
Authors

If you’re building AI or agentic systems, you know that document pipelines become the bottleneck long before your models do. While connectors such as S3, Salesforce, Box, and Google Drive handle large-scale production ingestion, you also need a much faster path for debugging, evaluation, and event-driven workflows, one where you can push documents into a pipeline instantly without configuring connectors first.
To support both of these needs, we have evolved the Unstructured API into a single, push-based interface that supports both on-demand jobs and persistent production workflows. The API handles the entire document lifecycle, from ingestion and parsing through enrichment, chunking, embedding, and delivery of high-fidelity JSON to downstream applications. The Unstructured Python SDK fully supports this API, making it easy to integrate file ingestion and preprocessing directly into your application code.
What’s new in the Unstructured API
This launch brings several changes together into a unified experience.
- On-demand jobs: Push local or application-generated files directly into the full Unstructured workflow without configuring connectors first.
- Pre-built templates: Start from opinionated, best-practice workflow templates for common RAG and document transformation use cases instead of designing everything from scratch.
- Visual-to-programmatic parity: Any workflow you design in the Unstructured UI is automatically exposed as a first-class API that you can invoke from your code.
- Unified API: Use the same API for both ad hoc evaluation and persistent production workflows, so you no longer maintain separate codepaths for experimentation and operations.
For existing users: This unified API replaces the need to work directly with separate workflow and partitioning endpoints (which remain fully backward compatible). Your current connectors and pipelines continue running unchanged while you migrate at your own pace.
Debug and iterate instantly with on-demand jobs
One of the biggest sources of friction in document pipelines is configuring ingestion paths before you can even begin evaluating your data or processing strategies. With on-demand jobs, you can skip that step entirely.
You can now push local files directly into the full Unstructured pipeline on demand. With a single authentication flow, you submit a file or a batch of files from your development environment or application, and each request runs the complete pipeline, including partitioning, enrichment, chunking, and embedding, before returning structured, AI-ready JSON.
This is the fastest way for you to A/B test chunking strategies, evaluate extraction quality, build agents or enable business process automation workflows that need to process user uploads instantly without standing up ingestion infrastructure.
Below is a screenshot showing a sample sequence of commands: submitting an on-demand job with a local file, checking job status, and downloading the processed output.
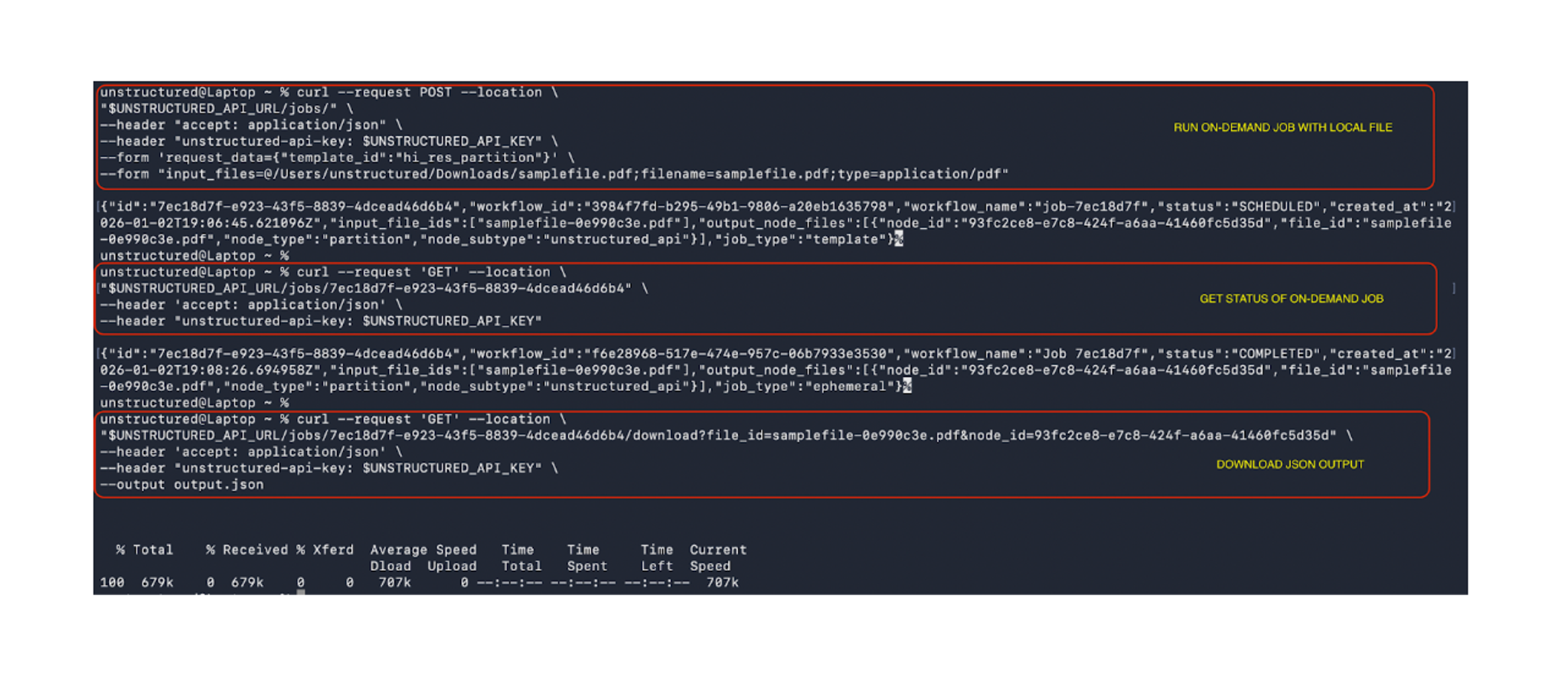
See the full set of curl commands and PythonSDK code for on-demand jobs in the documentation.
Accelerate setup with pre-built templates
You don’t have to design every workflow from scratch. The Unstructured API includes pre-built templates optimized for common RAG, enrichment, and document transformation patterns so you can start processing documents immediately.
These templates run on pre-warmed execution paths, giving you predictable startup times and consistent performance during both evaluation and production. You can use them as-is to get to value quickly, or treat them as a starting point that you refine over time.

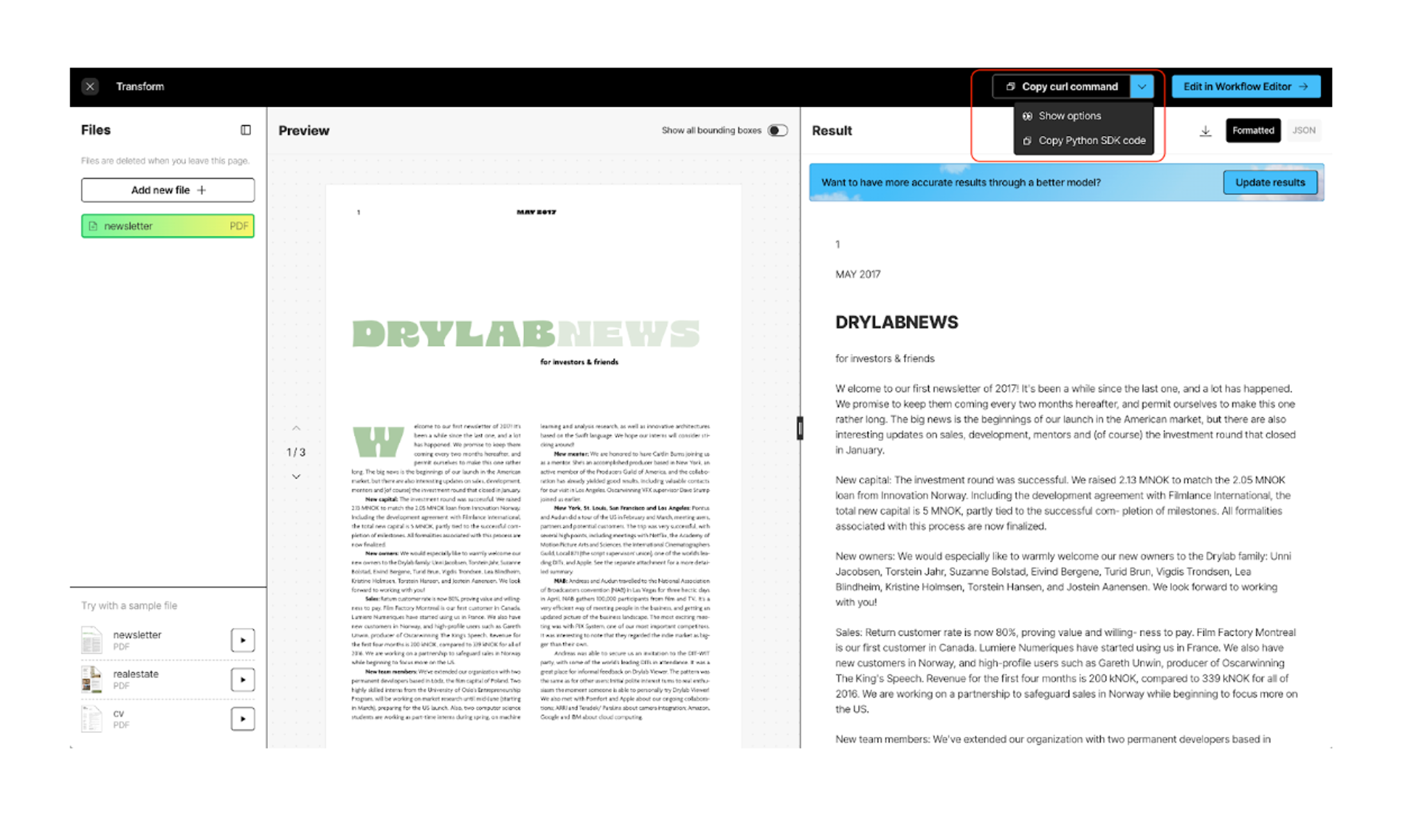
Design visually, execute programmatically
Every workflow you design visually in the Unstructured UI is automatically exposed as a first-class API.
You can refine partitioning, enrichment, chunking, and metadata logic visually, then invoke that exact workflow programmatically in your code. This lets you define document-processing standards once and reuse them across internal tools, agents, and RAG pipelines.
Keep production workflows, gain a unified API
If you’re already running Unstructured in production, nothing changes about how your existing pipelines run. You can continue processing documents from sources like S3, Salesforce, Box, and Google Drive and delivering high-quality structured JSON to your downstream applications using the same connectors and workflows you rely on today. Whether you’re handling a single document or a batch, Unstructured manages orchestration, queuing, and scaling behind the scenes so your workloads stay reliable.
What’s new is that the same unified API you use for on-demand jobs is now also how you create and manage production workflows. While the legacy partition endpoint limited you to processing local files with partitioning only, the new on-demand API allows you to partition, chunk, enrich, and embed. It offers everything the partition endpoint did and more. This gives you a single surface for both experimentation and operations, so you no longer need separate codepaths or deployment patterns as you move from a quick file test to a fully automated pipeline.
Below is a screenshot showing example curl commands that create a workflow with remote source and destination connectors and then run that workflow.
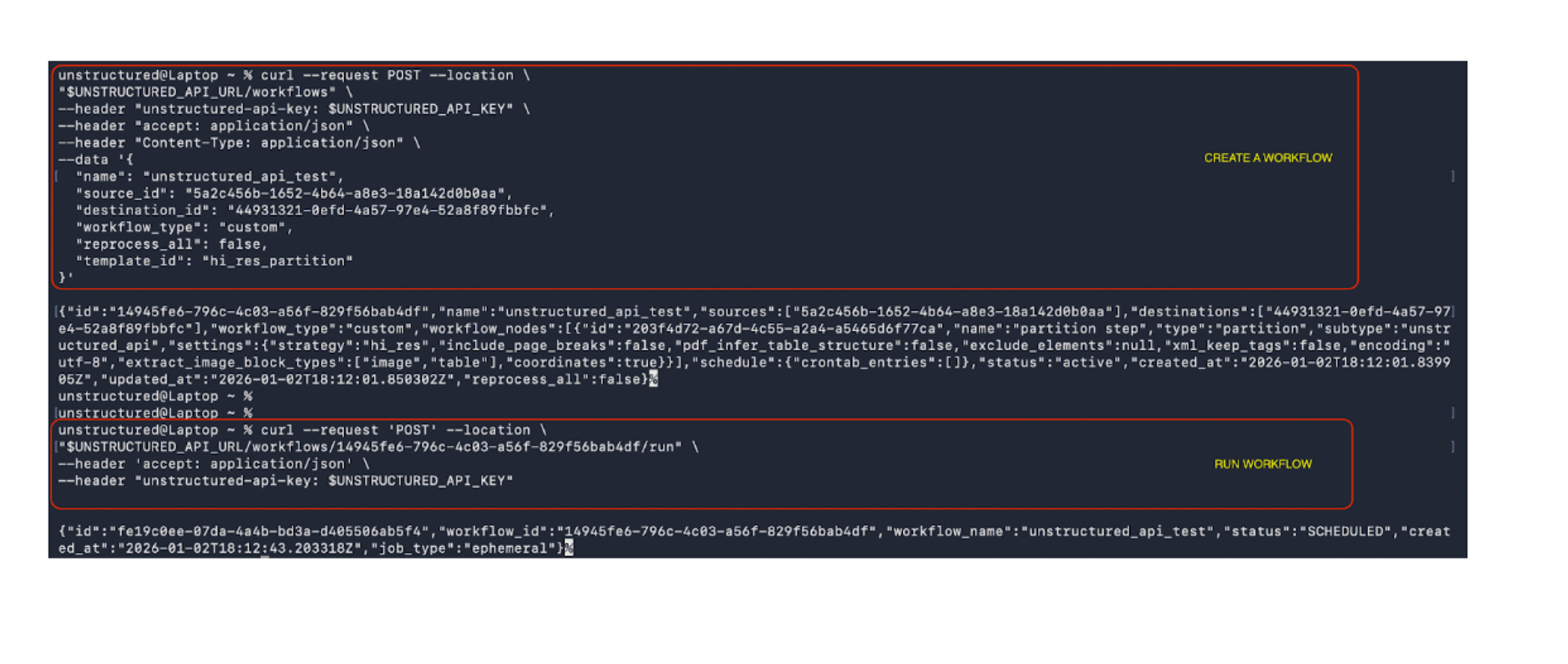
You can find the complete set of curl examples and Python SDK snippets for workflows in the documentation.
From event-driven to large-scale ingestion
With the Unstructured API and Python SDK, you spend less time managing ingestion infrastructure and more time improving downstream performance. Event-driven applications can push documents the moment they’re created, uploaded, or updated, while large-scale workflows continue to handle orchestration, queuing, and scaling for massive batches.
This unlocks:
- A simpler path from file to JSON: Go from a local document or user upload to structured output with minimal setup.
- Faster evaluation and iteration: Rapidly test and refine processing strategies without reconfiguring infrastructure every time.
- Cleaner paths to production: Move from experimentation to scale on the same API, without major refactors.
- Reliable AI inputs: High-fidelity data ready for search, retrieval, autonomous agents, and human-in-the-loop workflows.
Sign up today to get your API key and start converting messy documents into structured JSON for your GenAI and agentic workloads through a single, unified Unstructured API.


