
Authors

At Unstructured, we're always looking for ways to improve document preprocessing for Retrieval-Augmented Generation (RAG) systems. That's why we're excited to introduce Contextual Chunking, a powerful new feature in the Unstructured Platform. This enhancement tackles a key challenge in RAG implementations: preserving context during document chunking. By keeping document context together with a chunk, Contextual Chunking helps significantly improve retrieval results. Let's explore how it works and why it matters for your workflows.
The Context Challenge in Document Chunking
Data preprocessing for RAG systems involves breaking documents into smaller chunks before generating embeddings. While this approach works well for straightforward content, it has downsides when it comes to complex documents where context is crucial. Imagine chunking thousands of lengthy financial reports from different companies and time periods - a segment stating "revenue increased by 15%" isn't very useful without knowing which company, time period, or business it refers to.
Enter Contextual Chunking
Our new contextual chunking feature, inspired by Anthropic’s research, intelligently adds relevant contextual information to each chunk before it's embedded. It uses state-of-the-art language models to analyze the entire document and generate concise, meaningful context for each chunk.
How it Works
Here's what happens behind the scenes: when you enable contextual chunking in your workflow, each chunk gets a smart prefix that captures essential contextual information. Here's a real-world example from a financial report.
Without contextual chunking:
As of July 31, 2022, the aggregate market value of the voting common stock of
the registrant held by non-affiliates of the registrant, based on the closing
sale price of those shares on the New York Stock Exchange reported on July 29,
2022, was $186,168,142,989. For the purposes of this disclosure only, the
registrant has assumed that its directors, executive officers (as defined in
Rule 3b-7 under the Exchange Act) and the beneficial owners of 5% or more of
the registrant's outstanding common stock are the affiliates of the registrant.
The registrant had 2,695,655,933 shares of common stock outstanding as of March 15, 2023.
With contextual chunking:
Prefix: This chunk is from the annual report on Form 10-K for the fiscal year
ended January 31, 2023 filed by Walmart Inc., a large retail company, and it
provides information about the market value of the company's common stock.
Original: As of July 31, 2022, the aggregate market value of the voting common
stock of the registrant held by non-affiliates of the registrant, based on the
closing sale price of those shares on the New York Stock Exchange reported on
July 29, 2022, was $186,168,142,989. For the purposes of this disclosure only,
the registrant has assumed that its directors, executive officers (as defined
in Rule 3b-7 under the Exchange Act) and the beneficial owners of 5% or more
of the registrant's outstanding common stock are the affiliates of the registrant.
The registrant had 2,695,655,933 shares of common stock outstanding as of
March 15, 2023.
Proven Performance Improvements
This enhancement is particularly valuable when dealing with complex enterprise documents like financial reports, legal contracts, or technical documentation. The added context helps vector databases make more accurate similarity matches during retrieval, which means your RAG system can find the most relevant information more reliably.
The impact of contextual chunking is significant and measurable. According to Anthropic, this approach can reduce retrieval failures across multiple domains by 35% on average - a significant improvement that directly translates to better performance in downstream applications. Our own evaluation, focused on financial documents, also demonstrated impressive improvements in retrieval accuracy.
We have compiled an evaluation dataset of 5,563 question-answer pairs based on standard SEC filings (Form-10K), and measured the retrieval results. Our baseline evaluation system consisted of a basic RAG implementation (also called vanilla RAG or naive RAG) with the following characteristics:
- Similarity search without reranking
- ChromaDB as the vector database
- OpenAI "text-embedding-3-large" embedding model
- Top-20 document retrieval
We used 1 minus recall@20 as our primary evaluation metric, which measures the percentage of relevant documents that fail to be retrieved within the top 20 chunks. This metric captures the system's ability to surface pertinent information within a reasonable retrieval window.
We evaluated three distinct configurations while keeping all other parameters constant:
1) Baseline: Standard chunks without added context
2) Anthropic Configuration: Chunks contextualized using Anthropic's original prompt
3) Enhanced Configuration: Chunks contextualized using Unstructured's improved prompt
Anthropic's Prompt:
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.Unstructured's Prompt:
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Include a one sentence description of the document with identifying info.
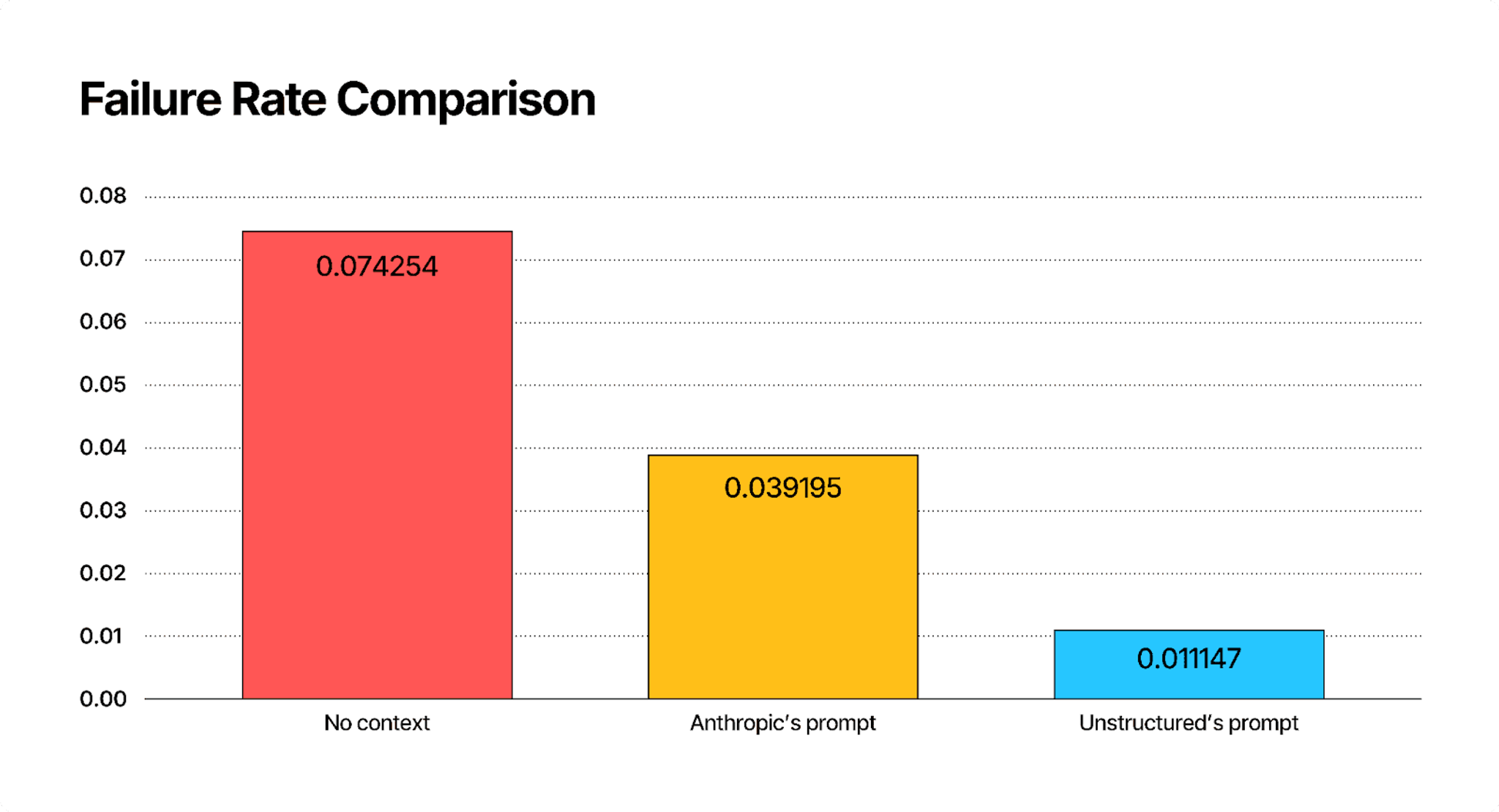
Answer only with the succinct context and nothing else.The evaluation yielded the following failure rates:
- Baseline (No Context): 0.074254
- Anthropic's Prompt: 0.039195 (47% reduction in failure rate over baseline)
- Unstructured's Prompt: 0.011147 (84% reduction in failure rate over baseline)
Considerations:
- Anthropic’s 35% failure rate reduction was measured across multiple domains, including academic papers and fiction. Our experiments show that in certain domains, like financial documents, the improvement may be even more pronounced.
- RAG implementation matters. Our results were measured for a basic RAG setup, however, your RAG implementation choices will also affect the performance. Choose the type of search (similarity, BM25, hybrid), embedding model, chunk size, reranker, metadata filters, and so on wisely and make sure to set up your own evaluations.
- Larger retrieval windows increase the likelihood of including relevant information. We additionally measured failure rates for retrieval @10 and saw that baseline RAG setup’s failure rate in this case increased to a staggering 0.23607, while the contextualized chunks performed the same. This indicates that simply increasing the retrieval window from 10 to 20 significantly improved the retrieval results. However, it’s important to note that excessive retrieval can exacerbate the needle-in-haystack problem as well as increase the costs. Experiment with the number of retrieved chunks to find the optimal window size for your use case.
Getting Started with Contextual Chunking in Unstructured Platform
Implementation couldn't be simpler. Within the Unstructured Platform, just enable the "Contextual chunking" toggle in your workflow's chunking settings. The feature integrates seamlessly with all our existing chunking strategies, whether you're chunking by character count, title, page, or similarity.
We've optimized the system for cost-effectiveness through intelligent prompt caching, ensuring minimal impact on your processing costs while maximizing retrieval accuracy.
Take Your RAG System to the Next Level
Ready to dramatically improve your document retrieval accuracy? Contextual Chunking is currently available to select customers, contact our team today to:
- Enable Contextual Chunking for your organization
- Get personalized guidance on optimizing your RAG implementation
- Schedule a demo to see the impact firsthand
FAQ
What is contextual chunking and why does it matter for RAG?Contextual chunking is a preprocessing technique that adds a concise, LLM-generated prefix to each document chunk before embedding. The prefix captures identifying information from the full document, such as the company name, time period, or document type, so that chunks carry enough context to be retrieved accurately even when their raw text is ambiguous.
How does document complexity affect retrieval quality in RAG systems?In straightforward documents, standard chunking works reasonably well because individual segments tend to be self-explanatory. In complex enterprise documents like financial reports, legal contracts, or technical manuals, chunks frequently lack the surrounding context needed for accurate similarity matching, which leads to higher retrieval failure rates and degraded downstream answer quality.
What retrieval window size should I use when building a RAG pipeline?There is no universal answer, but the tradeoff is real: a larger retrieval window increases the chance of surfacing relevant chunks but also introduces noise and raises inference costs. Testing across window sizes and measuring recall at each threshold is the most reliable way to find the right balance for your specific use case and document type.
How does Unstructured's contextual chunking prompt differ from Anthropic's original approach?Unstructured's prompt adds one specific instruction: include a one-sentence description of the document with identifying information. That small change produced a measurable difference in evaluation results on SEC Form 10-K filings, reducing retrieval failure rates by 84% compared to baseline, versus 47% for Anthropic's original prompt under the same test conditions.
How does contextual chunking integrate with existing workflows in the Unstructured platform?Contextual chunking is enabled through a single toggle in the chunking settings of any workflow and is compatible with all of Unstructured's existing chunking strategies, including character count, title, page, and similarity-based approaches. The feature also uses prompt caching to keep processing costs low, so teams can apply it at scale without a significant increase in per-document cost.


