
Authors

Let's be honest, PDFs are a bit of a paradox in the developer world. They're fantastic for ensuring documents look the same everywhere, preserving visual fidelity across platforms. But when the task is to extract structured, usable data from them? That's where the "love" part often fades, and the "hate" (or at least, a strong sense of frustration) kicks in. If you've ever found yourself wrestling with code to reliably pull out text snippets, make sense of tables, or even just differentiate a header from a paragraph, you're definitely not alone. By its very design,PDFs prioritize visual representation for human eyes over machine-readable structure.
If you're tired of this wrestling match, this guide is for you. This first part of our two-part series focuses on the crucial first step: understanding what it means to parse a PDF and how Unstructured delivers clean, structured document elements as the output. If you're looking to see how messy PDFs can be deconstructed into usable building blocks for downstream applications – whether that's feeding a RAG system, performing extraction tasks, or powering any other AI-driven feature – you're in the right place. In Part 2, we'll dive into the different strategies Unstructured employs to achieve this transformation.
The Technical Hurdles: Why Are PDFs So Tricky?
So, what makes programmatic PDF parsing such a formidable challenge? While parsing these PDFs, you may frequently encounter a range of tricky issues:
- Chaotic Layouts & Mixed Content: PDFs often feature multi-column text that can abruptly break for an image or a table. Headers and footers might blend seamlessly with the main content if you're only looking at raw text. A single page can be a jumble of text blocks, rasterized images, vector graphics, and tables—sometimes drawn with lines instead of being properly structured elements.
- The OCR Gauntlet: Many PDFs are essentially just images of text, especially if they've been scanned. This immediately throws you into the world of Optical Character Recognition (OCR), which comes with its fun: dealing with low resolution, skewed pages, handwritten/scanned text, diverse fonts, and potential inaccuracies.
- Formatting as Meaning: Visual cues are rich with semantic information for humans. Bold text often indicates a section heading, italics might signal emphasis or a citation, and changes in font size can denote a clear hierarchy. When it's not explicitly defined in the PDF structure, capturing this semantic value programmatically is a significant hurdle.
- The Missing Semantic Layer: Unlike well-structured HTML with its clear semantic tags (<h1>, <p>, <table>), most PDFs lack a readily available, machine-readable map of their content's meaning and organization. We're often left to infer structure from visual presentation.
What This Part Will Cover: Understanding the Blueprint of Your PDFs
This first part of our guide is dedicated to demystifying the output of PDF parsing with Unstructured. We'll focus on how Unstructured transforms complex PDFs into a structured and understandable format. Specifically, we will dive into:
- The Anatomy of Parsed PDFs: Gain deep insights into what you get back after Unstructured processes your document – a consistent, element-based representation.
- Introducing Document Elements: Learn how Unstructured breaks down PDFs into meaningful 'elements' like Title, NarrativeText, Table, Image, and more, forming the building blocks of your data.
- Accessing Your Parsed Data: We'll briefly show you how to get these elements using both the Unstructured API and the user-friendly UI.
- A Tour of Element Types: Discover the variety of document elements Unstructured can identify and how they help preserve the original document's semantics.
- Bringing Elements to Life: See practical examples of how to work with these elements, including visualizing their positions on the original page and accessing their content (like image data or table structures in HTML).
Our goal for this part is to equip you with a clear understanding of the rich, structured data Unstructured outputs, setting the stage for Part 2 where we'll explore the different strategies to generate these elements.
Getting Started with Unstructured for PDF Parsing
At a high level, Unstructured provides a platform that transforms difficult-to-process documents like PDFs into a structured list of document elements – AI-ready building blocks. Unstructured goes beyond simple text extraction to understand the content and context of these elements, which we'll explore in detail in this part.
Unstructured offers the Unstructured UI and the Unstructured API. Depending on your background, they’re both very powerful channels to set up your document processing pipeline.
Method 1: The Unstructured API
Use scripts or code. Integrates seamlessly into your app. Production-ready. Pay as you go.
The API's Workflow endpoint allows you to build, run, and maintain complete workflows, or if you’re just looking to rapidly prototype using Unstructured’s various partitioning strategies, we also have a Partition endpoint.
Let’s use the Partition Endpoint to quickly parse a PDF with the API.
Prerequisites:
- An Unstructured API Key (from your existing Unstructured account)
- Grab your nearest PDF file
Install the Python SDK
pip install unstructured-clientimport os, json
import unstructured_client
from unstructured_client.models import operations, shared
client = unstructured_client.UnstructuredClient(
api_key_auth=os.getenv("UNSTRUCTURED_API_KEY")
) # Instantiate the API client using your API key.
filename = "PATH_TO_INPUT_FILE"
req = operations.PartitionRequest(
partition_parameters=shared.PartitionParameters(
files=shared.Files(
content=open(filename, "rb"),
file_name=filename,
), # input file
strategy=shared.Strategy.VLM, # use our SoTA VLM strategy
vlm_model="gpt-4o", #VLM of choice
vlm_model_provider="openai",
languages=['eng']
)
res = client.general.partition(
request=req
)
element_dicts = [element for element in res.elements]
# Print the processed data's first element only.
print(element_dicts[0])Alternatively, if you prefer a no-code approach or want to quickly experiment visually, the Unstructured UI offers an intuitive way to build your pipeline. We've got you covered there too.
Method 2: The Unstructured UI
No-code user interface to build a powerful document processing pipeline. Pay-as-you-go platform. Very intuitive, even more accessible.
Prerequisites:
- Have an Unstructured account
- Grab your nearest PDF file
Interactive Workflow Builder
The recently introduced Interactive Workflow Builder enables rapid experimentation with different pipelines, providing immediate feedback on how Unstructured interprets your documents. This feature allows you to drag and drop local files (or select from preloaded examples spanning catalogs, newspapers, and more) and instantly view how your configured workflow transforms the document, all without setting up complex pipelines. It's the perfect tool for understanding the platform's capabilities before implementing full-scale automated workflows.
While traditional Unstructured workflows are designed to be "created and forgotten about"—automatically processing documents from source locations and indexing them into preferred destinations in a scheduled manner—our interactive demo focuses solely on the transformation step.
Setting Up Your Interactive Workflow
Creating a document processing workflow with Unstructured is straightforward. Here's how to get started:
- Access the Unstructured platform and navigate to the Workflow creation interface.
- Configure your transformation strategy. For example, selecting a strategy like 'Hi-Res' (which we'll explore in detail in Part 2) is often a good starting point for many PDFs to see detailed element output.
- Upload your document by dragging and dropping the PDF file into the source node.
- Hit the “Test ▶” button to kick off the workflow!
Interpreting the Results
The Universal Output: A List of Document Elements
Regardless of the path you took (API or UI), Unstructured hands you back a consistent, developer-friendly format: a JSON object containing a list of "elements." Each element in this list represents a distinct, semantically identified unit of your original document.
{'type': 'NarrativeText',
'element_id': '3f8870ba99a8b8f50df96df7dd8b9f5b',
'text': "The Transformer was proposed in the paper Attention is All You Need. A TensorFlow implementation of it is available as a part of the Tensor2Tensor package. Harvard\u2019s NLP group created a guide annotating the paper with PyTorch implementation. In this post, we will attempt to oversimplify things a bit and introduce the concepts one by one to hopefully make it easier to understand to people without in-depth knowledge of the subject matter",
'metadata': {
'filetype': 'application/pdf',
'languages': ['eng'],
'page_number': 1,
'filename': 'jalammar-github-io-illustrated-transformer-.pdf'}}Why is This Element-Based Approach So Powerful?
- Structure is King: By breaking the document into these semantic elements, you retain much of the original document's logical structure. You're not just getting raw text; you're getting text with context. A Title element clearly has a different role than a NarrativeText element that falls under it.
- Granular Control: You can iterate through these elements, filter by type (e.g., "give me all Table elements"), or process them differently based on their category.
- Rich Metadata: Each element comes packed with useful metadata: its text content, the page number it came from, often its coordinates (bounding box) on the page, the original filename, the element in its HTML format, and detected language. This allows for precise downstream processing or linking back to the source.
In essence, Unstructured doesn't just "read" your PDF; it understands and deconstructs it, handing you back the building blocks in a way that your code can readily consume and reason about. This moves you from the frustrating world of brittle, regex-based scraping to a more robust, semantic understanding of your documents.
What Kinds of Elements Can You Expect?
This isn't just about "text" and "not text." Unstructured's power lies in its ability to differentiate various types of content. You'll typically encounter elements like:
- Title : Headings and subheadings that structure the document.
- NarrativeText: Standard paragraphs of flowing text.
- Table: Recognized tabular data.
- Image: Identifies images and their associated captions.
- Header / Footer: Page headers and footers, so you can differentiate them from the main content.
- And others like ListItem, EmailAddress, PageBreak, etc., depending on the document and strategy.
Traditional document processing approaches often produce "flat" text that loses the semantic structure of the original document. Unstructured has a rich ontology of element types that helps maintain the original knowledge architecture and capture hierarchical relationships.
Working with Images and Tables:
Images:
For image elements, we also extract their Base64-encoded representation that can be used to decode the image later. This is currently available
# Picking up from our previous examples, assuming you have a list of elements:
for element in response.elements:
if "image_base64" in element["metadata"]:
# Decode the Base64-encoded representation of the
# processed "Image" element into its original
# visual representation, and then show it.
image_data = base64.b64decode(element["metadata"]["image_base64"])
image = Image.open(io.BytesIO(image_data))
image.show()Tables:
Tables are one of the hardest components to retrieve accurately, and in an accessible manner. We output tables as HTML strings, preserving row/column structure, which is often more useful than markdown.
# Once again, picking up from our previous examples, assuming you have a list of elements:
# Provide some minimal CSS for better table readability.
table_css = "<head><style>table, th, td { border: 1px solid; }</style></head>"
for element in response.elements:
if "text_as_html" in element["metadata"]:
# Surround the element's HTML with basic <html> and <body> tags, and add the minimal CSS.
html_string = f"<!DOCTYPE html><html>{table_css}<body>{element["metadata"]["text_as_html"]}</body></html>"
# Save the element's HTML to a local file.
save_path = f"{local_output_path}/{element["element_id"]}.html"
file = open(save_path, 'w')
file.write(html_string)
file.close()Seeing is Believing: Visualizing Element Bounding Boxes
Beyond the JSON, a powerful diagnostic feature in Unstructured is the ability to generate coordinate bounding boxes for your parsed elements, when using layout-aware strategies like "Hi-Res" (which we'll dive into more detail on later). These coordinates tell you exactly where on the page each element was found, and they provide visual insight into how elements are parsed under the hood.
Let’s quickly see how you might generate these coordinates and visualize them.
(Heads up: You'll need libraries like Pillow (PIL) for image manipulation, matplotlib for visualization and a way to convert your PDF page to an image, for example, using pdf2image. The exact code will depend on how you want to render, but here's how you generate coordinates.)
# !----Setup your Unstructured Client---!
pdf_filename = "path/to/your/document.pdf"
# Prepare the request to the Unstructured API
# We're using the 'hi_res' strategy and explicitly asking for coordinates.
partition_params = shared.PartitionParameters(
files=shared.Files(
content=open(pdf_filename, "rb"),
file_name=pdf_filename,
),
strategy=shared.Strategy.HI_RES, # Essential for layout-aware element detection
coordinates=True, # Request coordinate data for elements
pdf_infer_table_structure=True # Useful for complex tables
)
response = client.general.partition(partition_params)
# The response.elements will contain your list of parsed elements
# Each element dictionary will have a 'metadata' -> 'coordinates' key like this
# 'metadata': {'coordinates': {'points': [[300.4508333333334,
# 194.91561889648438],
# [300.4508333333334, 432.694845],
# [1396.8880111111105, 432.694845],
# [1396.8880111111105, 194.91561889648438]],
# 'system': 'PixelSpace',
# 'layout_width': 1700,
# 'layout_height': 2200}}Using the coordinates, we can draw the bounding boxes on our document like this:
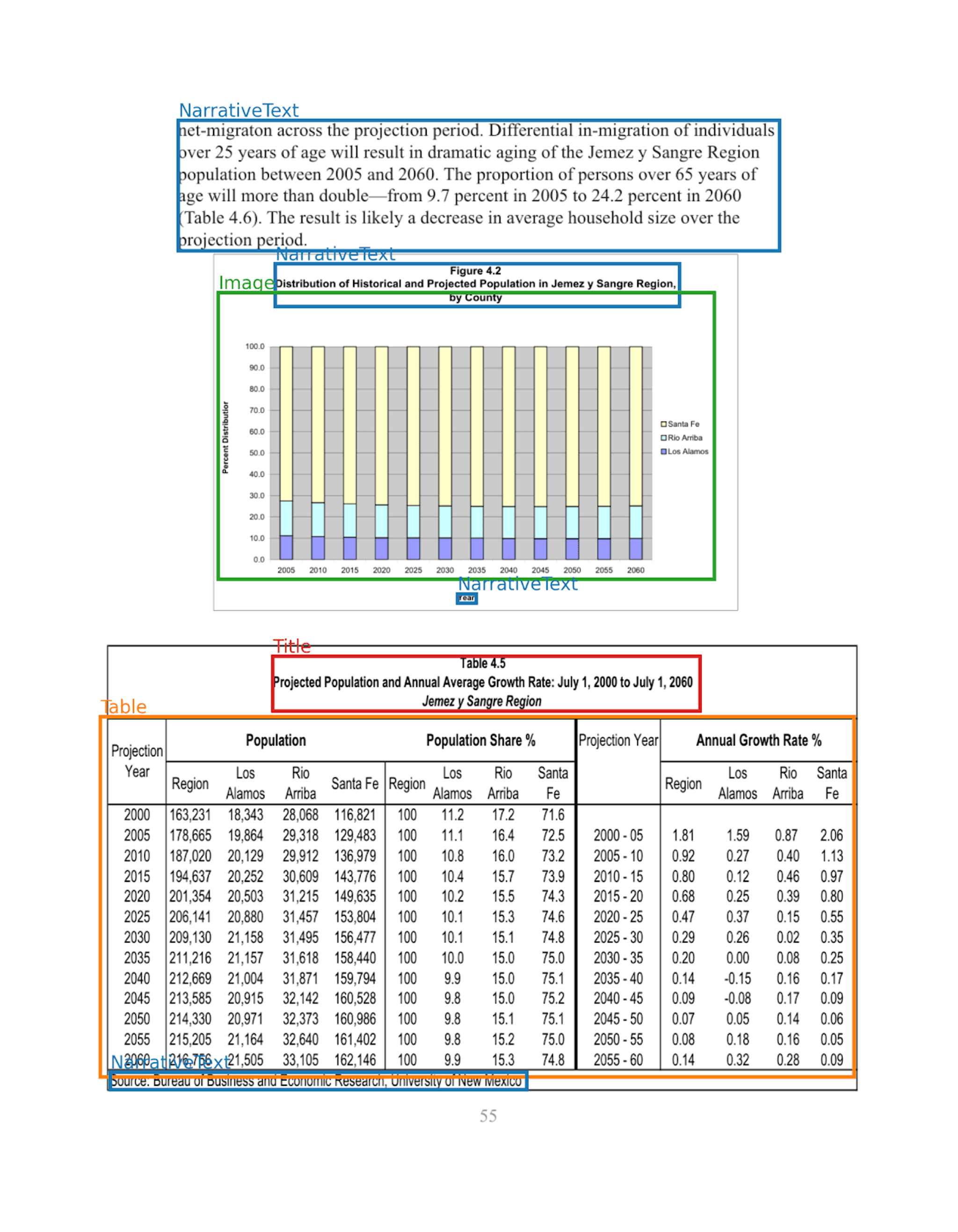
Looking at the visualization, notice how Unstructured has identified several types of elements:
- NarrativeText: The outlined sections in the image contain flowing paragraphs that explain the population trends. The system recognizes these as continuous prose rather than simple text extraction, preserving their narrative context.
- Image: The chart displaying population distribution is accurately identified as an image element, maintaining both the visual data and its relationship to surrounding content.
- Title: The table header "Projected Population and Annual Average Growth Rate: July 1, 2000 to July 1, 2060" is properly classified as a title element, recognizing its function in establishing context for the data that follows.
- Table: Perhaps most impressively, the complex population data table is correctly identified as a structured table rather than disconnected text. This preserves the crucial row-column relationships that give meaning to the numerical data. Since we selected the pdf_infer_table_structure option in our request, the table is also readily available in the HTML format.
From Paradox to Parsed: Understanding Your PDF's Building Blocks
In Part 1, we've seen how Unstructured demystifies complex PDFs by transforming them into a structured list of document elements. You've learned about various element types, their rich metadata (like content, type, and page location), and how this element-based output readies your PDFs for AI applications. This foundational understanding is key to unlocking your documents' value.
But how are these elements generated from diverse PDFs? That's where parsing strategies come in.
Coming Up in Part 2: Choosing Your PDF Transformation Strategy
Part 2 will shift from the what (elements) to the how (generation). We'll explore Unstructured's 'Fast,' 'Hi-Res,' 'VLM,' and 'Auto' strategies, examining their tech, strengths, and trade-offs. You'll learn to select the best strategy based on your document type, and needs for accuracy, speed, and cost. See you on the next one!
FAQ
Why are PDFs so difficult to parse programmatically?
PDFs are designed to preserve visual fidelity across platforms, not to expose machine-readable structure. This means content is often stored as positioned text blocks without semantic context, multi-column layouts can bleed into one another, and scanned documents require OCR just to access the text at all. Unlike HTML, PDFs have no native equivalent of semantic tags to distinguish a heading from a paragraph.
What is the difference between text extraction and document parsing?
Text extraction pulls raw characters from a file with little regard for structure or meaning. Document parsing goes further by identifying what each piece of content is, whether it is a heading, a table row, a caption, or a footnote, and preserving the relationships between those elements. For AI applications, that semantic context is often as important as the text itself.
How should tables in PDFs be handled when building AI pipelines?
Tables are among the hardest PDF elements to extract reliably because their structure is often implied visually rather than encoded explicitly. The most robust approach is to convert tables into a format that preserves row and column relationships, such as HTML or structured JSON, rather than flattening them into plain text where that structure is lost.
What does Unstructured output when it processes a PDF, and how is that output structured?
Unstructured returns a JSON list of document elements, where each element includes a type (such as Title, NarrativeText, Table, or Image), the extracted text content, and metadata covering the source filename, page number, detected language, and bounding box coordinates. This consistent format makes it straightforward to filter, route, or transform elements based on their semantic role before passing them to downstream systems.
How does Unstructured handle images and tables found inside PDFs?
For images, Unstructured extracts a Base64-encoded representation of each identified image element, which can be decoded and used directly in downstream workflows. Tables are output as HTML strings that preserve row and column structure, and when the pdf_infer_table_structure option is enabled, this structured representation is included alongside the standard element metadata.


