
Authors


We're excited to announce our new integration with PostgreSQL in the Unstructured Platform, expanding Unstructured Platform's capabilities to help data teams build more robust and efficient data preprocessing pipelines.
Why PostgreSQL?
You are probably already familiar with PostgreSQL and possibly already using PostgreSQL in your organization. The pgvector extension adds similarity search capabilities to PostgreSQL, enabling you to store vector embeddings directly alongside traditional relational data, unlocking new possibilities for solutions that use chatbots and virtual assistants, RAG, recommendations, and more. Using PostgreSQL can help your organization save time and money by using the knowledge and resources that you likely already have.
You can use the PostgreSQL destination connector in the Unstructured Platform to enable Unstructured to upload the documents and data that it processes from your various upstream cloud apps, file storage, databases, and vector stores; process that incoming information; generate any vector embeddings for the processed information as needed; and then add it all into your PostgreSQL databases. This approach enables you to get all of your organization’s unstructured information into one place in a consistent, structured format that can unlock more powerful use cases for your organization.
If you have legacy data in PostgreSQL but need to get it into a different destination instead, you can use the PostgreSQL source connector in the Unstructured Platform to send that data from your PostgreSQL databases to Unstructured for processing. Unstructured can then send the processed data to a variety of downstream destinations such as cloud storage, databases, and vector stores, in a consistent, structured format tailored to each particular destination.
PostgreSQL Integration in the Unstructured Platform
The PostgreSQL source and destination connectors in the Unstructured Platform are used to upload or download batches of data into or from your PostgreSQL databases. Here's how it works:
1: The Unstructured Platform ingests information from its original sources, preserving critical metadata along the way.
2: A workflow in the Platform processes your raw information into structured JSON, optionally enriches the content (for example, by generating summaries for tables where they exist), creates chunks, and generates vector embeddings (configurable with your preferred embedding model) for the processed content.
3: The connector efficiently manages batch uploads or downloads into or from your PostgreSQL databases. You can easily customize the batch size to fit your requirements.
Our PostgreSQL integration adheres to enterprise-grade security standards including:
- End-to-end encryption for data in transit.
- Authentication via API keys.
- Zero data persistence policy, and more.
You can learn more about the enterprise-grade features of the Unstructured Platform connectors in this blog post.
Configuring the connector
Before you configure the PostgreSQL source or destination connector, you will need:
Step 1: A cloud-based PostgreSQL database, such as an Amazon RDS for PostgreSQL instance or Azure Database for PostgreSQL server.
For Amazon RDS for PostgreSQL, Amazon recommends that you set the instance's Public access setting to No by default, as this approach is more secure. This means that no resources can connect to the instance outside of the instance's associated Virtual Private Cloud (VPC) without extra configuration. Learn more. Access an Amazon RDS instance in a VPC. If you must enable public access, set the instance's Public access setting to Yes, and then adjust the instance's related security group to allow this access. Learn how.
Step 2: Optionally, enable pgvector on the database.
a) For Amazon RDS for PostgreSQL or Azure Database for PostgreSQL, connect to the database and then run the PSQL command CREATE EXTENSION vector;
b) For other providers, see your provider’s documentation.
Step 3: The database’s host name and port number.
a) Get the host name and port number for Amazon RDS for PostgreSQL.
b) Get the host name for Azure Database for PostgreSQL. The port number is 5432.
c) For other providers, see your provider’s documentation.
Step 4: Allow Unstructured’s IP address ranges on the database. To get these address ranges, go to https://assets.p6m.u10d.net/publicitems/ip-prefixes.json and allow all of the ip_prefix fields’ values that are listed.
a) Allow these address ranges for Amazon RDS for PostgreSQL.
b) Allow these address ranges for Azure Database for PostgreSQL.
c) For other providers, see your provider’s documentation.
Step 5: A database in the instance. For Amazon RDS for PostgreSQL and Azure Database for PostgreSQL, the default database name is postgres unless a custom database name was specified during the instance creation process. For other providers, see your provider’s documentation.
Step 6: A table in the database. For the destination connector, the table’s schema must match the schema of the documents that Unstructured produces. Unstructured cannot provide a schema that is guaranteed to work in all circumstances. This is because these schemas will vary based on your source files’ types; how you want Unstructured to partition, chunk, and generate embeddings; any custom post-processing code that you run; and other factors.You can adapt the following pgvector-style table schema example for your own needs:
CREATE EXTENSION vector;
CREATE TABLE elements (
id UUID PRIMARY KEY,
record_id VARCHAR,
element_id VARCHAR,
text TEXT,
embeddings vector(3072),
parent_id VARCHAR,
page_number INTEGER,
is_continuation BOOLEAN,
orig_elements TEXT
);Step 7: The name and password of the user with sufficient access to the database.
a) Get the username and password for Amazon RDS for PostgreSQL. Manage user access.
b) Get the username and password for Azure Database for PostgreSQL. Manage user access.
c) For other providers, see your provider’s documentation.
To configure the source or destination connector by using the Unstructured Platform user interface:
Step 1: Log in to the Unstructured Platform.
Step 2: On the sidebar, click Connectors.
Step 3: Click New or Create Connector.
Step 4: Type some unique Name for the connector.
Step 5: For Type, make sure Source or Destination is selected.
Step 6: Click PostgreSQL, and then click Continue.
Step 7: Fill in your PostgreSQL database’s host name, database name, and port number, and then click Next.
Step 8: On the next screen, fill in your database username and password, and then click Next.
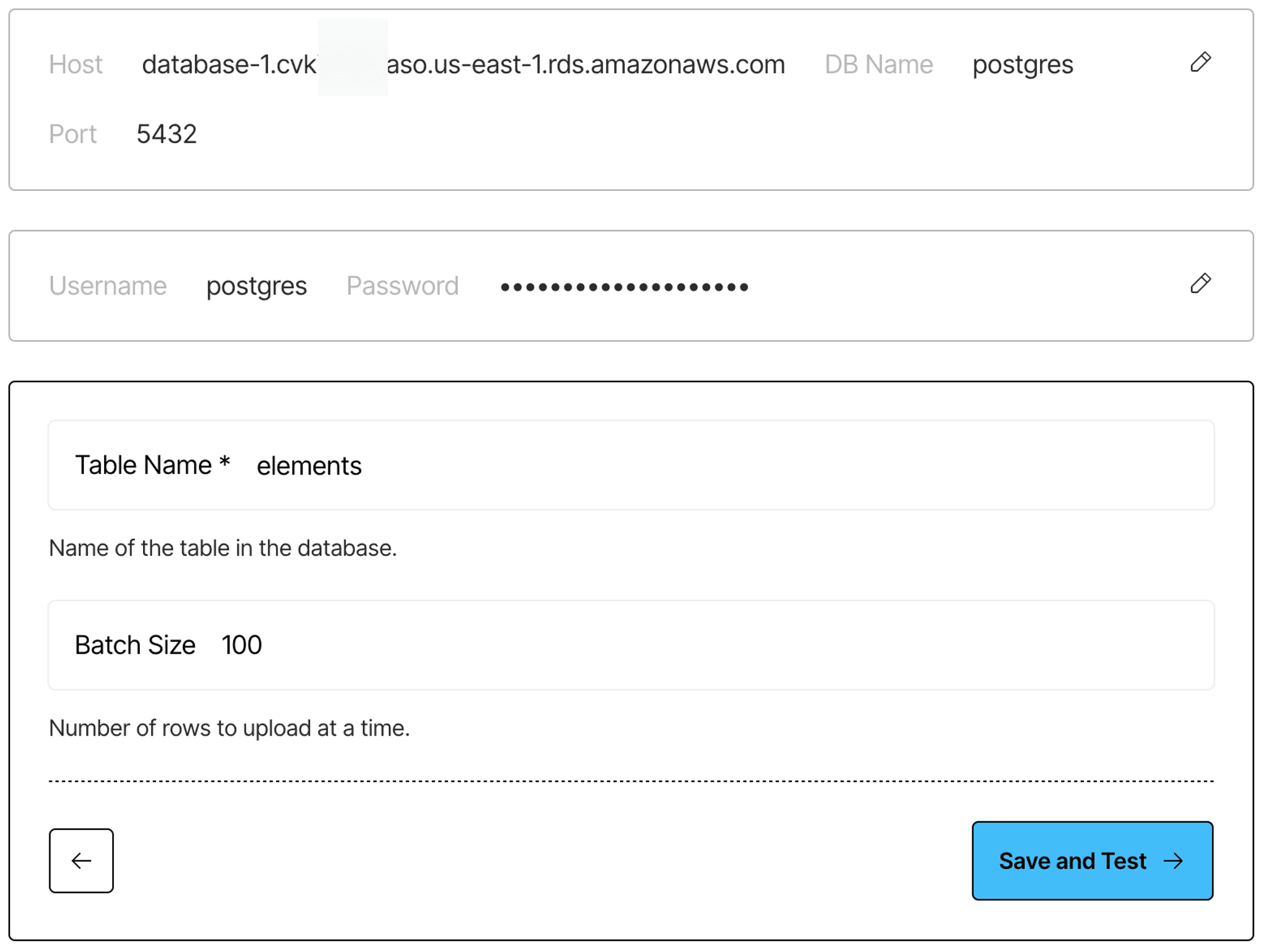
Step 9: On the next screen, fill in your table name. Also, for the destination connector, do the following:
a) Fill in the name of the ID column in the table.
b) Optionally, fill in a comma separated-list of column names to process, including the specified ID column. The default is all columns if not otherwise specified).
Step 10: Click Next.
Step 11: Compare your results to the following screenshots, and then click Save and Test.
Host name, database name, and port number:

Database username and password:
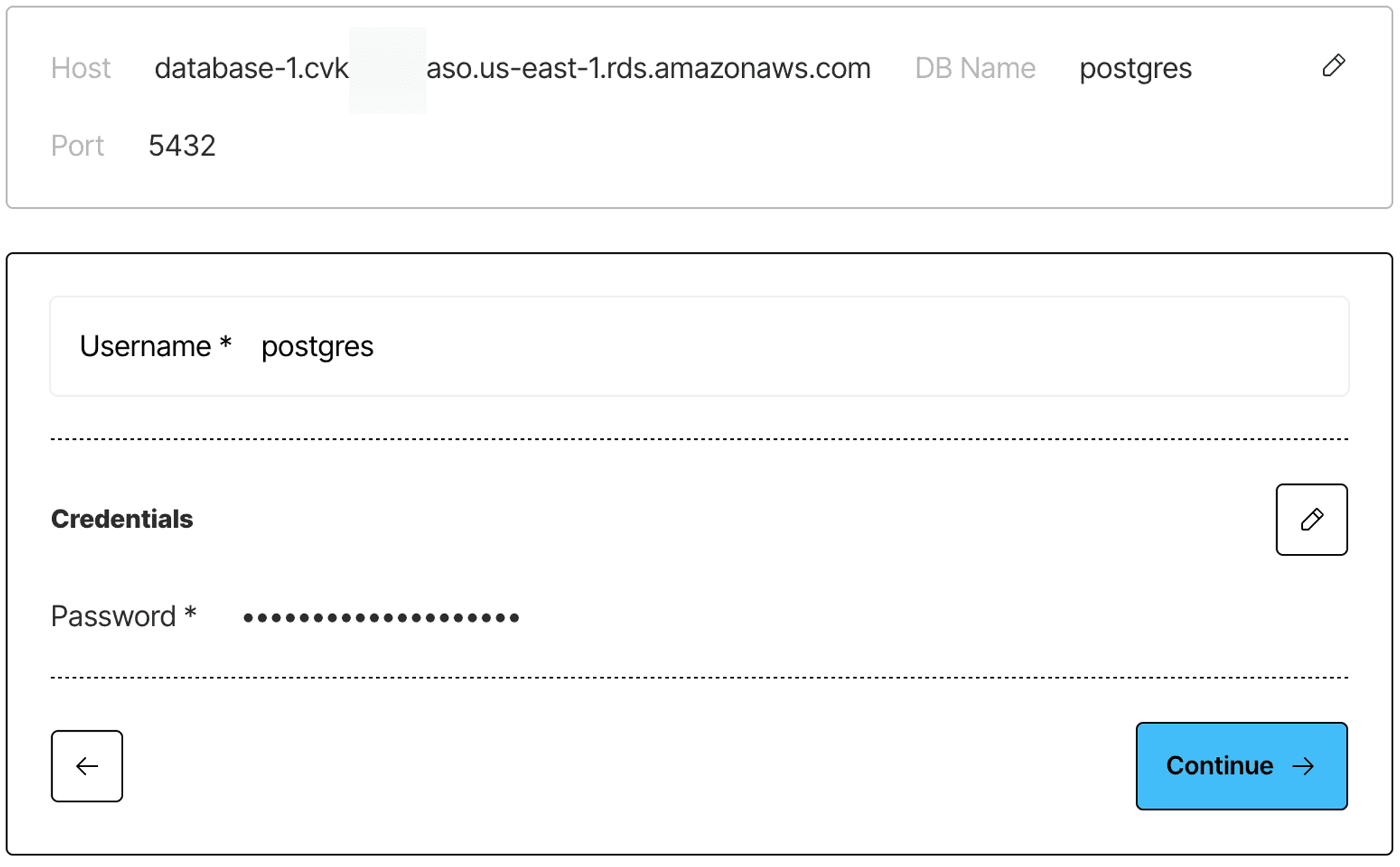
Table name, ID column, and column names (source connector only):
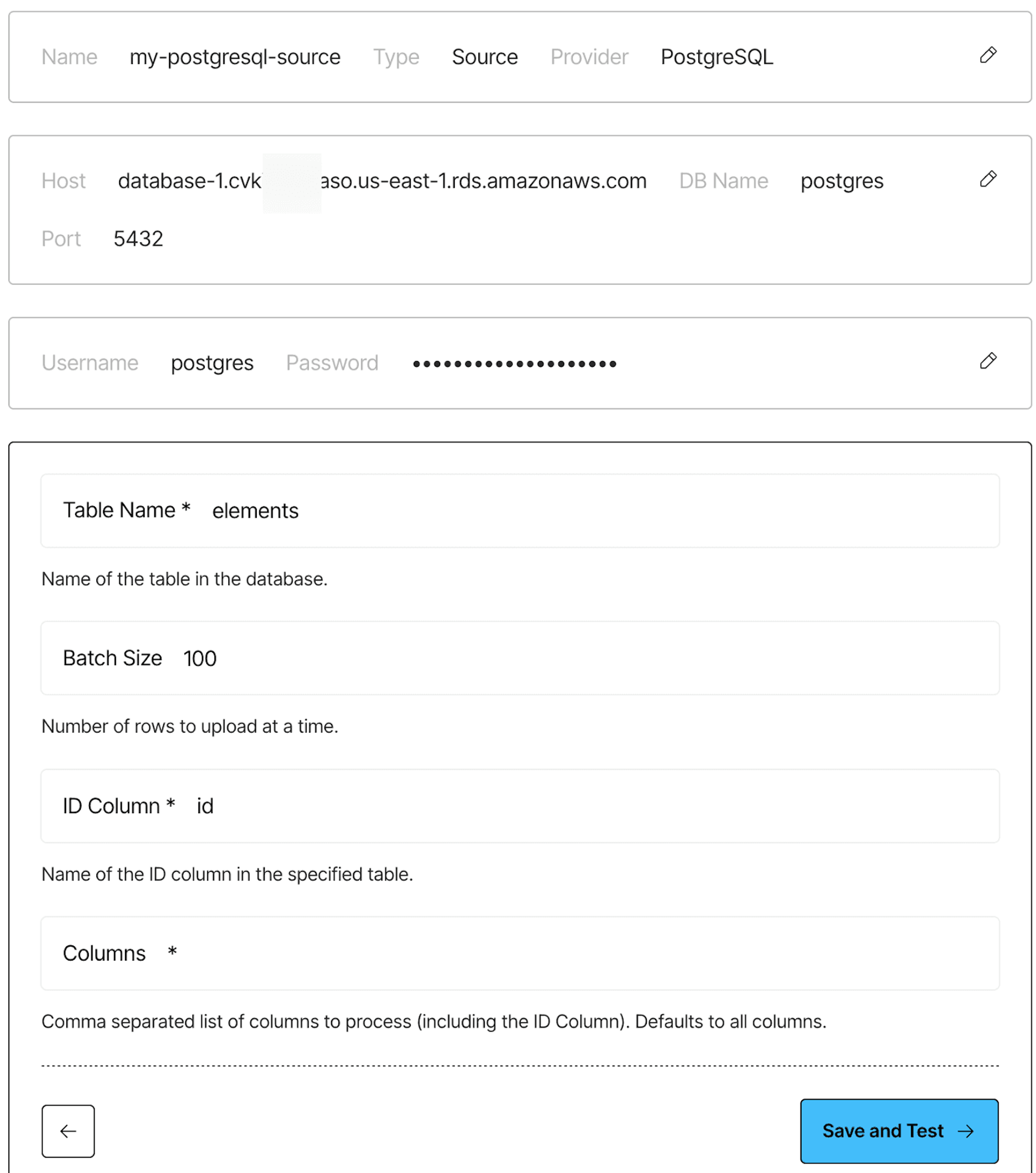
Table name (destination connector only):
To create a workflow for the source or destination connector by using the Unstructured Platform user interface, see Create a workflow in the Unstructured documentation.
To configure the source or destination connector by using the Unstructured Platform API instead, you can run one of the following curl commands. In this command, set the environment variables beginning with UNSTRUCTURED to the Unstructured Platform API URL and your Unstructured Platform API key; and fill in your PostgreSQL database’s host name and port number, database username and password, table name, and optionally a batch size representing the maximum number of records to transmit at a time. For the source connector, also specify the name of the ID column in the table, and optionally a comma separated-list of column names to process, including the specified ID column; the default is all columns if not otherwise specified.
For the source connector:
curl --request 'POST' --location \
"$UNSTRUCTURED_API_URL/sources" \
--header 'accept: application/json' \
--header "unstructured-api-key: $UNSTRUCTURED_API_KEY" \
--header 'content-type: application/json' \
--data \
'{
"name": "<name>",
"type": "postgres",
"config": {
"host": "<host>",
"database": "<database>",
"port": "<port>",
"username": "<username>",
"password": "<password>",
"table_name": "<table-name>",
"batch_size": <batch-size>,
"id_column": "<id-column>",
"fields": [
"<field>",
"<field>"
]
}
}'For the destination connector:
curl --request 'POST' --location \
"$UNSTRUCTURED_API_URL/destinations" \
--header 'accept: application/json' \
--header "unstructured-api-key: $UNSTRUCTURED_API_KEY" \
--header 'content-type: application/json' \
--data \
'{
"name": "<name>",
"type": "postgres",
"config": {
"host": "<host>",
"database": "<database>",
"port": "<port>",
"username": "<username>",
"password": "<password>",
"table_name": "<table-name>",
"batch_size": <batch-size>
}'To create a workflow for the source or destination connector by using the Unstructured Platform API, see Create a workflow in the Unstructured documentation.
Get started!
If you're already an Unstructured Platform user, the PostgreSQL source and destination connectors are available in your dashboard today!
Expert access
Need a tailored setup for your specific use case? Our engineering team is available to help optimize your implementation. Book a consultation session to discuss your requirements here.


