
Authors

When working with Retrieval-Augmented Generation (RAG), fast and efficient querying of processed document data is essential. MotherDuck, a serverless analytics platform built on DuckDB, offers a unique hybrid execution model that combines local speed with cloud scalability, making it a great choice for RAG workloads.
That's why we're excited to announce Unstructured's integration with MotherDuck! With this new integration, teams can seamlessly preprocess all of their unstructured data - enrich it, chunk it, embed it, and store it in a structured format optimized for AI applications in MotherDuck. Whether you're handling small datasets or scaling to the cloud for larger workloads, Unstructured and MotherDuck make it easier than ever to build scalable, high-performance RAG pipelines.
Why MotherDuck?
MotherDuck merges DuckDB's efficiency with cloud scalability, providing a unique architecture that combines local processing with cloud-based analytics. This design allows data engineers to execute queries seamlessly, leveraging both local and cloud resources as needed.
Key features of MotherDuck that enhance RAG implementations include:
- Native Support for Vector Operations: MotherDuck handles vector operations efficiently, enabling effective similarity searches and embedding manipulations.
- Integration with Python Data Science Libraries: MotherDuck works seamlessly with Python, allowing data engineers to utilize familiar tools and libraries in their workflows.
- Serverless Architecture: MotherDuck's serverless design eliminates the need for infrastructure management, enabling teams to focus on building and optimizing their RAG systems.
The Integration in Action
The Unstructured’s MotherDuck integration allows you to upload processed document data directly into your MotherDuck database. This includes all extracted text, metadata, and embeddings from your documents, organized in a structured JSON format optimized for RAG applications.
Setting Up the Integration
To get started with the MotherDuck integration, you'll need:
- A MotherDuck account
- A MotherDuck access token
- A database and schema in your account. Find an example of schema in the docs.
Using the Unstructured UI
1) Navigate to the Connectors section in your Unstructured dashboard.
2) Click "Destinations" followed by "New" or "Create Connector".
3) Give your connector a unique name.
4) Select "MotherDuck" as the provider.
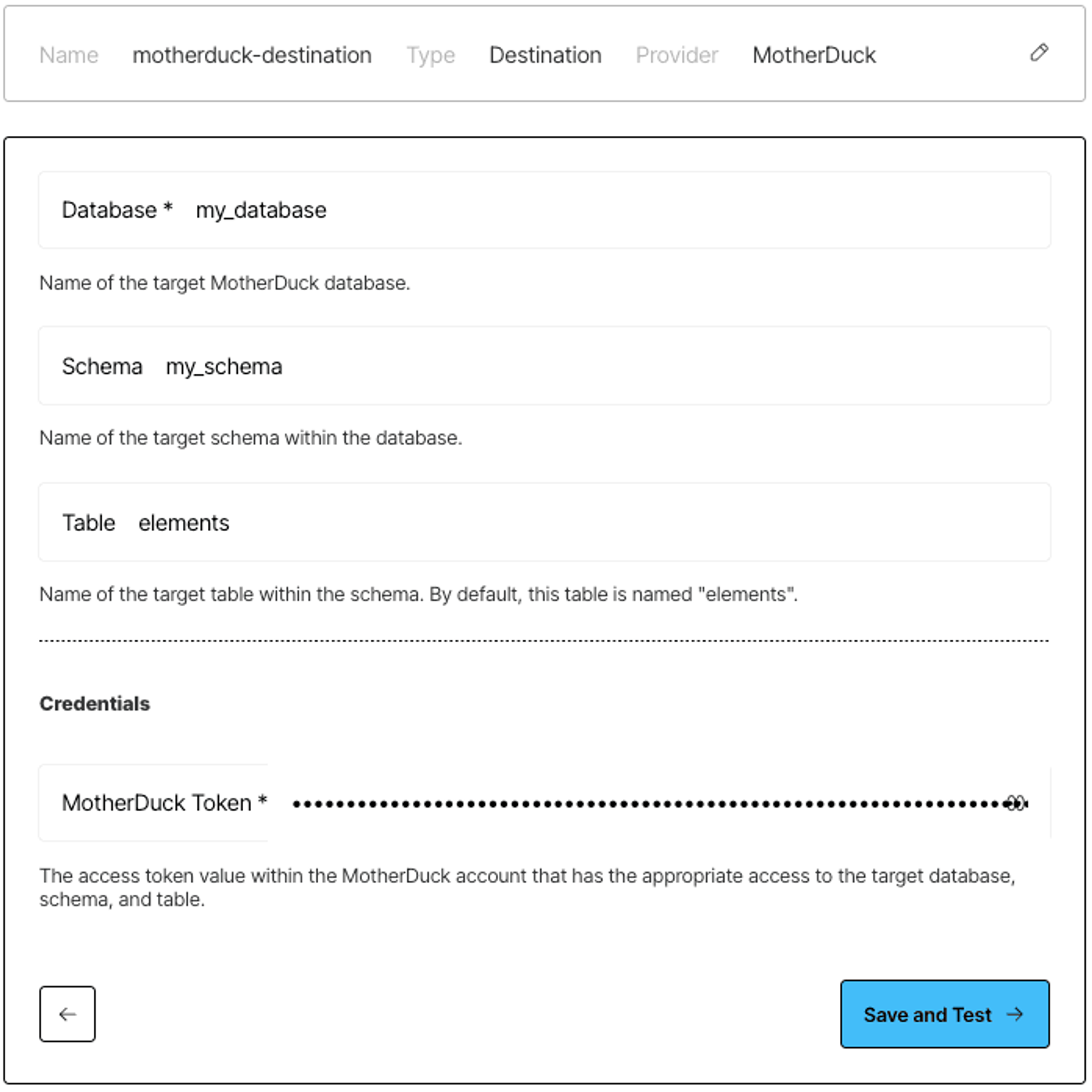
5) Fill in the required fields: database name, schema name, table name (defaults to 'elements' if not specified), MotherDuck token.
Here is an example of a completed set of fields for the connector:
Using the Unstructured API
You can also set up the integration programmatically using the Unstructured API.
With curl:
curl --request 'POST' \
--location "$UNSTRUCTURED_API_URL/destinations" \
--header 'accept: application/json' \
--header "unstructured-api-key: $UNSTRUCTURED_API_KEY" \
--header 'content-type: application/json' \
--data '{
"name": "<name>",
"type": "motherduck",
"config": {
"database": "<database>",
"db_schema": "<db-schema>",
"table": "<table>",
"md_token": "<md-token>"
}
}'With Unstructured Python SDK:
import os
from unstructured_client import UnstructuredClient
from unstructured_client.models.operations import CreateDestinationRequest
from unstructured_client.models.shared import (
CreateDestinationConnector,
DestinationConnectorType,
MotherDuckDestinationConnectorConfigInput
)
with UnstructuredClient(api_key_auth=os.getenv("UNSTRUCTURED_API_KEY")) as client:
response = client.destinations.create_destination(
request=CreateDestinationRequest(
create_destination_connector=CreateDestinationConnector(
name="<name>",
type=DestinationConnectorType.MOTHERDUCK,
config=MotherDuckDestinationConnectorConfigInput(
database="<database>",
db_schema="<db-schema>",
table="<table>",
md_token="<md-token>"
)
)
)
)
print(response.destination_connector_information)The integration supports a comprehensive table schema that includes all the fields you need for RAG applications, including text content, embeddings, metadata, and more. The complete schema is available in our documentation.
Get started!
If you're already an Unstructured user, the MotherDuck integration is available in your dashboard today!
Expert access
Need a tailored setup for your specific use case? Our engineering team is available to help optimize your implementation. Book a consultation session to discuss your requirements here.


