
Authors

Techniques like retrieval augmented generation (RAG) have become the main approach to using LLMs in conjunction with custom data. By retrieving relevant information from a vector store or database and passing it to an LLM, we can ground generated answers in context, significantly reducing the model's hallucinations.
At the same time, over the past year, we’ve seen LLMs released with ever increasing context windows, pushing the boundaries of how much context you can add to the prompt. For instance, Gemini 1.5 Pro sports a 2 million token window, while AI startup Magic is developing a model with a context window size of 100 million tokens, and there are even conversations about the possibility of models with infinite context windows in the future. This has sparked an ongoing debate among practitioners: will RAG remain necessary, or could models with these vast context windows eventually replace it?
In this blog post, we share a perspective on why we believe RAG will remain essential, even if we see a release of a hypothetical model with infinite context.
Understanding the Basics of RAG and Long Context Models
Feel free to skip this section if you understand how RAG works. RAG has been developed as a way to address some serious limitations of the off-the-shelf LLMs. These LLMs, trained on publicly available data, are prone to hallucinations when prompted with questions that are about domain-specific knowledge, proprietary data, or recent events. RAG is a technique where LLMs text generation is augmented with information from an external knowledge base. When a query is posed, the system first retrieves relevant information from the knowledge base and then incorporates this information into the prompt for the LLM. This enables LLMs to access information beyond their training data and tends to help it generate more informed and accurate responses. In RAG, there are many ways to retrieve relevant context based on the user query. While the most popular method is similarity search over vector representations of text, this is by far not the only method. The “R” in RAG actually benefits from decades of Information Retrieval practices, and you can leverage hybrid search, BM25, metadata pre-filtering, reranking, and other techniques to tailor retrieval for best results for the use case at hand.
Long context models are still LLMs, so they suffer from the same hallucination issues - they don’t have the domain-specific knowledge, proprietary data, or information about latest events in their training data. However, some folks claim that as the context window size increases we may be able to give an LLM all of the necessary data in a prompt instead of storing the data first, and retrieving relevant chunks of information. There is a certain appeal to this idea. By providing all of the information within a single context window, long-context LLMs can potentially understand the nuanced relationships between different data points, which can be a benefit compared to situations when not all relevant context is retrieved via RAG. Having a single prompt also promises to reduce the complexity of the entire system by avoiding preprocessing the data, chunking it, generating embeddings, storing it in a vector store, and figuring out the best method for retrieving relevant information.
However, despite the advancements in long context models, RAG remains an indispensable technique, offering clear advantages. Let's look into the core reasons why RAG persists.
Large Volumes of Data
Even though the size of the LLMs context window keeps growing, it still has a limit. Let’s take Gemini 1.5 Pro as an example. At the moment, it offers a 2M-token window size, which, for the English language, would translate into approximately 8,000,000 characters. This would equal around 1600 000 words or so, which in turn, is about 3400 Word pages with standard fonts and font sizes. To give you some perspective, a standard annual financial report from a publicly traded company can easily be 300-400 pages long, which means you can only feed your model about 10 documents of this type. This may be sufficient for a demo, but not in any realistic production-scale application.
Scalability and Cost-Effectiveness
Processing millions of tokens in a context window incurs substantial computational and financial costs, even with advancements in caching. Running inference with a model that supports millions of tokens in its context window, will require expensive compute, will inflate the cost of inference, while generating a response will take unacceptably long. This creates another practical limitation for long-context models, especially in applications requiring rapid responses or handling high-volume queries.
In contrast, the RAG approach can be more efficient as it only utilizes the most relevant pieces of information for a given query, reducing the number of tokens that need to be processed. By carefully curating what information is added into the context window through the retrieval process, RAG can offer much lower operational costs and fast responses.
Data Aggregation and Management
RAG systems are preferable in real-world enterprise use cases, particularly when dealing with diverse data sources. The data is typically aggregated from multiple data sources: some may be structured, and some may be unstructured. If some of the data is unstructured, it may come in a variety of native formats that you can’t necessarily directly pass to your LLM without initial preprocessing. On top of that, additional preprocessing is often required - some data may need to be cleaned from PII/PHI, enriched with custom use case specific context and metadata to address access controls, recency aspect of the documents, and more. With data constantly changing, managing the documents as well as their transformations and enrichments, is much more feasible in a RAG system where you can have scheduled ETL pipelines and a vector store/database. At Unstructured, we help enterprises build advanced RAG applications, and we see first-hand how important it is to ensure that data is accurately processed, and maintained up-to-date before it reaches any retrieval or LLM model pipeline.
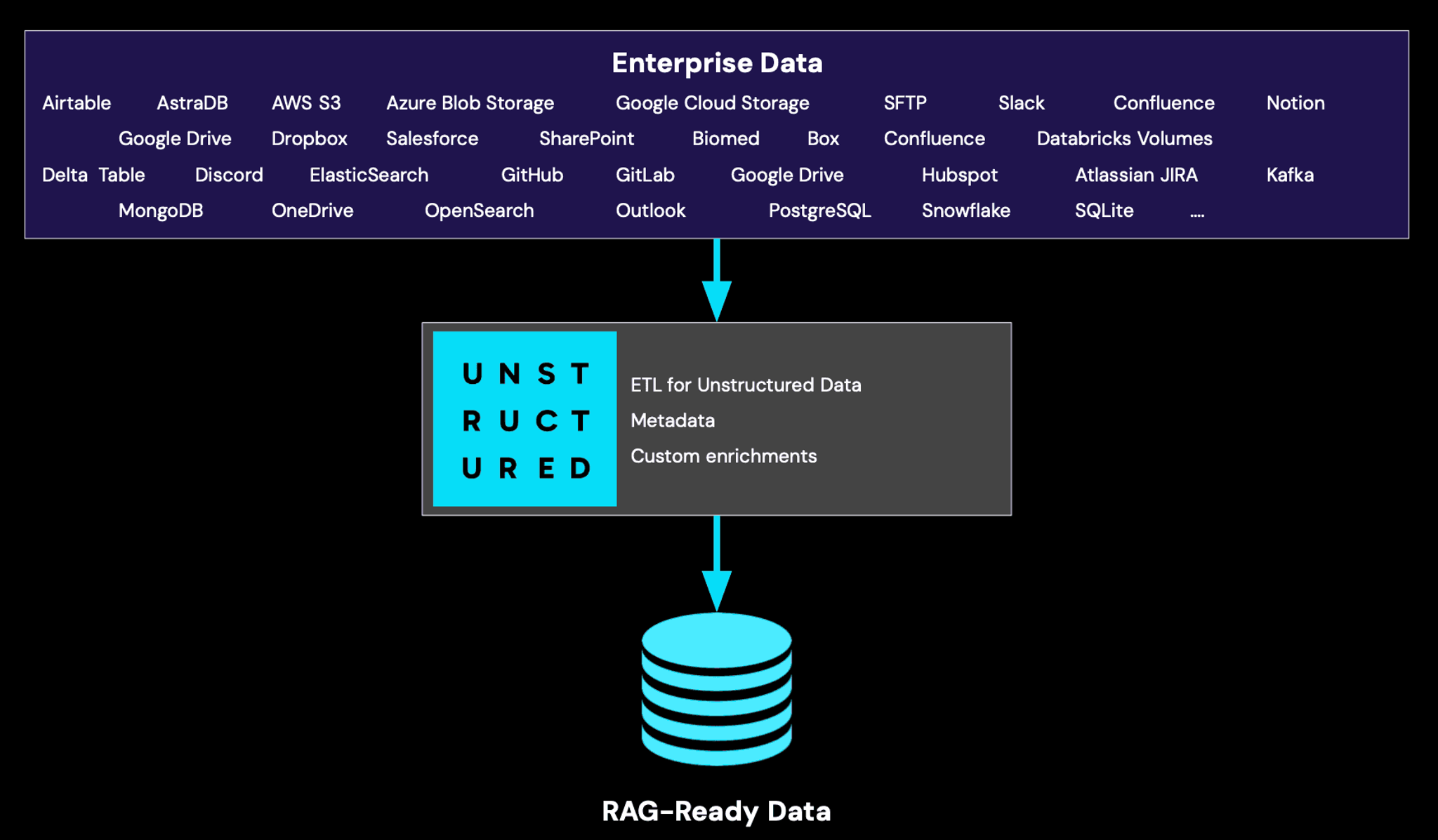
Our approach enables enterprises to transform raw data into LLM-ready formats, ensuring that all valuable information within unstructured sources—like PDFs, emails, scanned documents, and more — is fully utilized.
Explainability, Transparency, and Grounded Generation
RAG's ability to provide citations and trace information back to its source offers transparency and accountability that is critical in many use cases. This is especially vital in industries like finance, healthcare, and law, where decisions require a clear audit trail and accuracy is paramount. With long-context models, identifying the specific information that informed a response can be challenging, making it difficult to verify accuracy and debug potential hallucinations.
Role Based Access Control
Certain LLM-based applications require enforcement of role-based access control to data. This is impossible to ensure with all data being available at once in every prompt. RAG is a much more flexible system because it allows you to control data access by retrieving only the necessary, role-specific information for each query. By segmenting data and retrieving contextually relevant chunks at query time, RAG can enable precise, on-demand access that aligns with an organization’s access control policies.
Agentic and Other Advanced Capabilities
RAG lays the groundwork for more sophisticated agentic AI systems. It can be a component in a more complex system that uses LLMs to interact with various tools and data sources, allowing for more dynamic and complex interactions beyond traditional query-response paradigms. It facilitates the development of systems that can proactively retrieve information, search online, execute tasks, and adapt to changing situations.
When to Choose Long Context Over RAG
While in most real-world enterprise scenarios, long-context models are prohibitively expensive, and inflexible, there are situations in which long-context models might be preferable to RAG.
In use cases with many repetitive and overlapping queries over a small set of documents, a long context model may be a better fit than RAG. Let’s say your users are asking the LLM to summarize the same set of documents over and over. In this example, a long context window combined with a prompt caching approach may be a more suitable solution than RAG. When dealing with relatively static information and predictable queries, the simplicity of a long-context model with caching could outweigh the benefits of RAG.
Caching can enhance the efficiency of long context models, though it will not fully address the challenges that come with scale, cost, and latency.
RAG in an Infinite Context Future
Let's now consider a hypothetical future in which we have an LLM with infinite context. Even in such a scenario, we believe the RAG approach will remain relevant.
- Context Selection and Relevance: With infinite information accessible, the challenge shifts to effectively selecting and prioritizing the most pertinent context for a given query.Current long-context LLMs still struggle with the needle-in-a-haystack problem that may become even more pronounced with the hypothetical infinite context. The techniques employed in RAG build on decades of information retrieval approaches, and become even more critical for pinpointing the most relevant information amidst a sea of data.
- Computational Efficiency: Even with infinite context, computational resources remain finite. Efficient retrieval and selective use of context will still be necessary to manage processing demands and maintain responsiveness.
- Explainability and Compliance: Tracing the origin of information used to generate responses will remain critical for many applications, and cannot be solved by increasing LLMs context window size.
- RBAC: Role-based data access will remain important in many applications. In these situations the data that is passed to an LLM will still need to be retrieved taking into account user access permissions.
Conclusion
While long-context models offer compelling advantages, RAG remains a powerful and essential technique for enhancing LLMs, especially in real-world enterprise applications. Its ability to retrieve and integrate relevant information from external sources, along with its advantages in scalability, cost-effectiveness, and transparency, solidifies its position as a technique that will remain relevant. Even in a future with hypothetical infinite context, the principles of RAG, focusing on efficient context retrieval, access control, grounded generation, and responsible AI usage, will continue to be critical for building reliable and impactful LLM-based systems.
FAQ
What is retrieval augmented generation (RAG) and why is it used with LLMs?
RAG is a technique that retrieves relevant information from an external knowledge base and injects it into an LLM's prompt at query time. This grounds the model's responses in specific, up-to-date, or domain-specific data rather than relying solely on what was learned during training, which helps reduce hallucinations and improve accuracy.
Why can't long-context models fully replace RAG in enterprise applications?
Even the largest context windows available today can only fit a fraction of a real enterprise's data. Beyond volume limits, processing millions of tokens per request is computationally expensive and slow, and long-context models offer no mechanism for enforcing role-based access control or tracing which source informed a given response.
When does it make sense to use a long-context model instead of RAG?
Long-context models with prompt caching are a reasonable fit when users repeatedly query a small, relatively static set of documents with predictable questions. In that narrow scenario, the simplicity of loading all content into a single context window can outweigh the overhead of building and maintaining a retrieval pipeline.
How does Unstructured help prepare data for RAG pipelines?
Unstructured processes raw unstructured sources such as PDFs, scanned documents, HTML, and emails into clean, structured, LLM-ready formats. It handles the preprocessing steps that RAG depends on, including document parsing, chunking, PII removal, and metadata enrichment, so that what reaches your vector store is accurate and consistently formatted.
How does Unstructured support the data management requirements of enterprise RAG systems?
Unstructured enables enterprises to build scheduled ETL pipelines that aggregate data from multiple sources, apply transformations, and keep vector stores current as underlying documents change. This directly addresses one of RAG's core operational challenges: ensuring that the knowledge base reflects the latest information and is properly structured before it reaches any retrieval or LLM model pipeline.


