

Authors

Unstructured.io offers a powerful toolkit that handles the ingestion and data preprocessing step, allowing you to focus on the more exciting downstream steps in your machine learning pipeline. Unstructured has over a dozen data connectors that easily integrate with various data sources, including AWS S3, Discord, Slack, Wikipedia, and more.
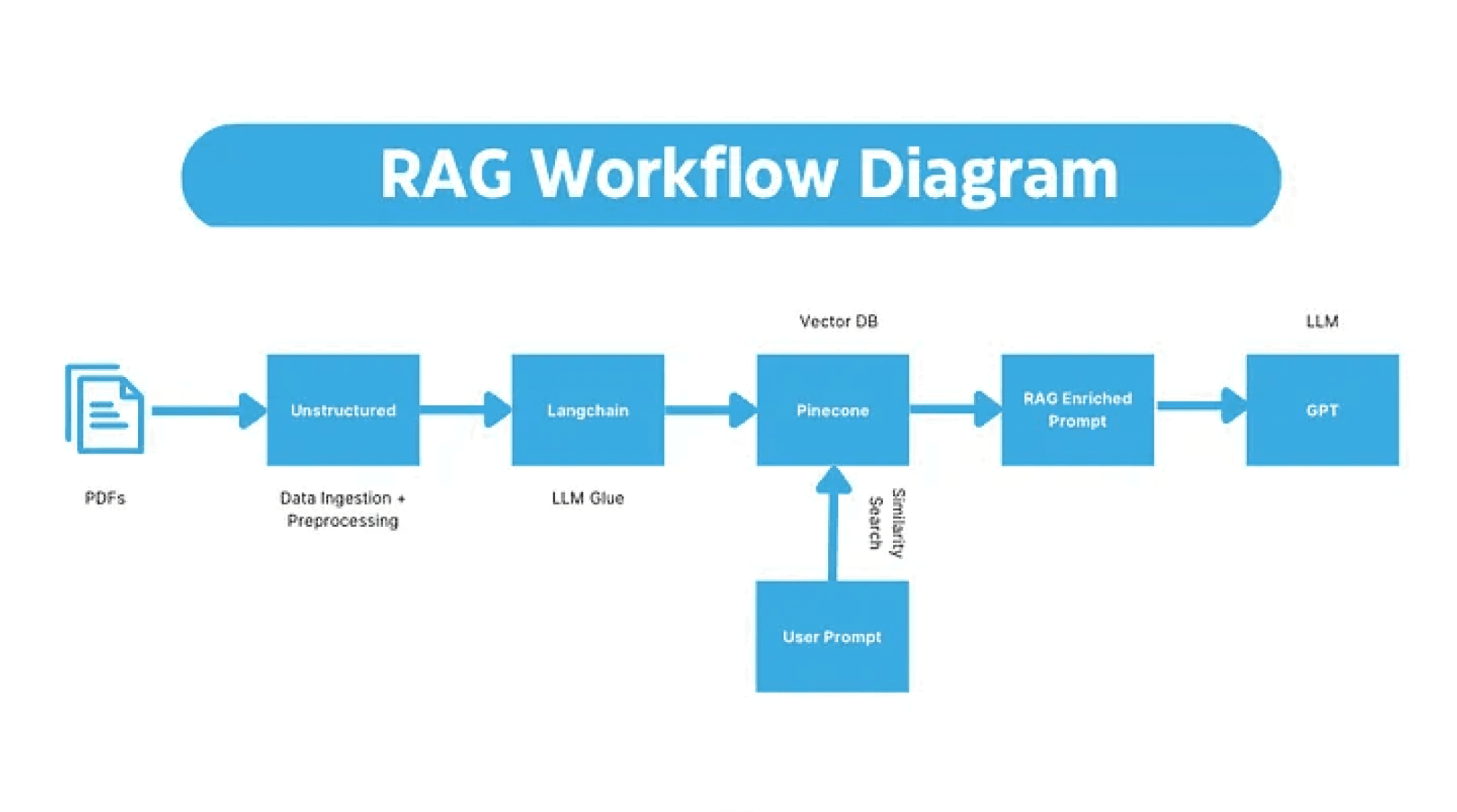
In this guide we will go through a step-by-step guide on how to grab your data from GCS, and preprocess that data and upload it to a vector database for Retrieval Augmented Generation (RAG).
Prerequisites:
- Install Unstructured from PyPI or GitHub repo
- Install Unstructured Google Cloud connectors here
- Obtain Unstructured API Key here
- Obtain OpenAI API Key here
- Obtain Pinecone API key here
- A Google Cloud Storage (GCS) bucket full of documents you want to process
- Basic knowledge of command line operations
Enable GCS Access:
In order to access your files from GCS you need to grant access to reading the buckets within your GCS account. If you are unfamiliar with this process I will go over a basic example but if you are already familiar with the steps feel free to skip to the next section.
- Navigate to your Google Cloud Console (link)
- Click on the project that you plan on grabbing data from
- On the left side of the screen click IAM & Admin -> Service Accounts
- Click “+ Create Service Account” and fill in the fields
- Once you’ve created the new service account click on it and go to “KEYS”
- Click “ADD KEY”->”Create new key”->JSON
- That will download a JSON file with your keys. Please ensure that these keys are properly stored as they pose a security risk.
- Place the JSON file somewhere safe and in a path you can access later on
Run Unstructured API with GCS Connector:
With your Unstructured API key and GCS bucket ready, it’s time to run the Unstructured API. To run the `unstructured-ingest` command, you need to install the unstructured open-source library that can be easily obtained from this GitHub repository.
Follow the instructions in the repository to install the library and please make sure to install the additional dependencies below:
!pip install "unstructured[gcs,all-docs]" langchain openai pinecone-client
Once you installed the additional dependencies, you are good to run the API. For this tutorial, I’ve elected to run the API in a python notebook.
# Add the environment variable for the GCP service account credentialsos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/Path/to/your/keyfile.json'
command = [ "unstructured-ingest", "gcs", "--remote-url", "gs://<YOUR-BUCKET>/", "--structured-output-dir", "/YOUR/OUTPUT/PATH", "--num-processes", "2", "--api-key", "<UNSTRUCTURED-API-KEY>", "--partition-by-api"]
Explanation:
- os.environ[‘GOOGLE_APPLICATION_CREDENTIALS’] =/path/to/your/keyfile.json — Add the environment variable for the GCP service account credentials
- “gcs” — specifies the data connector
- Set the output directory using ` — structured-output-dir` parameter
- Specify ` — num-processes` to distribute the workload across multiple processes
- Include ` — api-key` from the earlier step in your API call
- Use the ` — partition-by-api` flag to indicate running the partition through API rather than the library
We are proud to introduce our free-to-use API, tailor-made for enthusiasts and developers keen on prototyping. We’ve allocated a specific number of dedicated workers to ensure seamless operation and to cater to our user community. However, we understand the needs of larger corporations and heavy-duty tasks. With this in mind, we are excited to announce that an enterprise-grade API is on the horizon.
Review the API output:
Once the command completes, you’ll find the structured outputs in your specified output directory. These files contain the extracted information from your unstructured data, ready for analysis or further processing.
When we build RAG systems, our LLMs model only performs as well as the context that is provided to them. For that reason, we want to remove unnecessary textual elements found in our files. Fortunately Unstructured classifies text by element types and when Unstructured finds elements that it can’t classify it labels them as “UncategorizedText”. Often that “UncategorizedText” is unhelpful and distracting to our LLM. In this tutorial we will remove those “UncategorizedText” elements with the following helper function.
def remove_element_from_json(filepath, item_to_remove): # Read the file and load its contents as JSON with open(filepath, 'r') as file: data = json.load(file)
# Filter out the elements with the specified 'type'updated_data = [item for item in data if item['type'] != item_to_remove] # Write the updated data back to the filewith open(filepath, 'w') as file:json.dump(updated_data, file, indent=4)
Now you can call the above helper function by specifying the file path to the document and the element type you’d like to remove.
filepath = '/YOUR/OUTPUT/PATH'remove_element_from_json(filepath, "UncategorizedText")
Load Json Files Into Langchain:
The next step is to load in your cleaned and processed structured data into LangChain’s document loaders. In this case we will use the UnstructuredFileLoader by LangChain.
from langchain.document_loaders import UnstructuredFileLoader
# Now you will load to files outputted from the Unstructured API. You'll find the files in the output directory. loader = UnstructuredFileLoader("/YOUR/OUTPUT/PATH", post_processors=[clean_extra_whitespace],)docs = loader.load()
Chunk the Text Files:
Next we will need to chunk the original documents so that our Large Language Models (LLMs) can process the potentially long documents. A current limitation of LLMs is that they can only process a certain amount of context. We chunk data to make the pieces of text digestible for them.
For the purpose of this tutorial I have chosen to go with LangChain’s RecursiveCharacterTextSplitter however they have a variety of different chunking methods found here.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)docs = text_splitter.split_documents(docs)
Setting up Pinecone:
Once we’ve chunked our data now we can embed it and store it in a vector database. In this demo I am going to use Pinecone however there are a variety of different options each with their own strengths.
# Storing API keys like this poses a security risk. Only do this in prototypingos.environ['PINECONE_API_KEY'] = "<PINECONE-API-KEY>"
# Pinecone Environment Variableos.environ['PINECONE_ENV'] = "<PINECONE-LOCATION>"pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), # find at app.pinecone.ioenvironment=os.getenv("PINECONE_ENV"), # next to api key in console)index_name = "gcs-demo"# First, check if our index already exists. If it doesn't, we create itif index_name not in pinecone.list_indexes():# we create a new indexpinecone.create_index(name=index_name,metric='cosine',dimension=1536 )
Create Helper Functions:
The next step is once we’ve initialized our Pinecone database we need to create a helper function to grab all the relevant chunks of information from our vector database to be later used by our LLM ( inspiration).
limit = 3600embed_model = "text-embedding-ada-002"
def retrieve(query):res = openai.Embedding.create(input=[query],engine=embed_model) # retrieve from Pineconexq = res['data'][0]['embedding'] # get relevant contextsres = index.query(xq, top_k=3, include_metadata=True)contexts = [x['metadata']['text'] for x in res['matches']] # build our prompt with the retrieved contexts includedprompt_start = ("Given the contextual information and not prior knowledge, answer the question. If the answer is not in the context, inform the user that you can't answer the question.\n\n"+"Context:\n")prompt_end = (f"\n\nQuestion: {query}\nAnswer:")# append contexts until hitting limitfor i in range(1, len(contexts)):if len("\n\n---\n\n".join(contexts[:i])) >= limit:prompt = (prompt_start +"\n\n---\n\n".join(contexts[:i-1]) +prompt_end)breakelif i == len(contexts)-1:prompt = (prompt_start +"\n\n---\n\n".join(contexts) +prompt_end)return prompt
Now that we have a helper function to retrieve the relevant chunks of information we need a helper function to take in our augmented prompt and feed it into our LLM.
def complete(prompt): # query text-davinci-003 res = openai.Completion.create( engine='text-davinci-003', prompt=prompt, temperature=0, max_tokens=400, top_p=1, frequency_penalty=0, presence_penalty=0, stop=None ) return res['choices'][0]['text'].strip()
Query Vector Database:
With our two helper functions, we can now leverage our vector database to retrieve relevant pieces of information to help our LLM answer domain specific questions.
query = "A question you'd like to ask about your PDF"
# first we retrieve relevant items from Pineconequery_with_contexts = retrieve(query)query_with_contexts
Once we’ve retrieved the necessary context we can feed it into our LLM to answer our question.
# then we complete the context-infused querycomplete(query_with_contexts)
Conclusion:
In this blog we’ve gone from unstructured raw PDFs stored in a GCS bucket to pre-processing them, and uploading them to a vector database for our LLM to query from. There are a lot of potential improvements in this process including chunking techniques but I hope you now can take any file format and build a RAG pipeline around it. The complete code can be found here.
If you have questions, join our community Slack group to connect with other users, ask questions, share your experiences, and get the latest updates. We can’t wait to see what you’ll build!
FAQ
What is a RAG pipeline and why does it matter for LLM applications?
A RAG (Retrieval Augmented Generation) pipeline enhances large language model responses by retrieving relevant information from external documents and injecting that context into the prompt before generating an answer. This approach allows LLMs to answer questions grounded in specific, up-to-date, or proprietary data rather than relying solely on what was learned during training.
What are the core stages of building a RAG pipeline from scratch?
A RAG pipeline typically involves four stages: ingesting and preprocessing raw documents, chunking the text into manageable segments, embedding those chunks and storing them in a vector database, and retrieving the most relevant chunks at query time to pass as context to an LLM. Each stage affects the quality of the final output, so decisions around chunking strategy and data cleaning are worth careful consideration.
Why does data quality in the preprocessing stage affect RAG performance?
LLMs can only work with the context they are given, so noisy or poorly structured input directly degrades response quality. Removing irrelevant elements like headers, footers, and uncategorized text before embedding helps ensure the retrieved context is meaningful and focused on content the model can actually use.
How does Unstructured handle document preprocessing for RAG pipelines?
Unstructured parses documents across formats including PDFs, HTML, PPTX, and images, and classifies extracted content into structured element types such as titles, narrative text, and tables. This classification allows you to filter out low-value elements like uncategorized text before chunking and embedding, which improves the signal quality of what gets stored in your vector database.
What data connectors does Unstructured support for ingesting source documents?
Unstructured offers over a dozen data connectors that integrate with sources including AWS S3, Google Cloud Storage, Slack, Discord, and Wikipedia, among others. This means you can pull documents directly from where they already live and run them through the preprocessing pipeline without building custom ingestion logic for each source.


