
Authors

Today we’re thrilled to announce Unstructured Serverless—the simplest, fastest, and most cost-effective way to render enterprise data AI-ready. Along with our new serverless infrastructure, we are deploying a host of enhancements including:
- New Signup Flow
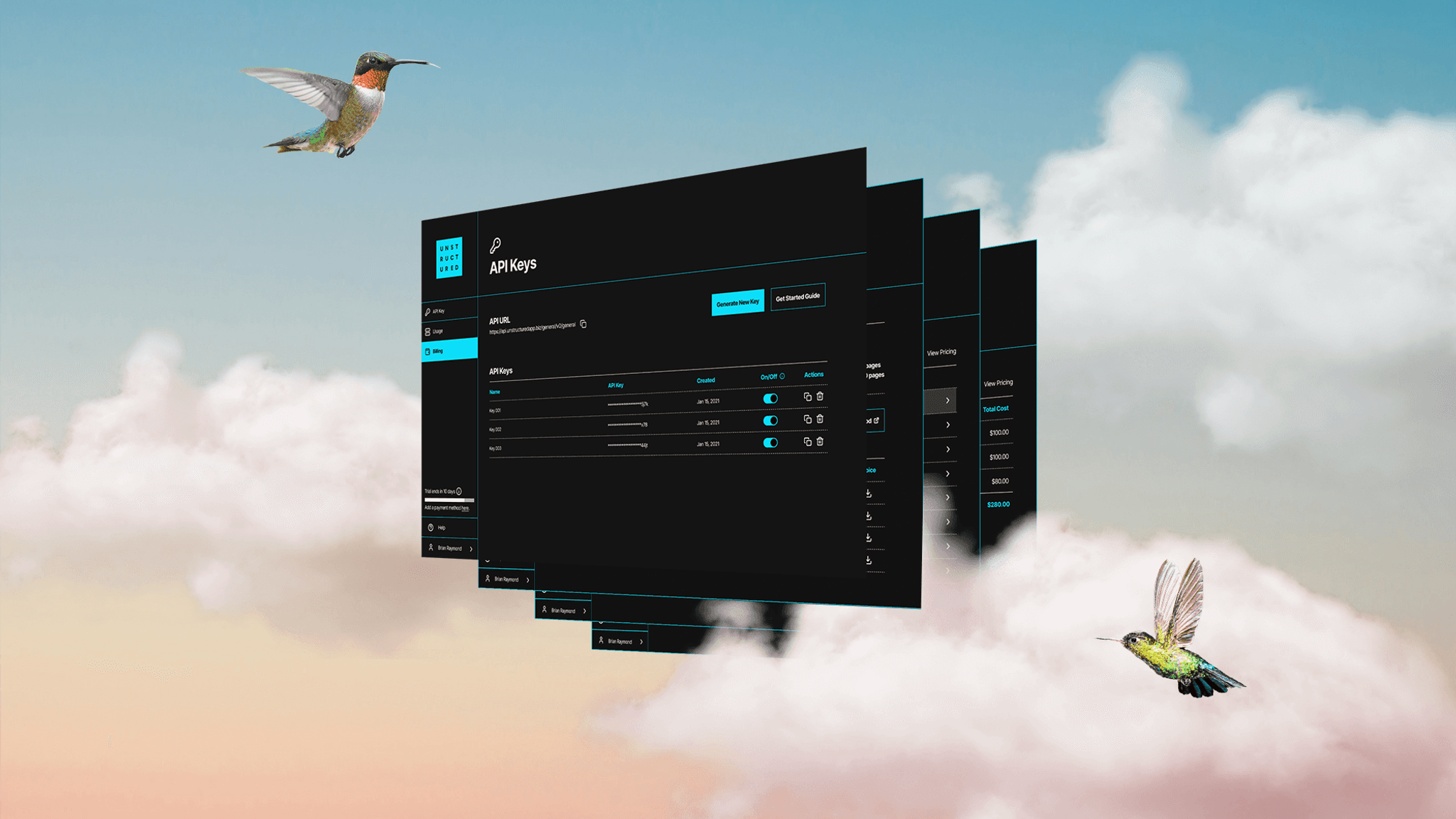
- New Admin Dashboard
- New Per Page Pricing Model to improve predictability and reduces cost
- 5x improvement in processing throughput for PDFs
- 70% improvement in table classification and structure detection
- 11% improvement in text accuracy
- 20% reduction in word error rate
- Multi-Region cloud hosting to improve resiliency
- SOC 2 Type 2 compliance
- Entirely new documentation
All available now—try it here!
Good Data = Good AI
It’s becoming increasingly clear that harnessing proprietary data through production AI workflows is going to be critical to companies’ long term competitive advantage. Over the past two years we’ve worked alongside leading enterprises and our developer community to deliver GenAI-ready data to power a wide range of AI applications spanning enterprise search to customer service agents.
As organizations move beyond prototypes and into production they require performant, resilient, scaleable, and secure tooling they can trust with their most important data workloads. It’s with this in mind that we’ve worked over the past several months to dramatically enhance our developer experience and the performance of our commercial API with a host of enterprise-grade features including SOC 2 Type 2 certification.
Throughout this journey we’ve been consistently reminded that what matters most to the success of production GenAI projects is good, clean data, and we’re committed to making it effortless to achieve this reality.
Improved Transformation Performance
Unstructured Serverless API leverages our next-generation document transformation models that deliver superior performance over our open source models along several key dimensions:
- 5x improvement in processing throughput for PDFs
- 70% improvement in table classification and structure detection
- 11% improvement in text accuracy
- 20% reduction in word error rate
Improved transformation and better document element classification helps deliver better LLM-enabled workflows across three critical areas:
- Developers can clean data by removing unwanted document elements (ie. removing headers and footers or images).
- Developers can more effectively utilize advanced chunking strategies. For example, developers can chunk by document element to identify document sections (ie. chunk by title).
- Developers can use metadata filtering to enhance retrieval by surfacing the most relevant data within a file at query time.
In addition to layering in AI-native processing capabilities, we’ve continued to advance our transformation pipelines by implementing traditional pre-processing techniques including hand crafted parsers, regular expressions, python libraries, and more. This has resulted in the fastest, most performant, and most cost effective solution on the market.
Improved Pricing
With Unstructured Serverless API, we are launching a per-page pricing model. In our initial launch in Q1 of this year we charged by compute hour. We quickly learned that this wasn’t the best approach for predictability and transparency. As a result, we’ve simplified our pricing to:
- Fast Pipeline: $1 per 1,000 pages
- Hi-Res Pipeline: $10 per 1,000 pages
- With the previous pricing model, processing 1,000 PDF pages costs $12.93.
- With the new pricing model, processing 1,000 PDF pages now costs $10.00.
There is no longer any charge to create infrastructure. It is always available.
Improved Startup Speed and Latency
Another advantage of our serverless infrastructure is that 99+% of requests have virtually zero startup time. Continuously online worker nodes reduce ramp up times from thirty minutes previously to under three seconds.
We have also made significant improvements to reduce latency in our preprocessing pipelines. With this release, we process documents 5x faster using techniques like document splitting, where each document is deconstructed and distributed to individual worker nodes for parallelized transformation.
Improved Developer Experience
Delivering a delightful developer experience is our number one priority. With this release, we have drastically improved our onboarding flow with a refreshed signup process, a new admin panel to manage API keys and track usage, and completely new documentation.
Good Data = Good AI
Since we released our commercial API, thousands of organizations have turned to Unstructured to carry their GenAI workloads. Unstructured Serverless offers better extraction performance and all of the benefits that come with SaaS software such as hosting, regular upgrades, scalability, reliability, and a managed SLA.
We cannot wait to see what you build with Unstructured Serverless. If you have any questions, we’d love to hear from you! Please feel free to reach out to our team through our Slack community.


