
Authors

Introduction
If you are looking to build a production-ready Retrieval Augmented Generation (RAG) system with GraphRAG, and leverage Unstructured preprocessing and chunking capabilities, you are in the right place! This blog post is about the recent integration of Unstructured into R2R (RAG to Riches), an open-source RAG engine that lets you build, scale, and manage user-facing RAG applications in production. It incorporates cutting-edge RAG solutions like Graph RAG, hybrid search, with features necessary for production builds, like user authentication and group permissions.
With Unstructured's powerful processing, R2R can handle the 64+ file types that Unstructured supports. Unstructured also adds the ability to read complex documents, whether the complexity stems from unique reading order, or images embedded in a .pdf. This unlocks the ability to answer intricate questions that require interpreting tables and charts.
In this recent integration, R2R incorporates the Unstructured open source library by default for local build-outs, or can be configured to use the Serverless API, which provides automatic scaling and has access to more performant ML models for enhanced processing. Combining R2R with Unstructured also leverages the orchestration capabilities of R2R for RAG: orchestration via Hatchet, including knowledge graph construction.
Getting Started with R2R and Unstructured
Try this out for yourself to see how R2R + Unstructured works with your data!
Installing R2R is simple:
pip install "r2r"Then, you can start your R2R deployment:
r2r serve --dockerIf you’d like to use the Unstructured API with R2R, we can create a custom config file. You can get your Serverless API key here, and for first time users, we offer a 2-week free trial. Read here to learn more about the different offerings from Unstructured, to see which is most suitable for your use case. The OSS, which is used by R2R by default, is recommended for prototyping, whereas the Serverless API is recommended for production, and includes VPC offerings on AWS and Azure.
[parsing]
provider = "unstructured_api"
[chunking]
provider = "unstructured_api"Then, we start our R2R deployment with our custom config and our Unstructured API key:
export UNSTRUCTURED_API_KEY=your_unstructured_api_key
r2r serve --docker --config-path=/path/to/configWe'll take a complex file, such as a this supplemental data report from Uber, which contains graphics, charts, and tables.
We then ingest this file into our R2R deployment:
curl https://s23.q4cdn.com/407969754/files/doc_earnings/2023/q4/supplemental-info/Uber-Q4-23-Earnings-Supplemental-Data.pdf >> uber.pdf
r2r ingest-files uber.pdfLeveraging Unstructured within R2R
Check out these examples below, to see what kind of question-answering capabilities best-in-class parsing via Unstructured unlocks in R2R! You can ask your R2R RAG system questions about images of complex tables, scanned pdfs, or whatever messy, noisy, unstructured documents you work with!
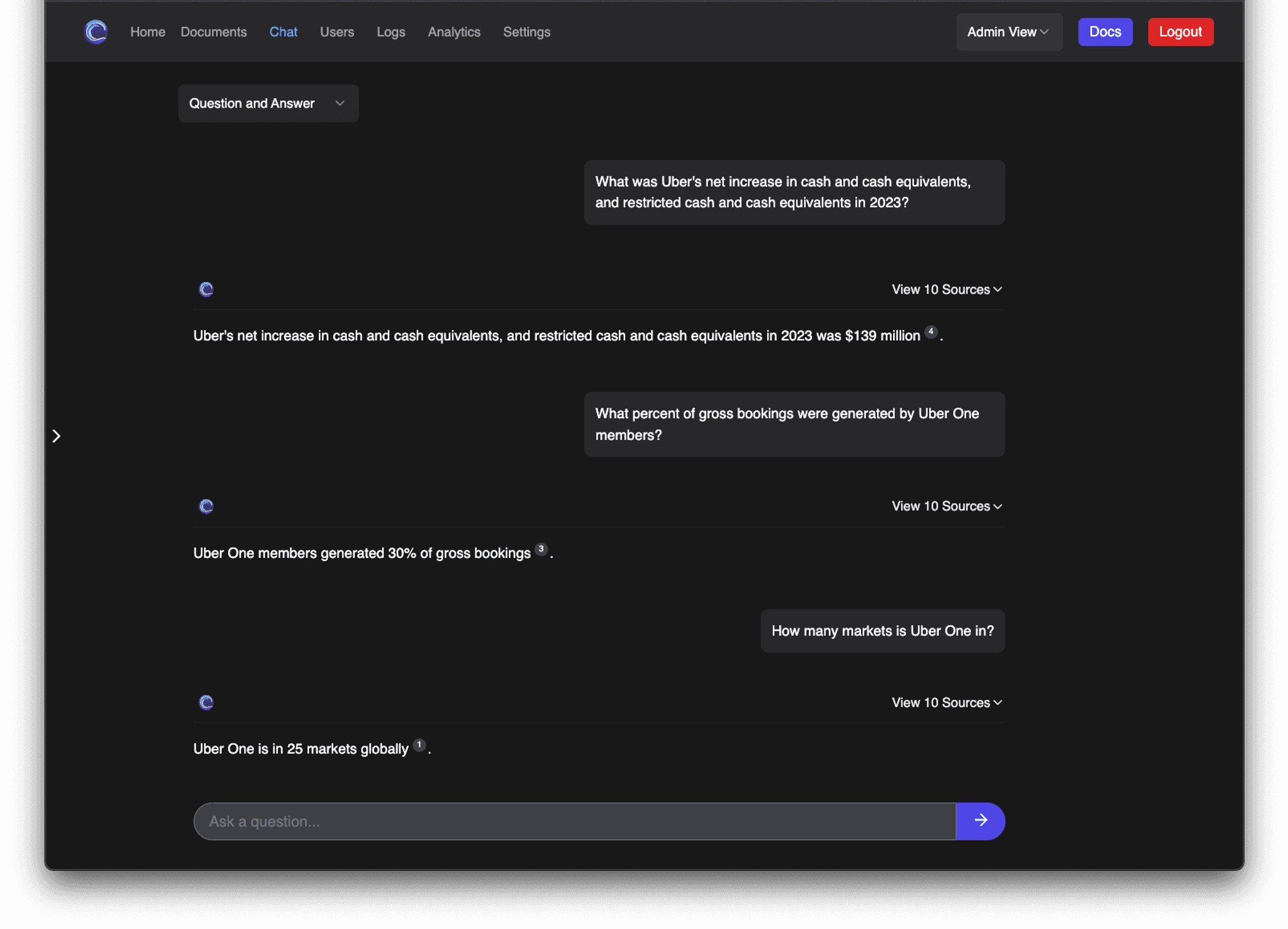
Figure 1: Answering complicated questions with Unstructured.
The resulting answers are not only correct but also reference specific data chunks parsed by Unstructured:
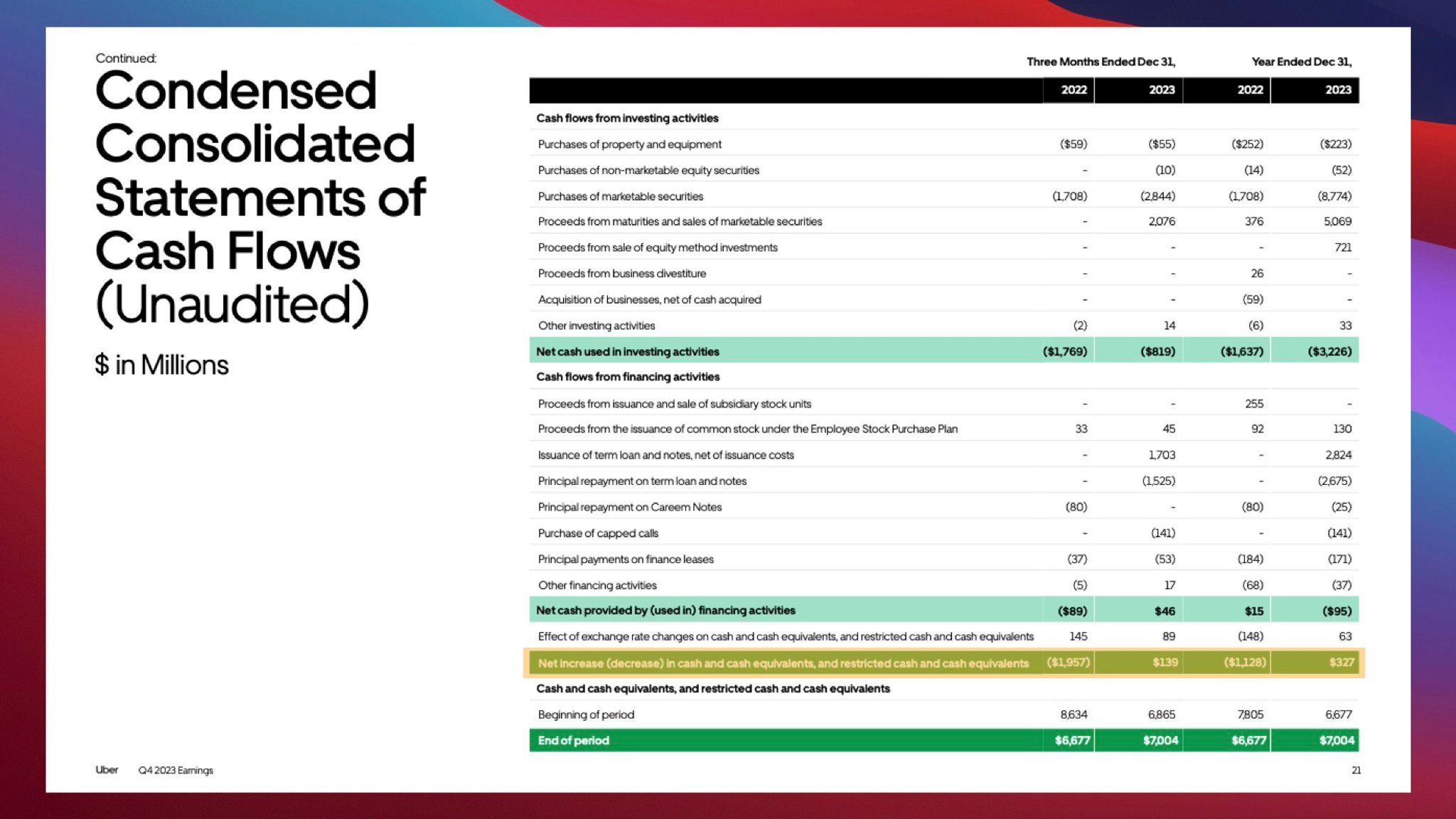
Figure 2: Complicated financial tables which Unstructured was able to extract.

Figure 3: Details around the Uber platform which Unstructured was able to extract.
GraphRAG: Enhancing RAG with Knowledge Graphs
R2R incorporates GraphRAG, an advanced technique that combines traditional RAG with knowledge graphs. GraphRAG enhances the retrieval process by leveraging the relationships between entities in your data.
To build a knowledge graph from your ingested data:
r2r create-graphThe create-graph job gets triggered for each document. You can view the job status in the hatchet dashboard. Once that is complete, run
r2r enrich-graphThe resulting graph looks like this:
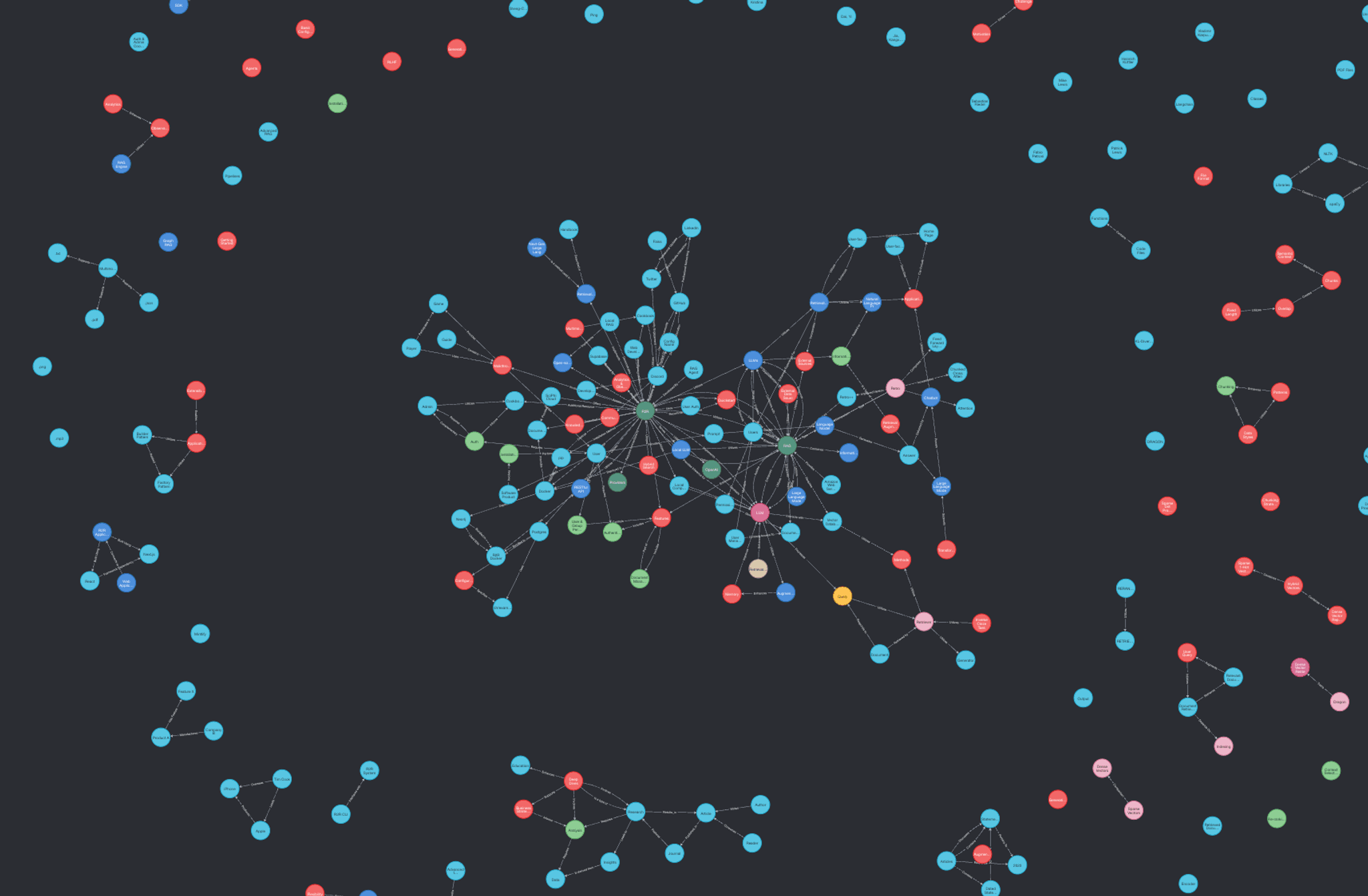
Figure 4: A knowledge graph built off of data processed by Unstructured
GraphRAG allows R2R to answer questions that are otherwise challenging for traditional vector search, for example:
```
# Overview of R2R
R2R, or RAG to Riches, is a multifaceted platform that enhances the capabilities of artificial
intelligence (AI) systems. It integrates various technologies and methodologies to optimize
data retrieval, improve response accuracy, and facilitate user interactions across different
applications.
…By combining vector search with graph-based retrieval, GraphRAG can provide more contextually relevant and accurate responses, especially for complex queries that require understanding relationships within the data.
Integration
To see how R2R integrated Unstructured into their codebase, check out their Unstructured chunking and parsing providers.
Conclusion
In the rapidly evolving landscape of AI-powered applications, having a reliable and accurate document processing solution is crucial. By combining Unstructured's best in class parsing capabilities with R2R's robust RAG framework, you're equipped to build production-ready applications that can handle real-world data challenges.
Whether you're dealing with financial reports, technical documents, or any other complex data sources, the Unstructured and R2R integration ensures your RAG system is built on a solid foundation of precisely extracted and well-structured information. This powerful combination, enhanced by advanced features like GraphRAG, positions your applications at the forefront of AI-driven information retrieval and generation.


