
Authors

The latest generation of frontier models are doing things that weren't possible a year ago. They score at or near human-expert level on complex reasoning benchmarks. They handle million-token context windows. They write code, analyze financial models, process documents, and produce output that holds up to real professional scrutiny. The progress here is genuine, and the benchmarks reflect it.
If you're building a pipeline that processes real enterprise documents — invoices, financial reports, contracts, technical manuals — you've probably looked at these models and wondered how far a good one can get you. The benchmarks look strong. The capabilities look promising. So what actually happens when you point one at a stack of real documents with a simple extraction prompt and ask it to do the work?
That's exactly what we wanted to find out.
How We Ran the Test
We used SCORE-Bench, our open benchmark for document parsing consisting of 224 real-world documents that reflect what actually shows up in enterprise environments. Scanned invoices with skewed text, financial reports with deeply nested tables, healthcare forms, legal contracts, technical documentation with complex multi-column layouts. The full dataset is publicly available on Hugging Face.
We tested Claude Opus 4.6, GPT-5.2, Claude Sonnet 4, GPT-5-mini, and Gemini 2.5 Pro, each with a simple extraction prompt and no additional configuration. The baseline was our VLM Partitioner pipeline which used Claude Opus 4.5 with an optimized extraction prompt, post-processing, and output structure enforcement on top.
The gap between those two conditions is what the results measure.
The Results
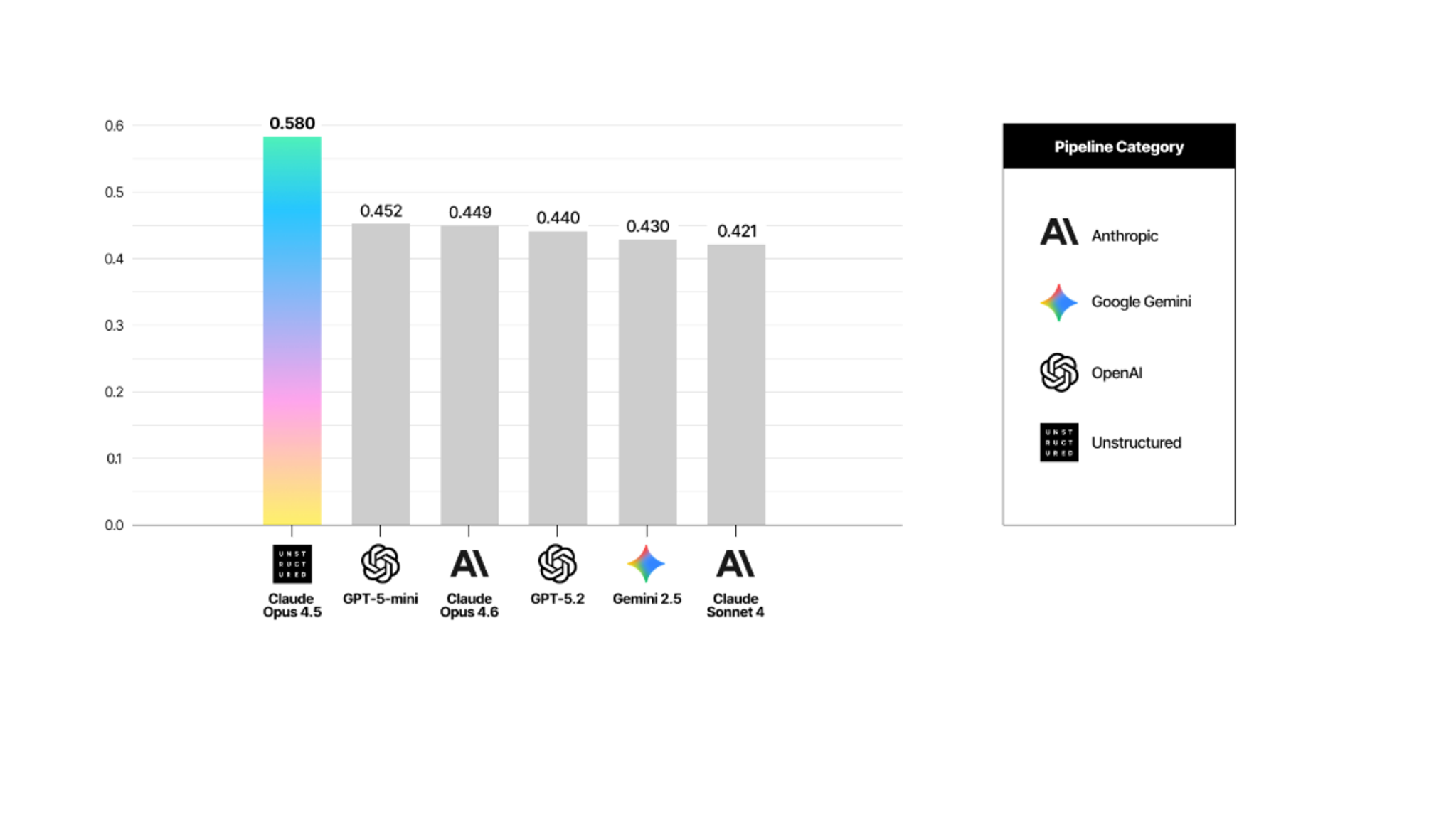
Across all five models, overall accuracy ran between 4 and 16 percentage points below our pipeline on the composite metric. Here's the full picture:
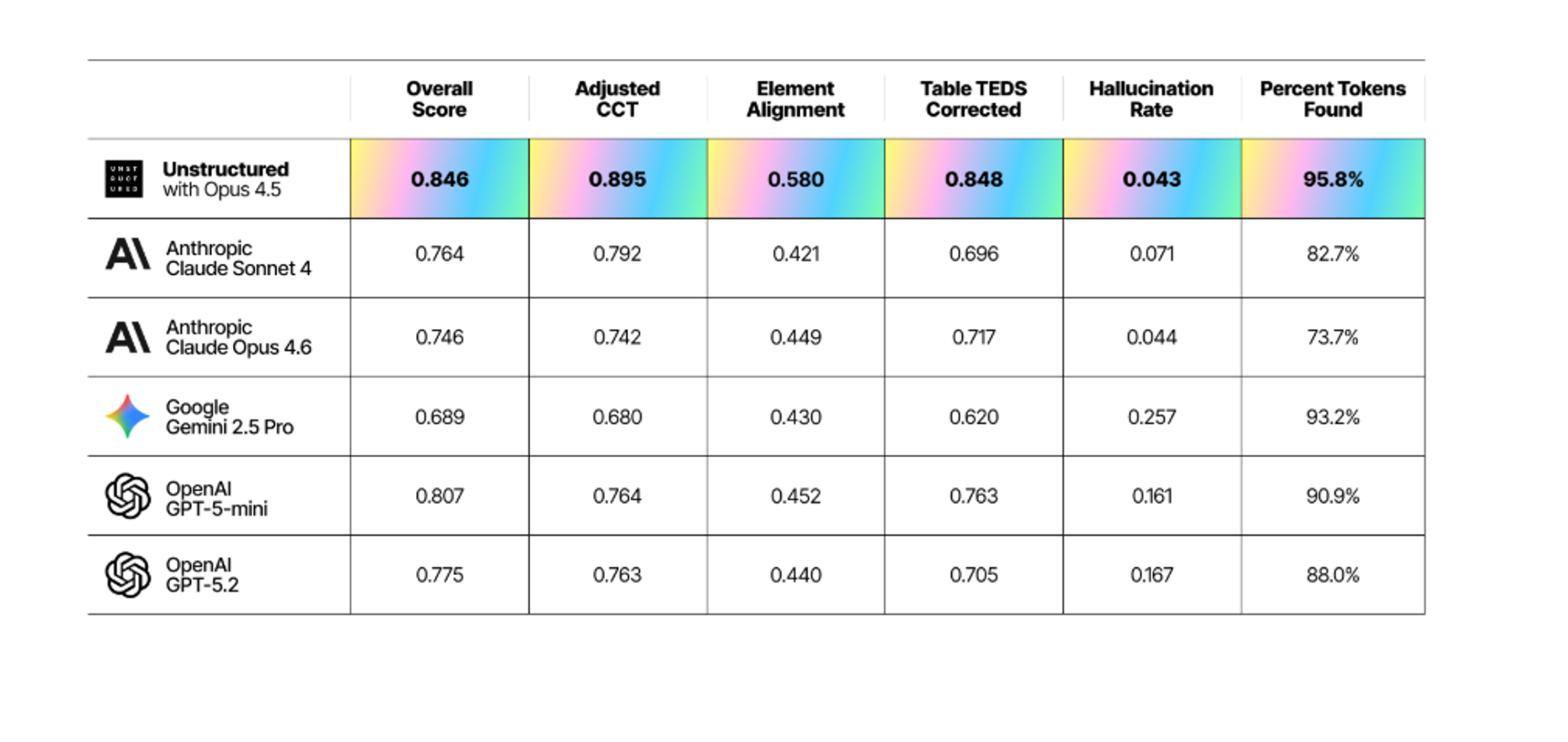
The gap isn't uniform across metrics. On some — hallucination control in particular — certain models land surprisingly close to our pipeline. On others, especially table extraction and document structure, the distance is considerably wider. That's where the more interesting findings are.
Where the Gap Opens Up
Hallucination Rate
This is the finding that surprised us most. Hallucination Rate measures how many tokens a model generates that aren't present in the source document. On this metric, Opus 4.6 stands out. Its rate was 0.044. Ours was 0.043. For practical purposes, they're the same.
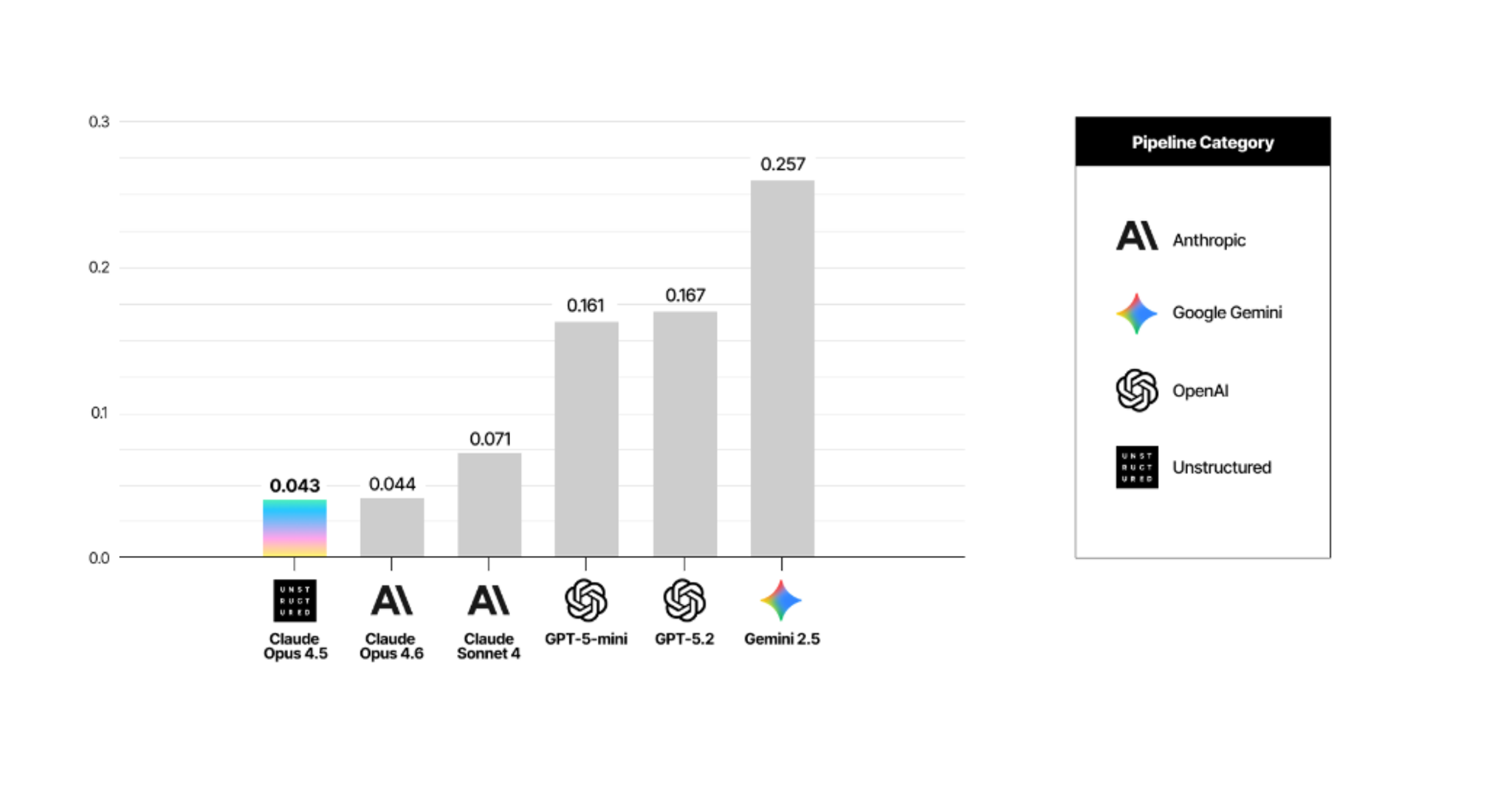
GPT-5.2 came in at 0.167, roughly four times our rate. GPT-5-mini at 0.161. Gemini 2.5 Pro at 0.257.
What this means for your pipeline: hallucinated content doesn't announce itself. It looks like extracted text. It flows into your vector store, gets retrieved, and feeds into your LLM as if it were real. The downstream effect is answers that are confidently wrong in ways that are hard to catch. Opus 4.6's base capability here is real. The model reads the document and doesn't invent content that isn't there. Where it falls short is structural, which is a different problem entirely.
The flip side of hallucination is coverage — how much of the source document actually makes it into the output. Opus 4.6 sits at 0.737 here, the lowest of all models tested. So while it barely hallucinates, it's also missing roughly a quarter of the document's content.
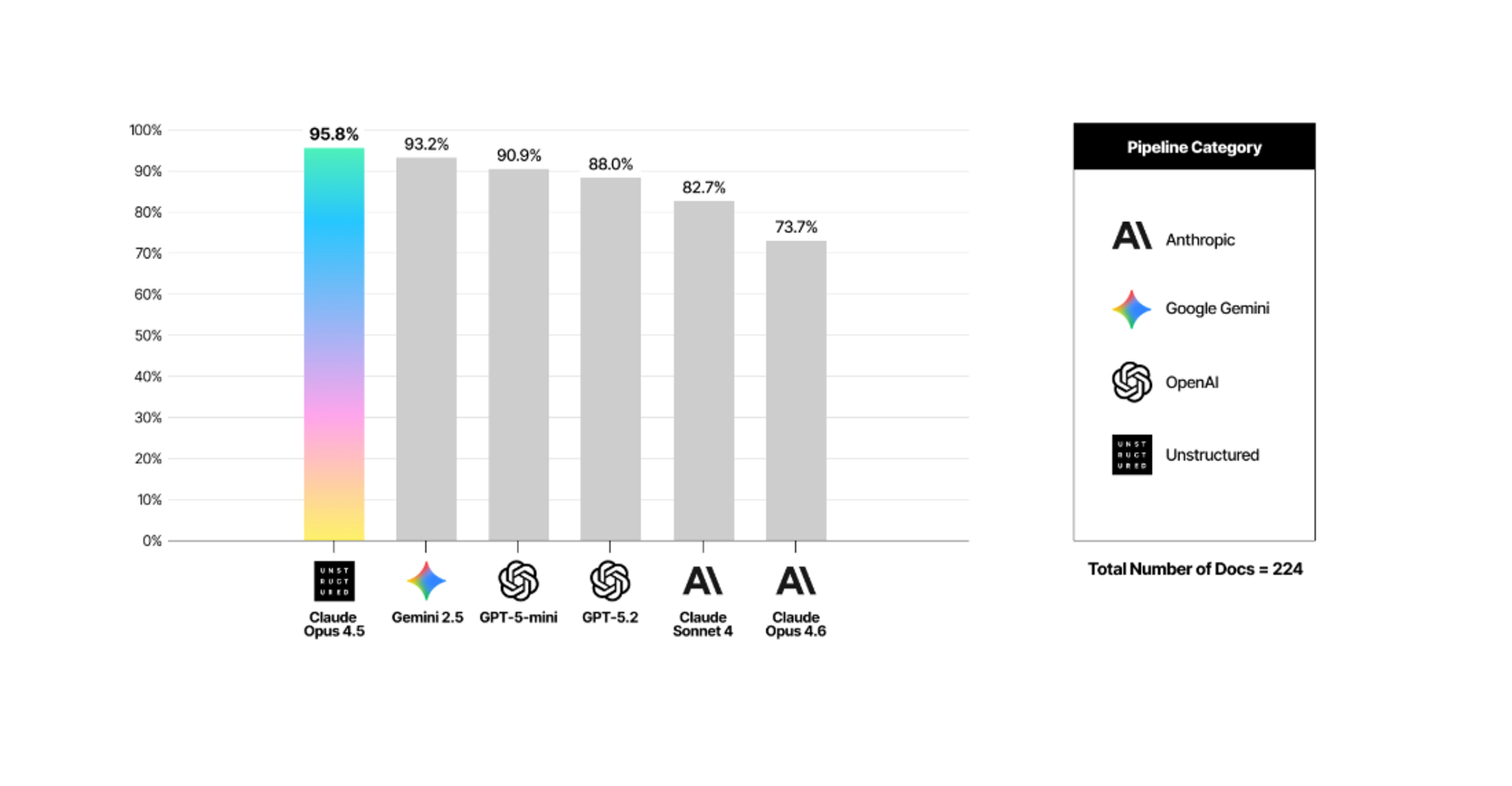
The tradeoff is worth understanding. Models that find more content tend to invent more too. GPT-5.2 and GPT-5-mini score higher on coverage but carry higher hallucination rates. Gemini finds a lot but hallucinates at the highest rate of the group. Getting both right at the same time — high recall, low hallucination — is what the numbers at the top of that chart reflect.
For your pipeline, missing content means gaps in retrieval. Your LLM gets asked a question, the relevant passage was never captured, and the answer comes back incomplete or wrong. It's a quieter failure mode than hallucination but just as real downstream.
Table Extraction
Tables carry a lot of enterprise value. Financial figures, pricing tables, specification sheets. Getting them wrong isn't a minor accuracy issue; it's a data integrity issue.
Across all five models, table extraction accuracy ran up to 23 percentage points below our pipeline.
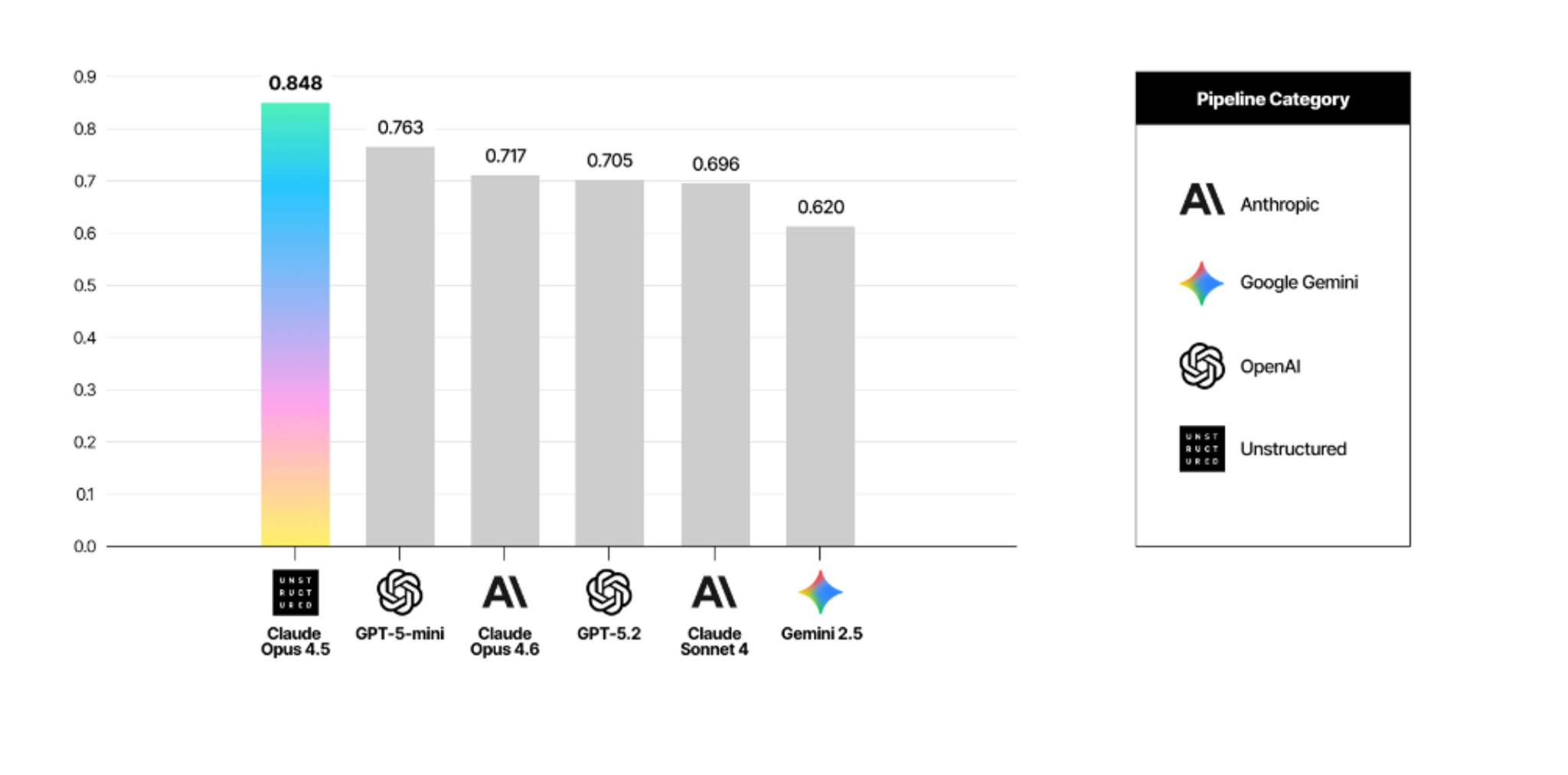
The metric that matters most here isn't just whether the model reads the text inside a cell correctly. It's whether it understands which row and column that text belongs to. A model can read "4.2 million" perfectly and still place it in the wrong column. At that point the number is correct and the meaning is wrong. That's the failure mode you'd run into downstream — not garbled text, but structurally misplaced data that looks right on the surface.
Document Structure
This is the widest gap in the data, and also the hardest problem. Element alignment measures whether a model correctly identifies and sequences headers, paragraphs, tables, and figures. Across all models tested, it came in up to 16 percentage points lower than our pipeline.
What makes this consequential is that element alignment failures are silent. The text is still there. The document was processed. But the structural relationships between elements are wrong. Paragraphs get attributed to the wrong section. Figures get separated from their captions. Subheadings fold into body text. When those chunks land in your RAG pipeline, the context they carry is broken. Your LLM is working with the right words in the wrong order, and the answers it produces will reflect that without any obvious signal that something went wrong.
This is where a simple prompt falls furthest behind, and where the distance between a raw model call and an optimized pipeline is most pronounced.
Output Consistency
Accuracy aside, there's a separate production concern worth naming. Gemini 2.5 Pro returned inconsistent output formats on 12 of the 224 documents, roughly 5% of the dataset, that required post-processing before they could be scored at all.
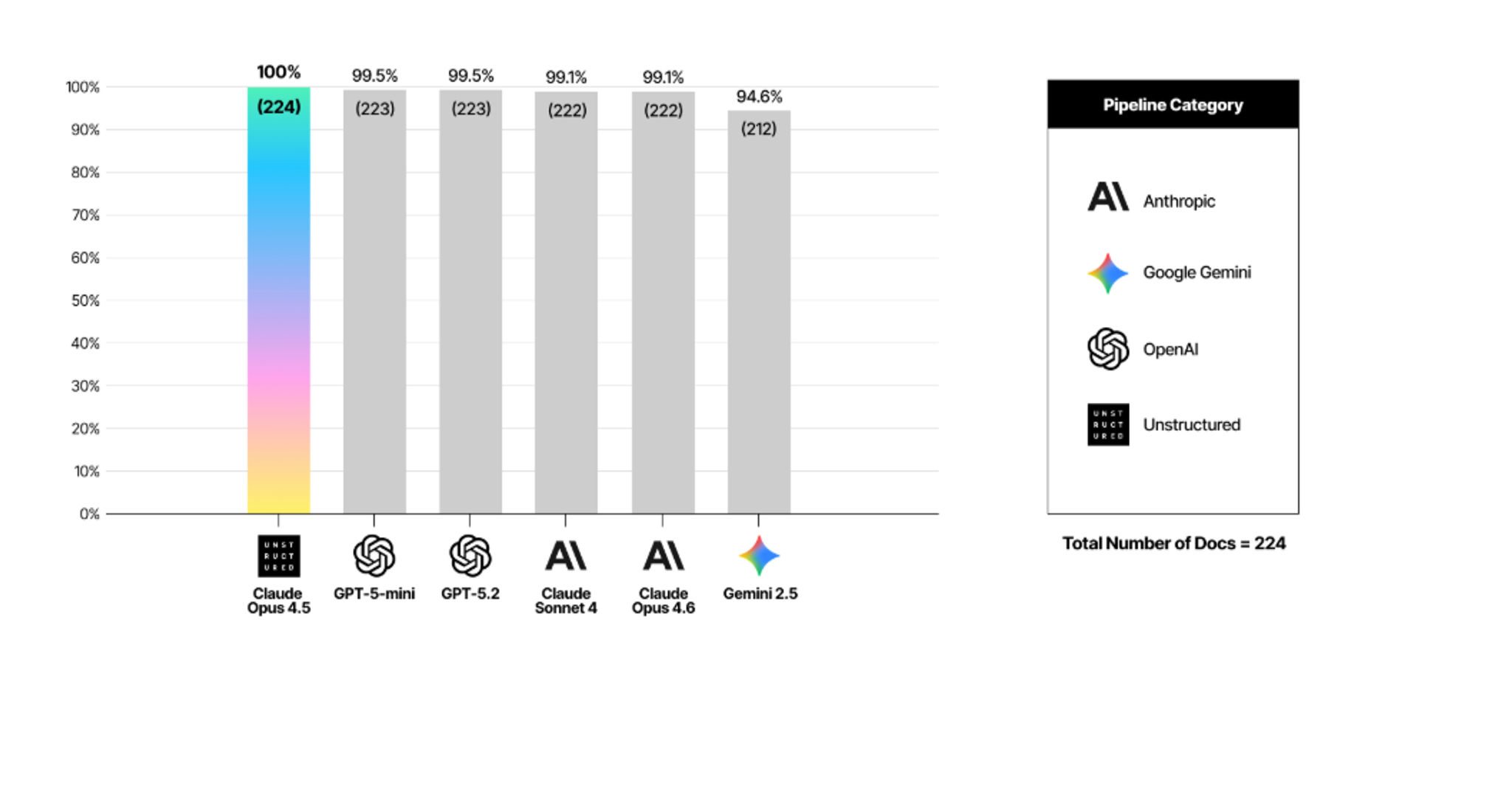
At that rate, you're not just dealing with lower accuracy on some documents. You're dealing with documents your pipeline can't consume directly. At scale that means additional engineering work to handle the exceptions, and a pipeline that can't be fully automated without a fallback layer built in.
What the Gap Is Made Of
The models we tested are capable. The hallucination finding makes that clear — Opus 4.6 reads documents without inventing content that isn't there. The gap isn't a capability problem. It's a configuration problem.
A simple extraction prompt doesn't tell a model how to handle merged table headers, how to sequence document elements, how much content to capture, or what output format to produce. It asks the model to do the work and trusts it will figure out the rest. For many tasks that's fine. For document parsing at enterprise scale, the details a simple prompt leaves unspecified are exactly where things break down.
Three layers separate a raw model call from a production-ready pipeline. Optimized prompting gives the model specific guidance for the structural demands of document parsing: how to think about headers, how to handle irregular table layouts, how to sequence elements, how to balance coverage against accuracy. Post-processing normalizes output and handles the edge cases that even well-prompted models produce. Output structure enforcement defines what a valid response looks like before the model generates one.
Each layer addresses a specific failure mode from the results. The element alignment gap is a prompting problem. The recall tradeoff in Opus 4.6 is a prompting problem. The format inconsistencies in Gemini are an output structure problem. Remove any one of these layers and you see it in the numbers.
The performance improvement doesn't come from the model alone. It comes from what you build around it.
Try It on Your Documents
These are strong models, and the results reflect that. What they also show is that general capability and document parsing performance are different things. The gap between a raw model call and a production-ready pipeline is real, and it's closeable. But it requires more than a prompt.
If you want to see what that looks like on your own documents, sign up for free and run your most challenging files through Unstructured.


