Build an end-to-end RAG chatbot for your personal e-book collection using the Unstructured Platform and MongoDB
Dec 6, 2024
Authors

In this guide, we’ll walk you through building a Retrieval-Augmented Generation (RAG) application that serves as your personal AI Librarian, helping you explore your digital book collection. You'll learn how to construct an unstructured data ETL pipeline for EPUB files using the Unstructured platform, leverage MongoDB Atlas as a vector store and search index, and orchestrate the RAG workflow with LangChain. Additionally, you'll develop an intuitive and interactive user interface using Streamlit, powered by a local llama3.1 model through Ollama. By the end of this tutorial, you’ll have a fully functional RAG application capable of engaging with your digital library, delivering precise and instant responses.
Prerequisites:
- Unstructured Platform access - More details HERE
- MongoDB account, a MongoDB Atlas cluster, and your MongoDB connection string (uri). Check out our documentation to learn how to prepare your MongoDB collection as a destination.
Find the code in this GitHub repo to follow along.
Switching from Serverless to Platform
If you’ve been using the Unstructured Serverless Ingest API, you’ll find all the features you know and love in a streamlined no-code interface. And if you haven’t tried Unstructured before, this is your chance to get up and running in minutes! Platform is a no-code evolution designed to empower even non-technical users with access to our world-class ETL solutions. Your data is processed seamlessly on Unstructured-hosted compute resources, removing the complexities of server management.
Unstructured Platform’s philosophy is simple: set it and forget it. Schedule your ETL pipelines, and let the Platform handle the rest. Plus, it comes packed with cutting-edge features, like image and table summaries, that enhance precision and elevate the performance of your RAG applications. We’re shipping new features fast, ensuring the Platform stays ahead of your needs. It’s a game-changer in simplicity and performance—are you ready to make the switch? Follow along in this blog post to see the steps to set up Platform to process all of your unstructured data files.
Unstructured Data ETL Pipeline
Every Retrieval-Augmented Generation (RAG) application begins with data: a comprehensive, relevant, and up-to-date knowledge base to provide the chatbot with essential context. For this tutorial, we want our AI Librarian to access a personal book collection stored locally in the common EPUB format. If you don’t already have books to use, you can download more than 70,000 free digital books from Project Gutenberg.
In this demo, the Unstructured Platform plays a critical role in preparing document data for ingestion into the knowledge graph. Unstructured's robust parsing and data extraction capabilities allow it to process diverse document formats—such as PDFs, HTML, or plain text—and produce structured outputs that preserve the semantic relationships within the content. To prepare these books for use in the app, we’ll construct an ETL (Extract, Transform, Load) pipeline on the Platform. In just a few clicks, our pipeline will:
- Extract the content of the EPUB books into document elements.
- Transform the document elements by chunking them into manageable text segments (read more about chunking here).
- Load the transformed data by creating vector representations of the text chunks using an embedding model and storing them in a vector database for retrieval.
In this tutorial, MongoDB Atlas will serve as the vector store, housing the processed book data for efficient querying and retrieval. Let’s dive in and get started!
Step 1: Fetching documents from our source (S3) with the Unstructured Platform
We start by creating a data source so Unstructured can access our documents. On the left sidebar select Connectors > Source > New and follow the setup instructions in our S3 source documentation.
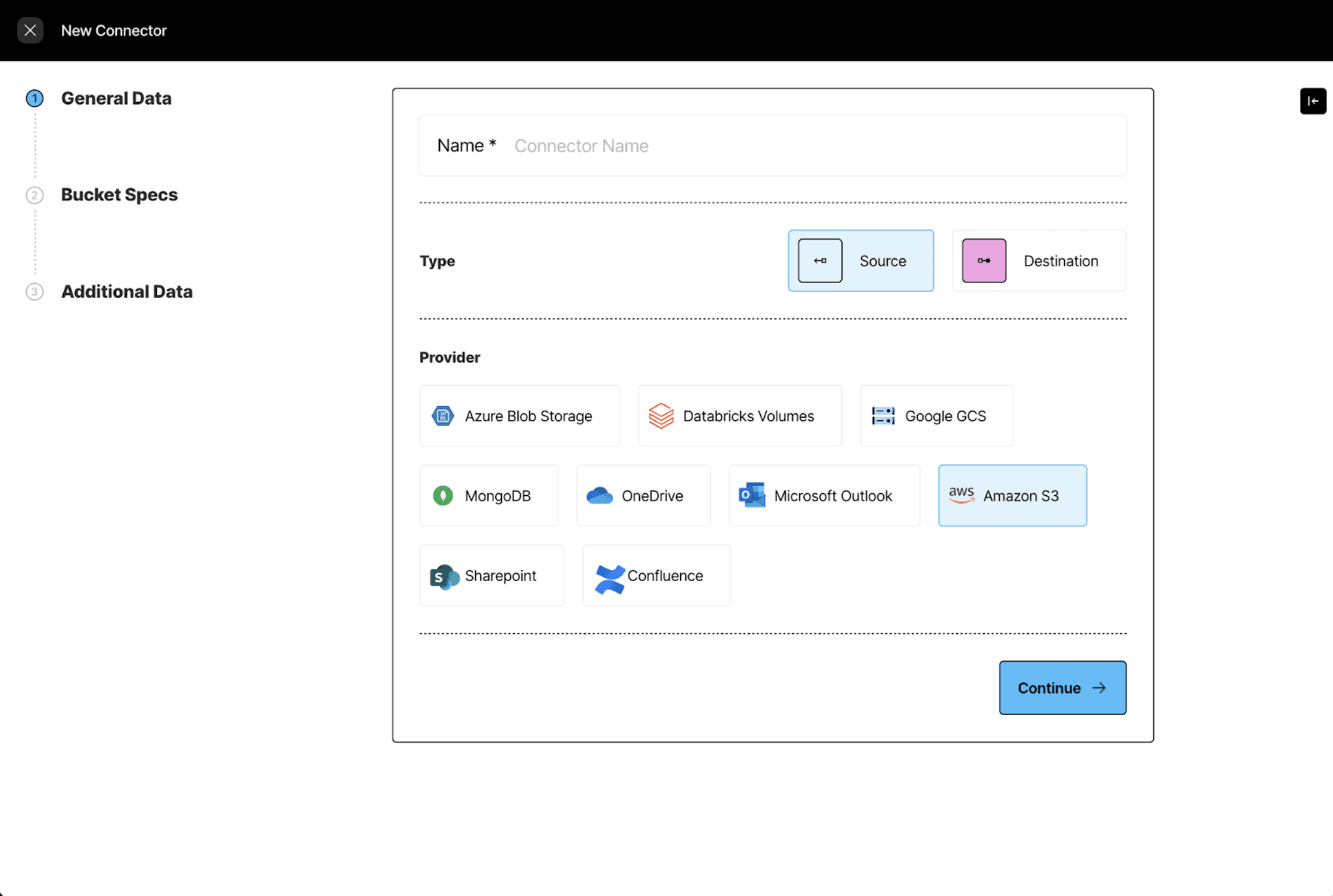
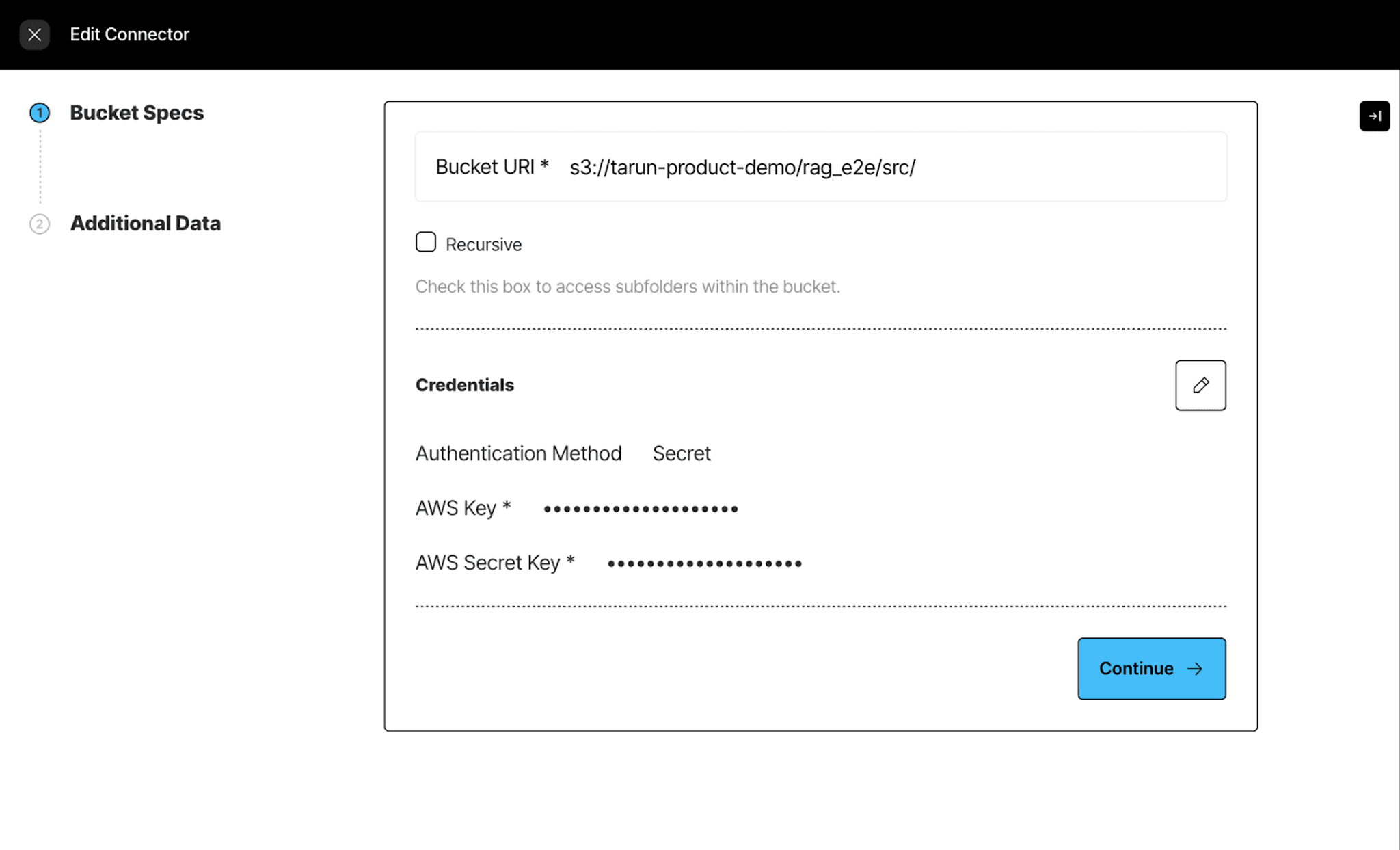
Next, we specify the S3 credentials to establish the connection.
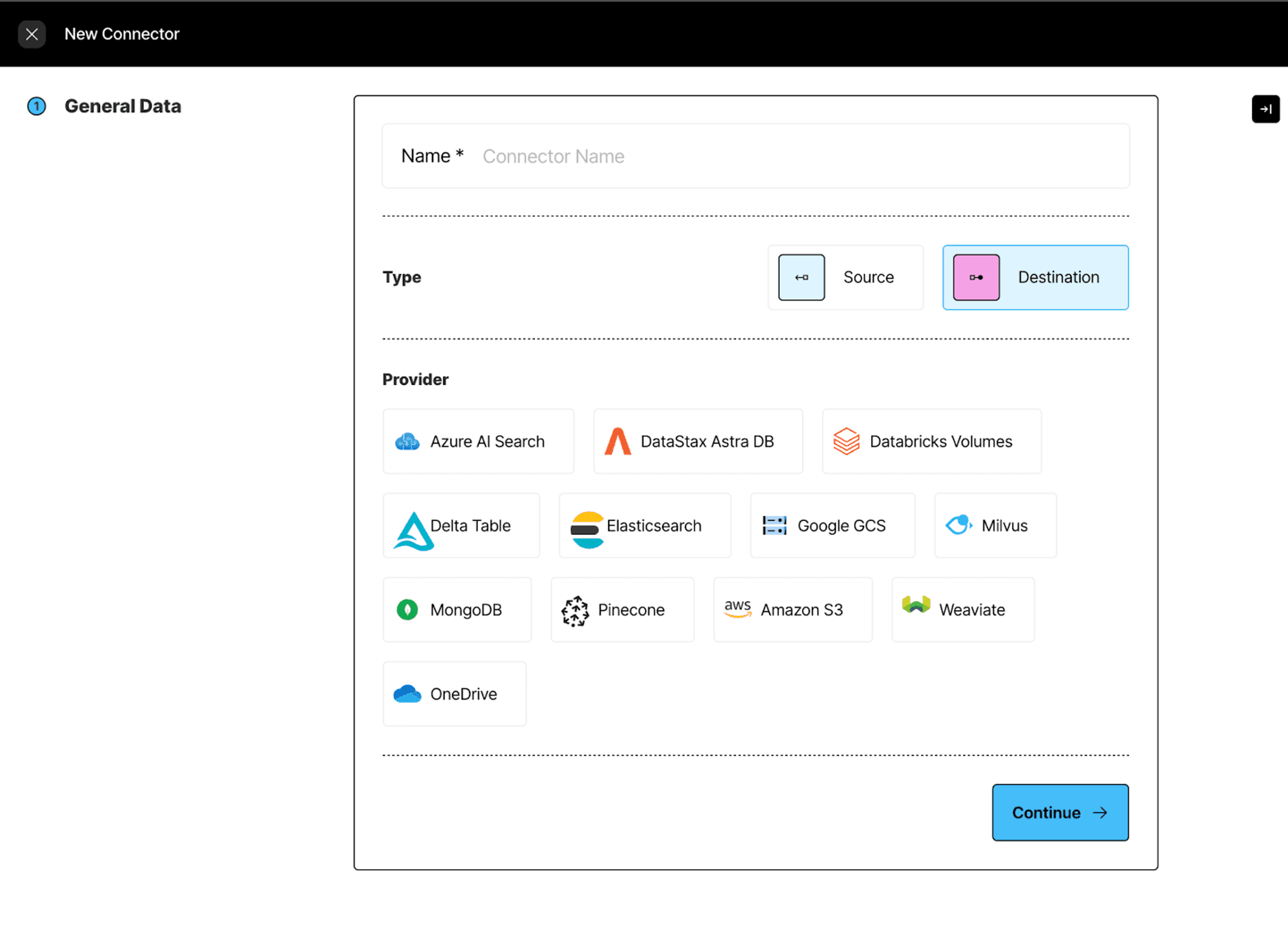
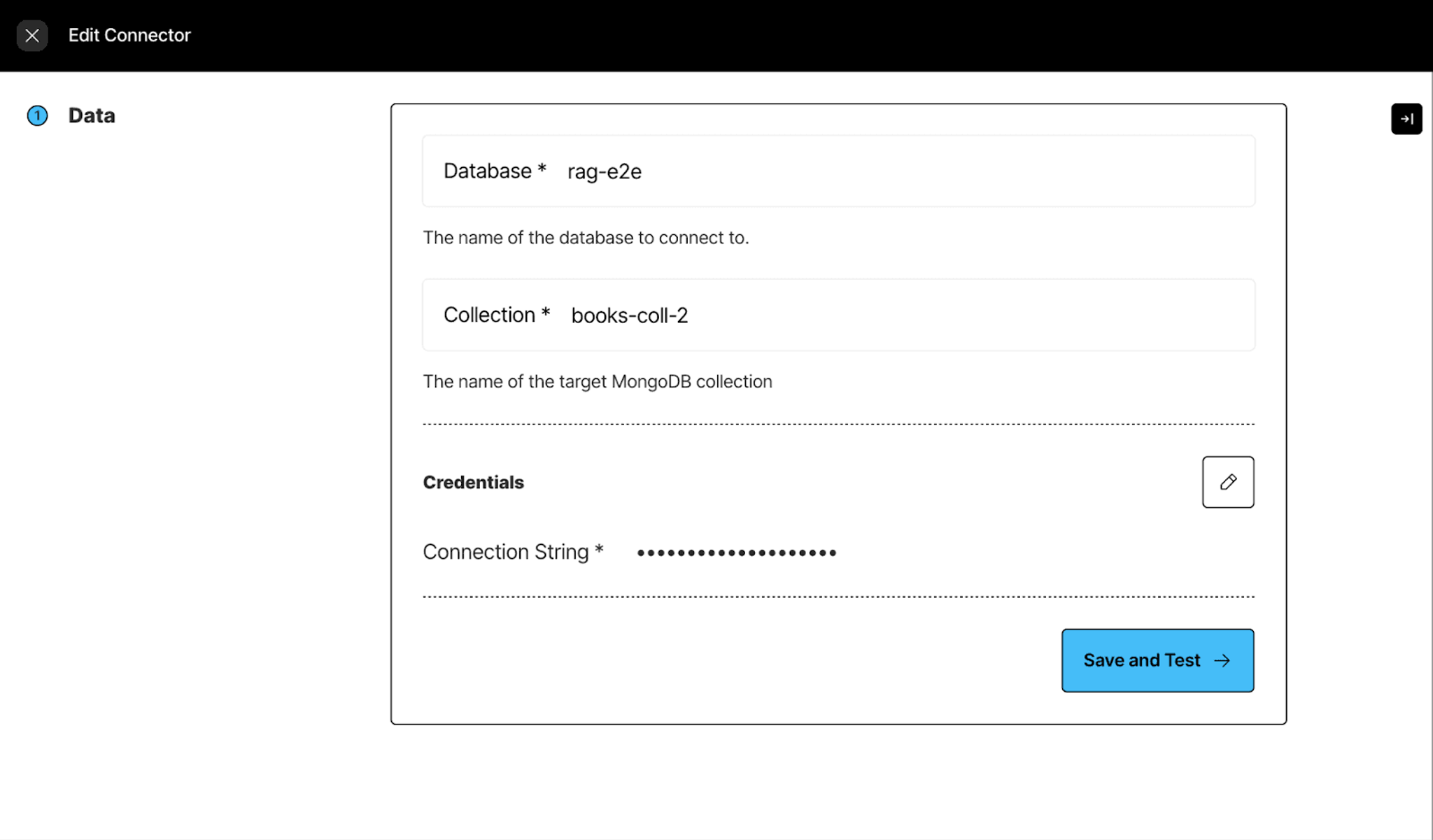
Step 2: Setting up our Destination Connector following our MongoDB destination documentation
Step 3: Construct your workflow for document processing
Select Workflows > New Workflow > Build it with Me
Select the source and destination connectors that we just created:
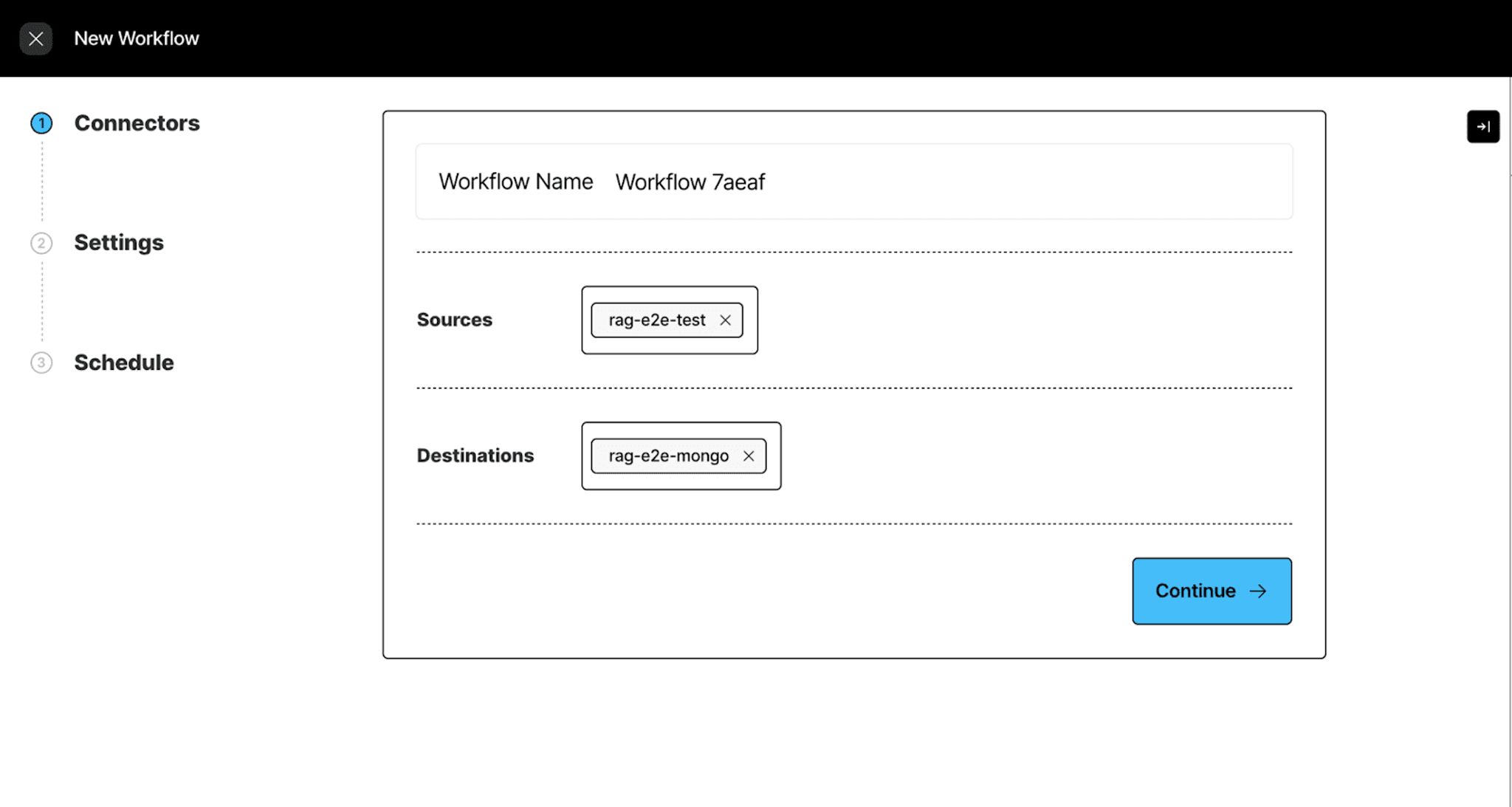
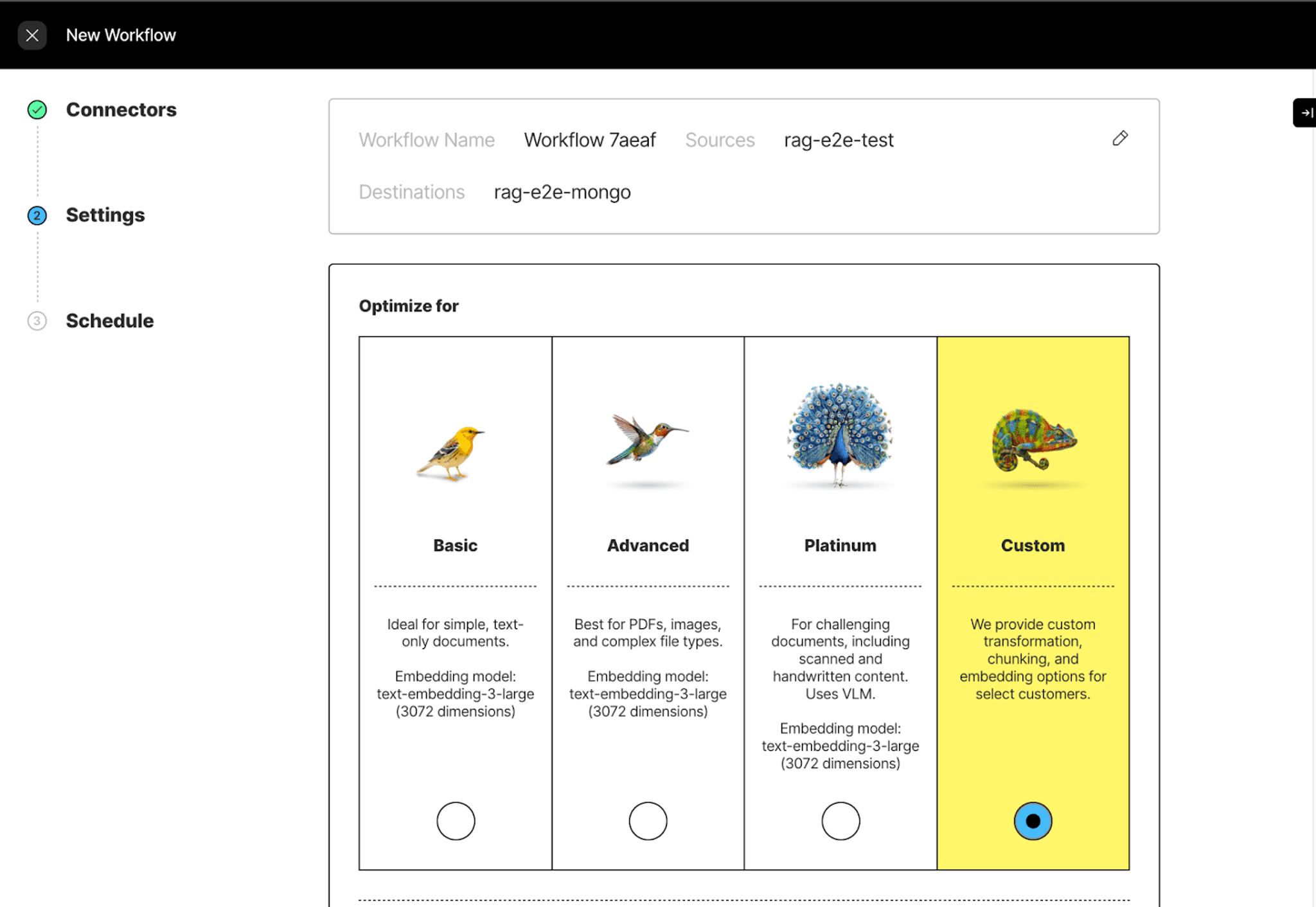
Then select custom to customize your workflow.
We are using the fast strategy since we are working with epub documents.
Let’s quickly review the parameters in this workflow creation form and what they mean:
Strategy:
- Basic / Fast is ideal for simple, text-only documents.
- Advanced / High Res is best for PDFs, images, and complex file types.
- Platinum / VLM is for challenging documents, including scanned and handwritten content.
Image Summarizers:
- Generates a description of the image content
- Example output includes details like image type, description of visual elements, and relevant metadata
Table Summarizers:
- Provides a textual summary of table contents
- Example output includes information about table structure, data trends, and key insights
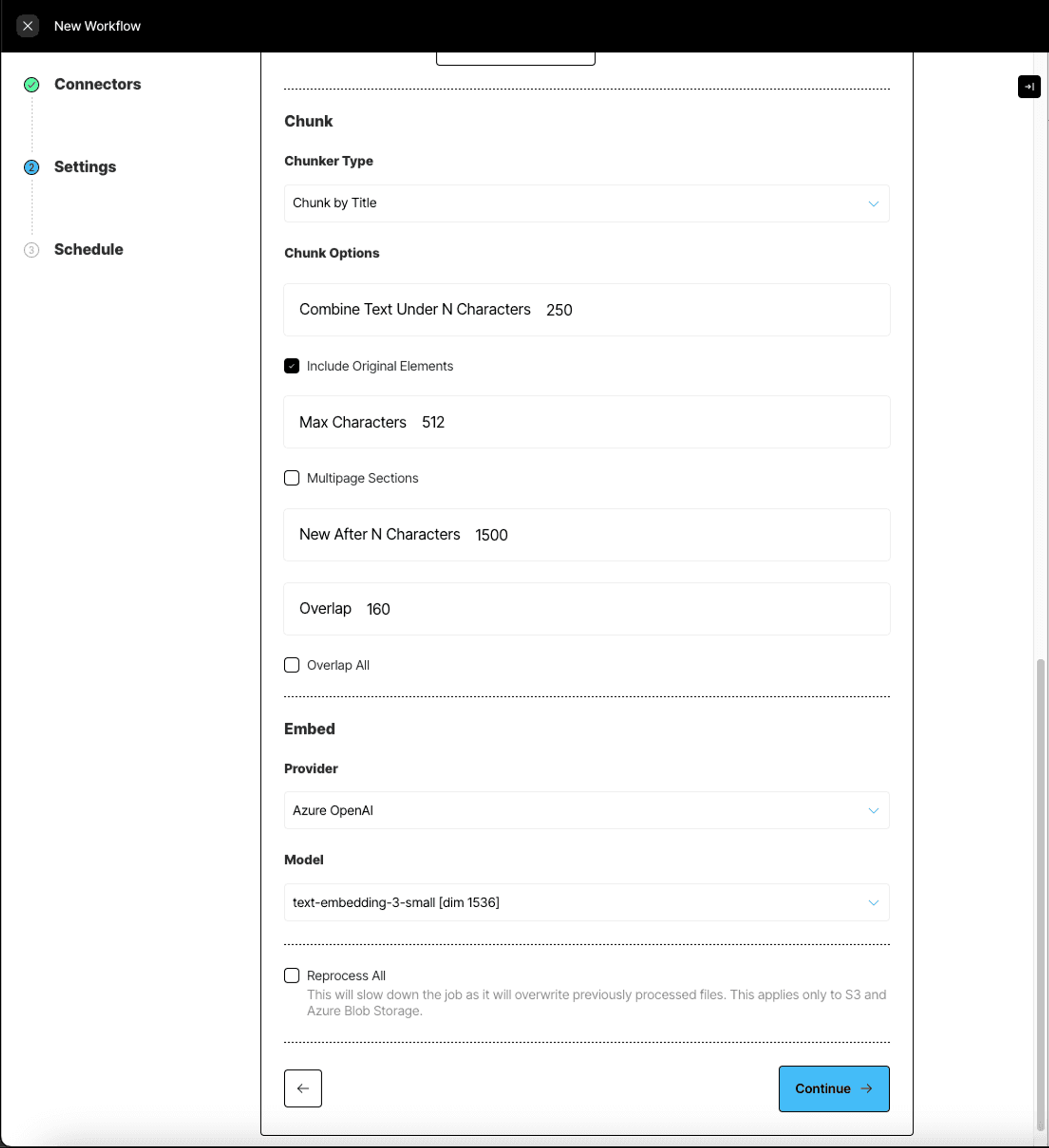
Chunking Types:
- Basic combines sequential elements up to specified size limits. Oversized elements are split, while tables are isolated and divided if necessary. Overlap between chunks is optional.
- By Title uses semantic chunking, understands the layout of the document, and makes intelligent splits.
- By Page attempts to preserve page boundaries when determining the chunks’ contents.
- By Similarity uses an embedding model to identify topically similar sequential elements and combines them into chunks.
Embed
- The Unstructured Platform uses optional third-party embedding providers such as OpenAI to generate semantically relevant embeddings on the extracted text.
This is the recommended way of setting up a workflow - granularly tuning every setting based on your data. If you want something quicker, you could also select one of the preset options available on the platform fast, hi-res and VLM to get started.
Finally, select the schedule at which you want to run this workflow.
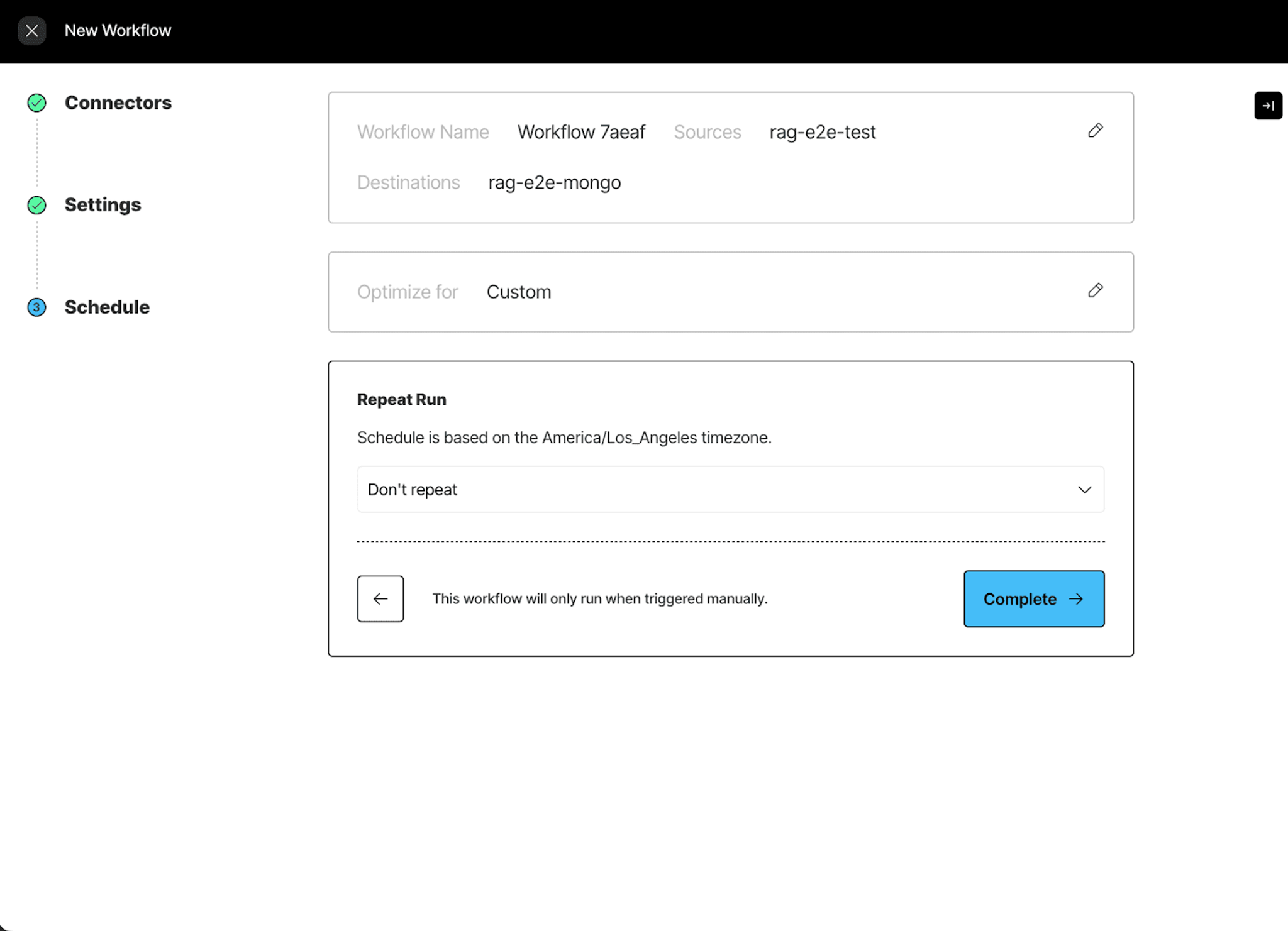
Our workflow is ready!
On the workflows page you should find the workflow you just created Workflow 7aeaf like this:
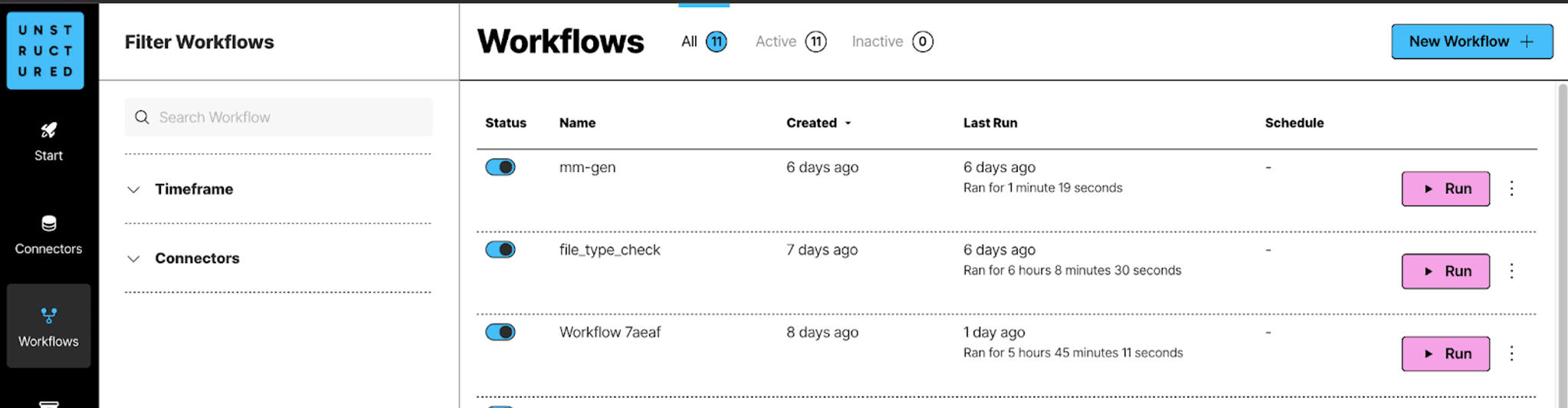
Simply hit "Run" to kick off the ETL workflow, and watch as your documents are processed automatically from start to finish.
You can monitor the progress of your workflow under the jobs pane.
At this point the data is preprocessed and loaded, we can set up the retriever for the chatbot.
Setting up the RAG pipeline
MongoDB Retriever
LangChain integrates seamlessly with MongoDB, allowing you to create retrievers based on an existing Vector Search Index. Here’s how you can set up a LangChain retriever using the index we just created:
Important: Ensure you use the exact same embedding model here as you did when preprocessing your documents. Consistency is key to accurate retrieval results.
Building a LangChain-Powered RAG Application
Now, let’s bring it all together by setting up a RAG chain using LangChain to orchestrate the process.
We’ll use the advanced Llama 3.1:8b model by Meta AI, available via Ollama, for the language model.
Key steps include:
- Defining a System Prompt: The prompt will guide the model to act as a well-informed AI Librarian, leveraging context to provide accurate responses to user queries.
- Enabling Memory: This feature allows for multi-turn conversations, maintaining context across interactions.
- Contextualizing User Questions: We’ll incorporate a mechanism to rephrase user queries, integrating them with the conversation history for more informed answers.
With these components in place, you’ll have a responsive and context-aware RAG application ready to handle queries about your digital book collection!
Streamlit UI for Your Digital Library Assistant
The final step in building your app is to create an engaging and intuitive user interface using Streamlit.
Setting Up the App Title
To begin, configure the app's title and set the page title:
Designing the UI Function
We’ll define a function, show_ui, to manage the app's interface. This includes initializing session state, displaying chat messages, and handling user inputs.
Running the App
To start the application, navigate to the folder containing your streamlit-app.py file in your terminal and run:
Trying It Locally
If you'd like to test the app on your own machine:
- Clone the repository from GitHub.
- Create a .env file in the project root directory and add your secret keys and configurations to it.
With these steps, you’ll have a fully functional UI for your Personal Digital Library Assistant, ready to interact with users and provide valuable insights from your digital book collection!
If you want to try this with your own epub collection, check out our AI Librarian repository and sign up for Platform to get started!


