
Authors

Welcome to Part 2 of our deep dive into PDF processing with Unstructured! In Part 1, we laid the groundwork by exploring how Unstructured dissects complex PDFs, transforming them from challenging, visually-focused documents into a structured, developer-friendly list of document elements. We saw that whether it's a Title, NarrativeText, Table, or an Image, each element comes with rich metadata, providing context and making the data AI-ready.
However, the journey from a raw PDF to these clean elements isn't always straightforward. PDFs vary wildly: some are clean, digitally-native documents, while others are scanned, have complex multi-column layouts, or contain intricate tables and forms. A one-size-fits-all approach to parsing simply won't cut it. This is where the power of Unstructured's different parsing strategies comes into play.
This second part of our guide will focus on these strategies. We'll explore the various methods Unstructured offers, from fast and simple to highly sophisticated, to generate the document elements we learned about in Part 1. Our goal is to equip you with the knowledge to choose the best strategy—or combination of strategies—for your specific PDF processing tasks, balancing considerations of speed, cost, and accuracy.
Let's dive into the "how" of PDF transformation.
PDF Parsing Strategies: Choosing Your Weapon
PDFs aren't one-size-fits-all, and neither are the methods to parse them. Unstructured offers multiple parsing strategies because, let's face it, a strategy optimized for a clean, text-based technical manual would probably struggle with a scanned, coffee-stained invoice. Picking the right one depends on your PDF's complexity, its origin (digital-native vs. scanned), the quality of the document itself, and, critically, your own project's requirements for speed, cost, and accuracy.
In Part 1, we saw what Unstructured produces: a list of document elements. Now, we'll explore how these elements are generated by looking at the main strategies Unstructured puts at your disposal.
1. Fast Strategy: For Speed and Simplicity
Think of it as: The quick, lightweight option. It’s designed for speed when you're dealing with documents that have relatively straightforward structures or when you primarily need to pull out text without intense layout analysis.
Best For:
- Simple, digitally-born PDFs that are mostly text with basic formatting.
- HTML files, TXT files, and other non-PDF textual formats.
- Use cases where processing cost and speed are paramount, and perfect layout fidelity is secondary.
How It Works (Under the Hood):
- Primarily relies on extracting text directly from the PDF's content streams (the embedded text objects).
- Uses heuristics to determine reading order and basic element breaks. It doesn't perform deep visual analysis or OCR.
Pros:
- Speed: It's the fastest of the bunch.
- Cost-Effective: "Cheap" in terms of computational resources and actual costs.
Not the Best Option for:
- Complex Layouts: Will likely struggle with multi-column text, tables, handwritten text, or documents where text flow isn't linear.
- Images & Scanned Content: Generally won't process text within images or fully scanned pages (as it doesn't inherently invoke OCR).
2. Hi-Res Strategy: The Workhorse for Visually Complex Digital PDFs
Think of it as: Your go-to for most digitally-born PDFs that contain a mix of text, tables, and images where layout matters. It leverages computer vision methods to understand the page structure.
Best For:
- Complex PDFs with embedded images, tables, and varied layouts (e.g., reports, contracts, academic papers, brochures, technical manuals).
- When you need to accurately identify different semantic elements (titles, paragraphs, lists, tables) based on their visual presentation.
How It Works (Under the Hood):
- Object Detection Core: At its heart, Hi-Res uses an object detection model (our proprietary custom YoloX model, trained on a large corpus of documents) to identify regions of interest on the page – these are your bounding boxes for text blocks, tables, images, titles, etc.
- Mapping to Ontology: The detected objects (bounding boxes with class labels like "table" or "figure") are then intelligently mapped to Unstructured's semantic element types (Table, Image, NarrativeText, etc.).
- Table Processing: When a table is detected via its bounding box, that region is passed to a specialized Table Transformer model (another custom-trained model) designed to understand the row/column structure.
- Key Win: Unstructured typically outputs these tables as clean HTML strings in the element's metadata, as discussed in Part 1. This is a significant advantage over frameworks that might only give you Markdown, as HTML preserves a richer structure.
- OCR (Optical Character Recognition) Integration: We use custom-tuned versions of OCR engines like Tesseract and PaddleOCR to convert that image text into machine-readable characters. The OCR is applied strategically to the identified text-containing bounding boxes.
Pros:
- Excellent accuracy on a wide variety of complex PDFs.
- Detailed element breakdown with reliable bounding box coordinates (as seen in Part 1).
- Structured HTML output for tables.
- Handles embedded images and can apply OCR where needed.
Cons & Common Pitfalls for Developers:
- Table Transformer Limits: While good, our Table Transformer (like all current table models) can still struggle with exceptionally complex tables – think multi-page spanning cells, deeply nested structures, or tables with very unconventional formatting.
- Not ideal for purely scanned, handwritten, or low-quality documents where there's little digital text or layout information to begin with (that's where VLMs start to shine).
3. VLM (Vision Language Model) Strategy: The Heavy Artillery for the Toughest Cases
Think of it as: Calling in the big guns when other methods struggle, especially for documents that are primarily images of text or have extremely challenging layouts.
Best For:
- Scanned documents, especially those with poor quality, varied fonts, or handwritten annotations.
- PDFs with highly unconventional or "broken" layouts that confuse traditional object detection.
- Extracting information from forms or documents where the semantic understanding of visual groupings is paramount.
How It Works (Under the Hood):
- Image-First: The PDF page is effectively treated as an image.
- VLM Power: This image, along with a custom-crafted prompt, is sent to a powerful Vision Language Model (we leverage models from providers like OpenAI (e.g., GPT-4o) and Anthropic (e.g., Claude 3.7 Sonnet)). The prompt guides the VLM to "read" the page and identify structural elements based on our desired ontology.
- Mapping Outputs: The VLM's response is then carefully parsed and mapped back into Unstructured's standard list of document elements.
- Mitigating Hallucinations: This is an active area of development for all VLM applications. We use careful prompting and output validation techniques, but developers should be aware that VLMs can occasionally "hallucinate" or misinterpret content.
Pros:
- Can often succeed where other strategies fail, especially on scanned or visually degraded documents.
- Offers high accuracy in understanding complex relationships between visual elements.
Cons & Developer Considerations:
- Cost: VLM calls are generally the most expensive strategy due to the computational cost of these large models. It's often not necessary or cost-effective for every page of every document.
- Image Element Extraction: While a VLM can identify that an image exists and even describe it, getting precise bounding box coordinates for that sub-image element itself (to allow for its separate extraction) is less straightforward than with object detection models like YOLOvX. The VLM "sees" the whole page image you send it.
4. Auto Strategy: The Smart Orchestrator
Think of it as: An intelligent manager dynamically choosing the best parsing approach per page to optimize for quality and cost.
Best For:
- Diverse document collections with varying complexity.
- Optimizing quality and cost without manual page-by-page inspection.
- A good general-purpose starting point for unknown PDF types.
How It Works (Under the Hood):
- Dynamic Routing: Auto analyzes each page individually, acting as an intelligent routing system rather than a distinct parsing method.
- Per-Page Decision Making:
- Simple, text-based pages may use a Fast-like approach.
- Pages with complex structures (tables, images, intricate layouts) are typically routed to "Hi-Res."
- Scanned pages or those where Hi-Res struggles might be escalated to VLM if enabled and deemed necessary.
Pros:
- Balanced Performance: Applies powerful (and costlier) strategies only when a page's characteristics warrant, optimizing accuracy.
- Cost Savings: More cost-effective for large, mixed-complexity document sets than uniformly applying Hi-Res or "VLM."
- User Simplicity: Provides a robust, general-purpose solution, handling strategy decisions automatically.
Working Example: Hi-Res vs. VLM for Tables
Extracting tables accurately from PDFs is challenging due to complex structures like merged cells, missing borders, and multi-level headers. The Hi-Res and VLM strategies offer different strengths here. Consider the example below:
Original Table: The example shows a complex table with multi-level column headers (e.g., "Population," "Population Share %" spanning sub-categories), varied alignments, and implicit groupings.
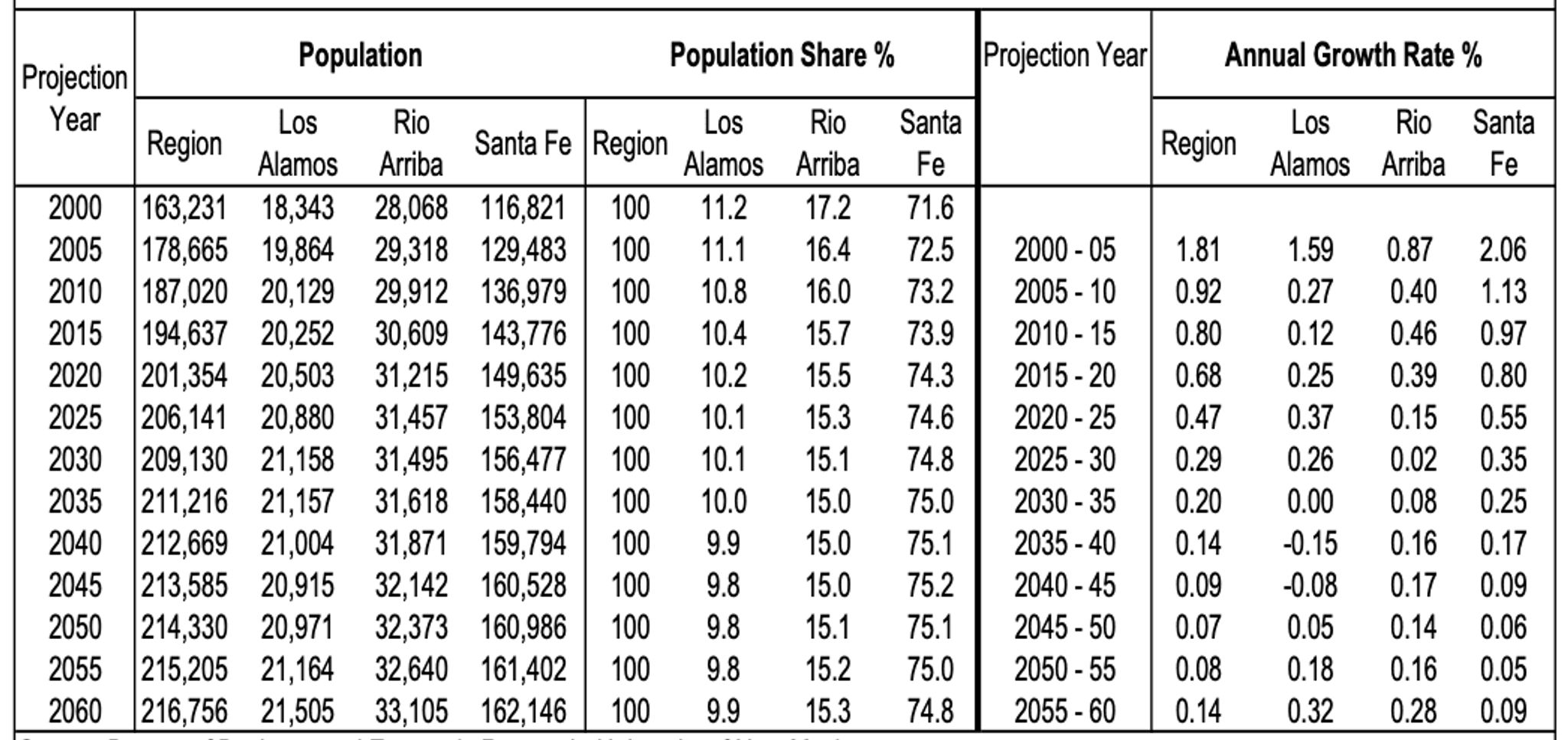
Hi-Res Output: Hi-Res uses object detection and table transformers. For such tables:
- It identifies most cells and extracts text.
- For highly nested headers (like "Population Share %"), it might flatten the hierarchy or struggle with precise granular mapping. The visual example shows data capture, but groupings under multi-level headers might be less distinct than the original.
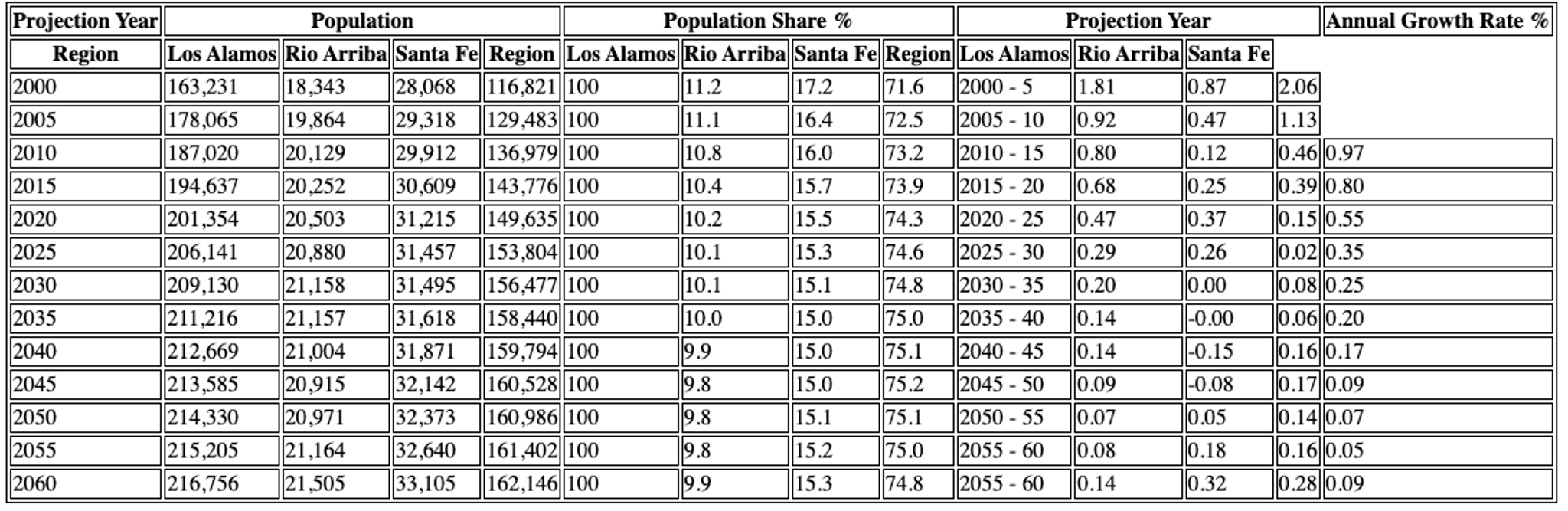
VLM Output: VLM treats the table as an image, applying a vision-language model for a more holistic understanding:
- It's generally better at interpreting complex, nested headers (e.g., recognizing "Projection Year" as a parent header).
- The HTML output more accurately reflects these hierarchies, offering clearer semantic structure, as seen in the visual example's cleaner data association under multi-level headers.
- It's more robust to visual inconsistencies or missing borders.
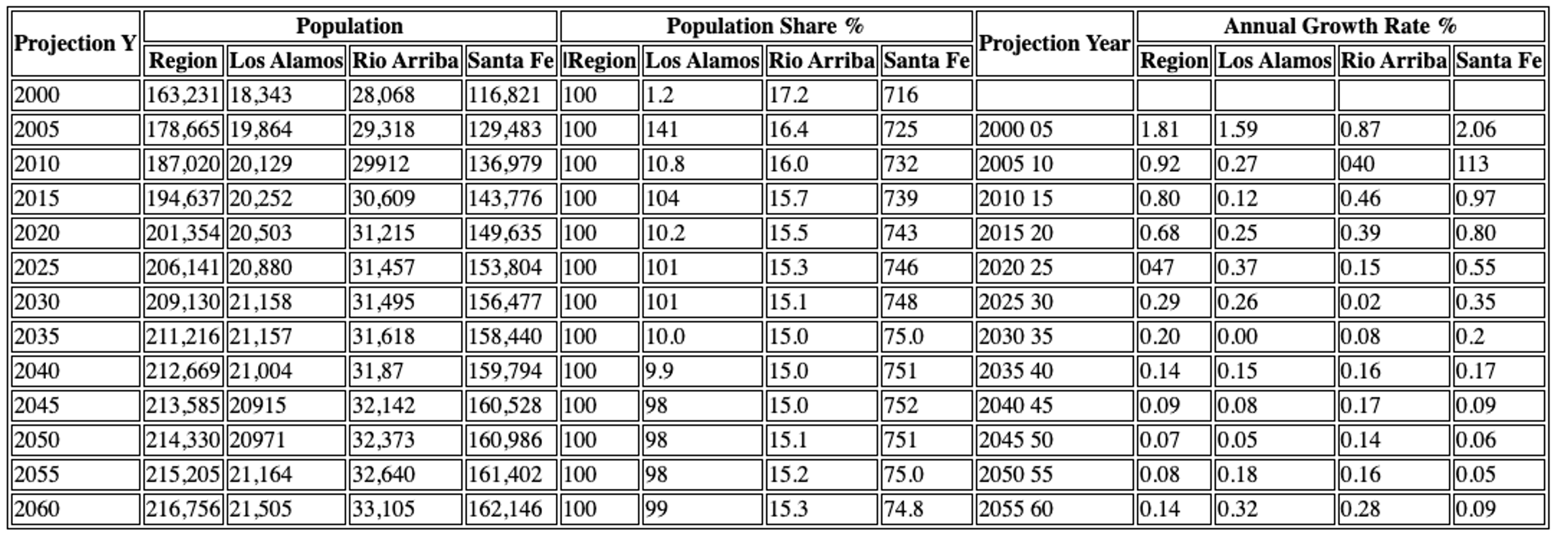
Key Differences & When to Choose:
- Structural Fidelity: For deep, nested headers or unconventional layouts, VLM often excels.
- Accuracy vs. Cost/Speed: Hi-Res is faster and cheaper. It's effective if minor imperfections in complex headers are acceptable.
- Content Type: For scanned tables (pure images), VLM is better suited.
Key Technical Tradeoffs: Speed, Cost and Accuracy
Beyond Basic Parsing: Preparing Data for AI/RAG
Getting structured elements out of your PDFs using the right parsing strategy is a massive win, but for many AI-driven applications, especially RAG systems, it's just the first crucial step. Once Unstructured has dissected your document into meaningful pieces like Title, NarrativeText, and Table elements, you'll often want to further prepare this data to make it optimally useful for LLMs.
Here’s a look at common next steps and features Unstructured provides to get your data AI-ready:
- Chunking for Context: LLMs have context window limits. Simply feeding them entire documents, or even large elements, can be inefficient or lead to lost information. Unstructured helps you intelligently break down your parsed elements into optimally sized, coherent chunks. This can be done using various strategies, such as chunk_by_title (which keeps related content under a heading together) or fixed-size methods, ensuring that each chunk is semantically relevant and fits within LLM constraints.
- Embedding for Search: To enable semantic search and retrieval (the 'R' in RAG), your text chunks need to be transformed into numerical representations called vector embeddings. Unstructured facilitates this by integrating with popular embedding model providers (e.g., OpenAI, TogetherAI, and others). This converts your textual content into vectors that capture its meaning, allowing systems to find the most relevant chunks based on query similarity.
- Enrichments for Content Depth: Raw text, even when chunked and embedded, can sometimes lack the necessary signals for high-quality retrieval. Unstructured allows for enrichments that add more semantic value:
- Named Entity Recognition (NER): Automatically tag entities (like people, organizations, locations, dates) within your text. This can improve search precision and provide more context to the LLM.
- Summarization/Descriptions: For table elements or even image elements (where alt-text or VLM-generated descriptions can be created), generating concise summaries can provide quick context or alternative representations for retrieval.
- Load to Destinations: Once your data is parsed, chunked, embedded, and enriched, it needs to be stored in a system that your AI application can query. Unstructured supports direct and automatic indexing of your processed, AI-ready data into all major vector database destinations (e.g., Pinecone, Weaviate, Qdrant, Neo4j, and many more). This streamlines the pipeline from raw document to queryable knowledge base.
- Efficient Workflows (fsspec connectors & scheduling): For ongoing processing, Unstructured's platform considers efficiency.
- Connectors (fsspec): When using connectors to sources like S3, GCS, Azure Blob Storage, etc., Unstructured can keep track of processed files. This means you don't necessarily have to reprocess all documents every time; only new or updated files are processed, saving time and cost.
- Scheduling: You can schedule your document processing workflows to run at regular intervals, ensuring your AI application always has access to the latest information from your document sources.
By leveraging these capabilities, you move beyond basic parsing, ensuring access to high-quality, contextually rich, and easily retrievable information.
Enterprise Grade Security and Parsing
Handling sensitive documents in enterprise environments demands robust security and strict compliance. Unstructured’s Enterprise ETL+ platform is purpose-built to meet these high standards, offering both flexibility and peace of mind.
Key features include:
- Continuous and Scalable Processing: Automatically handles large document volumes with consistent performance, making it ideal for real-time data pipelines.
- Strict Compliance Standards: Supports SOC 2 Type 2, HIPAA, and GDPR, ensuring regulatory alignment across industries.
- In-VPC Deployments: Keeps data within your organization’s Virtual Private Cloud for full control and enhanced security.
- Custom Preprocessing & Integrations: Easily integrates with third-party systems and allows for tailored preprocessing steps to fit existing enterprise workflows.
Conclusion
Across this two-part series, we've journeyed from the complexities of PDF structures to the sophisticated strategies Unstructured employs to tame them. In Part 1, we established the importance of a structured, element-based output. In this Part 2, you've gained insight into the different parsing strategies—Fast, Hi-Res, VLM, and Auto—understanding their trade-offs in speed, cost, and accuracy, particularly for challenging elements like tables.
The ability to choose the right strategy, or let Auto intelligently decide, empowers you to convert diverse PDF landscapes into clean, AI-ready data. Coupled with features for chunking, embedding, enrichment, and secure enterprise deployment, Unstructured provides a comprehensive toolkit to unlock the valuable information within your documents.To start transforming your data with Unstructured, contact us to get access. For enterprises with complex needs, we offer tailored solutions. Book a session with our engineers to explore how Unstructured can fit your workflows.
FAQ
What are the main challenges with parsing PDFs for AI applications?
PDFs vary significantly in structure and origin, from clean digital documents to scanned images with degraded quality, complex multi-column layouts, and intricate tables. A single parsing approach cannot handle this range effectively, which means accuracy, speed, and cost all depend on matching the right method to the document type.
Why do complex tables cause problems for traditional PDF parsers?
Tables with multi-level headers, merged cells, missing borders, and nested structures require understanding both the visual layout and the semantic relationships between cells. Most traditional parsers extract text linearly and lose the hierarchical context that makes table data meaningful for downstream applications.
When should a RAG pipeline use a vision-language model instead of a layout-based parser?
Vision-language models are best suited for scanned documents, handwritten content, or pages with unconventional layouts that confuse object detection approaches. For clean, digitally-born PDFs, a layout-based parser is typically faster and more cost-effective, reserving VLM processing for cases where visual understanding is genuinely necessary.
How does Unstructured handle documents that mix simple and complex pages in the same file?
Unstructured's Auto strategy analyzes each page individually and routes it to the appropriate parsing method, applying Fast-like processing to simple text pages and escalating to Hi-Res or VLM for pages with tables, images, or scanned content. This per-page routing avoids the cost of applying heavy models uniformly across an entire document.
Why does Unstructured output extracted tables as HTML rather than Markdown?
HTML preserves structural details like merged cells, nested headers, and multi-column spans that Markdown cannot represent accurately. For AI applications that need to reason over table content, this richer representation reduces information loss between the original document and what the LLM ultimately receives.


