Unstructured Leads in Document Parsing Quality: Benchmarks Tell the Full Story
Nov 18, 2025
Authors

For too long, the conversation around document parsing quality has relied on outdated metrics that don't capture what actually matters. Traditional OCR-era evaluation frameworks designed for deterministic systems systematically misrepresent the capabilities of modern generative parsing solutions, resulting in inadequate evaluation of today's document parsing tools.
Today, we're sharing our internal evaluation results using SCORE (Structural and Content Robust Evaluation), a framework purpose-built for the generative era. The data shows Unstructured delivering strong performance across the metrics that matter for production document processing. More importantly, we're open-sourcing the evaluation methodology so the community can verify these results independently on their own data and apply the SCORE evaluation framework to any document parsing solution.
Why Traditional Metrics Miss the Mark
Legacy evaluation approaches assume a single "correct" output exists for every document. But generative systems often produce semantically identical content in structurally different forms. Consider a simple table showing quarterly revenue:
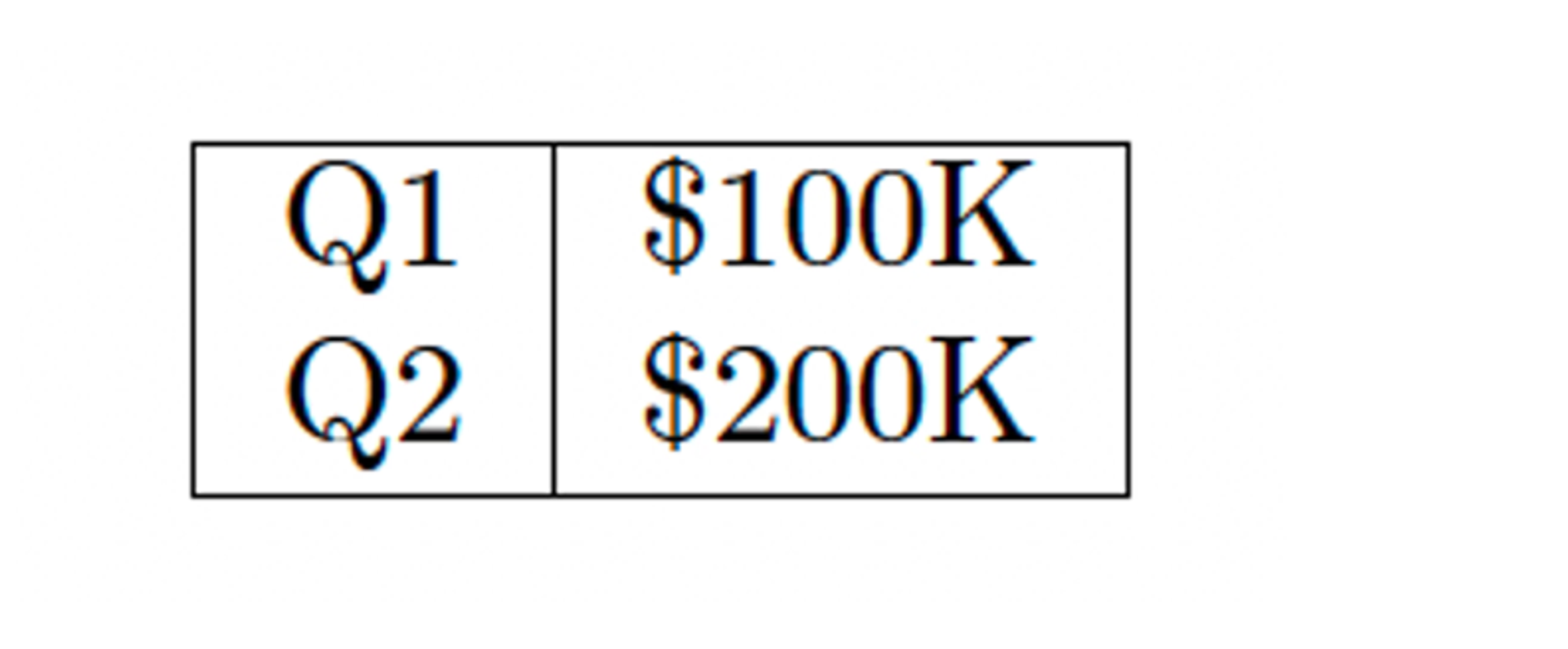
One parser might extract it row-wise as "Q1 $100K Q2 $200K" while another outputs column-wise as "Q1 Q2 $100K $200K." Both preserve the complete information. Both enable downstream applications to succeed. Yet traditional character-based metrics would penalize one as fundamentally "wrong".
This isn't a corner case, but the norm with modern document parsing. A system generating semantically rich HTML with proper hierarchical structure gets punished by metrics designed for plain text. Another might score near-perfectly on string matching while introducing subtle hallucinations that break RAG applications. Single-number evaluation scores obscure these critical trade-offs.
The implications extend beyond misleading benchmarks. Teams make technology decisions based on flawed comparative data. Research directions optimize for the wrong objectives. Production deployments fail because laboratory metrics don't predict real-world performance.
SCORE: Evaluation for the Generative Era
SCORE addresses four fundamental limitations of traditional evaluation:
Adjusted CCT corrects the CCT/NED score by applying word-weighted fuzzy alignment across different elements (tables, paragraphs), recognizing semantic equivalence despite structural variation. When two systems represent the same data differently but preserve all relationships, we treat them as equivalent rather than penalizing interpretation differences.
Token-Level Diagnostics separate content omissions from hallucinations. Instead of conflating missing information with fabricated content, we measure recall (Tokens Found) and precision (Tokens Added) independently providing actionable diagnostics about where systems actually fail.
Semantic-First Table Evaluation scores based on content similarity rather than bounding box overlap. Generative systems don't produce explicit coordinates, so we developed format-agnostic evaluation that normalizes HTML, JSON, and plain text into comparable representations while incorporating spatial tolerance for legitimate variations.
Hierarchy-Aware Consistency assesses whether systems maintain coherent document organization. We map heterogeneous labels like "title," "sub-title," and "sub-heading" to functional categories, enabling semantic-level comparison across different labeling schemes.
The framework moves beyond single scores to multi-dimensional assessment. Rather than asking "how accurate is this system?", we can now answer "what are its content fidelity characteristics, hallucination risks, coverage completeness, and structural understanding capabilities?"
For teams evaluating document parsing solutions, this matters enormously. A system optimized for zero hallucinations might sacrifice content coverage. Another might excel at structural interpretation while being less consistent on raw text fidelity. SCORE makes these trade-offs visible and measurable.
Benchmarking the Landscape
We evaluated Unstructured against other leading document parsing tools (both commercial and open source), including Reducto, LlamaParse, Docling, Snowflake’s AI_PARSE_DOCUMENT layout mode, Databricks' ai_parse_document, and NVIDIA's nemoretriever-parse.
The benchmark was conducted on Unstructured’s internal dataset of real-world enterprise documents, not curated academic content, but the messy reality most organizations face: scanned invoices, multi-column layouts, nested tables, handwritten annotations, and documents from industries like healthcare, finance, and manufacturing.
For Unstructured, Reducto, and Docling, we tested multiple pipeline configurations. For the other tools, we used their default configurations.
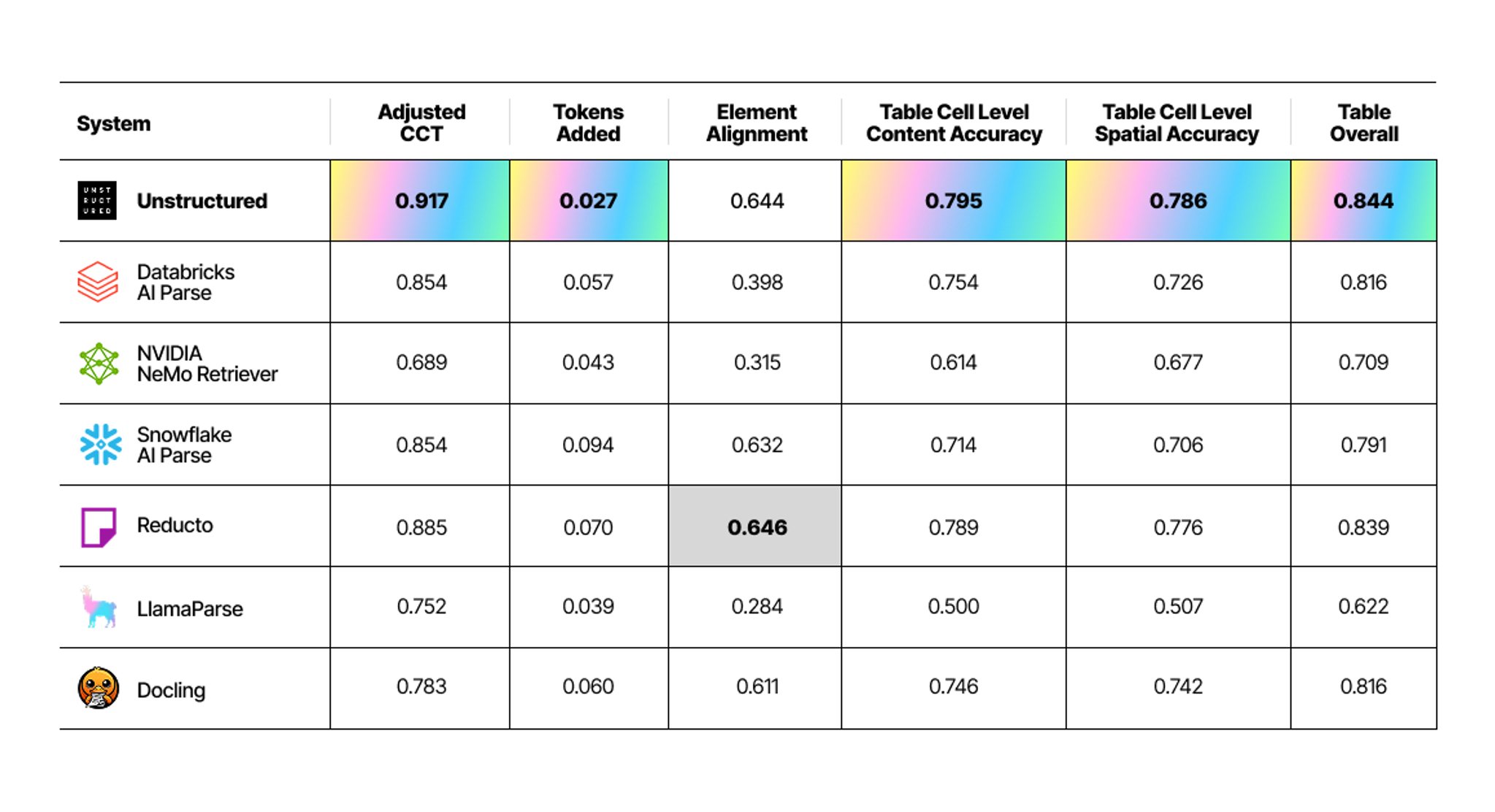
Here's how the landscape looks across the tools. The table below reports each system's best result regardless of pipeline:
These results cover over 1,000 pages and evaluate multiple dimensions of document understanding:
Content Fidelity: Unstructured achieved an Adjusted CCT score of 0.917, demonstrating strong semantic preservation while tolerating format differences.
Hallucination Control: Hallucination is a silent killer for RAG applications. This metric directly tracks spurious tokens introduced by the parser. Unstructured pipelines show the lowest Tokens Added rate at 0.027.
Structural Understanding: Unstructured's Element Alignment of 0.644 indicates solid hierarchy-aware consistency, performing comparably to other leading tools on maintaining coherent document organization.
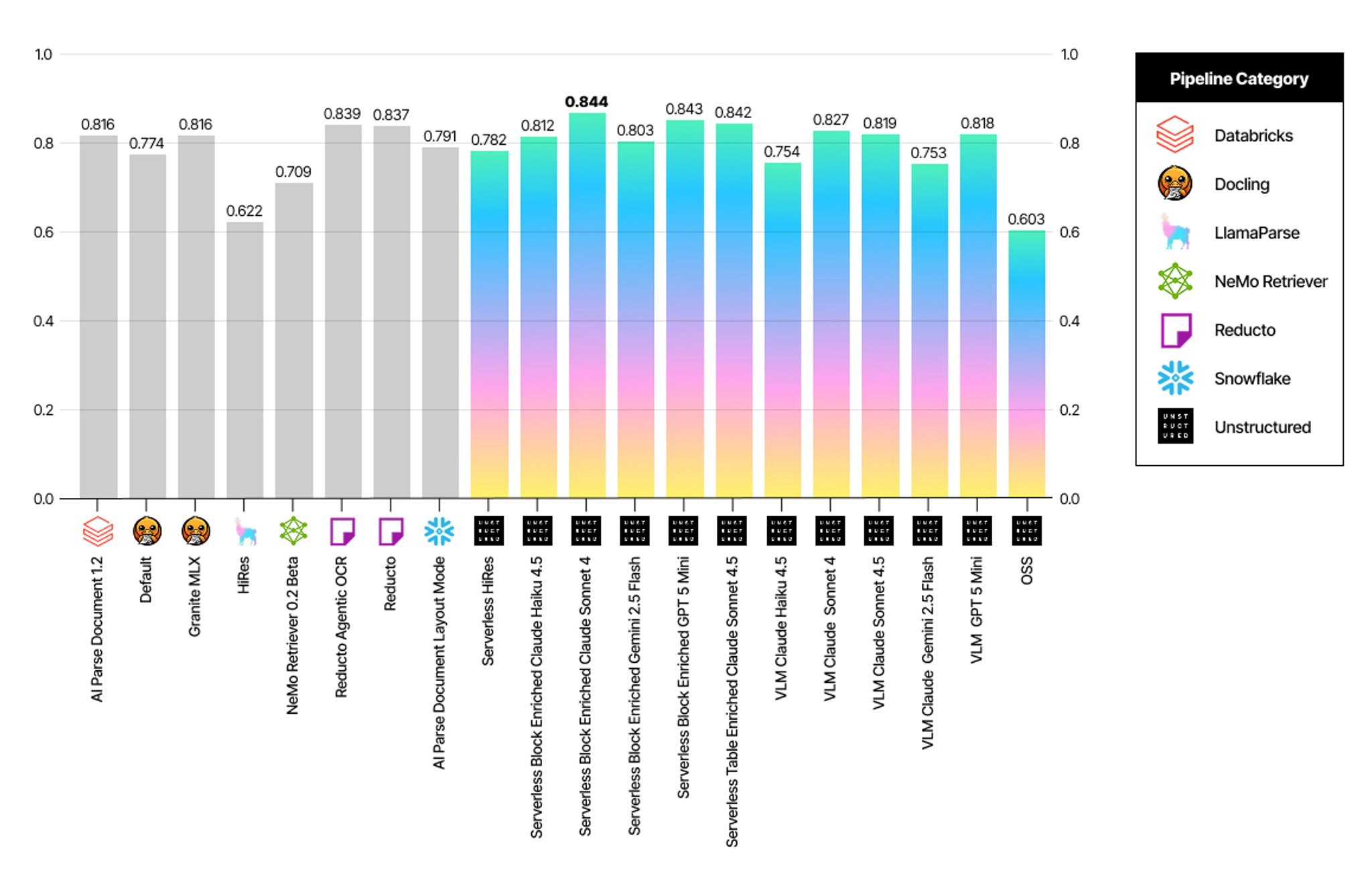
Table Extraction Excellence: Unstructured leads with an overall table score of 0.844, combining superior cell-level content accuracy (0.795), cell-level spatial accuracy (0.786), and table detection. This represents strong performance in format-agnostic table processing.
These differences translate to meaningful advantages in production environments. Unstructured's pipelines deliver strong content fidelity and precision, achieving low hallucination rates and accurate end-to-end table extraction. This translates directly to fewer downstream failures, higher RAG accuracy, better search relevance, and more reliable agentic systems.
The Full Picture
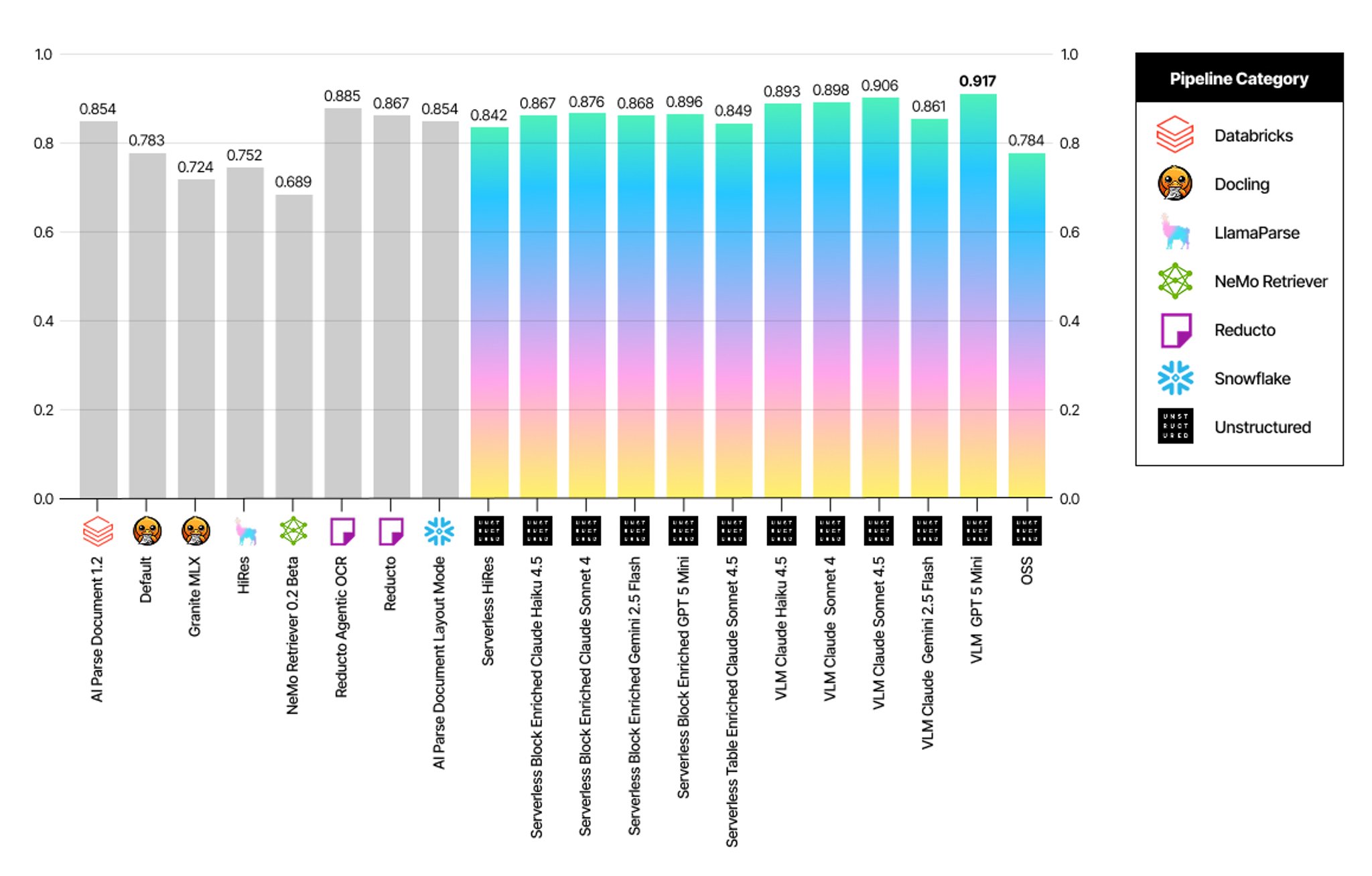
To provide complete transparency, we're sharing detailed results for every pipeline configuration we tested. The charts below show how different Unstructured pipelines each using different VLMs and enrichment strategies perform across the above SCORE metrics.
What the data reveals:
- Different pipelines excel at different tasks: Some configurations optimize for table extraction, others for content fidelity, and others for structural understanding
- Trade-offs exist: A pipeline with the highest table accuracy might have slightly different hallucination characteristics than one optimized for element alignment
- Consistent leadership: Across the diversity of configurations, Unstructured pipelines consistently outperform competitors on key metrics
- Informed choice: You can select the pipeline that best matches your specific document types and downstream requirements
Adjusted CCT by pipeline
Tokens Added by pipeline

Element Alignment by pipeline
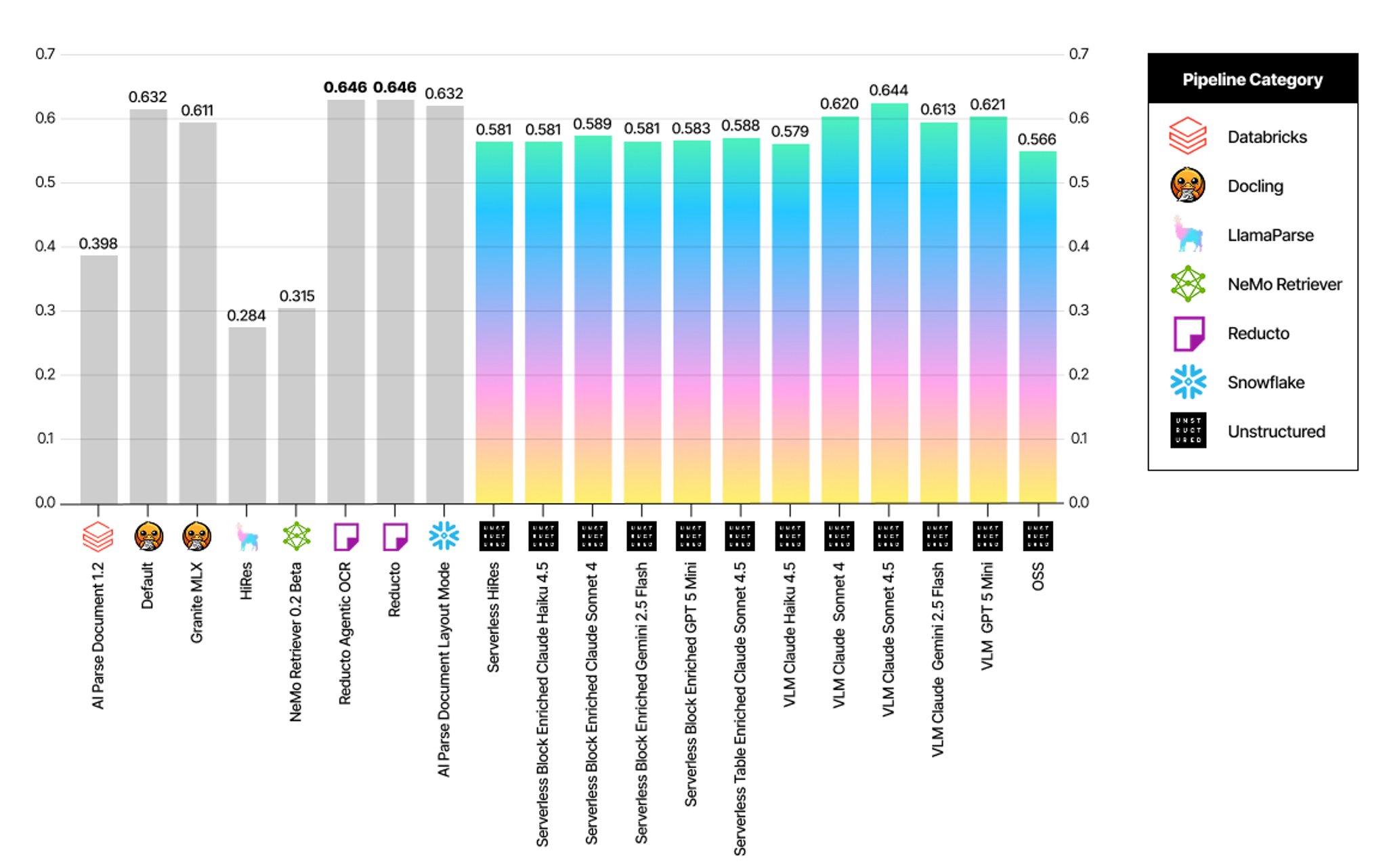
Table Cell Level Content Accuracy by pipeline
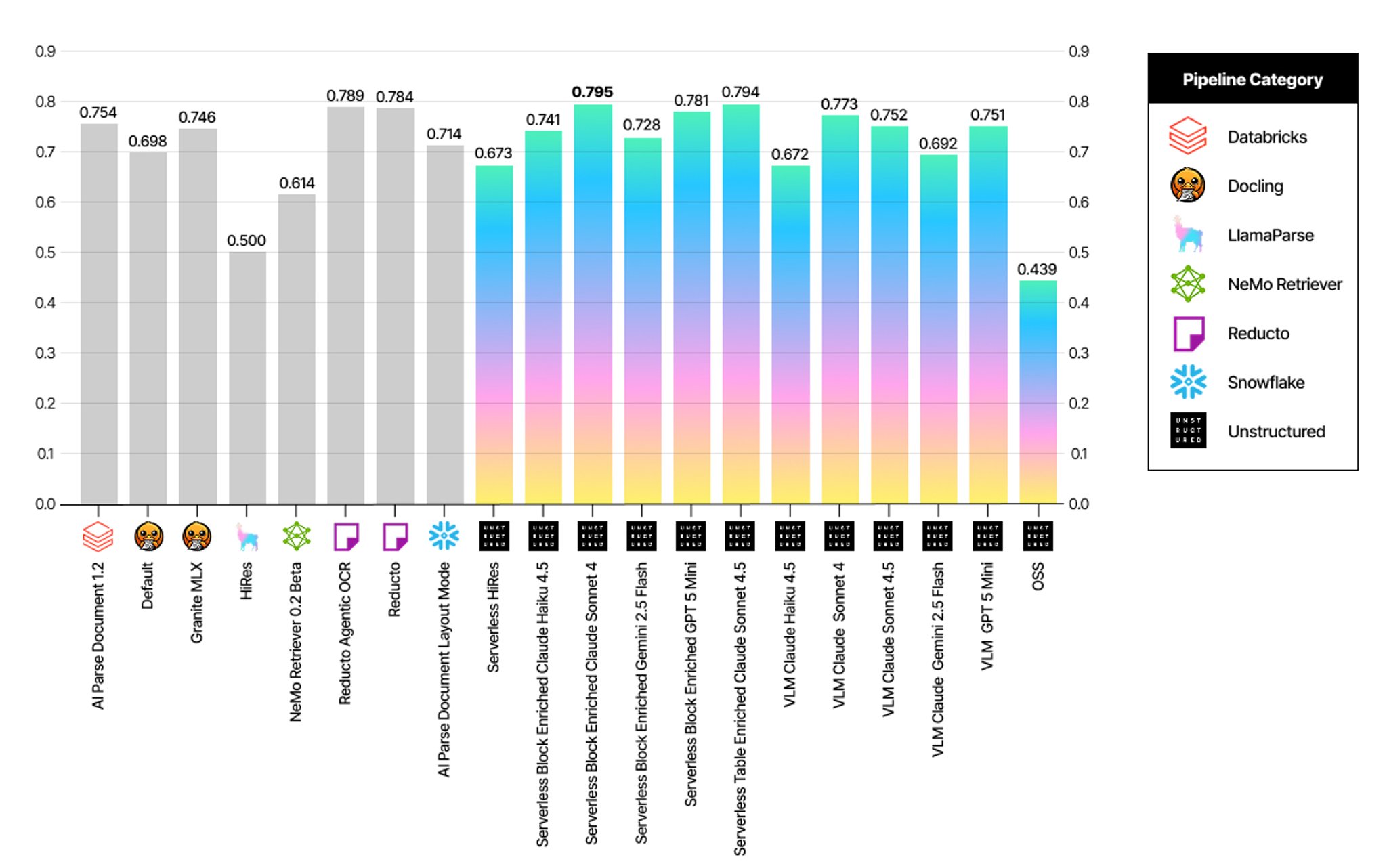
Table Cell Level Spatial Accuracy by pipeline

Table Overall Score by pipeline
Most document parsing vendors show you a single number from their best-case scenario. We're showing you the full spectrum of results across different models, and document partitioning strategies. Why?
- Because you deserve to make informed decisions. When you understand the trade-offs between different pipelines, you can choose the one that aligns with your specific requirements. Need maximum table accuracy for financial documents? We can show you which pipeline delivers that. Prioritizing minimal hallucinations for RAG applications? The data is right here.
- Because we're confident in our results. Unstructured doesn't need to hide behind cherry-picked examples. Our pipelines lead across metrics because we've invested deeply in the science of document understanding.
- Because the landscape keeps evolving. By openly benchmarking our pipelines against competitors and new models, we can quickly identify when a new model or pipeline configuration delivers better results and make it available to you.
The Power of Choice
At Unstructured, we don't limit you to a single parsing strategy. Our platform integrates multiple approaches and a wide selection of leading vision-language models, with every option rigorously benchmarked against real-world scenarios. When new models and techniques emerge, we evaluate, optimize, and make them available if they improve results.
This philosophy extends beyond just having options. It's about continuous improvement without vendor lock-in. You're never forced to wait for a monolithic system to improve. As the field advances, you benefit immediately from new capabilities that match your needs. Additionally, if you need anything custom, we’re prepared to help. From prompt tuning to model hosting, we can tailor pipelines for your specific needs.
Real-World Data, Rigorous Evaluation
Our evaluation dataset deliberately captures enterprise document complexity: scanned forms at fax quality, financial reports with deeply nested tables, technical manuals with multi-column layouts, and documents with handwritten annotations. This reflects what production systems actually encounter, not cherry-picked examples optimized for impressive benchmark claims.
The evaluation scripts on GitHub demonstrate exactly how to calculate individual SCORE metrics, include labeled examples following our annotation conventions, and provide the framework for teams to benchmark on their own data.
Unlike closed benchmarks where methodology remains opaque, we're open-sourcing the evaluation framework itself. Teams can:
- Replicate our methodology on their own document collections
- Label their domain-specific content using our annotation conventions
- Calculate SCORE metrics with the same scripts we use internally
- Compare systems fairly using format-agnostic, interpretation-aware evaluation
This turns SCORE from theoretical framework into a practical tool. Whether you're processing legal contracts, medical records, or manufacturing specifications, you can now measure what actually matters for your use case.
Stay tuned, in the next several weeks we’ll also be releasing a diverse subset of our internal evaluation dataset, composed entirely of publicly shareable documents. This subset will act as a standardized benchmark for the SCORE framework, enabling consistent and transparent evaluation across the industry.
Try It Yourself
We invite you to experience Unstructured's document parsing quality firsthand. Simply drag and drop a file from the Start page after login, and test the high-fidelity transform with generative refinement enrichments on your most challenging documents.
The benchmarks tell the story. The methodology is open. The data speaks for itself. Try Unstructured, and discover why leading teams rely on Unstructured to power production AI pipelines.
For technical details on the SCORE framework, see our research paper. To explore the evaluation methodology and run your own benchmarks, visit the GitHub repository. For questions about Unstructured's platform capabilities, contact our team.
FAQ
Why do traditional document parsing metrics produce misleading benchmark results?
Traditional metrics assume a single correct output exists for every document, which causes them to penalize semantically equivalent outputs that differ in structure. For example, a table extracted row-wise versus column-wise may preserve identical information, but character-matching metrics will score one as incorrect. This leads teams to make technology decisions based on flawed comparisons and to optimize pipelines for the wrong objectives.
What is the SCORE evaluation framework and why was it developed?
SCORE (Structural and Content Robust Evaluation) is a framework built specifically for generative document parsing systems. It measures four dimensions independently: content fidelity, hallucination rates, structural understanding, and table extraction accuracy. Unlike single-number benchmarks, SCORE makes trade-offs visible so teams can evaluate parsers against what actually matters for their downstream applications.
How does hallucination in document parsing affect RAG applications?
When a parser introduces spurious tokens or fabricated content, that noise propagates directly into the retrieval index, degrading the quality of retrieved context and ultimately the accuracy of generated responses. Unlike missing content, hallucinated content is difficult to detect because it appears plausible. Measuring precision and recall independently, rather than conflating them into a single score, is the most reliable way to diagnose this risk.
How does Unstructured handle the trade-off between table accuracy and hallucination control across different pipelines?
Unstructured offers multiple pipeline configurations, each using different vision-language models and enrichment strategies, with every configuration benchmarked across all SCORE metrics. This means you can select a pipeline optimized for table extraction in financial documents or one that prioritizes minimal hallucinations for RAG applications, based on published performance data rather than vendor claims. The platform also supports custom prompt tuning and model hosting if your requirements fall outside standard configurations.
How can teams use Unstructured's evaluation methodology on their own documents?
Unstructured open-sourced the SCORE evaluation scripts on GitHub, including labeled examples and annotation conventions. Teams can apply these scripts to their own document collections, whether legal contracts, medical records, or manufacturing specifications, to calculate the same metrics used in the published benchmarks. This allows for direct, apples-to-apples comparison against any document parsing solution on domain-specific content rather than relying on generic academic datasets.


