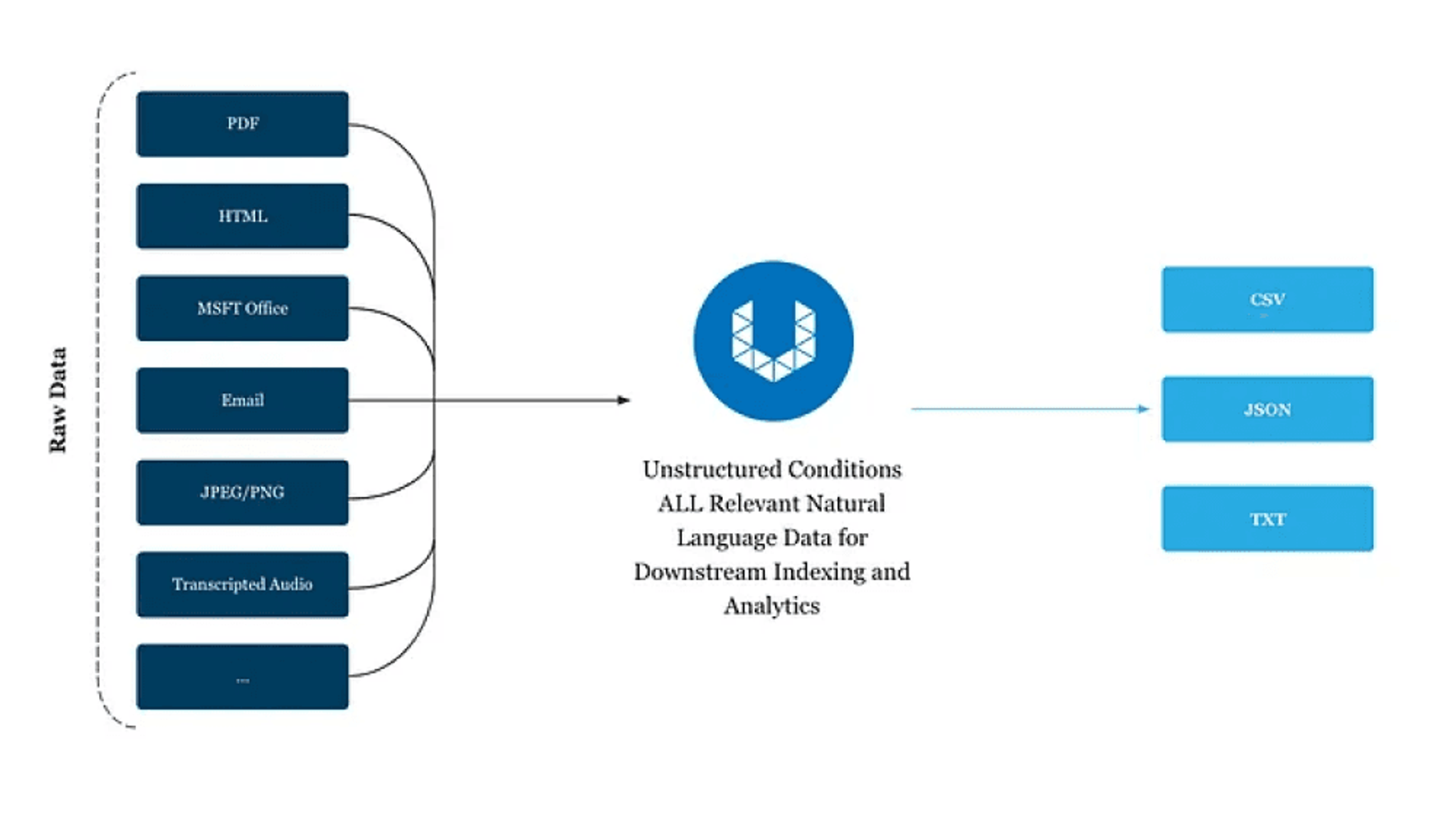

Authors

Getting Down to Work
Scraping
We started with grabbing more than 100k pages of IRS manuals — largely in PDF format — from the IRS government website. Note that you can use Unstructured’s API not only to preprocess PDFs, but also HTML, MSFT Office file types, emails, and more.
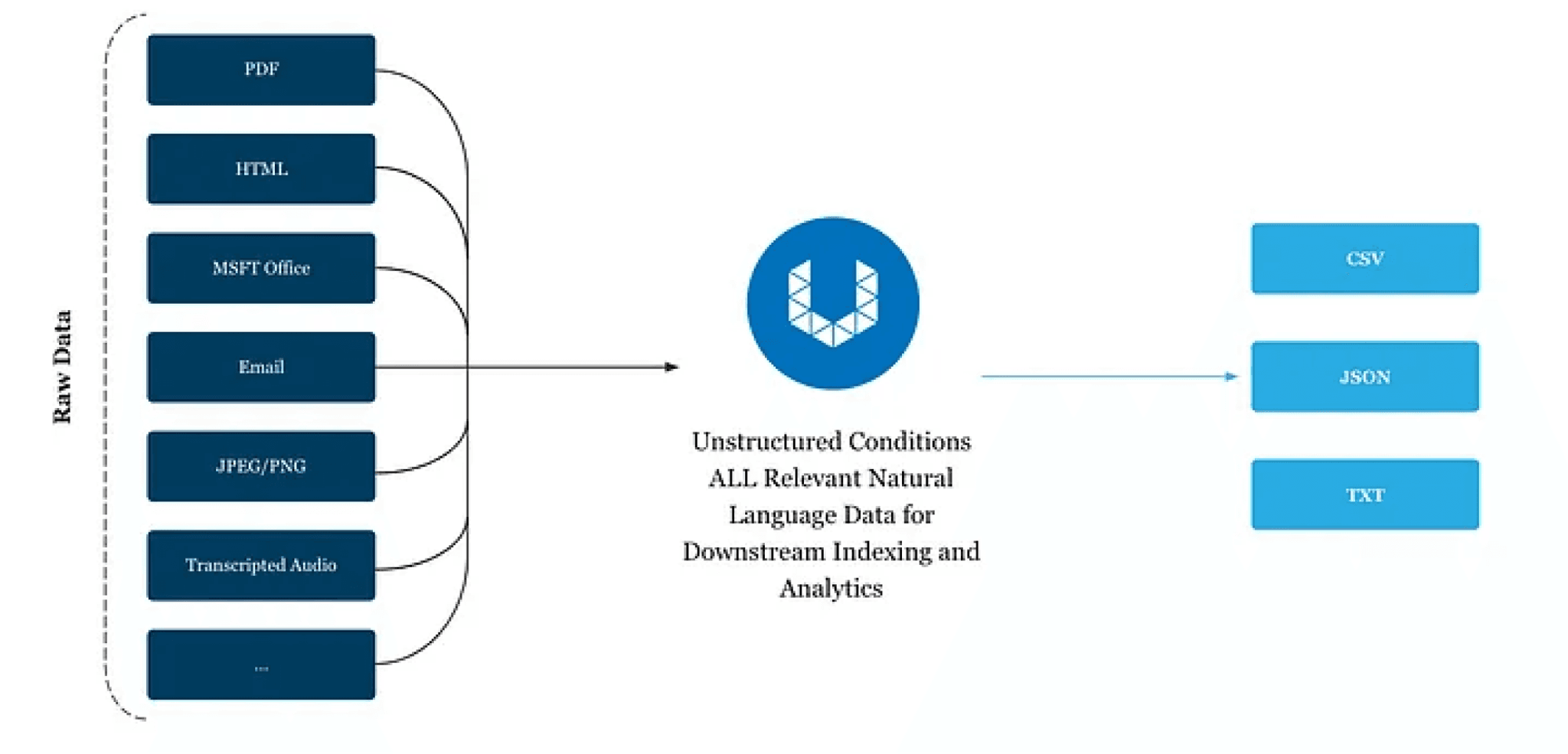
Preprocessing
Once we’d gathered our data, the first step in this project is utilizing Unstructured’s API (or you can deploy our image on your hardware) to preprocess the raw PDFs and transform them into clean JSON. See the readme here to follow the install instructions and clone the demo repo. Once you’re ready to use Unstructured, here’s the one and only command you’ll need for turning your data into easily digestible content:
PYTHONPATH=. ./unstructured/ingest/main.py \ --local-input-path <ingest-input-dir> \ --structured-output-dir <ingest-output-dir> \# optional parameter -> this will hit the *NEW* API vs. processing locally --partition-by-api
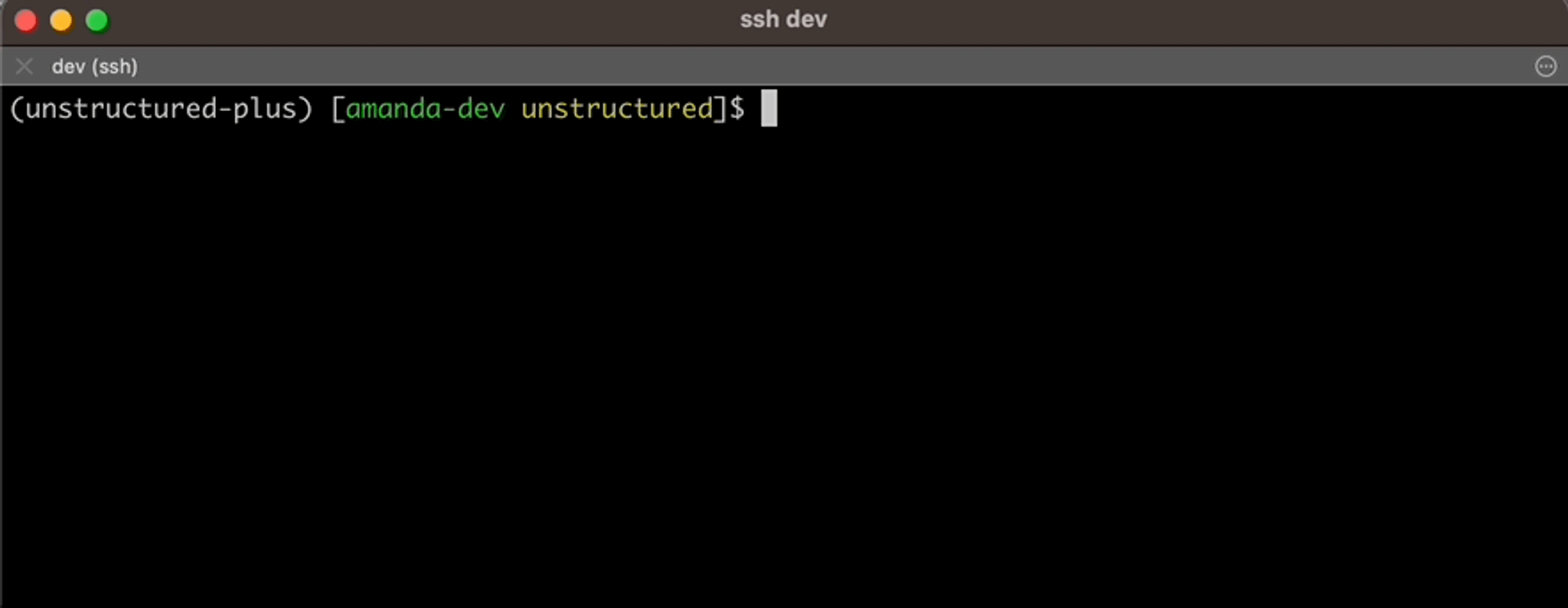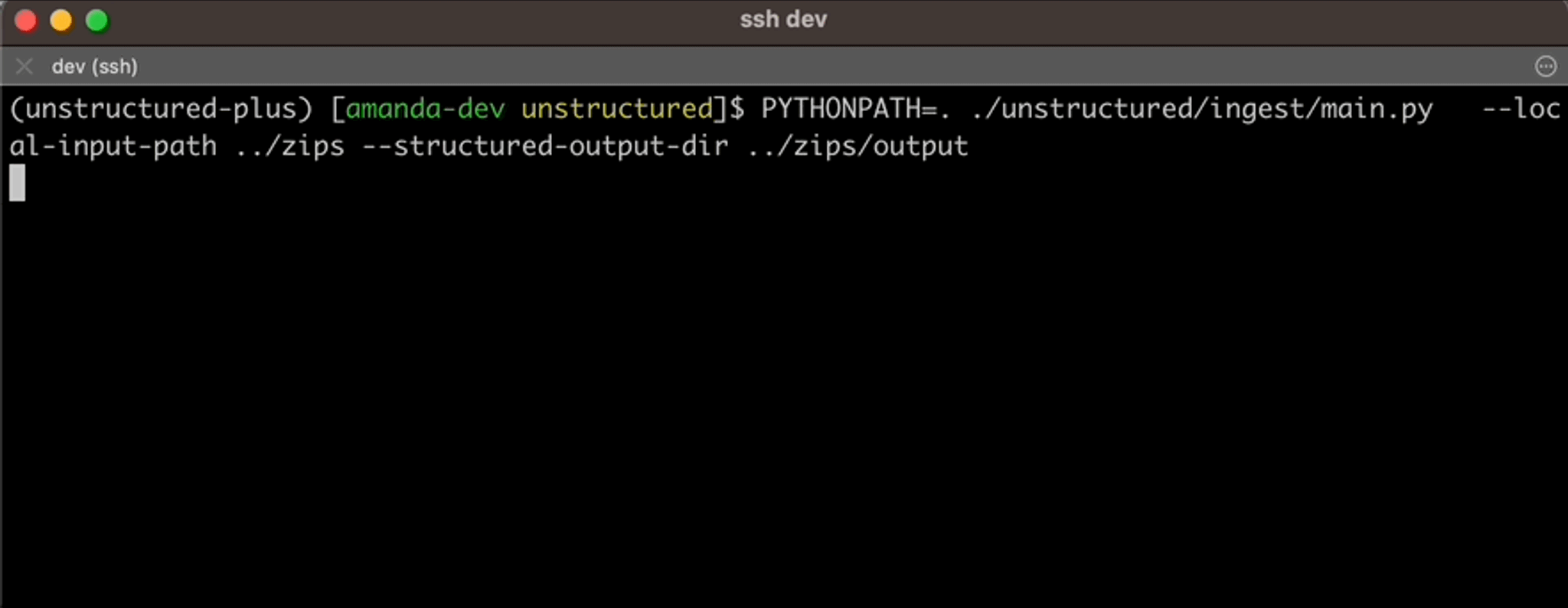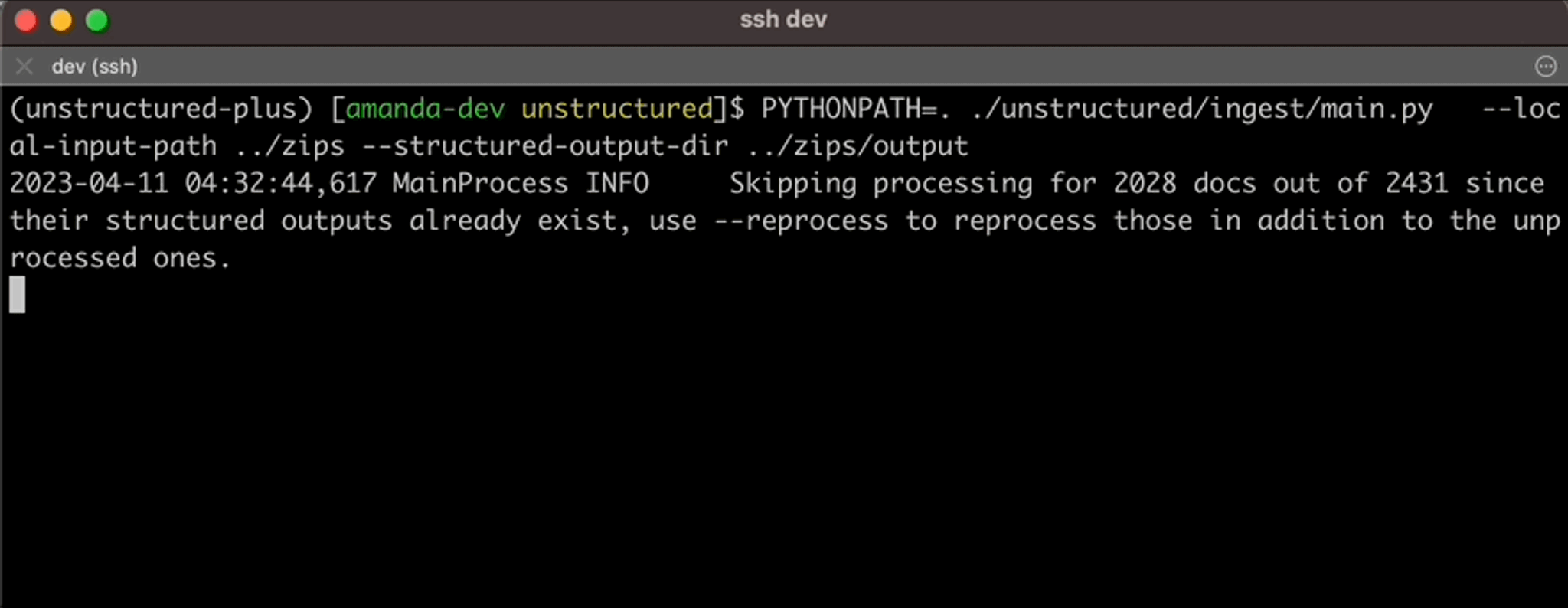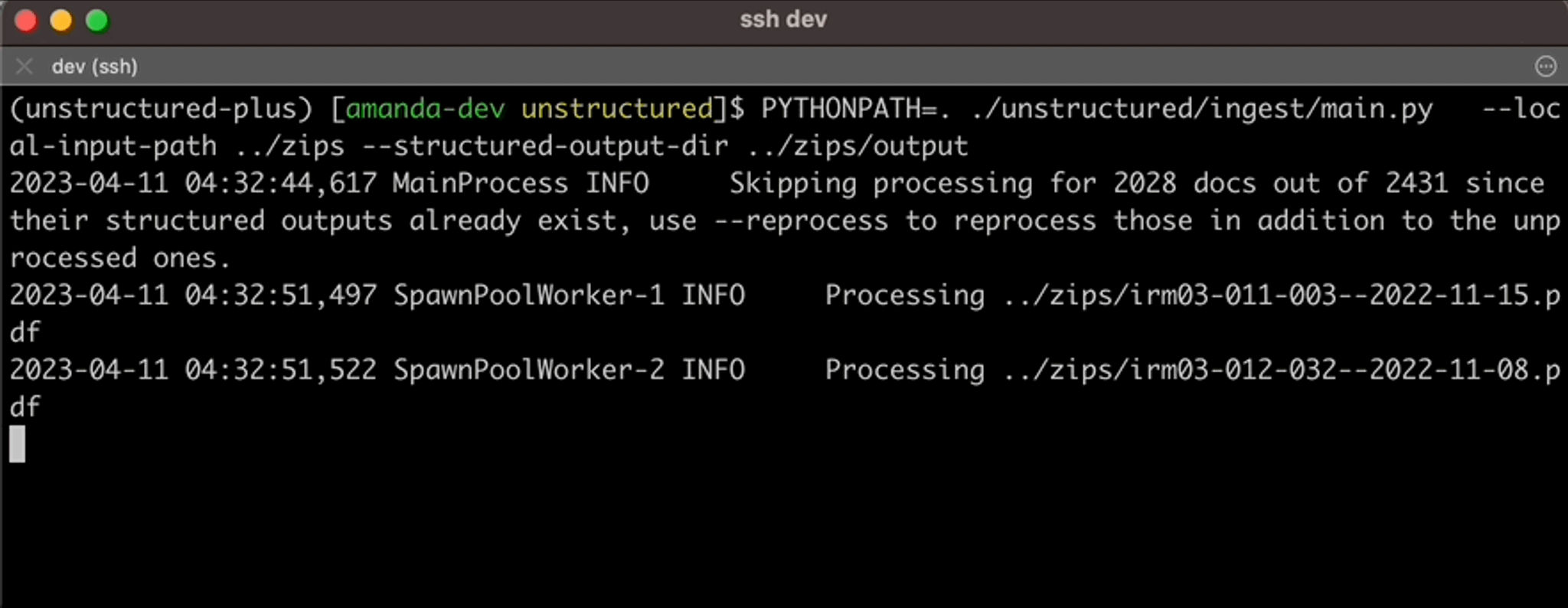
If you’re extracting data locally without using the API, you can increase throughput with the — num-processes parameter. E.g., 8 processes if running on hardware with 64gb available. Below is just one example of how Unstructured will transform the raw data into a structured JSON format.
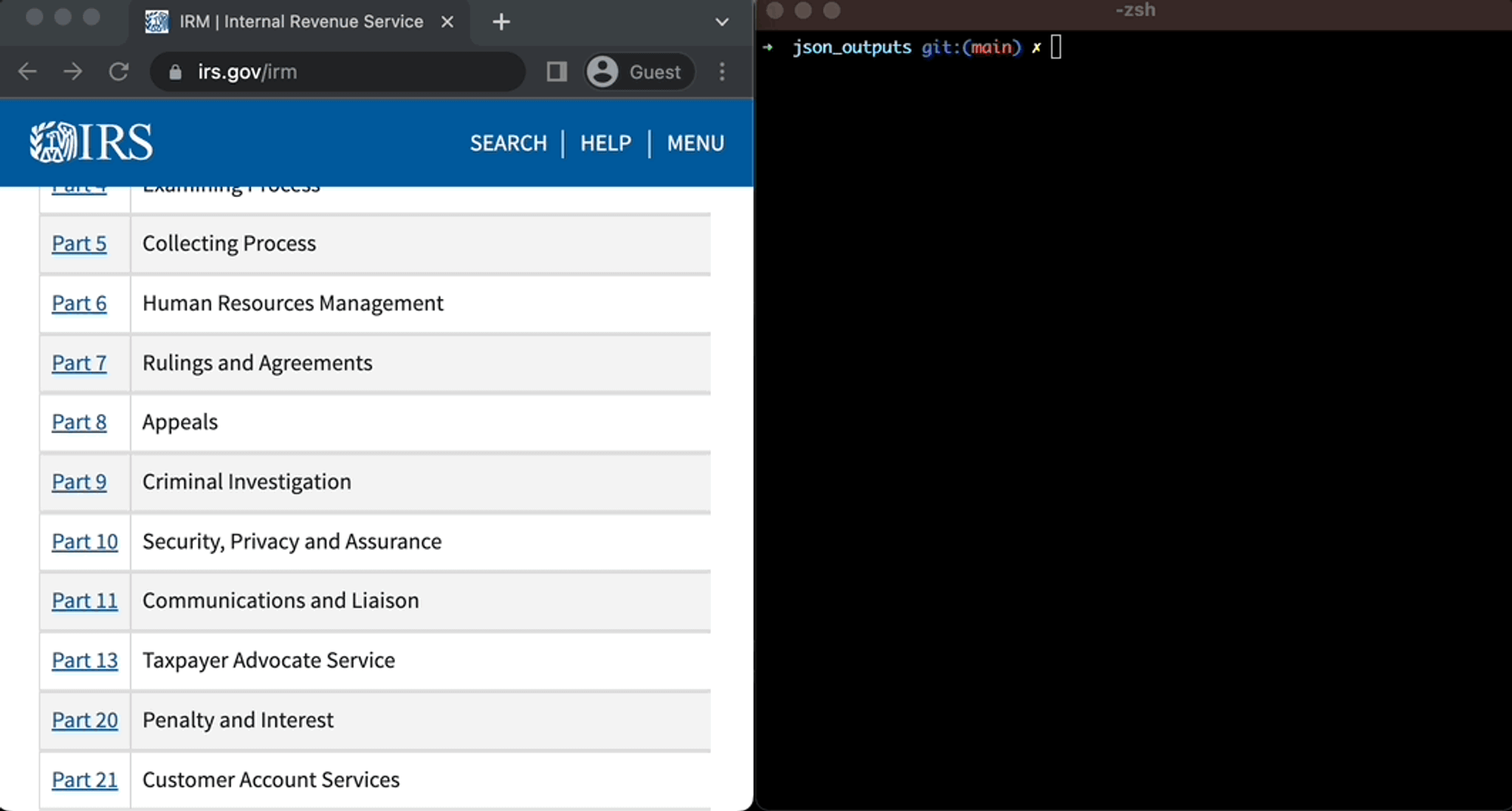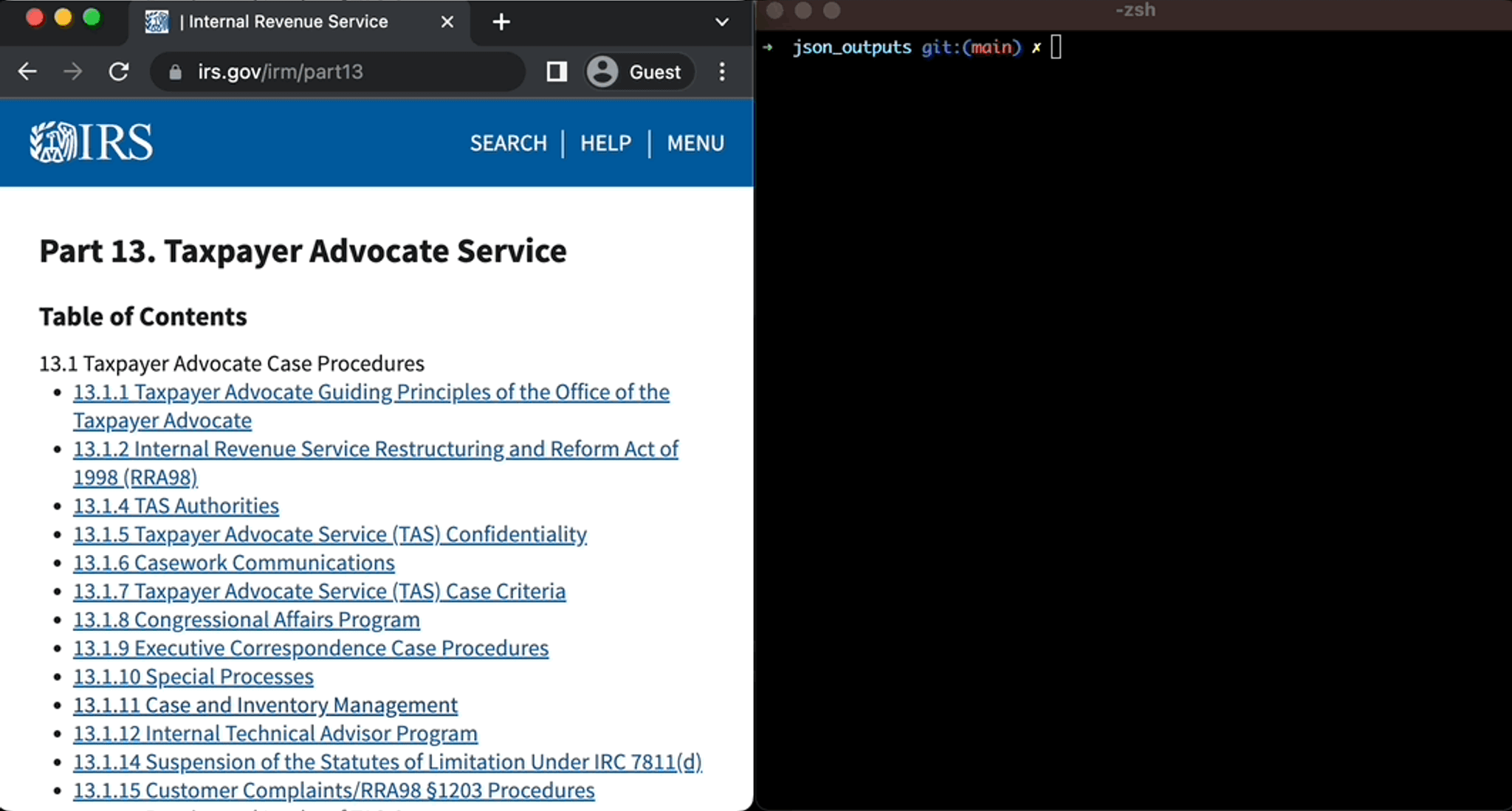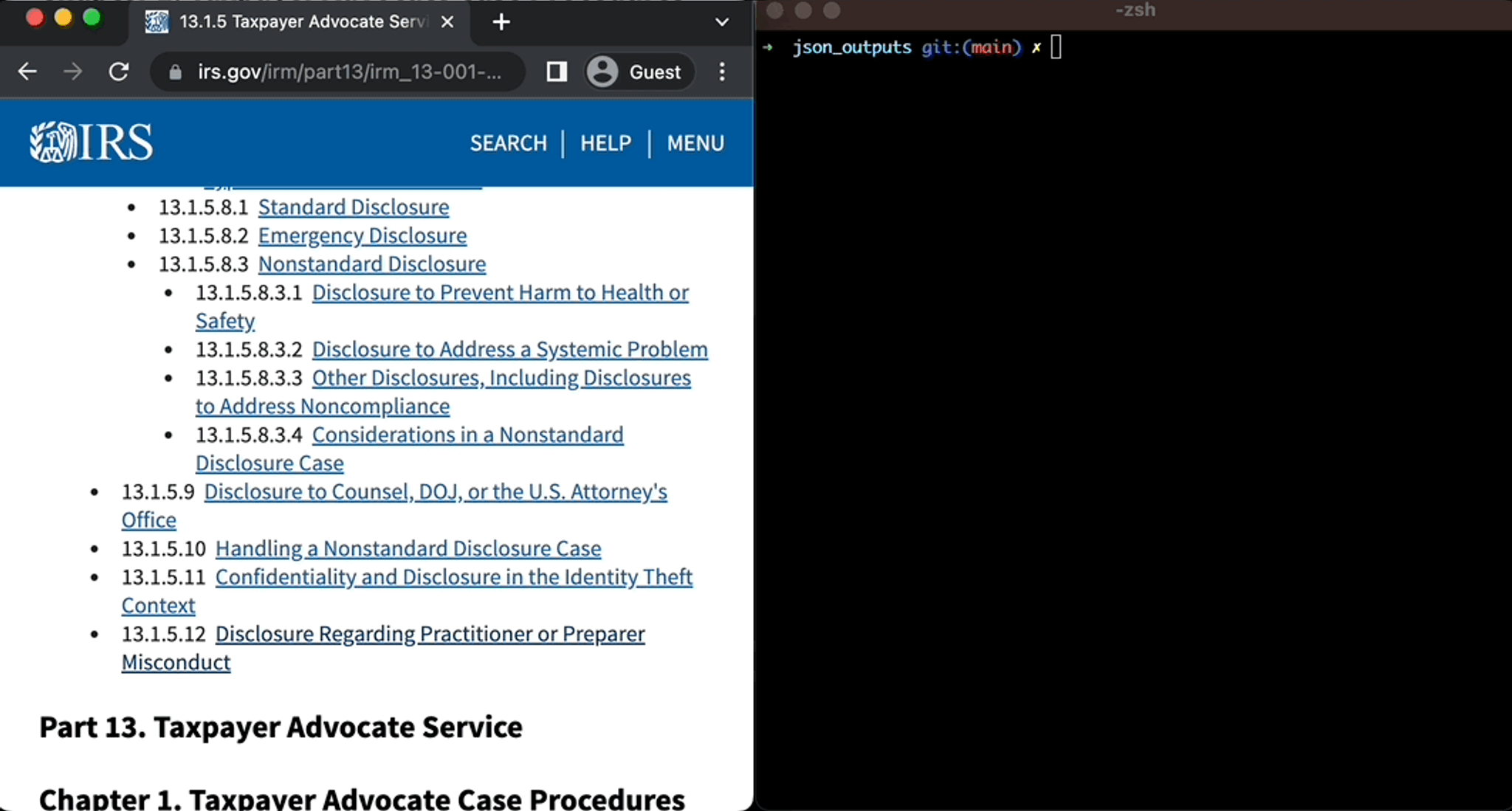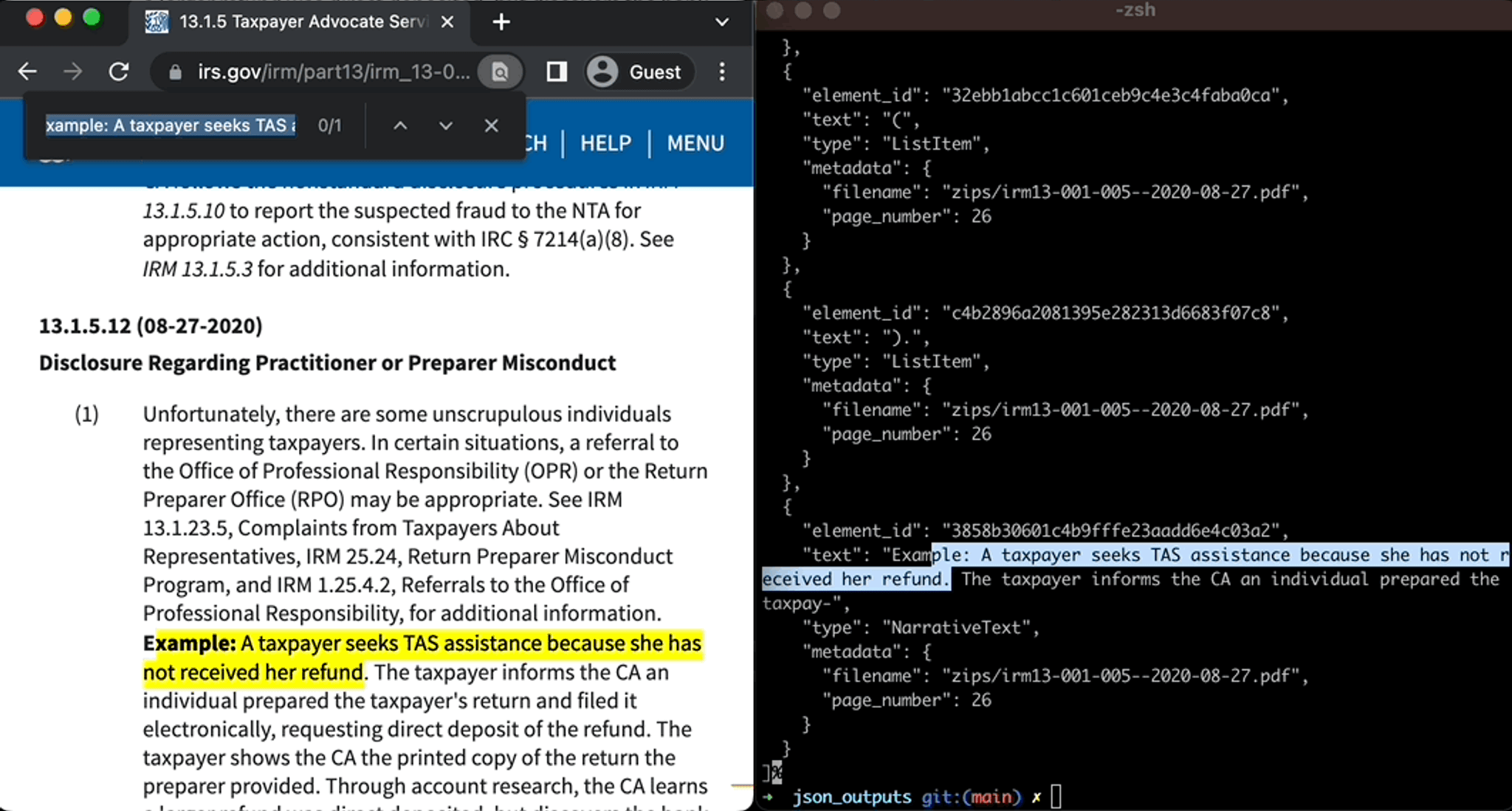
Once Your Data has Been Preprocessed Working with Structured Data
Once Unstructured has done the heavy lifting of converting the raw files to usable JSON, we can nest the preprocessed data within an architecture that allows an LLM to benefit from this organization-specific data.
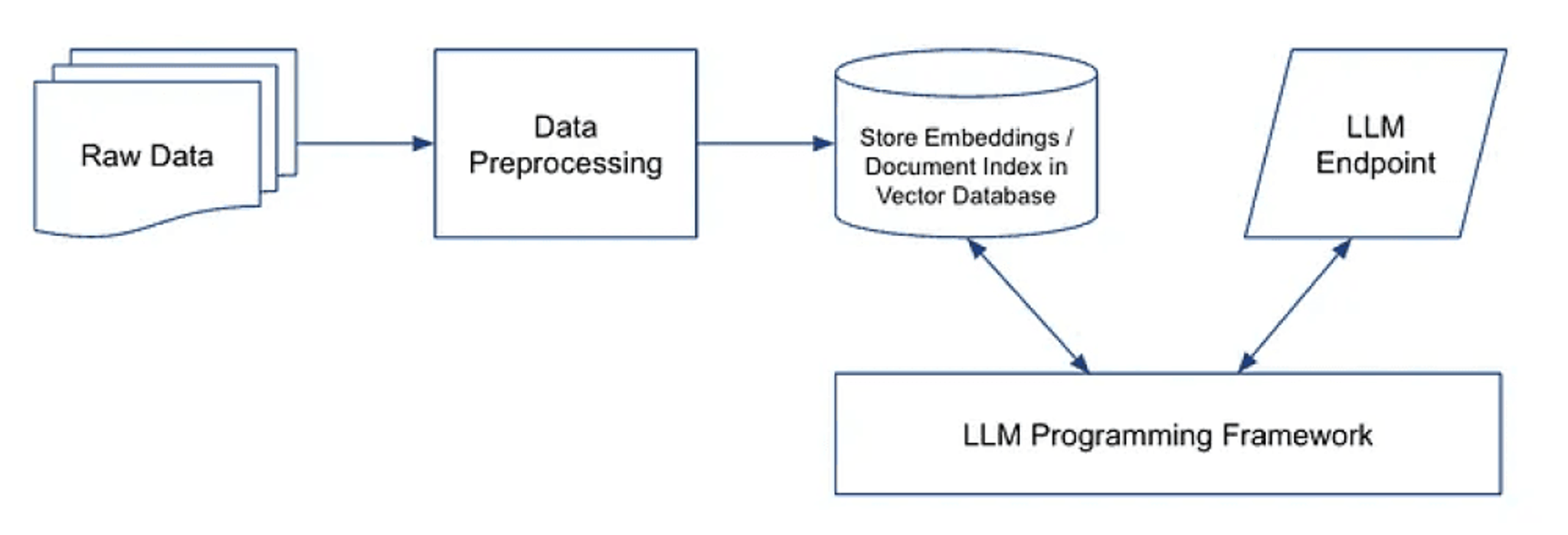
(For more detail on each of those make sure to checkout our article LLMs and the Emerging ML Tech Stackhere.)
For this particular project we tried out Pinecone for storage (we’ve also had great luck with Chroma, Weaviate, Qdrant, and others), OpenAI for embeddings and LLM (because it was easy…but we could have easily gone to Hugging Face to snag open source alternatives), and LangChain as a programming framework (Llama Index works great too!). Again it’s important to note that once we’re working with the preprocessed data it’s easy to experiment with different downstream libraries. For example, if hybrid search seems like a compelling way to go, it’d be easy to evaluate Llama Index and/or LangChain + Supabase.
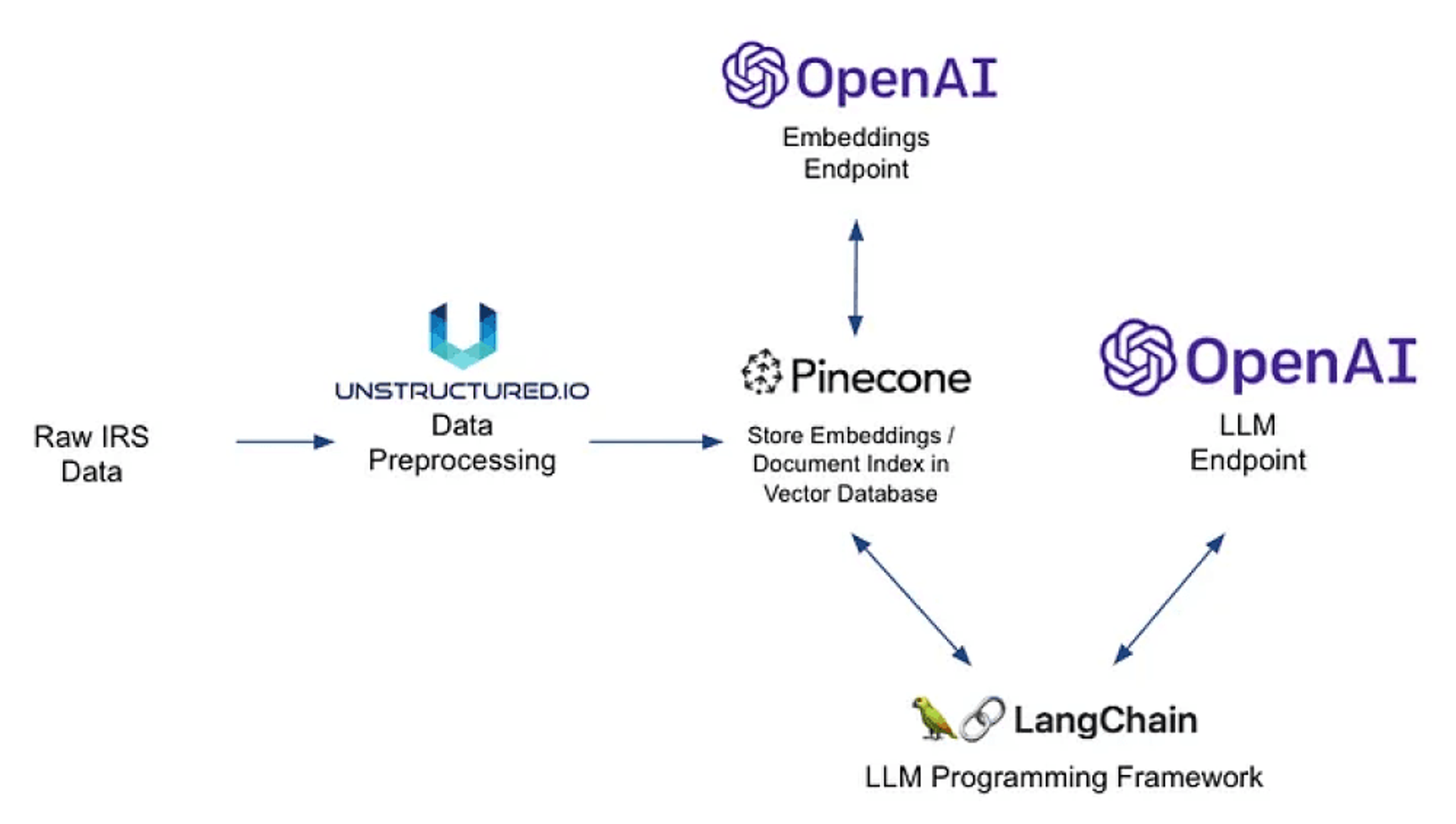
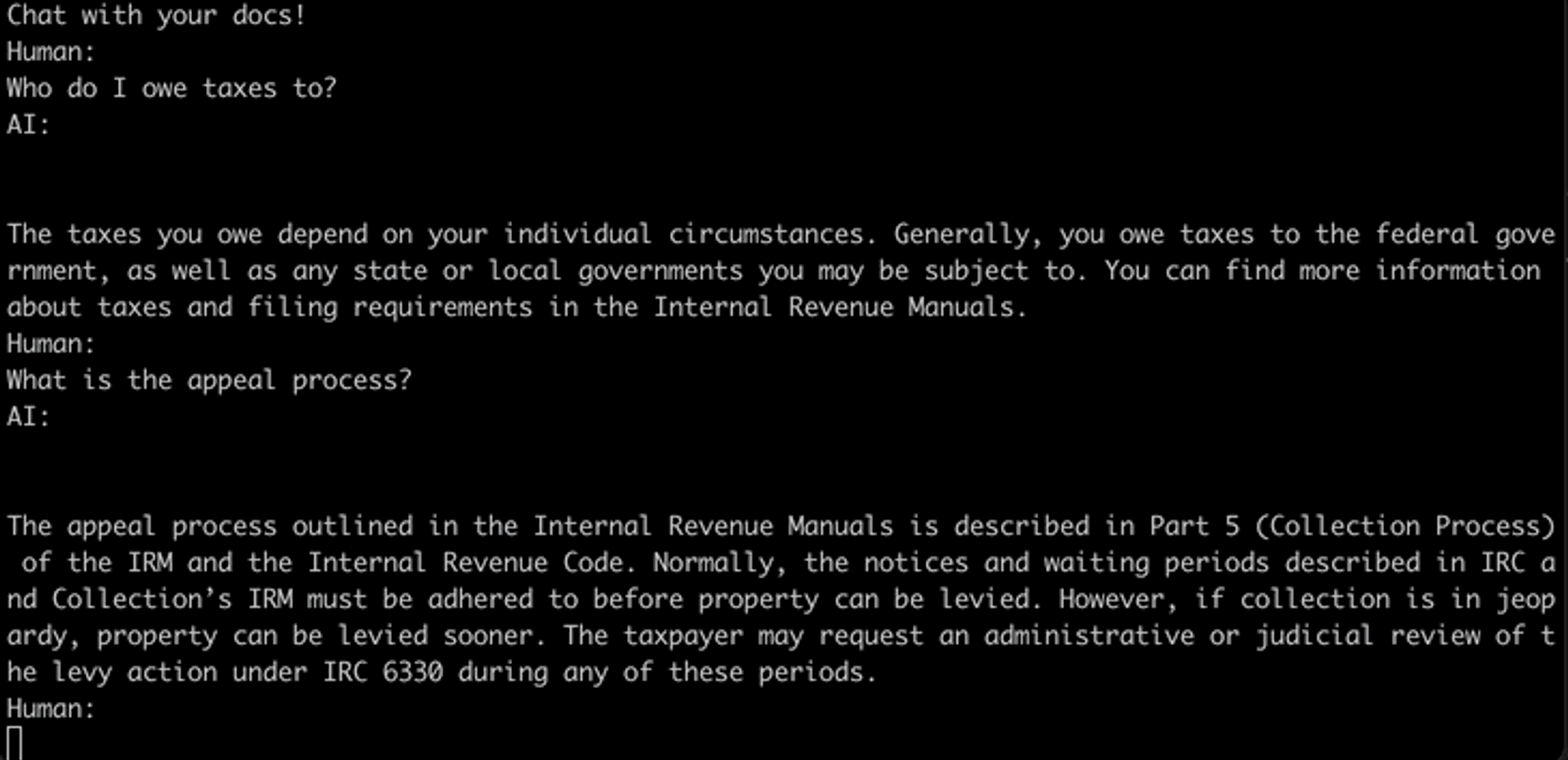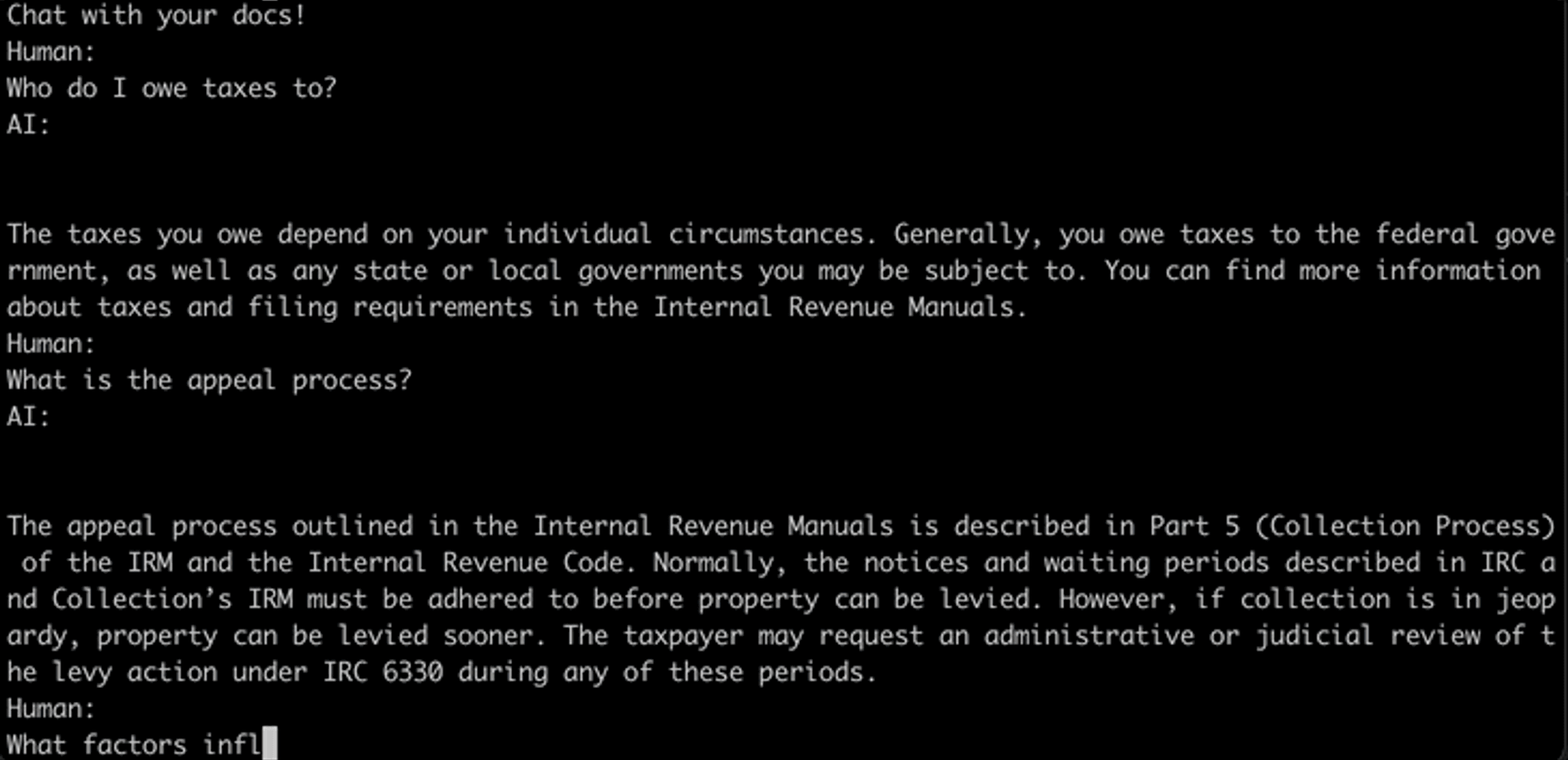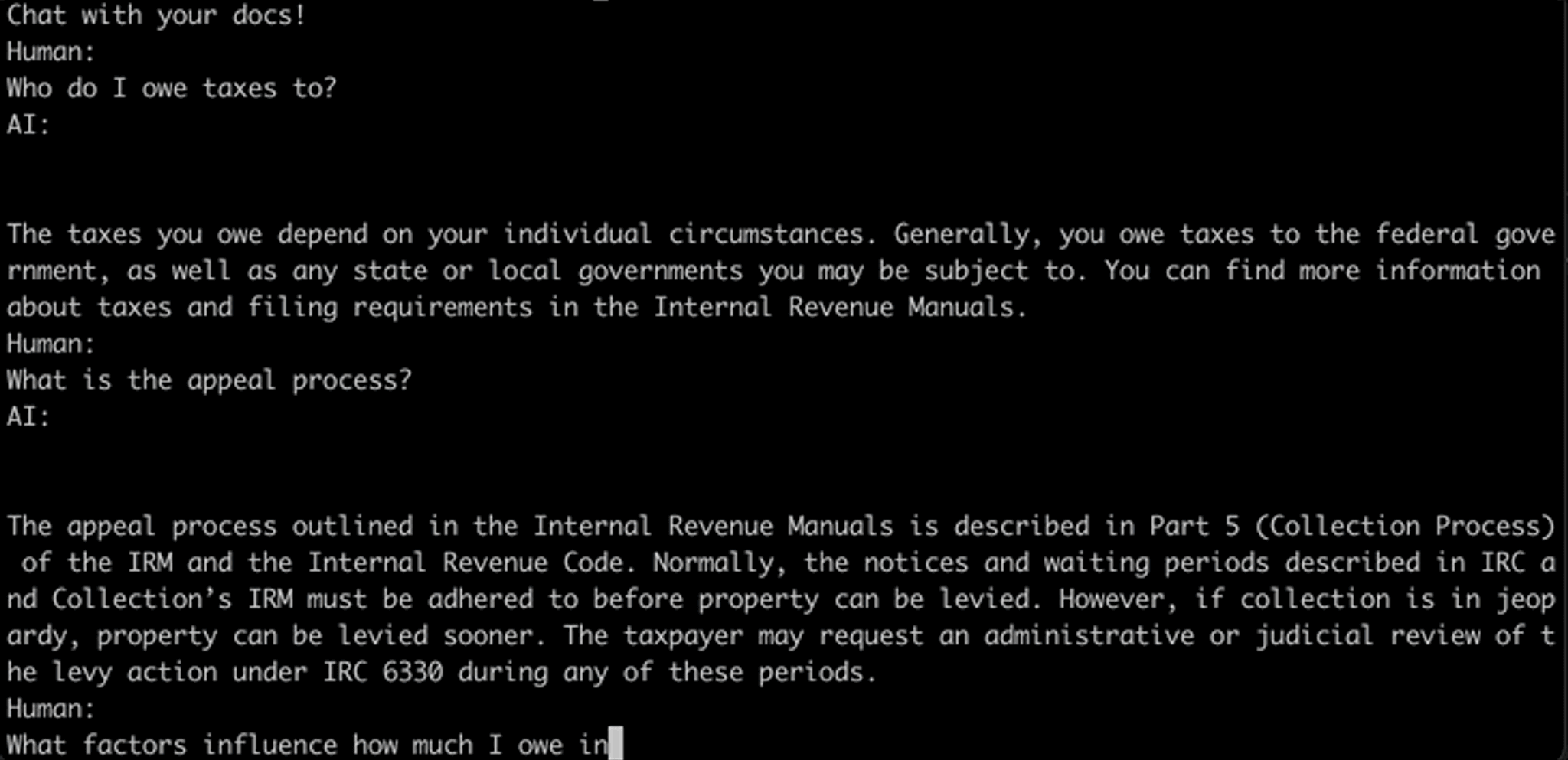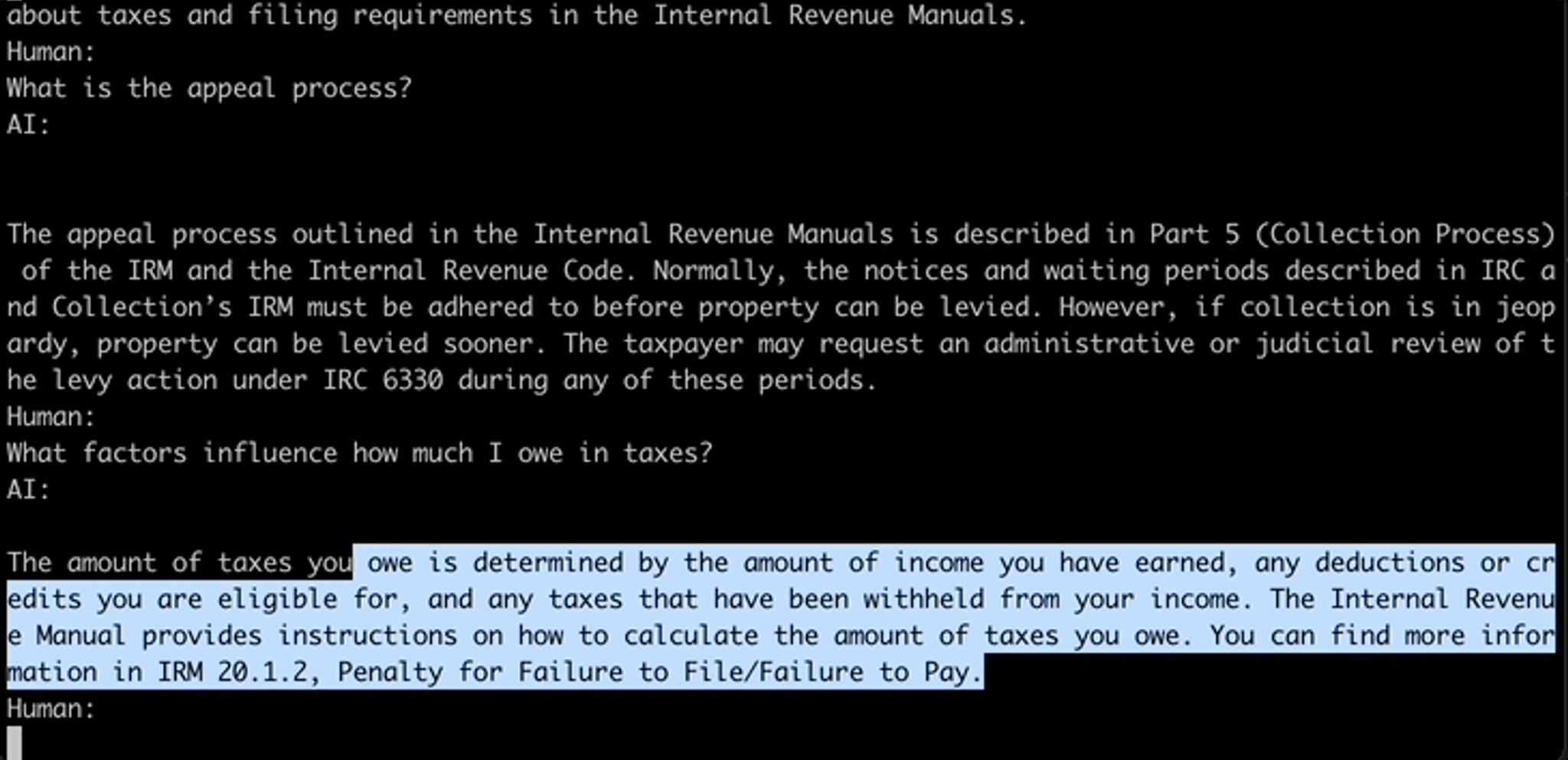
Chat Your IRS Data: We’re ready to field some questions!
Once the vector DB is populated with all 100k preprocessed documents and their corresponding embeddings, all we’ve got to do is query. Come one, come all to one of the two options below and bring all the musings you’ve ever had on IRS policy, procedure, and process.
Here are the two ways you can check this out for yourself.
- Our Hosted Instance
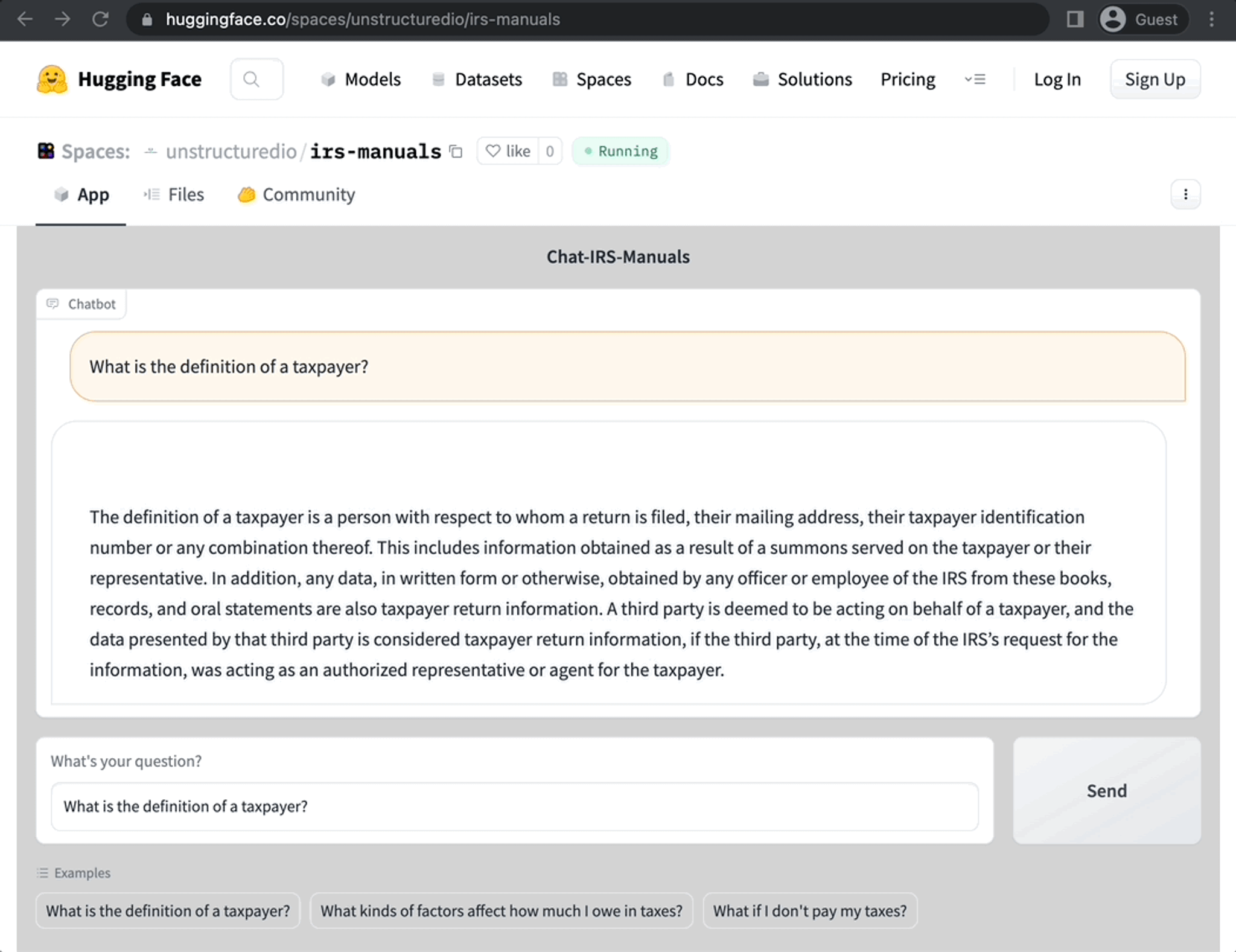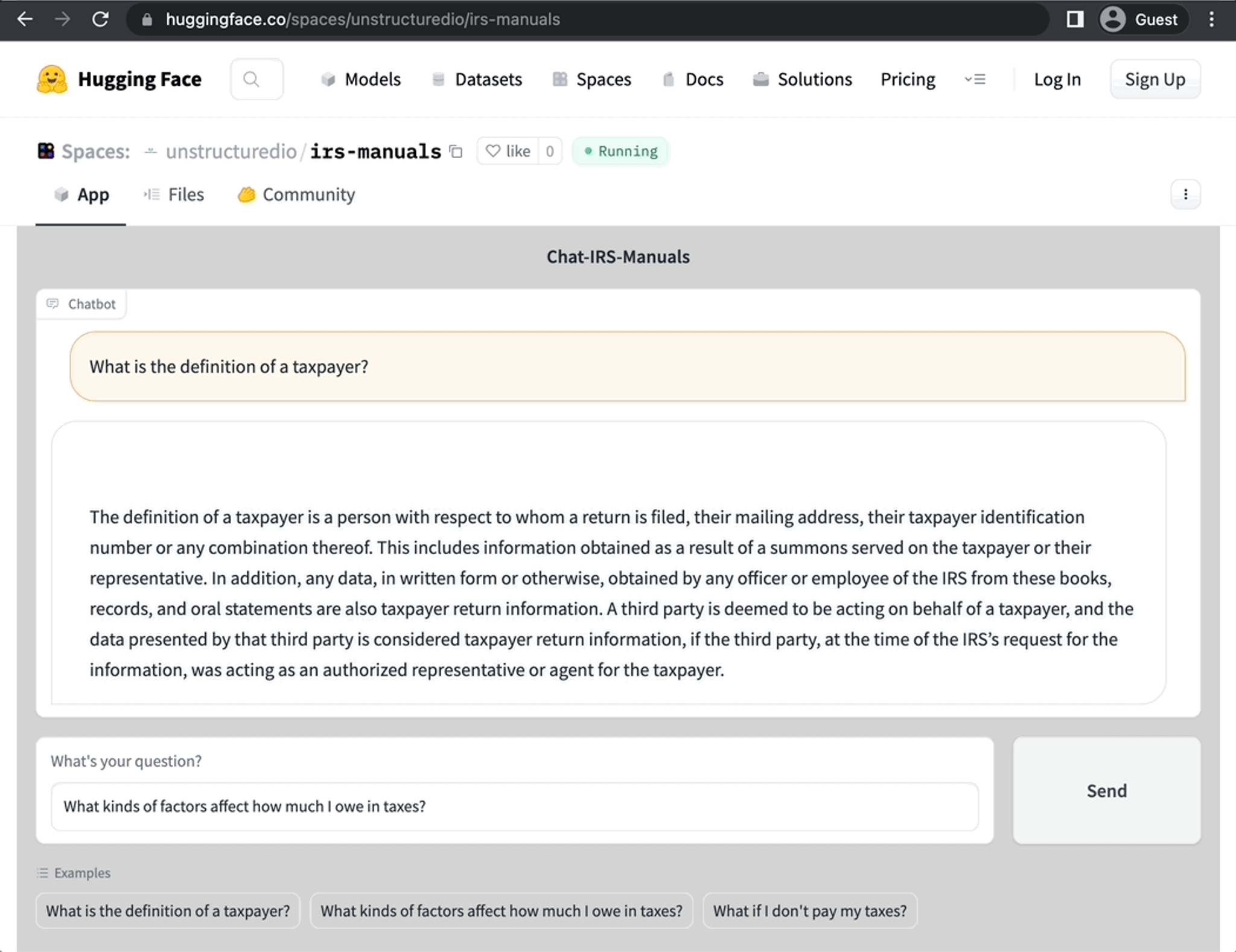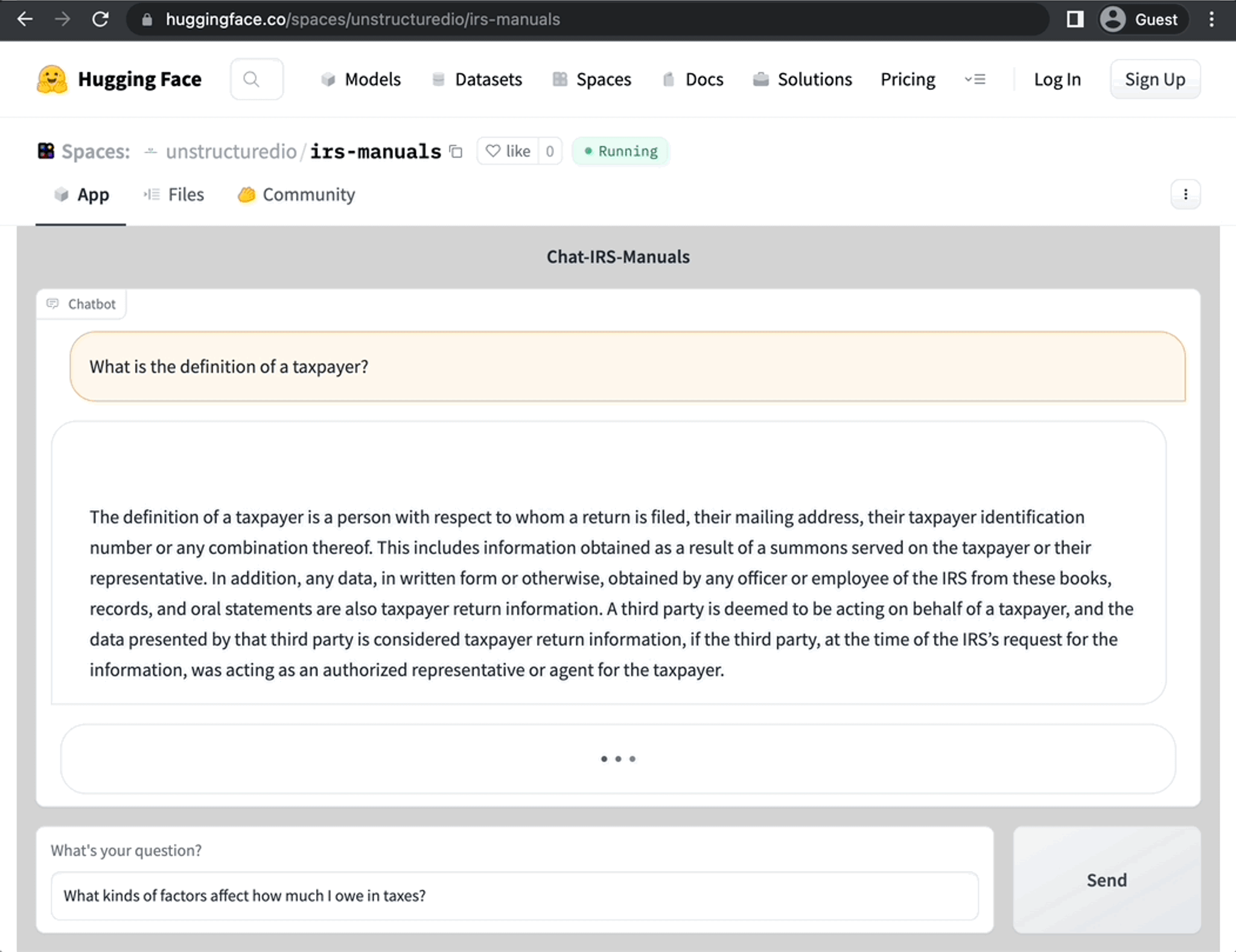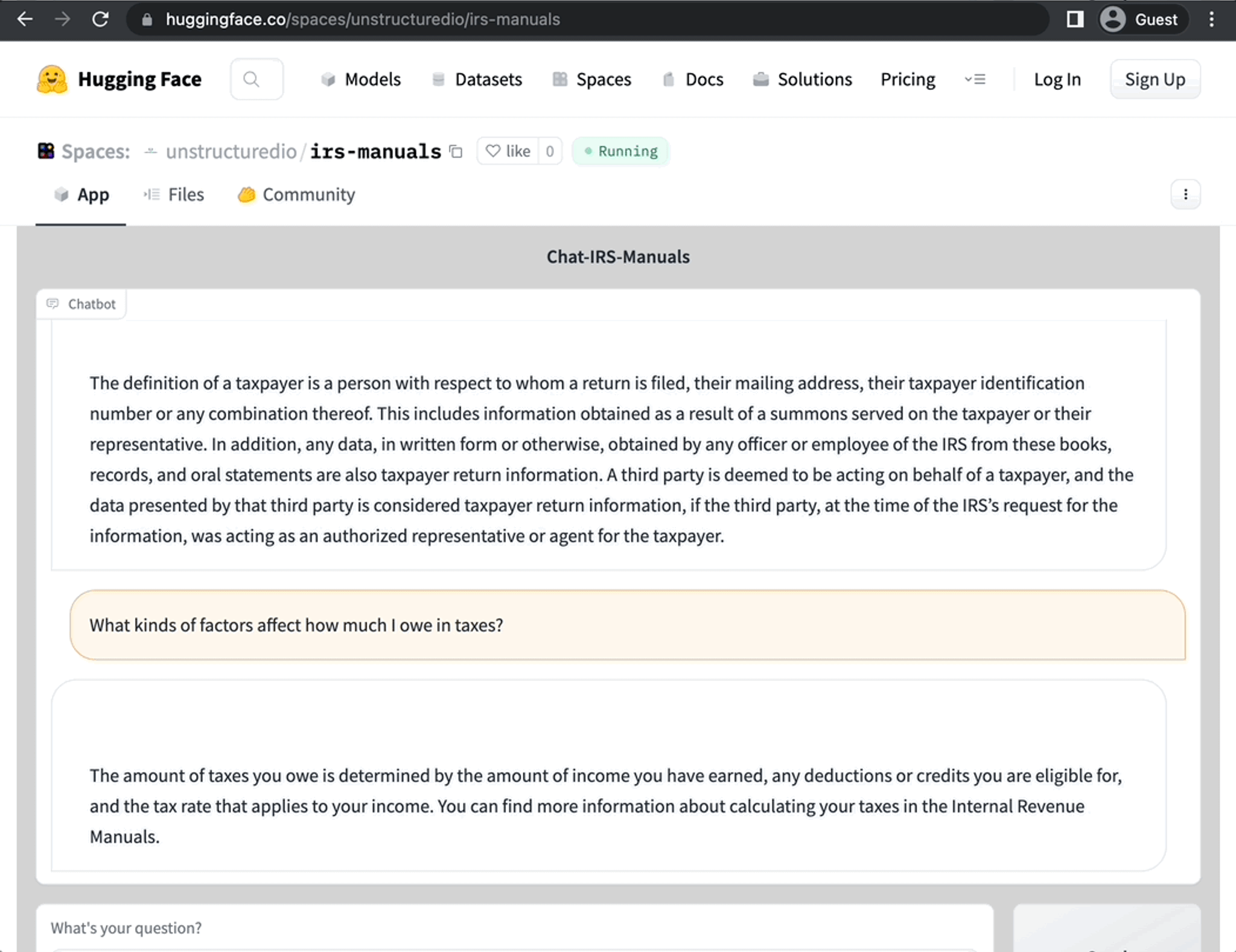
- Running the CLI app yourself
Next steps
Data is powerful, but only if we can make use of it. With Unstructured, we’re excited to help enterprises exploit their internal data with LLMs. We’re continually adding to our natural language preprocessing capabilities and expanding the number of data connectors we support. No matter where your natural language data resides or what file type its contained in, Unstructured has got you covered.
Github repo → Clone the demo repo and connect to your own data source
Community Slack → Join our growing community
Hosted Instance → Chat with the IRS Manuals yourself
Example questions for Chat Your IRS Docs:
- Are there regulations around email communication?
- What is the difference between federal and state tax?
- Who is the head of the IRS?
- How are penalties determined for late filings?
- Tell me about the Whistleblower Office
- tell me about Tax and Fingerprint Checks needed for experts
- What is the process of making an appeal?
- Tell me about Daily Delinquency Penalty
- When are taxes owed?
- Who has to pay taxes?
- How do I process amended tax returns?
- How do I investigate charitable contribution deductions?
- What kinds of tax credits are there?
- Do churches pay taxes?
- Tell me about form 709


