

Authors

Prerequisites:
- Unstructured Serverless API key - get yours here.
- MongoDB account, a MongoDB Atlas cluster, and your MongoDB connection string (uri). Check out MongoDB’s Getting Started guides to learn how to set these up.
Find the code in this GitHub repo to follow along.
Unstructured data ETL Pipeline
Every RAG application starts with data: a knowledge base with relevant and up-to-date information that will feed the chatbot with crucial context. For this tutorial, we want the AI Librarian to be able to access the personal book collection that we have stored locally in a common EPUB format. If you need some books to get started, you can download over 70,000 free digital books from the Project Gutenberg website.
Let’s make these books ready for our app! To do so, we’ll need to build an ETL (extract, transform, load) pipeline to extract the content of the books into document elements, chunk the document elements into appropriately sized pieces of text (read more about chunking here), create vector representations of the chunks with an embedding model, and load the results into a vector store for later retrieval.
In this tutorial, we’ll be using MongoDB Atlas to store the processed books.
The whole ETL pipeline can be created with just a few lines of Python code:
Pipeline.from_configs(
context=ProcessorConfig(
verbose=True,
tqdm=True,
num_processes=20
),
indexer_config=LocalIndexerConfig(input_path=os.getenv("BOOKS_PATH"),
recursive=False),
downloader_config=LocalDownloaderConfig(),
source_connection_config=LocalConnectionConfig(),
partitioner_config=PartitionerConfig(
partition_by_api=True,
api_key=os.getenv("UNSTRUCTURED_API_KEY"),
partition_endpoint=os.getenv("UNSTRUCTURED_URL"),
strategy="fast"
),
chunker_config=ChunkerConfig(
chunking_strategy="by_title",
chunk_max_characters=512,
chunk_multipage_sections=True,
chunk_combine_text_under_n_chars=250,
),
embedder_config=EmbedderConfig(
embedding_provider="langchain-huggingface",
embedding_model_name=os.getenv("EMBEDDING_MODEL"),
),
destination_connection_config=MongoDBConnectionConfig(
access_config=MongoDBAccessConfig(uri=os.getenv("MONGODB_URI")),
collection="unstructured-demo",
database="books",
),
stager_config=MongoDBUploadStagerConfig(),
uploader_config=MongoDBUploaderConfig(batch_size=10)
).run()Let’s unpack what’s going on here. Unstructured supports ingesting data from 20+ locations via easy-to-use source connectors, and uploading processed data into 20+ destination connectors.
The ETL pipeline above is constructed from multiple configs that define different aspects of its behavior:
- ProcessorConfig: defines the general parameters of the pipeline’s behavior - logging, parallelism, reprocessing, etc.
- LocalIndexerConfig, LocalDownloaderConfig, and LocalConnectionConfig are the configs for the Local source connector. Our books are stored in a local directory, so we are using the Local source connector to ingest them. The only mandatory parameter here is the input_path that points to where the books are stored.
- PartitionerConfig: Once the books are downloaded from their original source, the first thing Unstructured will do is partition the documents into standardized JSON containing document elements and metadata. We’re using Unstructured Serverless API here, but if you set the partition_by_api parameter to False, all processing will happen locally on your machine. The fast strategy here lets Unstructured know that we don’t need complex OCR and document understanding models to extract content from these files. Learn more about partitioning strategies here.
- ChunkerConfig: Once all of the books are partitioned, the next step is to chunk them. The parameters in this config control the chunking behavior. Here, we want the chunk size to be under 512 characters, but not smaller than 250 characters, if possible. Learn about chunking best practices in our recent blog post.
- EmbedderConfig: The final processing step is to embed chunks with an embedding model. Unstructured supports multiple popular model providers - specify your favorite provider and model in this config.
- MongoDBConnectionConfig, MongoDBUploadStagerConfig, MongoDBUploaderConfig: The three final configs define how you will authenticate yourself with MongoDB and upload the results.
Note that these configs don’t have to be in this exact order, but it helps to organize them this way to understand the flow of the data.
Once the data is preprocessed and loaded into a MongoDB Atlas database, navigate to your MongoDB account, and create a vector search index from the table. Find the detailed steps here. Use the JSON Editor to define your data’s fields - you can find an example in the tutorial’s GitHub repo.
Note: Don’t forget to whitelist the IP for the Python host (your IP) in Network Access, otherwise you will get connection errors when attempting to retrieve data.
At this point the data is preprocessed and loaded, we can set up the retriever for the chatbot.
MongoDB Retriever
LangChain integration with MongoDB supports creating retrievers from an existing Vector Search Index, here’s how we can create a LangChain retriever with the index we’ve just created:
def get_retriever():
vectorstore = MongoDBAtlasVectorSearch.from_connection_string(
connection_string=os.getenv("MONGODB_URI"),
namespace="books.unstructured-demo",
embedding=HuggingFaceEmbeddings(model_name=os.getenv("EMBEDDING_MODEL")),
text_key="text",
embedding_key="embeddings",
)
return vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})Make sure to use the exact same embedding model here as the one that you used when preprocessing the documents.
LangChain-powered RAG
Finally, let’s build a RAG chain using LangChain to orchestrate the whole process.
- We’ll use the latest Llama3.1:8b model by Meta AI, available through Ollama.
- We’ll define a system prompt that will instruct the model to behave as a knowledgeable AI Librarian and use provided context to generate answers to user questions.
- We’ll enable memory to have multi-turn conversations and a prompt to rephrase a user’s question to contextualize it with the conversation history.
def get_chain():
retriever = get_retriever()
local_model = "llama3.1:8b"
model = ChatOllama(model=local_model,
num_predict=500,
stop=["<|start_header_id|>", "<|end_header_id|>", "<|eot_id|>", "<|reserved_special_token"])
system_prompt = """
<|start_header_id|>user<|end_header_id|>
You are a helpful and knowledgeable AI Librarian. Use the following context and the user's chat history to
help the user. If you don't know the answer, just say that you don't know.
Context: {context}
Question: {question}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
rag_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{question}"),
]
)
rag_chain = (
{
"context": RunnableLambda(get_question) | retriever | format_docs,
"question": RunnablePassthrough()
}
| rag_prompt
| model
)
contextualize_q_system_prompt = """Given a chat history and the latest user question \
which might reference context in the chat history, formulate a standalone question \
which can be understood without the chat history. Do NOT answer the question, \
just reformulate it if needed and otherwise return it as is."""
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
runnable = contextualize_q_prompt | model | rag_chain
chat_memory = ChatMessageHistory()
def get_session_history(session_id: str) -> BaseChatMessageHistory:
return chat_memory
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="question",
history_messages_key="chat_history",
)
return with_message_historyStreamlit UI
The final step is to give the app a nice looking UI which we will add using Streamlit.
First, let’s give the app a title:
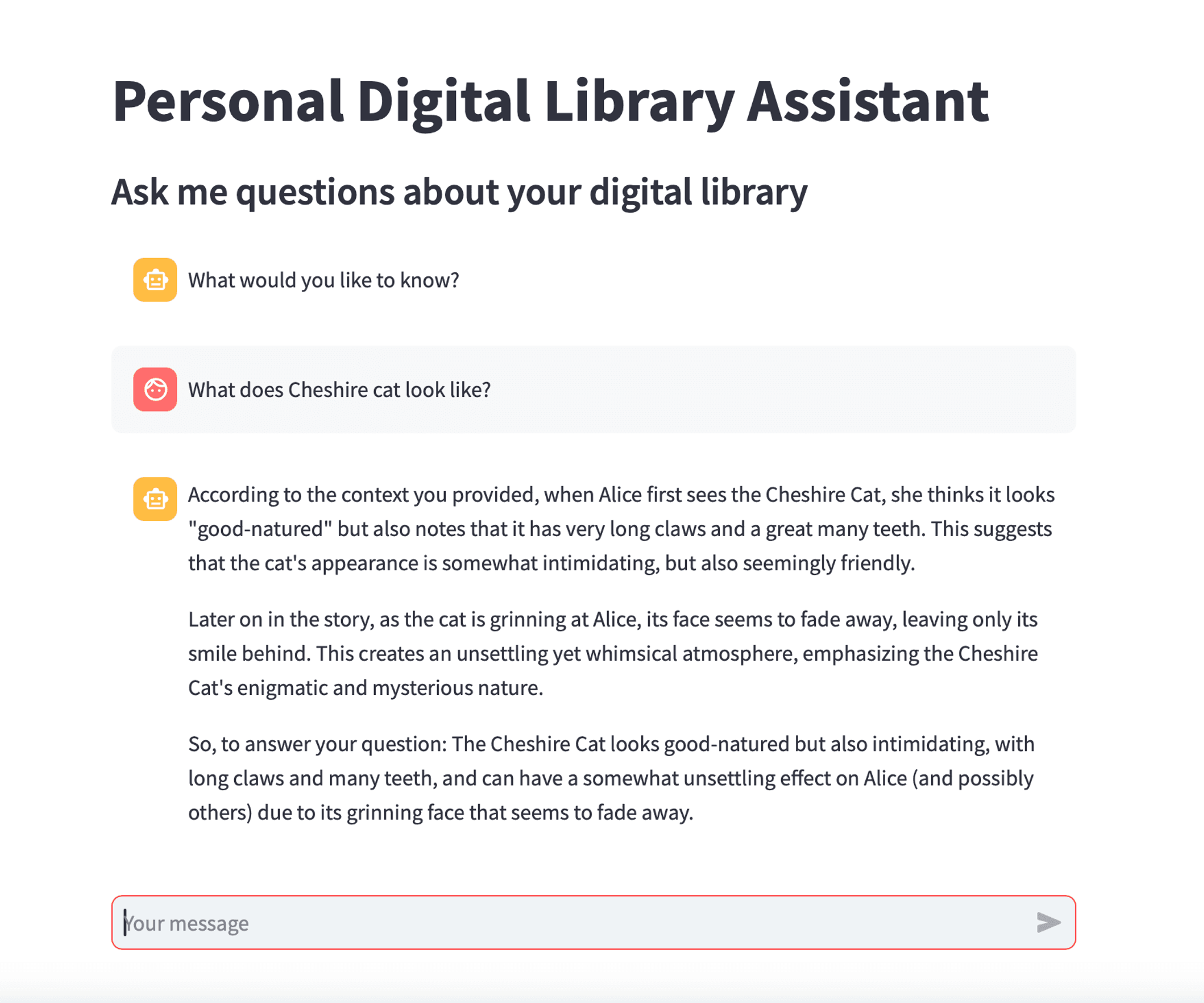
st.set_page_config(page_title="Personal Digital Library Assistant")
st.title("Personal Digital Library Assistant")Next, let’s define a function that will display the app’s UI:
- Initialize session state values and initial prompt to the user.
- Display existing chat messages.
- If a message has been entered, append the message to the messages list in the session state and display the message in a chat bubble.
- Generate a response if the last message is from the user.
def show_ui(qa, prompt_to_user="How may I help you?"):
if "messages" not in st.session_state.keys():
st.session_state.messages = [{"role": "assistant", "content": prompt_to_user}]
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# User-provided prompt
if prompt := st.chat_input():
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# Generate a new response if last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Flipping pages..."):
response = ask_question(qa, prompt)
st.markdown(response.content)
message = {"role": "assistant", "content": response.content}
st.session_state.messages.append(message)Running the app
Finally, to run the app, all we need to do is to navigate to the location of the streamlit-app.py file in your terminal and call streamlit run streamlit-app.py
If you’d like to try this example on your own machine, clone this GitHub repo, create .env in the project’s root and add your secrets to it.
You can easily modify this app to use any of the other 20+ file types supported by Unstructured including PDFs, markdown, HTML, and more!
Get your Serverless API key today and start building! We look forward to see what you build with Unstructured Serverless. If you have any questions, we’d love to hear from you! Please feel free to reach out to our team at hello@unstructured.io or join our Slack community.


