Finding Needles in a Haystack: PII Detection at Scale with Unstructured, Box, and Elasticsearch
Jun 3, 2025
Authors

You’ve got tens of thousands of documents sitting in Box: PDFs, Word files, maybe a few PowerPoints from 2011, and somewhere in there, tucked between meeting notes and legal contracts, is sensitive information. Names, emails, Social Security numbers. The kind of stuff that keeps compliance teams up at night.
The problem? You don’t know where it is. You just know it’s there.
Manually combing through every file isn’t an option, and traditional solutions either choke on unstructured content or need everything perfectly tagged and organized. (Spoiler: your files aren't.)
That’s where Unstructured comes in. We wanted to see how easy it would be to plug into a real-world data source like Box, process the chaos with the Unstructured, and land that content into a system built for search and filtering (Elasticsearch) to flag documents with PII quickly and reliably.
So that’s what we built:A simple but powerful pipeline that takes content from Box, runs it through Unstructured’s parsing and enrichment workflow, and drops the results into Elasticsearch, where you can query for things like email, phone number, or even use regex-based detectors to surface potential issues.
In this post, we’ll walk through how you can set up this pipeline yourself, from fetching your files to parsing them in Unstructured, and surfacing flagged content in Elasticsearch. We’ve already stitched it together, but we’ll rebuild it step-by-step so you can follow along, tweak as needed, and get it working for your own data.
Let’s get started.
Prerequisites
Setting up the Box Source Connector
To get started, let’s use Box as a source using a custom app configured for server authentication with JWT. The goal here is to give Unstructured secure, scoped access to the content you want to process without exposing everything in your Box account.
Here’s the high-level checklist:
- Create a Box Custom App with Server Authentication (JWT).
- Enable the right scopes:
- Write all files and folders stored in Box
- Make API calls using the as-user header
- Authorize the app as a Box Admin.
- Share the target folder with the app’s service account email (you'll find this in the app settings).
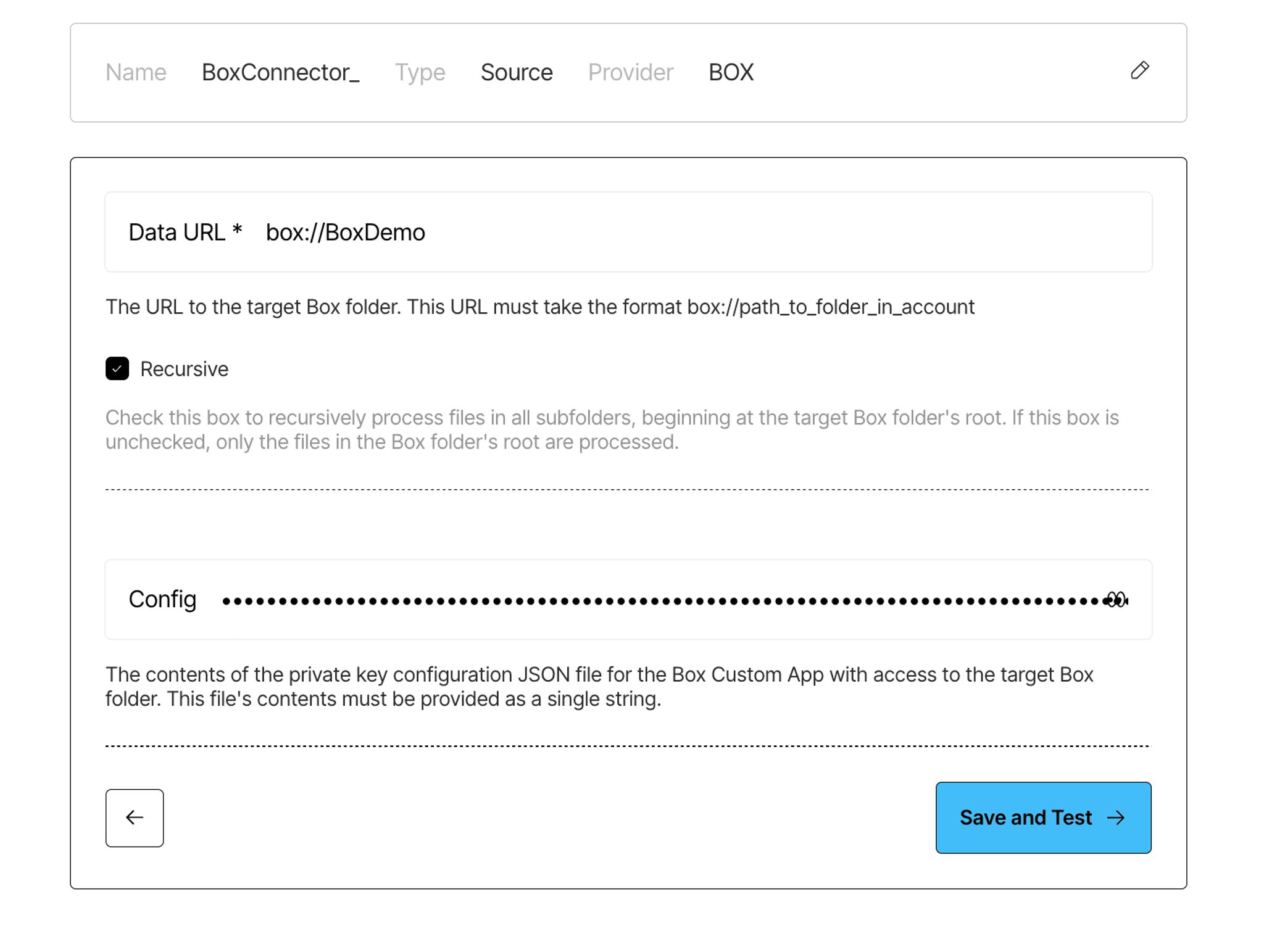
- Grab the remote folder URL( it’ll look like box://path/to/folder/in/account.)
- Generate the private key JSON file from the Box developer console. You’ll paste this (as a single-line string) into the connector setup.
If any of this sounds unfamiliar, this video has your back. Once it’s set up, you’re ready to connect Box as a source in the UI.
Once you’ve gathered these details, log into the Unstructured, head over to the Connectors tab, and click Create Connector → Source → Box. Paste in the required values and hit save. Your source connector is now ready to go.
Setting up the Elasticsearch Destination Connector
To send processed data to Elasticsearch, all you need is:
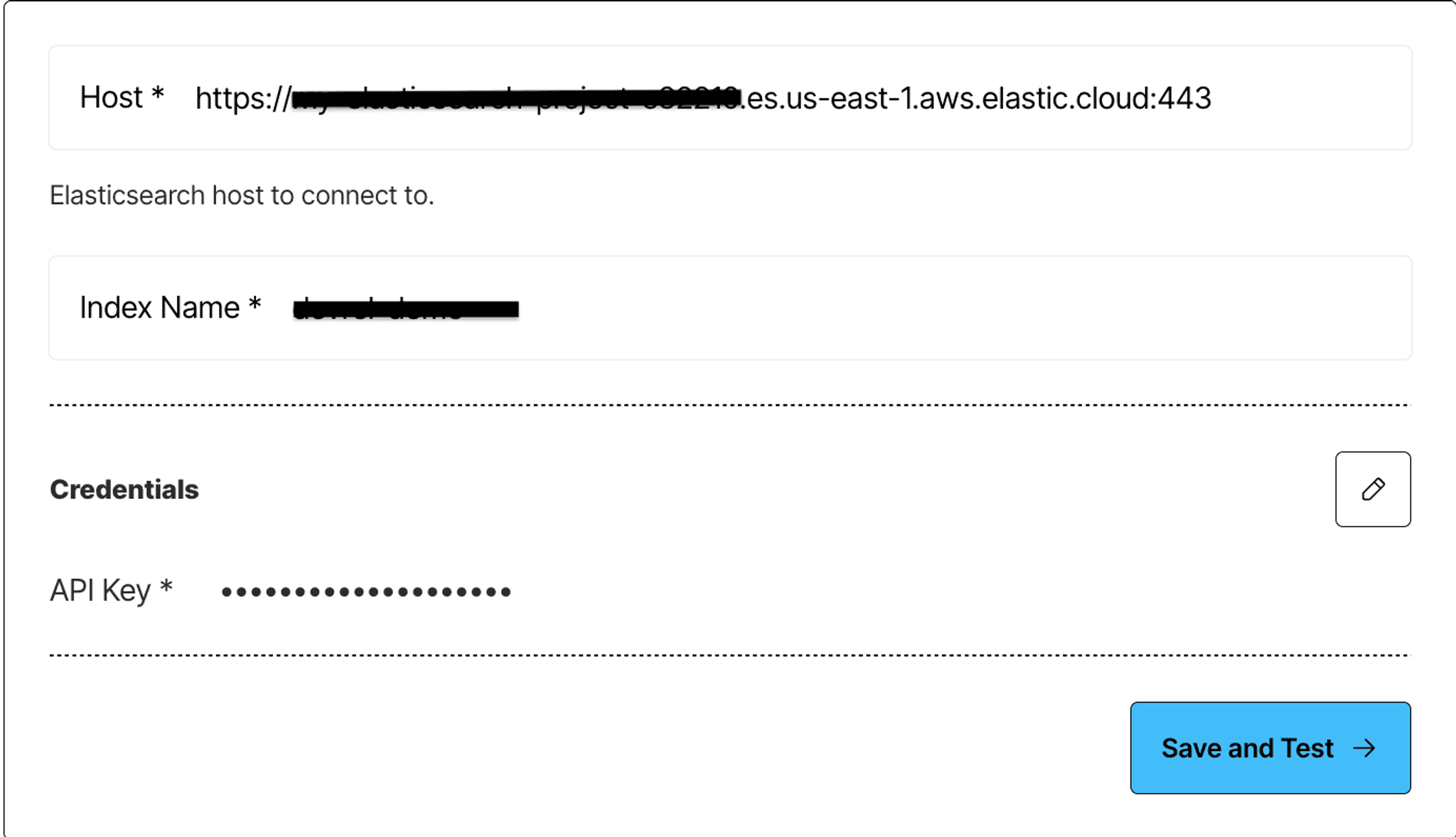
- Elasticsearch Endpoint URLFor example:https://my-elasticsearch-project-.es.us-east-1.aws.elastic.cloud:443
- API KeyYou can generate this from your Elasticsearch dashboard under Management > Security > API Keys.
- Elasticsearch Index
If you need help, these docs cover it in more detail.
And then, just like before, jump into the Unstructured UI, navigate to the Connectors tab, and click Create Connector → Destination → Elasticsearch. Enter your details, save, and you're good to go.
Now that we’ve set up the connectors, let’s get into the workflow.
Building It Out in the UI
Once you're inside Unstructured, the real fun begins. The interactive workflow builder is like a visual playground for workflows, you get to lay out each transformation step, test it instantly, and tweak things as you go.
Start by going to the Workflows tab, click Create New Workflow and select Build it Myself. This will open up the interactive workflow where you can drag in your sample file to the leftmost node (the source node). You can bring your own Box-connected content or drop in any doc you're curious about (we tried everything from invoices to scanned letters).
From there, it’s all about chaining together the right transformations. Let’s select the Hi-Res option for the Partitioner Node, add Image Description Enrichment, and for PII detection let's add a NER (Named Entity Recognition) enrichment node.
We can use NER enrichment with a custom prompt to extract personally identifiable info like names, phone numbers, and addresses from textual content. To add this to your workflow, select the ‘+’ sign, hover over Enrich and select Enrichment with Text as the input type.
Here’s the prompt we used.
Extract named entities and their relationships from the following text.
Provide the entities, their corresponding types and relationships as a structured JSON response.
Entity types:
- PERSON
- ORGANIZATION
- LOCATION
- ROLE
- PHYSICAL_ADDRESS
- CREDIT_CARD_NUMBER
- SSN_NUMBER
- PERSON_NAME
- EMAIL_ADDRESS
- PHONE_NUMBER
[START OF TEXT]
{{text}}
[END OF TEXT]
Response format json schema: {
"items": [
{ "entity": "Entity name", "type": "Entity type" },
{ "entity": "Entity name", "type": "Entity type" }
]
}What’s great here is you don’t have to wait for the full pipeline to run to see if it's working. Once you’ve added the nodes, just hit “Test ▶” and the platform processes your document right there in the UI. You can even step through the output at each node to see how your prompt is behaving.

If you're exploring Unstructured for the first time, this is the place to start. You’ll get a feel for how it parses your documents, how custom prompts shape the output, and what kind of PII actually gets flagged.
And once you're happy with how it performs, you can click the Source and Destination nodes, add in your newly created Box and Elasticsearch connectors, hit Save and run the workflow.
Querying Results from Elasticsearch
Once the workflow finishes running and the documents land in Elasticsearch, you can start searching through them to spot flagged content, names, SSNs, mock credit cards, and so on.
In our case, we uploaded a mix of financial reports, mock documents with synthetic personal info, and even a few image-based records like fake credit cards. Let’s look at how you can search across that data for sensitive entities, like Social Security numbers using the Elasticsearch Python client.
Start by setting your connection details. These values can come from a secrets manager or be entered manually:
import os
from elasticsearch import Elasticsearch
# Define your Elastic Cloud endpoint and API key
os.environ["ES_API_KEY"] = userdata.get("ES_API_KEY")
os.environ["ES_HOST"] = userdata.get("ES_HOST")
os.environ["ES_INDEX"] = userdata.get("ES_INDEX")
Next, initialize your Elasticsearch client using API key authentication:
# Initialize the Elasticsearch client using API key auth
es = Elasticsearch(
os.environ["ES_HOST"],
api_key=os.environ["ES_API_KEY"]
)Now that you’re connected, let’s define a simple search function that lets you query for a specific entity type, like SSN_NUMBER, CREDIT_CARD_NUMBER, or any other tag extracted by your prompt-based NER node:
def search_data(entity):
'''
Queries Elasticsearch for given entity
returns
responses from Elasticsearch
'''
query = {
"_source": ["metadata.page_number", "metadata.filename"],
"query": {
"bool": {
"should": [
{
"match_phrase": {
"text": entity
}
},
{
"term": {
"metadata.entities-items.type.keyword": entity
}
}
],
"minimum_should_match": 1
}
}
}
response = es.search(index=os.environ["ES_INDEX"], body=query)
return responseThis function searches the text field (containing the Image Node’s results) and also checks the entities-items.type field (which holds tagged entity types from the Text Node). You can tweak this logic depending on how your data is structured.
Let’s run the query and print where these entities show up:
responses = search_data("SSN_NUMBER")
for hit in responses["hits"]["hits"]:
metadata = hit["_source"].get("metadata", {})
print(f"Filename: {metadata.get('filename')}, Page: {metadata.get('page_number')}")Filename: financial_news_data.pdf, Page: 4
Filename: financial_news_data.pdf, Page: 2
Filename: financial_news_data.pdf, Page: 4
Filename: doc_3.jpg, Page: 1
Filename: financial_news_data.pdf, Page: 2
Filename: financial_news_data.pdf, Page: 3
Filename: financial_news_data.pdf, Page: 3
Filename: doc_4.jpg, Page: 1
Filename: doc_1.jpg, Page: 1
Filename: doc_2.jpg, Page: 1Lets check out one of the pages flagged:

From here, you can pivot to reviewing the raw content, surfacing trends, or even integrating this into a review workflow with alerts or dashboards. And since Unstructured outputs rich metadata, there’s a lot you can slice and dice.
Wrapping Up
With just a few clicks and some light configuration, you've got a full pipeline for identifying sensitive information buried deep in unstructured content. Whether it's PDFs, images, or reports, Unstructured helps you parse, enrich, and search it all.
The interactive builder makes it easy to experiment, tune prompts, and test against real documents. And once you're happy with the results, connecting to Elasticsearch gives you a powerful way to query and review flagged content at scale.
Ready to put your knowledge into action? Contact us to get onboarded to Unstructured. For enterprises with more complex needs, we offer tailored solutions. Book a session with our engineers to explore how we can optimize Unstructured for your unique use case.


