Authors

Trusted by 73% of the Fortune 1000
As companies productionize generative artificial intelligence (GenAI) workflows, they’re facing a data bottleneck. Their existing extract, transform, and load (ETL) solutions aren’t able to render raw unstructured data into large language model (LLM) compatible formats, which is forcing engineers to manually batch process their data. Unstructured solves this problem by continuously harvesting newly generated unstructured data, transforming it into LLM-ready formats using our optimized, pre-built pipelines, and writing it to downstream locations such as vector or graph databases. Unstructured delivers fast, high quality data transformations, empowering organizations to deploy GenAI solutions with greater speed and reliability. With an intuitive No Code user interface (UI) and API, Unstructured allows teams to effortlessly generate horizontal GenAI-ready data layers, maximizing impact.
Stand up and deploy GenAI ETL pipelines in less than five minutes using Unstructured. Running via No Code UI or via API, Unstructured automatically transforms complex, unstructured data into clean, structured data for GenAI applications. Data is routed through dynamic transformation and enrichment pipelines to deliver the highest quality output to your LLM. Automatically. Continuously. Effortlessly.
Introducing the Unstructured Platform
The Unstructured Platform allows you to effortlessly ingest data from your system of record to a destination of your choice. You can sign up in seconds. In minutes, you can configure your source and destination connectors. And in hours, you can have your data preprocessed and ingested into the destination of your choice. You can do all of your ETL (partition, chunk, and vectorize) with just a few clicks. And we incorporate the latest innovations in ETL, such as VLMs, into a configuration-free flow to process your data, so that you don’t need to do any work to have access to state-of-the-art models.
How it Works Under the Hood
Transformation & Enrichment
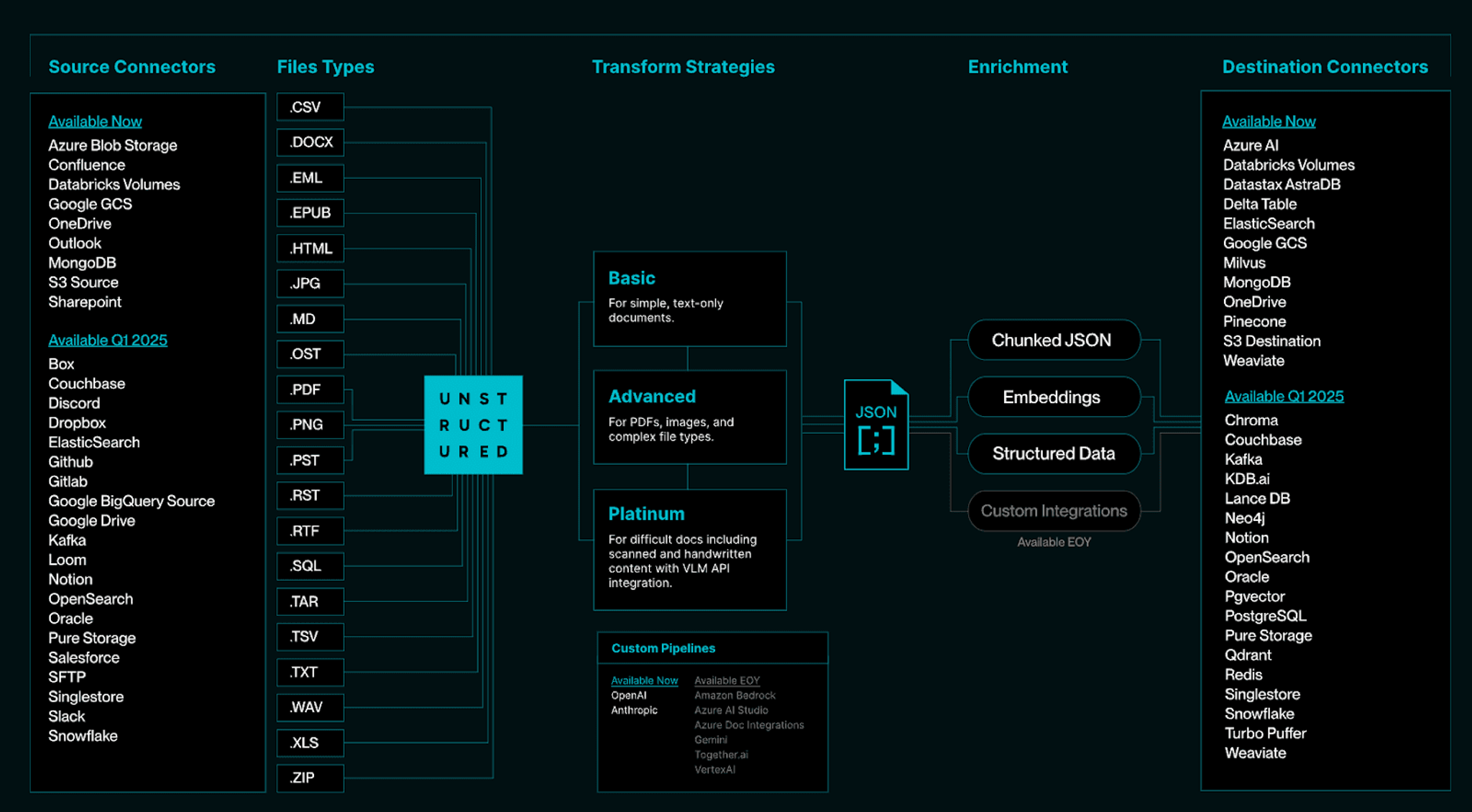
We heard your feedback and we have updated our transformation offerings considerably since our last product release. With three pre-configured options—Basic (ideal for simple, text-only documents), Advanced (best for PDFs, images and complex file types), and Platinum (perfect for the most challenging documents including scanned and handwritten content with VLM API integration)—you can’t get better transformation anywhere else, and you also don’t need to overpay by throwing a generative language model at a simple document. We offer one click options to streamline any of these pipelines, as well as an option to customize workflows to meet your specific requirements.
Our generative approach offers you the flexibility to work with the best VLMs for data transformation. Currently, we support OpenAI GPT-4o and Anthropic Claude Sonnet 3.5, with plans to expand to additional options, including models from AWS Bedrock, Together AI, and many more. While our team optimized the VLM prompts for seamless integration, prompt customization will be available in the near future to support your specific use cases or data requirements. For transformation, enrichment, and embedding, we ensure smooth connectivity with leading model providers and continue to expand our integrations to give you more choices over time.
At the heart of our service, we provide a range of optimized ETL workflows designed for different document types. These options are ideal for users who are just getting started or have basic needs. At the same time, we provide extensive customization possibilities for users who want to experiment and tweak their ETL pipeline to fit their exact requirements. Our smart chunking strategies are designed to handle diverse use cases, and we also provide options to customize chunking parameters, ensuring adaptability.
Connect & Orchestrate
Do you have data across multiple sources, with destinations that have very specific and often changing requirements for ingestion? Did you know that it’s much easier to build a connector than to maintain it in a production system over time? We’ve got you covered! With over 50 source and destination connectors, we have taken on the challenge of maintaining the connectors and documentation so that you don’t have to worry about it. We’ve also architected our connectors to automatically detect and process only new data, so you don’t need to monitor new data coming in.
Most GenAI projects start with an API key scavenger hunt: you need a half dozen to capture the full pipeline. And a similar scavenger hunt to find out the ultimate cost of the project. We maintain and facilitate all of these third party API integrations, so you don’t have to worry about billing, uptime, or latency concerns. And you don’t need to go through all the setup to get a new API key to try a new embedding provider, we will seamlessly integrate it for you as part of our platform’s orchestration.
Enterprise Features
With our extensive experience working with enterprise customers, we have provided a number of enterprise features to ensure security and compliance. We are SOC 2 Type 2, HIPAA and GDPR compliant. We will also have advanced admin controls so that you can control which users in your organization have access to which data. And in addition to our SaaS Hosted offering, we provide an option to deploy in-VPC so that your data never leaves your ecosystem.
With privacy, sovereignty, and safety top of mind, we have architected our Platform offering with a “control plane” and a “data plane,” allowing us to offer advanced orchestration capabilities without compromising on data management best practices. Our data plane component allows customers to select where their data flows are processed (including in their own VPC or On Prem), which can reduce latency and cloud costs. Layered on top of this is a control plane, which handles orchestration tasks like scheduling and overall workflow definitions. The control plane is designed to never touch the data that flows in the data plane—even file names! Additionally, this architecture enables horizontal scale-out for virtually unlimited throughput. When customer workflows need to connect to sensitive data stores, the data plane needs authentication credentials. Our control plane is written to automatically encrypt these credentials before they leave your browser with a personal encryption key not shared by any other customers, and they are only ever decrypted just-in-time within the data plane. Worldclass Transform & Orchestration
How to get Access to Platform
We can’t wait for you to get going with the Unstructured Platform! Click here to sign up and try Platform for free.
FAQ
Q: How is Platform different from Serverless API?
A: By the end of this year Platform will offer the same features as the API and more, and eliminate the need to configure complex data processing scripts. Instead, you'll be able to build all of your pipelines in a user-friendly UI.
Q: What happens to the current Serverless API?
A: The new Platform API will replace the current Serverless API, offering backward compatibility with Ingest workflows and enhanced features like out-of-the-box VLM-based partitioning. Existing source and destination connectors will remain accessible, with more capabilities planned. Starting in January, a dedicated SDK will simplify integration. Legacy Serverless users can continue using the current API until full functionality is available on the Platform.
Q: I like using your open source software, why should I try this new Platform?
A: If you like our OSS you will love Platform. OSS is great for experimenting, and Platform is perfect for production-ready AI workloads.
Q: How can I try the Platform?
A: Sign up here, and start building your workflows! If you need help, check out the extensive documentation or reach out to us!
Q: What kinds of documents can I process with the Platform?
A: Check out the full list of supported document types in our documentation.
Q: How do I know my data is secure?
A: We’re SOC 2 Type 2 certified, HIPAA compliant and GDPR-ready. We also offer in-VPC deployment for complete data sovereignty.
Q: What if I need help getting started?
A: No problem! We are here to help. Drop us a note here and we’ll get in touch.


