Simpler, Faster, and More Powerful Way to Transform Documents in Unstructured
Nov 10, 2025
Authors

Unstructured has always had one focus: clean, high-quality data for downstream AI systems.
We connect to an unparalleled array of enterprise data sources and destinations, and our robust transformation strategies extract critical content and metadata from over 70 types of unstructured data. With flexible DAG-based workflows, smart chunking, seamless embedding integrations, and enterprise-grade security, we handle the full lifecycle of unstructured data preprocessing, freeing you to focus on building groundbreaking GenAI systems.
We’re excited to announce a series of updates to Unstructured that take enterprise-grade document transformation to the next level - making it simpler, faster, and more intuitive than ever to turn complex data into formats ready for AI consumption.
Let’s explore what’s new!
From Login to Your First Processed Document in 3 Clicks
We’ve completely reimagined the initial user experience to help you immediately see the power of Unstructured.
Upon login, you can drag and drop files right away, straight from the Start page. Once uploaded, Unstructured automatically processes your documents using our best-in-class workflow. After processing, you get high-fidelity outputs, side-by-side previews, bounding boxes, and full JSON downloads.
Here's how this new experience makes your life easier:
- Immediate access to high fidelity document processing: Documents you upload are processed with an automatic workflow that runs our high fidelity transformation workflow.
- Simplified focus: The interface focuses solely on file transformation, making it easy to see results fast without overwhelming customization options.
- Enhanced visual preview: Side-by-side rendering shows the original document on the left and the transformed output on the right, letting you verify accuracy at a glance.
- Bounding box visualization: See exactly how Unstructured identifies and segments elements within your document with the addition of bounding boxes.
- Interactive navigation: Click on any element in your document or its transformed output, and we'll highlight the corresponding section on the other side. This makes it simple to compare exactly how elements map from source to structure.
- Full JSON access: Download or review the complete JSON output whenever you need it.
- Seamless workflow transition: Once you're satisfied with how Unstructured handles your documents, hit a single button to move into the Workflow Builder with your exact workflow pre-configured. Then add your data sources, destination connectors, chunking strategy, embedding models, and deploy at scale.
This Start-page experience supports files up to 10MB, making it perfect for quick evaluations. You can now effortlessly test Unstructured on your documents, visually check the outputs, and then seamlessly transition to building scalable production workflows.
Generative Refinement
With the Start-page drag-and-drop workflow, we're introducing the new high fidelity document transformation workflow powered by our new Generative Refinement enrichments. This new approach significantly outperforms traditional methods as well as other VLM-based document parsers, by combining state-of-the-art document partitioning with targeted Vision Language Model (VLM) post-processing.
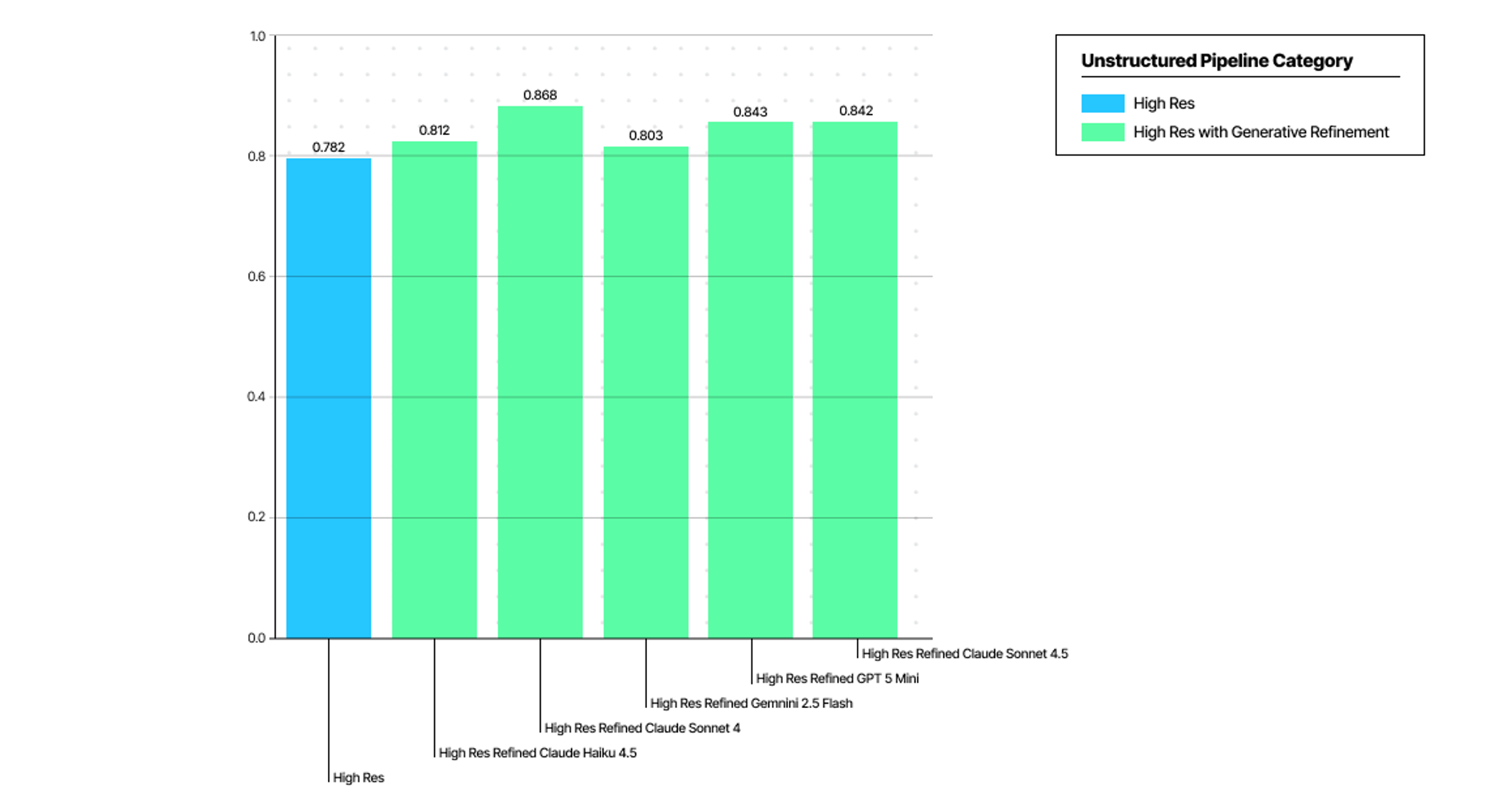
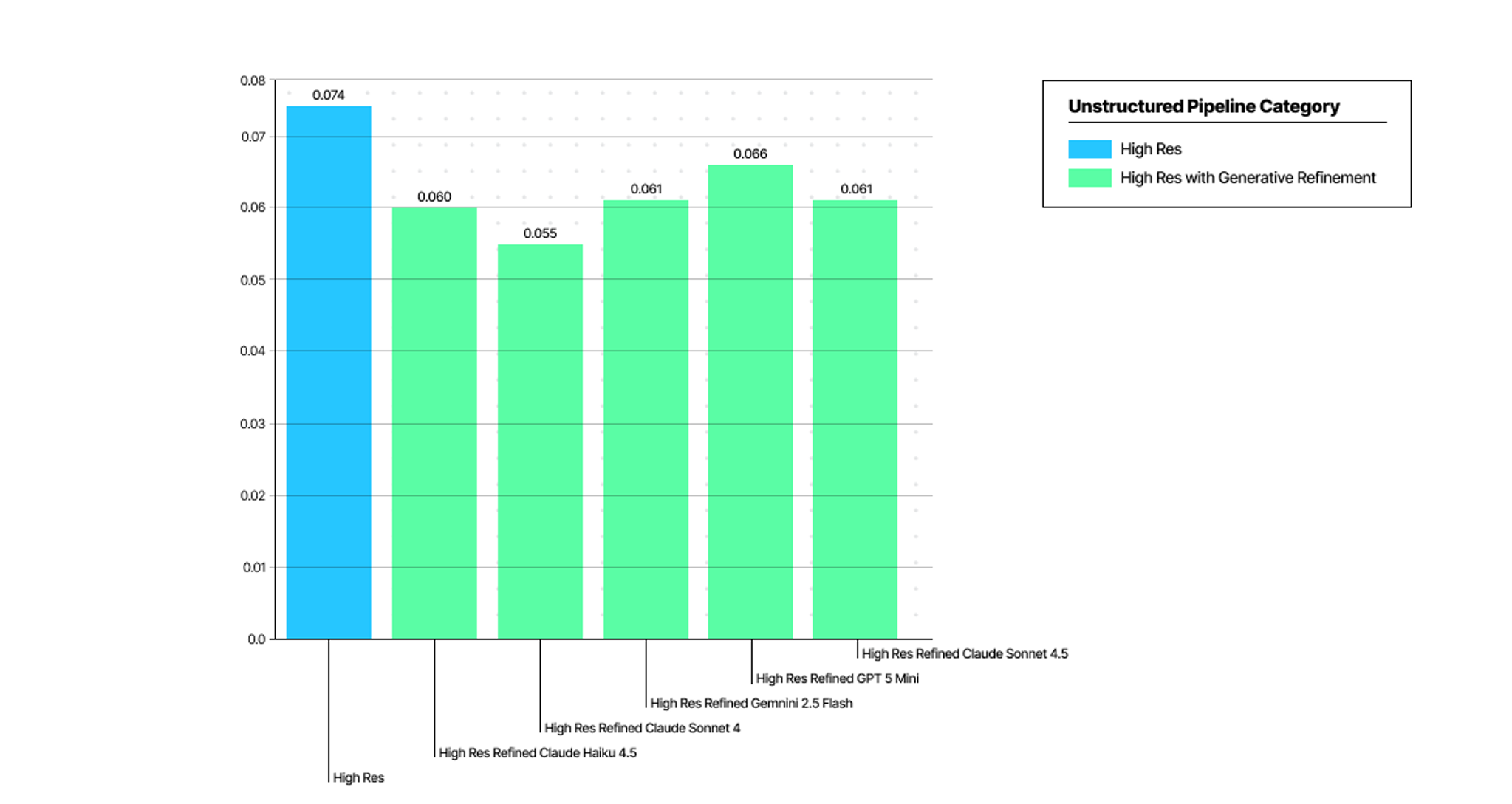
Here’s how the new workflow compares to pure High Res partitioner available in Unstructured.
Higher Content Fidelity

Better Table Content and Structure Preservation
Lower Hallucinations
Achieving this level of fidelity was made possible, in part, by addressing the limitations of traditional OCR-era evaluation approaches that do not account for diversity in content representation and hallucinations introduced by generative document parsing (learn more in our recent paper). We are confident in this approach delivering the best results on the market and we will be sharing further benchmarks shortly.
Why it matters
High resolution document partitioning followed by generative refinements is the key to achieving accurate, structurally sound, and low hallucination output for your downstream RAG/Agentic system.
- High Accuracy: By cleaning up mistakes that slip through traditional OCR, the final output is significantly cleaner and more reliable. This is achieved by extracting the semantic content with a VLM from individual text elements instead of relying only on OCR output or sending an entire page to a VLM.
- Structural Integrity: Images, tables, and text are all processed with specialized, VLM-powered tools, ensuring crucial structural information is perfectly preserved. This is vital for complex financial reports, legal documents, and forms.
- Minimal Hallucinations: The refined process drastically reduces the chance of the VLM generating incorrect or fabricated content, giving you greater confidence in your data.
- Faster Path to Production: You spend less time correcting and more time building GenAI systems that work flawlessly with your real-world documents.
Generative Refinement turns your document transformation from “good enough” into truly enterprise-grade, giving you confidence that your data is accurate, complete, and AI-ready.
How it Works Under the Hood
The high-fidelity transformation workflow is a specific, powerful combination of a high resolution partitioner and three Generative Refinement enrichments. This entire workflow is what runs automatically when you drop a document into the new Transform tab.
- High Res Partitioner: The process begins by using the High Res Partitioner. This leverages advanced object detection to first meticulously identify and isolate every individual element such as text blocks, tables, and images, and capture precise bounding box locations for each.
- Generative Refinement enrichments: Once partitioned, a series of specialized VLM-powered enrichments are applied to refine the content of each element type:
- Generative OCR [NEW!]: All text elements are sent to a VLM to extract the highest-fidelity version of the content. This precise targeted optimization significantly improves accuracy of textual outputs compared to standard OCR alone or using VLMs on entire pages.
- Table to HTML: Table elements are passed to a VLM to be returned as HTML. This is critical for preserving the table's structural relationships, which is essential for accurate understanding by a downstream AI.
- Image Description: Image elements are sent to a VLM to generate searchable, high-quality descriptions that can then be embedded alongside the text.
The approach intelligently combines the results from the initial High Res partitioner with the refined, high-fidelity content from all three enrichments. When you drag and drop your documents on the Start page, you first see the result of the High Res partitioning, and then the final, fully refined output is displayed after the refinement is complete.
Crucially, once you are satisfied with the result and move to the Workflow Builder, it will offer this exact, high-fidelity workflow pre-configured and ready for you to connect a source and destination to run at scale.
Simplified Pricing: Get Started for Free with No Time Limit
We've simplified our pricing to make it easier than ever to get started with Unstructured. Our new pricing structure includes three tiers designed to meet you wherever you are in your document transformation journey:
Let’s Go! Free. No time limits
Start processing documents immediately without any setup, infrastructure management, or charges. Process up to 15,000 pages for free, no strings attached and all features included. There's also no time limit! Go at your own pace and take the time you need to fully evaluate Unstructured's capabilities on your use cases.
Pay-as-you-go: $0.03/page. Flat Rate
Need to process a higher volume of documents? Enjoy unlimited pages at $0.03/page with no recurring fees.
Your $0.03/page includes the entire end-to-end data transformation pipeline: enterprise-grade source connectors to capture data from your systems, powerful transformation strategies with advanced partitioning and VLM-powered enrichments, smart chunking, seamless embedding integrations, and destination connectors to load results into your vector database or storage of choice. All features included. Only pay for what you use.
Business: Fully Custom to Your Needs
For organizations looking for complete data ownership, full customization, and dedicated technical support. This tier includes fully isolated, customer-hosted deployments, custom volume pricing, custom SLAs, and all features included.
Ready to Transform Your Unstructured Data?
The best way to understand what Unstructured can do is to experience it firsthand. Sign up today, and test how we handle your documents. Explore cached examples, upload your own files, and see the quality for yourself.
For a more comprehensive walkthrough or to discuss how Unstructured can solve your specific document processing challenges, reach out to our team for a personalized demo.


