
Authors


There’s a long-standing debate on X about whether “RAG is dead” - the latest on this topic based on using Gemini 2.0 Flash to parse and extract info from your documents directly. A 1 million token context window, that’s impressive! We’ve written previously on this topic at a high level. So we tried Gemini 2.0 out for a project around parsing SEC S-1 filings, and we will detail what worked, what didn’t, what we did, and what we might do differently with either approach next time. Note that we tried this for one document type, SEC S-1 filings, that is fairly long, and not standardized in its formatting. We find this to accurately describe most documents our customers encounter in production GenAI applications. But there may certainly be other use cases where documents are more standardized, and our findings are less relevant.
Tl;dr: We compared S-1 filing extraction completeness, cost, and latency between Agentic RAG and long context via Gemini 2.0. Agentic RAGwas more effective than the long context approach at extracting information for most fields in our extraction, with the notable exception of one which required broader document understanding. Agentic RAG was cheaper. Gemini 2.0 was faster. Below are all of our findings that we will dive into in the rest of this blog post:
Keep reading to find out how we got these results and what they mean!
Introduction
Parsing and analyzing SEC S-1 filings is challenging due to their inconsistent structure and varying content. But they contain valuable information. We recently set out to explore how well LLMs can process these dense, complex documents—testing different approaches to determine what works best in practice. In this post, we'll share our learnings, covering:
- Why analyzing S-1 filings is a complex problem.
- The steps involved in consistent information extraction.
- A comparison of two methods we tested:
- Long Context Approach: Feeding entire S-1 filings into an LLM with a large context window, in this case, Gemini 2.0.
- Agentic Retrieval-Augmented Generation (RAG): Transforming files by converting them to json, splitting these filings into chunks, embedding them, then retrieving only relevant sections at query time. We use the Unstructured Platform to get our data LLM-ready.
- Our conclusions based on the results we observed when applying these methods to a dataset of 1,200 technology companies' S-1 filings.
We’ll walk through our methodology, key findings, and the trade-offs between these approaches. Whether you’re working with financial documents or other large text corpora, our experience might help inform your own AI-driven document analysis efforts, and help you choose the right approach for your documents.
A Quick Primer on S-1 Filings
S-1 filings are registration statements companies submit to the Securities and Exchange Commission (SEC) before going public in the US. They contain critical details—risk factors, financials, market insights, and more—but at hundreds of pages long, extracting structured information from them is far from trivial. Key insights analysts often look for include:
- Company Background and Business Overview
- Risk Factors
- Market Opportunity
- Forward-Looking Statements (such as future growth projections or product launches)
- Financial Statements (including revenue, net income, and more)
Because it’s a legal document, an S-1 filing can sometimes be hundreds of pages, packed with domain-specific jargon, disclaimers, and forward-looking statements. The complexity and size make it an excellent testbed for generative AI capabilities, providing a compelling challenge for models designed to process lengthy, unstructured text.
Data & Methods
The Dataset
For this project, we’ve collected a dataset of 1,200 technology companies’ S-1 filings using the SEC EDGAR API. Our entire corpus consists of PDF versions of these documents, each with its own formatting and layout.
Our goal: Programmatically extract key structured fields from these documents—like risk factors, financial metrics, market size references, and customer counts—and store them for subsequent analysis and insights.
Below is a high-level view of the fields we’re interested in:
- Business Overview: Company categories/segments, mentions of market size, sales model, etc.
- Market Opportunity: Total Addressable Market (TAM) and how the company defines its opportunity.
- IPO Financials: Shares offered, IPO price per share, implied market cap.
- Risk Factors: Key business, financial, operational, and regulatory risks.
See the next sections for the Pydantic models that outline these fields more formally.
The Extraction Challenge
Traditional extraction methods struggle with S-1 filings due to their:
- Length (typically 50-200 pages)
- Mix of structured tables and unstructured text
- Legal/technical jargon, and inconsistent structure
- Strategic information buried in verbose sections
We are looking to extract specific information from these documents in a structured format. There are a couple of ways we can employ LLMs to handle the dynamic nature of this task.
Method 1: Long Context Extraction Setup
The first method we experimented with involves passing the entire S-1 document to an LLM capable of handling very long input contexts. We used Gemini 2.0 Flash, which can handle up to 1M input tokens at inference time - you can fit the entire Bible in a single query. The overarching goal is to have the model read the entire filing and provide extracted fields.
Here is the core setup:
- Extract text from HTML: First convert the S-1 HTML to a readable text form like Markdown, then extract raw text.
- Set a system prompt:
- Pass the entire S-1 text as context: Pass the content from the entire S-1 into the prompt with each request.
- Use Pydantic for Structured Output: Pydantic allows you to perform structured output generation and validation from LLMs. This is helpful especially when you’re working with data and you need schema validation. In our context an example Pydantic model would look something like this:
class BusinessOverview(BaseModel):
categories: List[str] = Field(
...,
description="Exhaustive list of of categories or market segment the company operates in "
"(e.g., 'cloud computing,' 'enterprise software'), exactly as it is mentioned in the S-1 "
"filing. Do not paraphrase or summarize."
)
market_size: Optional[str] = Field(
None,
description="Extract any mentions of total addressable market (TAM) or market size estimates.",
type="string"
)
customer_count: Optional[str] = Field(
None,
description="Extract any mentions of Number of current customers/users.",
type="string"
)
average_deal_size: Optional[float] = Field(
None,
description="Average deal size or customer spend in dollars.",
type="number"
)
sales_model: Optional[str] = Field(
None,
description="What kind of Sales model, e.g., 'direct', 'channel', or 'online adoption'.",
type="string"
)
The types define how we want the output generated, and the description acts as a prompt to the LLM when it is extracting these fields from the document.
Why Long Context?
- This approach is straightforward: prompt the model with the entire text, ensuring no detail is omitted.
- It’s helpful for quick prototyping because you don’t have to worry about chunking or storing embeddings.
Challenges
- Potentially expensive calls if the context is very large.
- The method can be slow and might still lead to partial extraction if the model fails to retain all relevant details in one shot.
Method 2: Agentic RAG (Retrieval-Augmented Generation)
The second approach we took uses Agentic RAG. RAG in general has been widely used since it combines the principles of information retrieval with LLMs’ ability to synthesize information and generate well-written responses to queries related to private information. Due to context-length limitations in LLMs, instead of passing the entire S-1 in one go, RAG breaks it into smaller chunks for retrieval on an as-needed basis. This also allows the user to keep private/internal information in secure locations, without exposing it entirely to a third-party provider.
RAG Data Setup
Before we start writing processing queries, we need to set up the pipeline to convert our documents so they’re ready for RAG. This involves taking all the PDFs, parsing the raw documents, extracting the text, chunking them for accurate retrieval, and generating embeddings on the data to be used for retrieval. The Unstructured Platform takes care of all of this so you can get your documents from where they live to a vector database in just a few minutes. Simply upload your documents to a source, configure your connectors and workflow, and hit run.
To get started, let's set up our source and destination in Unstructured Platform! For a more detailed step-by-step guide on how to configure a S3 -> Vector DB workflow, check out our recent blog on setting up with Platform. In this RAG data setup, we followed many of the same steps:
- Create a new source connector at https://platform.unstructured.io/connectors/editor/new/sources and fill in as per https://docs.unstructured.io/platform/sources/s3.
- Create a new destination connector at https://platform.unstructured.io/connectors/editor/new/destinations and fill in as per https://docs.unstructured.io/platform/destinations/astradb for an Astra DB destination connector. You can set up an account and our destination collection at https://www.datastax.com/products/datastax-astra. Make sure to set up the destination collection on AstraDB with your embedding dimension in mind: in this example, text-embedding-3-large with dimensions of 3072.
- Construct your workflow for document processing
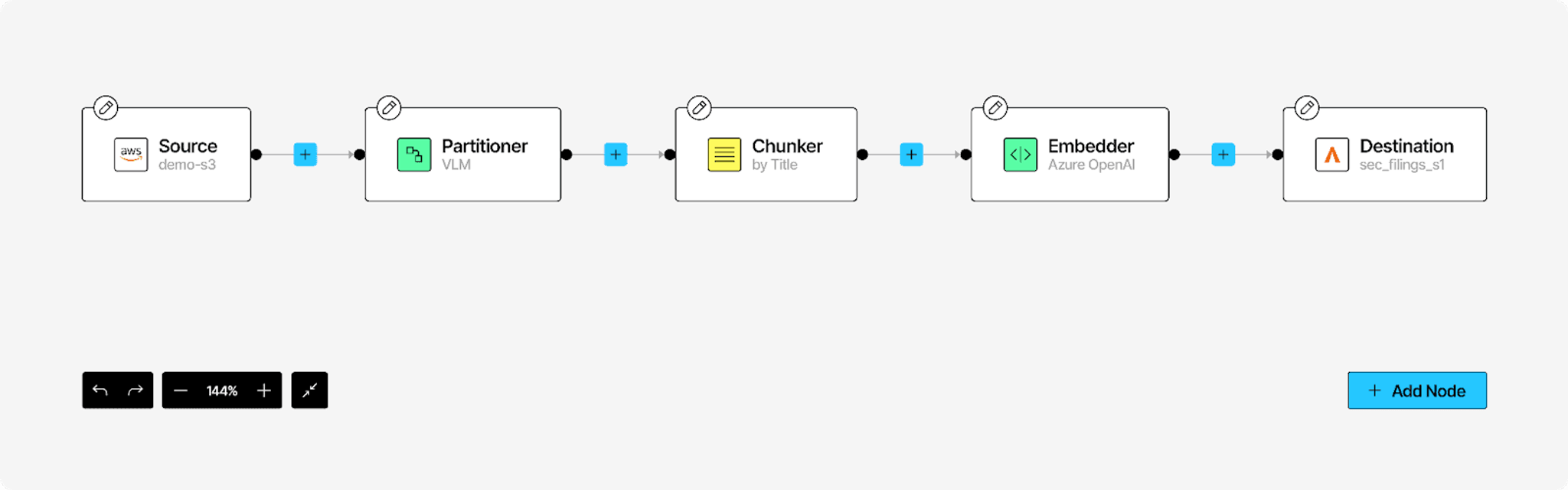
To summarize our workflow characteristics:
- Document Parsing: select the VLM partitioner method in the Unstructured Platform (which leverages vision language models) to parse unstructured PDFs.
- Chunking: The extracted text is segmented by title, with a chunk size of 2048 characters and an overlap of 160 characters.
- Embedding: We used the text-embedding-3-large model to embed each chunk in 3072-dimensional embedding space. Remember to use the same embedding dimensions between your AstraDB collection and the embedding provider.
- Storage: These embeddings and chunk metadata are stored in an AstraDB collection for fast similarity-based retrieval.
Once the job has completed running, all of our documents have been parsed and indexed in our AstraDB collection, ready to power RAG applications.
RAG Inference Flow
Now that we have our documents ready for RAG, let’s look at building our retrieval pipeline to extract relevant information for our queries.
We used SmolAgents by Hugging Face for our RAG pipeline. SmolAgents provides a powerful CodeAgent i.e. agents that write their actions in code (as opposed to "agents being used to write code"). Our pipeline consists of the following steps:
- RetrieverTool: We created a custom tool that, given a query, embeds the query and retrieves the k most relevant chunks from the AstraDB collection. This retrieval is also filtered to ensure only relevant documents for the specific company are returned. Agents can employ these tools as required to solve the tasks provided to them.
- CodeAgent: The agent has a set of predefined questions (the extraction fields) it needs to gather from each S-1 filing.
- The agent performs query reconstruction and passes the updated query to the retriever tool.
- It synthesizes the retrieved chunks using GPT-4o and generates a textual answer.
- Structured Output: The textual answers are then compiled across questions. Another small LLM call transforms these answers into the structured Pydantic schema, matching the same structure as the Long Context approach.
By doing so, the RAG pipeline limits how much text goes into each LLM call and uses targeted retrieval to extract only relevant sections of the S-1. This means the token cost of our analysis for a single company is significantly lesser, and the latency of output token generation is also faster.
Results
We compared extraction completeness, cost, token usage, and latency. In our attempted extractions, there were a lot of not a Number (NaN) values in the result of both extraction methods, where they failed to find the relevant information. To calculate the % extracted, we looked at how many of our 1000+ companies that we had S-1 filings for, had a reasonable extracted output for that field. We have indicated with an asterisk where we know the information is present in each filing, even if it is not consistently placed, since it is legally required to be present. We did some light filtering for non-answers in addition to counting NaNs as missing entries.
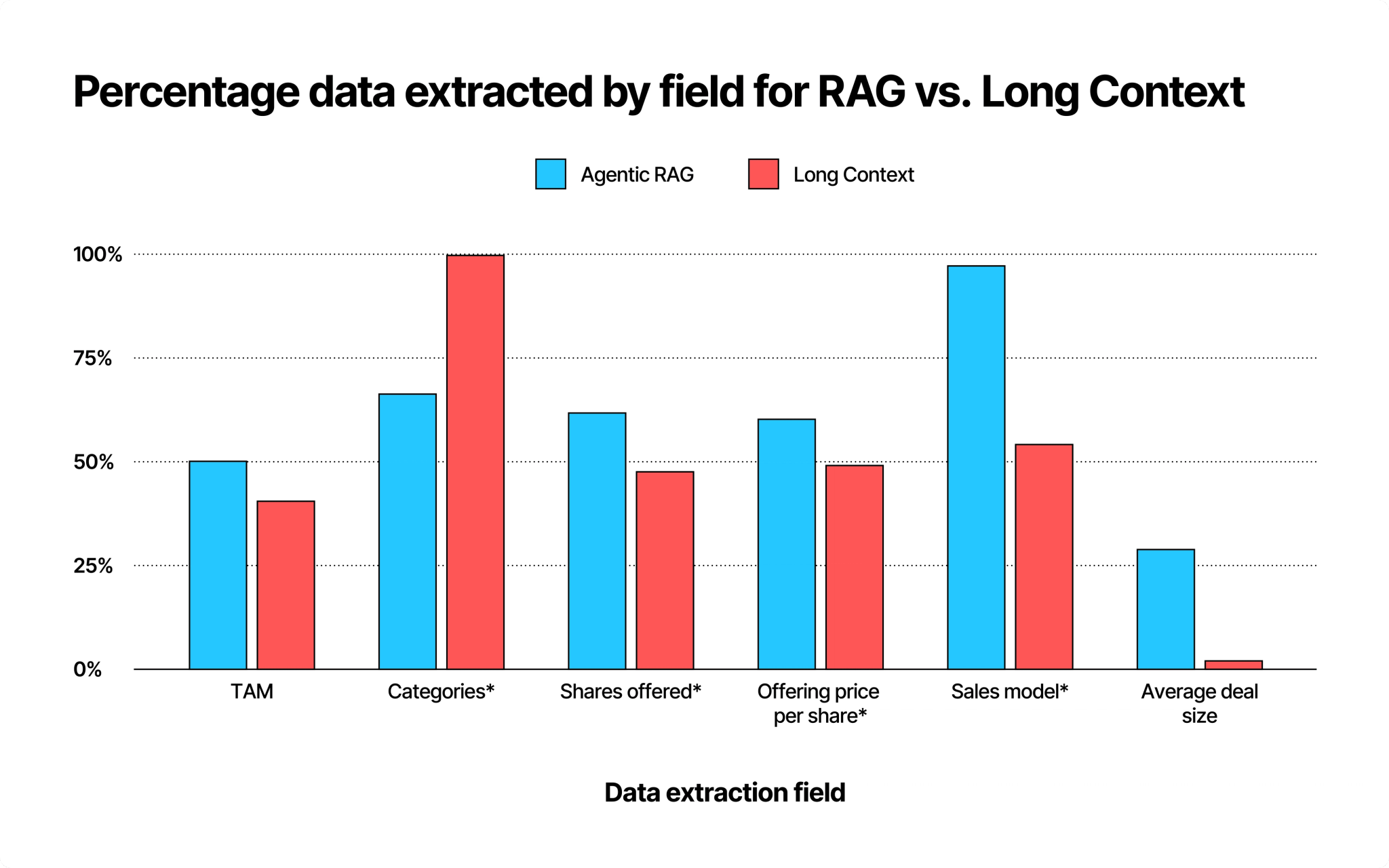
Looking below at the extraction performance between our RAG and Long Context methods on S-1 filings, we see that RAG outperformed Long Context in all fields but one. We see that Long Context significantly outperforms RAG in the categories field (99.8% vs. 66.4%). This makes sense since identifying categories requires understanding the entire document and summarizing, which LLMs handle well, while RAG, being chunk-based, isn't optimized for such tasks. Based on this small experiment, our sense is that RAG will be more performant for most straightforward information extraction, but Long Context will be the superior approach for information extraction that truly requires the full context to get right.
The asterisk (*) indicates fields where the information is always present in the S-1 filing, and we can reasonably expect 100% extraction in a perfect system.
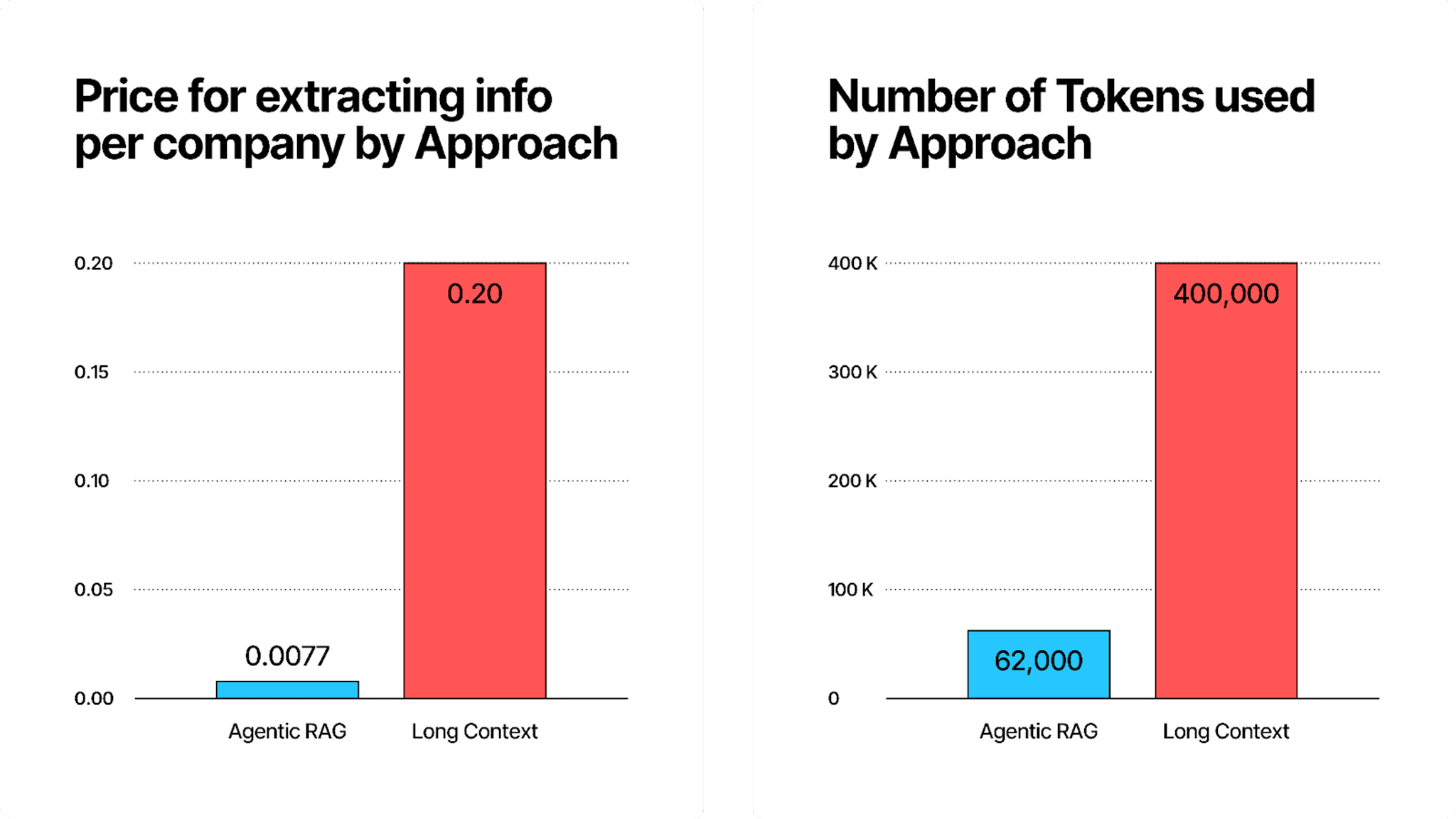
Next, we looked at the price and token usage comparison between our RAG and Long Context methods using Gemini Flash 2.0. Here, we see a stark contrast. The left chart shows that RAG incurs significantly lower costs per company that we extracted info for ($0.0077) compared to Long Context ($0.20). The right chart highlights that RAG processes only 62,000 tokens, on average, whereas Long Context requires 400,000 tokens, indicating a substantial efficiency advantage for RAG. This makes sense, since most of the questions only require a short section of the document to answer correctly. And, may, conversely, get lost as a needle in the haystack, if you are processing the full document instead.
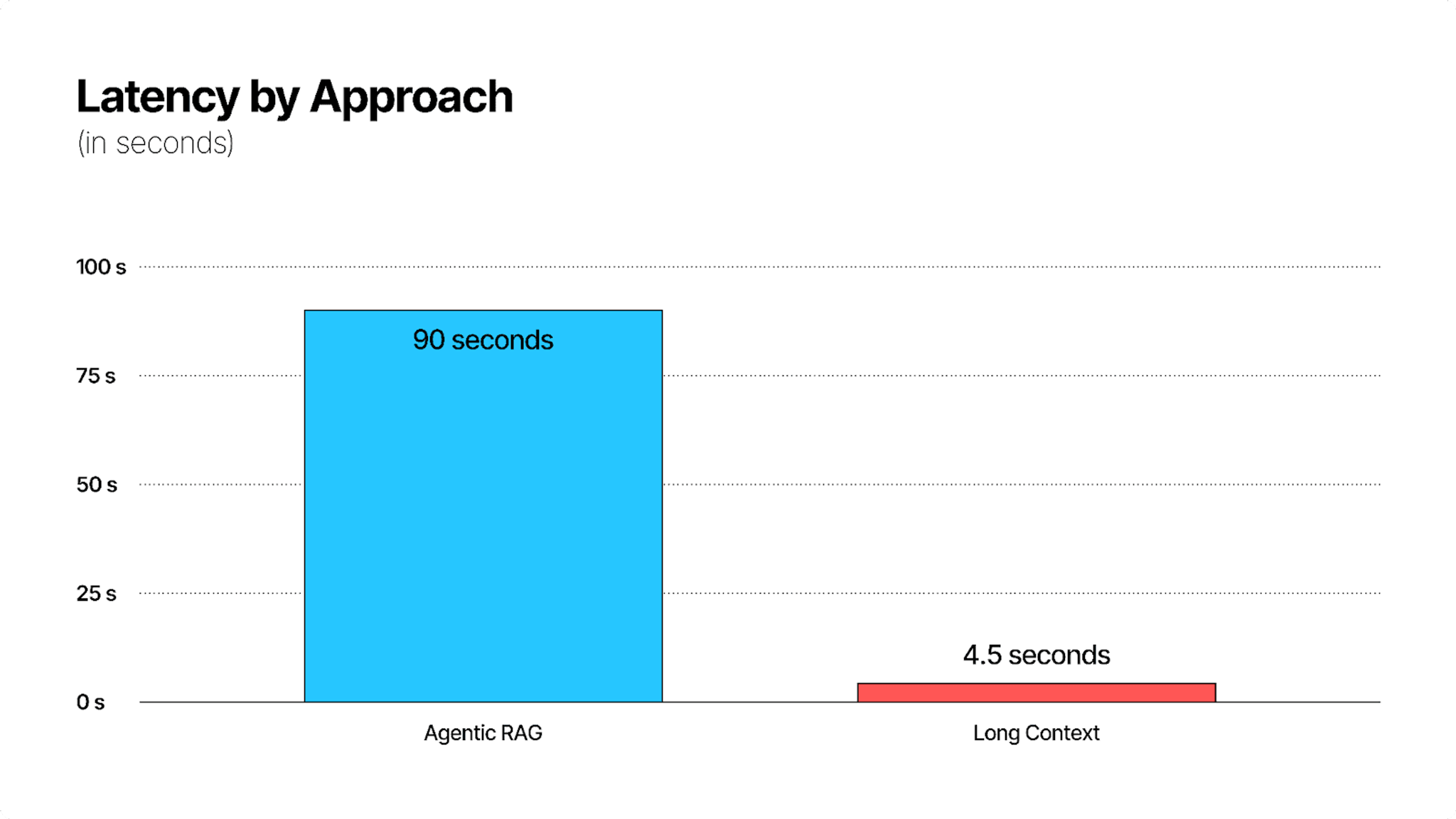
Lastly, we looked at the latency. Since we used an Agentic RAG setup for superior extraction performance, our queries took longer than the Gemini 2.0 queries.
Conclusion
In the end, we found that we wanted to use both methods for our extraction: Gemini to extract the challenging field of “categories”, and Agentic RAG for everything else. This hybrid approach yielded the most completeness in information, whereas Agentic RAG was most performant and least expensive overall.
Our RAG setup could also be further optimized to improve extraction completeness, whereas there isn’t much to do to improve on completeness for Long Context, except perhaps offering Gemini a financial reward for correct answers, or asking it to try really hard or to think hard before answering. For RAG, we could improve further upon the retriever for stronger results: using hybrid search, or metadata prefilters, could retrieve better results.
If you want to jump start your RAG setup by doing all the pre-processing with Unstructured Platform, contact us at sales@unstructured.io.


