Authors

These models perform document understanding training end-to-end with neural networks. Most of the systems take an image representation of a document and generate a text representation out of it. More recent ideas such as the UDOP (Universal Document Processing) system by Microsoft include mixed combinations of text and images are proposed
These systems are pre-trained using a large number of examples of images and their text representation, teaching the system to read documents and write text in an unsupervised fashion, and then fine tuned to perform a specific task using supervised training methods with manually annotated data.
Recent developments in pre-trained large language models, such as the GPT family, have demonstrated a surprisingly strong ability to perform novel tasks in response to a prompt. At Unstructured, we’re interested in how much of this we could use for document understanding.
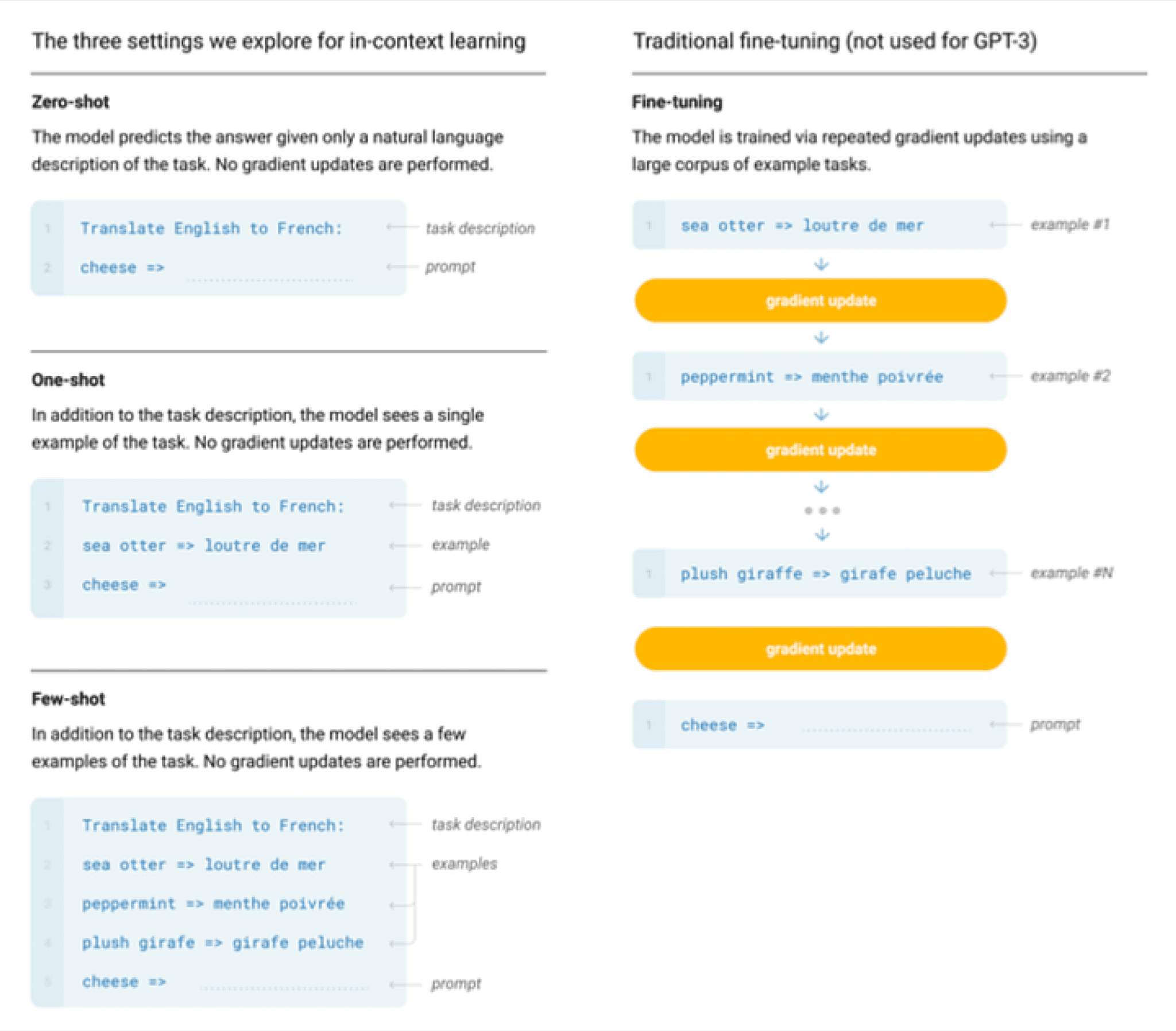
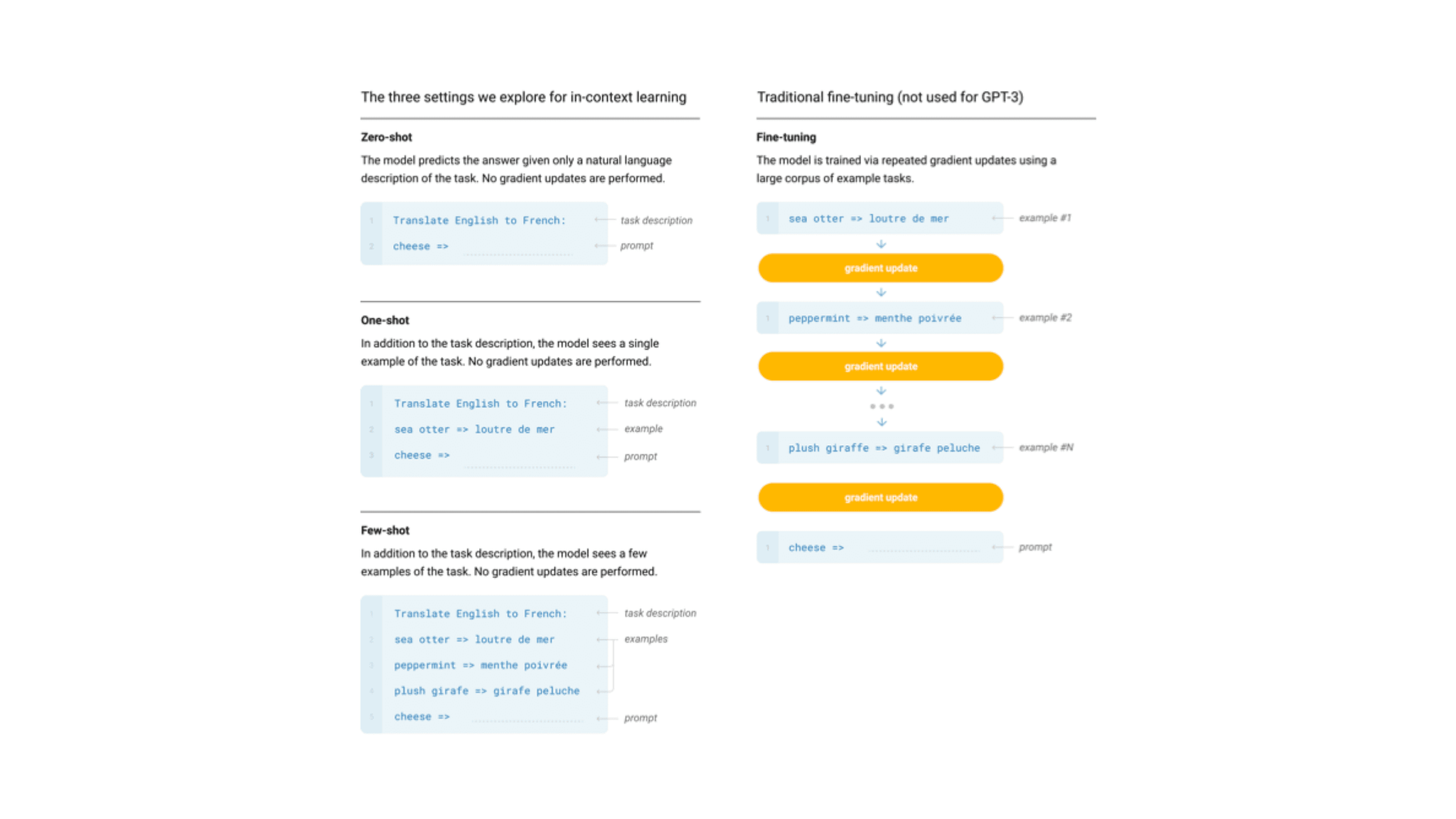
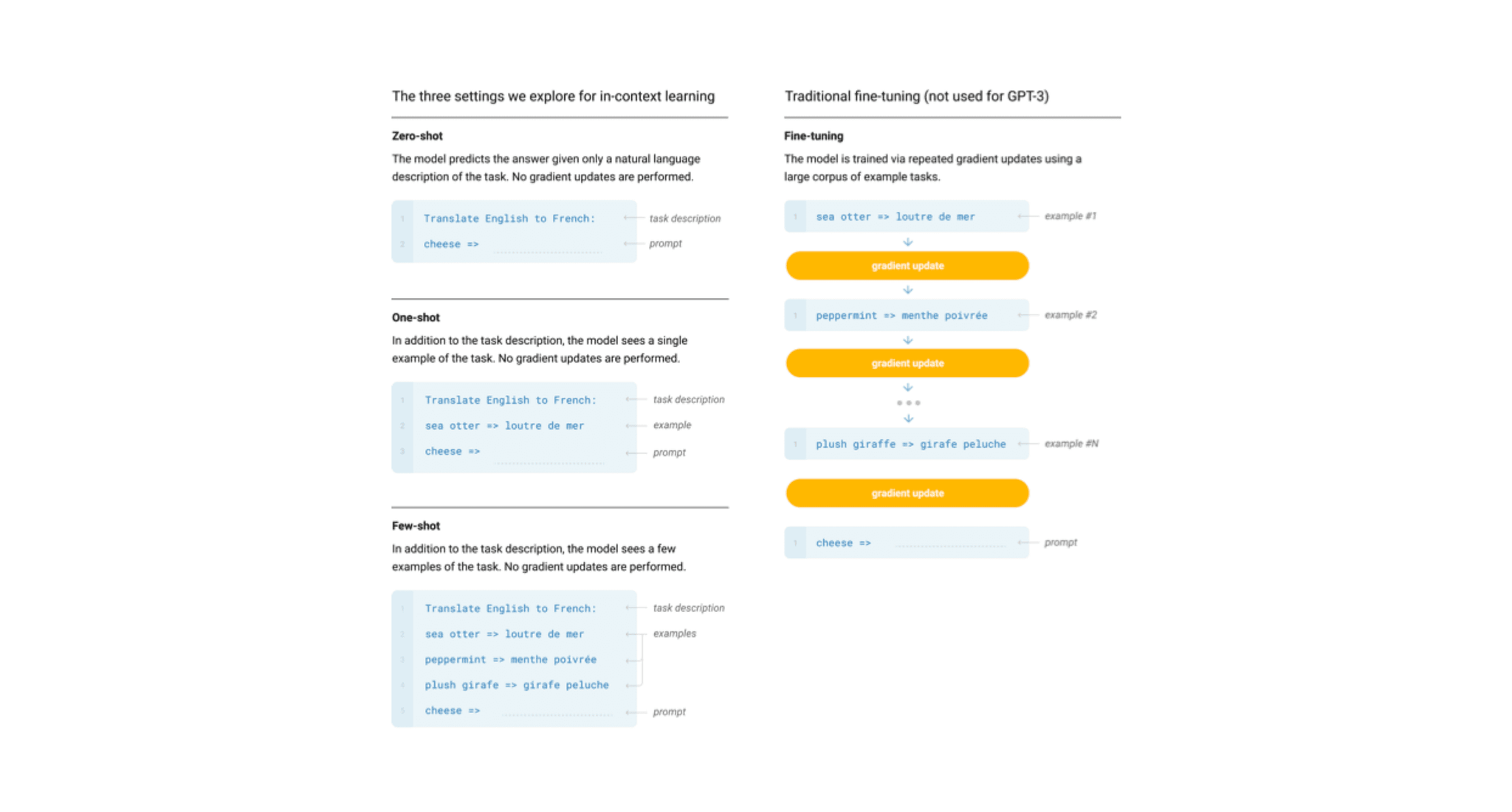
GPT-3 prompt training [Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877–1901.]
Document understanding has different requirements compared to typical language modeling tasks since it combines images and text, thus the relationship between the document image and the text needs additional considerations. Further, the expectations about the possible tasks that document understanding need to deal with are different. Documents need to be understood in combination with the expected task. With DocVQA, for example, the user presents questions about document images, as seen in the example below.

Example of image and questions from the DocVQA data set [Mathew, Minesh, Dimosthenis Karatzas, and C. V. Jawahar. “Docvqa: A dataset for VQA on document images.” Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021]
There is also recent work by UDOP, as shown in the table below, in which examples of self-supervised and supervised tasks in which prompt is being used are presented.
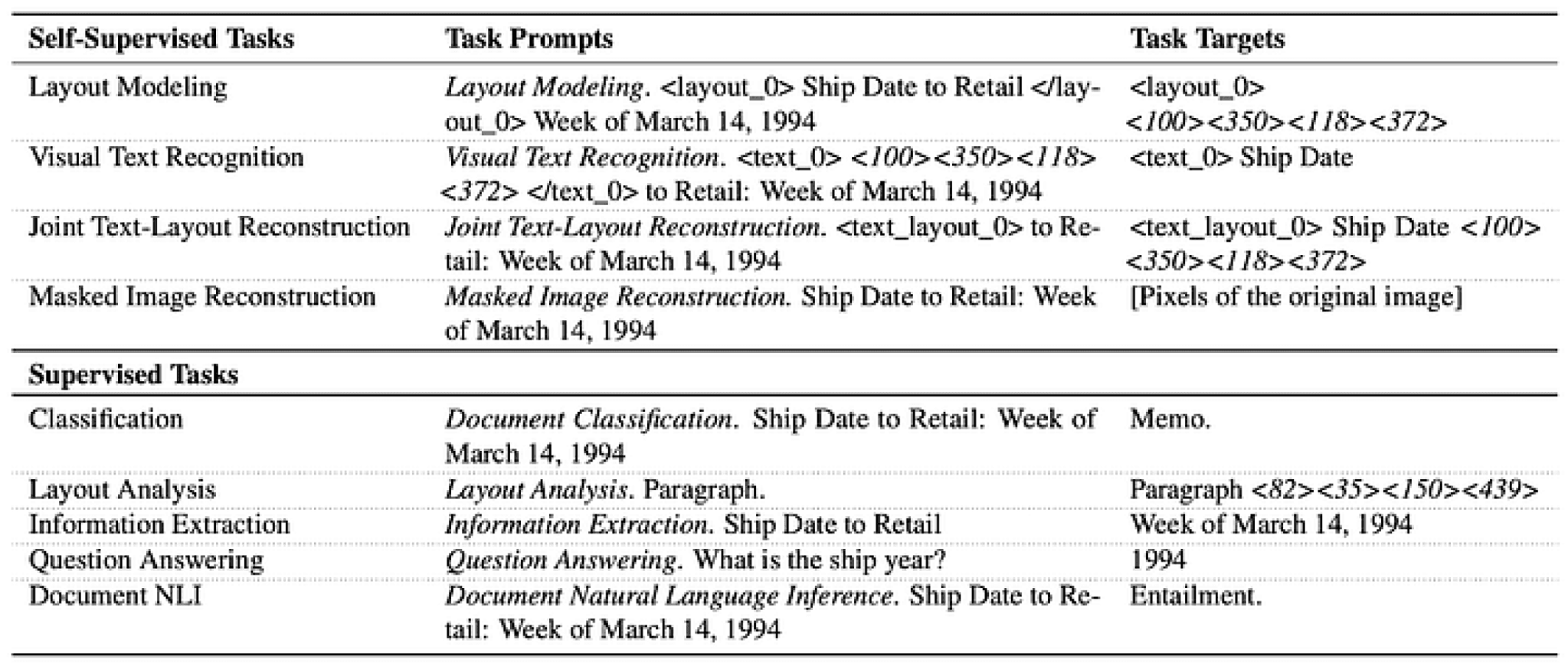
UDOP task prompts [Tang, Zineng, et al. “Unifying Vision, Text, and Layout for Universal Document Processing.” arXiv preprint arXiv:2212.02623 (2022)]
More recently, researchers have proposed methods that would allow systems such as ChatGPT to respond to corrections. The model relies on user feedback and a reinforcement learning model to correct the outputs of the decoder model.
ChatGPT can interact with a user providing insights from a large number of topics in different styles as in the example below:

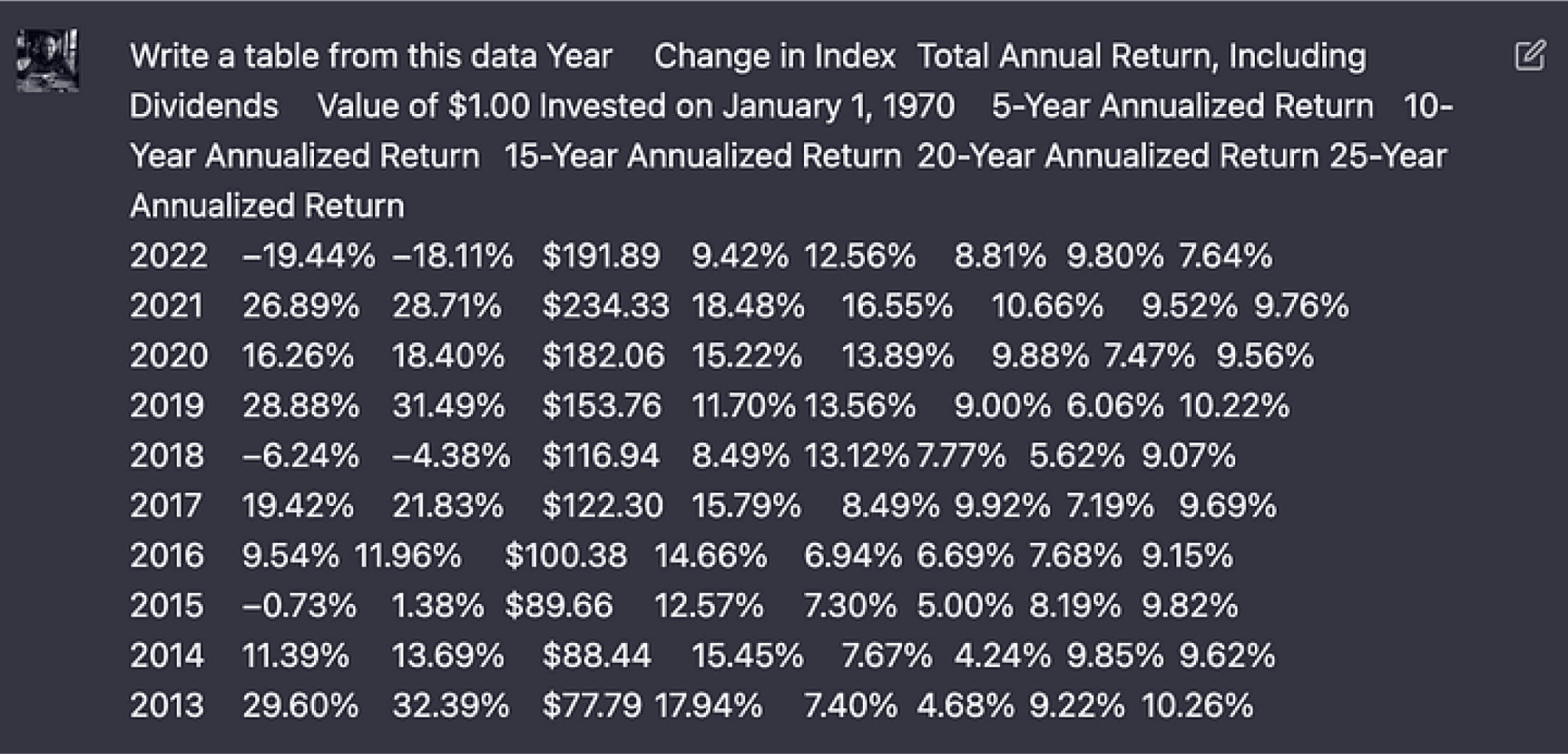
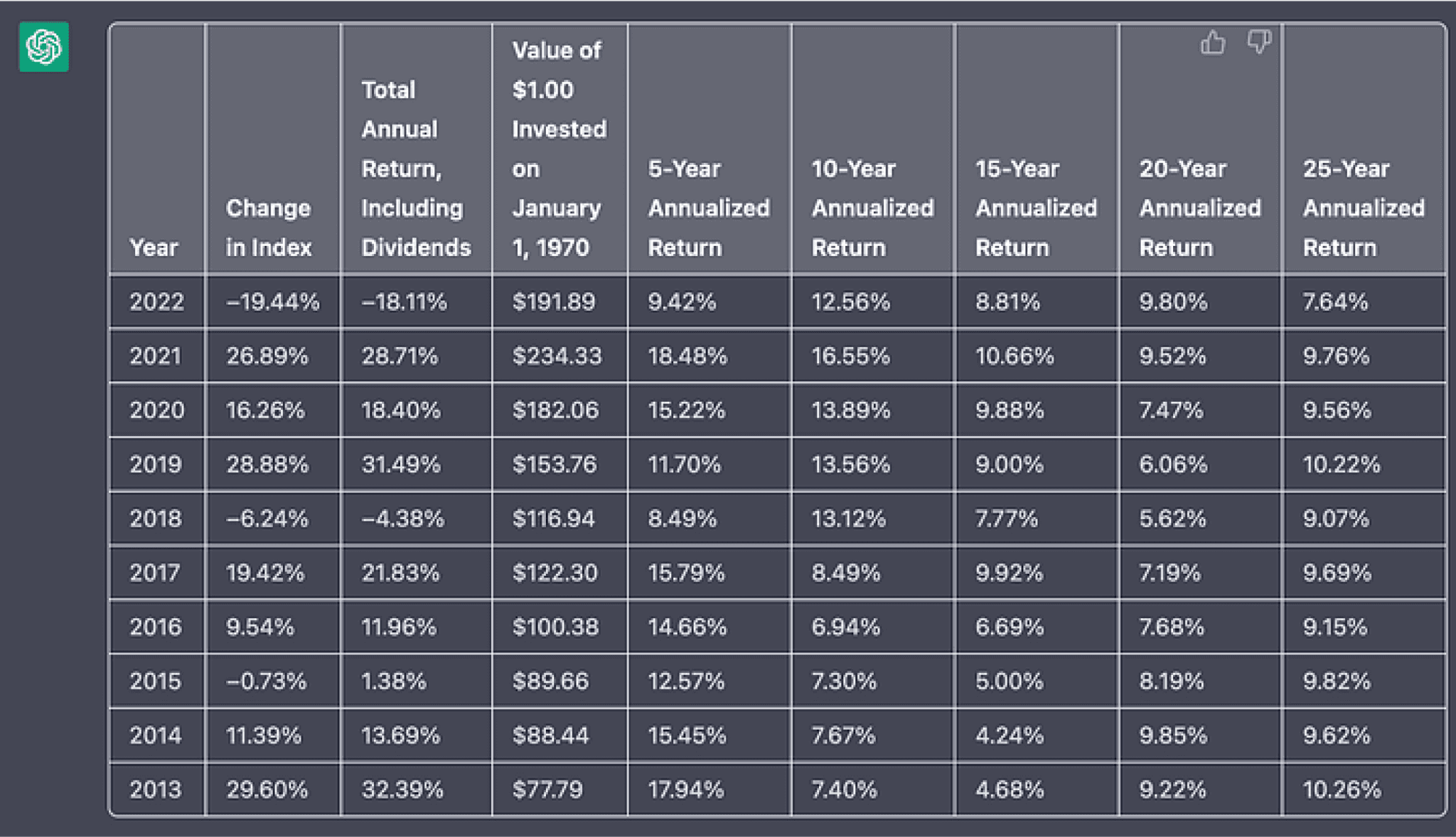
Based on its vast corpus of pre-training data, ChatGPT has demonstrated an ability to perform document understanding tasks. In the example below, the SP&500 performance in the last 10 years copied from wikipedia (left) was transformed into a table by ChatGPT (right). After pasting the data, it had lost the table formatting that ChatGPT could recover perfectly.
The Unstructured team is experimenting with these approaches to provide a more flexible interface for processing unstructured documents. If you’d like to keep up with our latest research, follow us on LinkedIn and Huggingface and give our GitHub library a star!


