
Authors

The Model Context Protocol (MCP) came out in November, and lately it's been getting a lot more attention. Anthropic announced MCP as a new standard for connecting AI assistants to the systems like content repositories, business tools, and development environments.
The architecture is straightforward: developers can either expose their functionality through MCP servers or build AI applications (MCP clients) that connect to these servers. Applications like Claude Desktop can then integrate an MCP client and leverage the functionality of a MCP server.
In this blog post, we’ll show you how you can use Unstructured MCP integration, which recently added Firecrawl support, to pull data from a website, partition, enrich, and chunk it to make it searchable—without writing any code.
Here’s what we can do with Unstructured MCP:
1) Crawl a website with Firecrawl.
2) Store the crawled data on Amazon S3.
3) Use the Unstructured API to process data from an S3 bucket into AstraDB.
When done, you’ll be able to easily query the indexed data and ask questions via RAG.
Let’s get started!
Step 1: Set up the MCP Server locally
Clone the UNS-MCP repo. Create a .env file and these keys to your environment, you can also find an example .env.templatehere:
Configure Claude desktop to discover your MCP server.
1) Go to ~/Library/Application Support/Claude/ and create a claude_desktop_config.json.
2) In that file add the following (example here):
Restart Claude Desktop.
Once your environment has been set and claude_desktop_config.json is configured, you begin interacting with our newly added MCP Server.
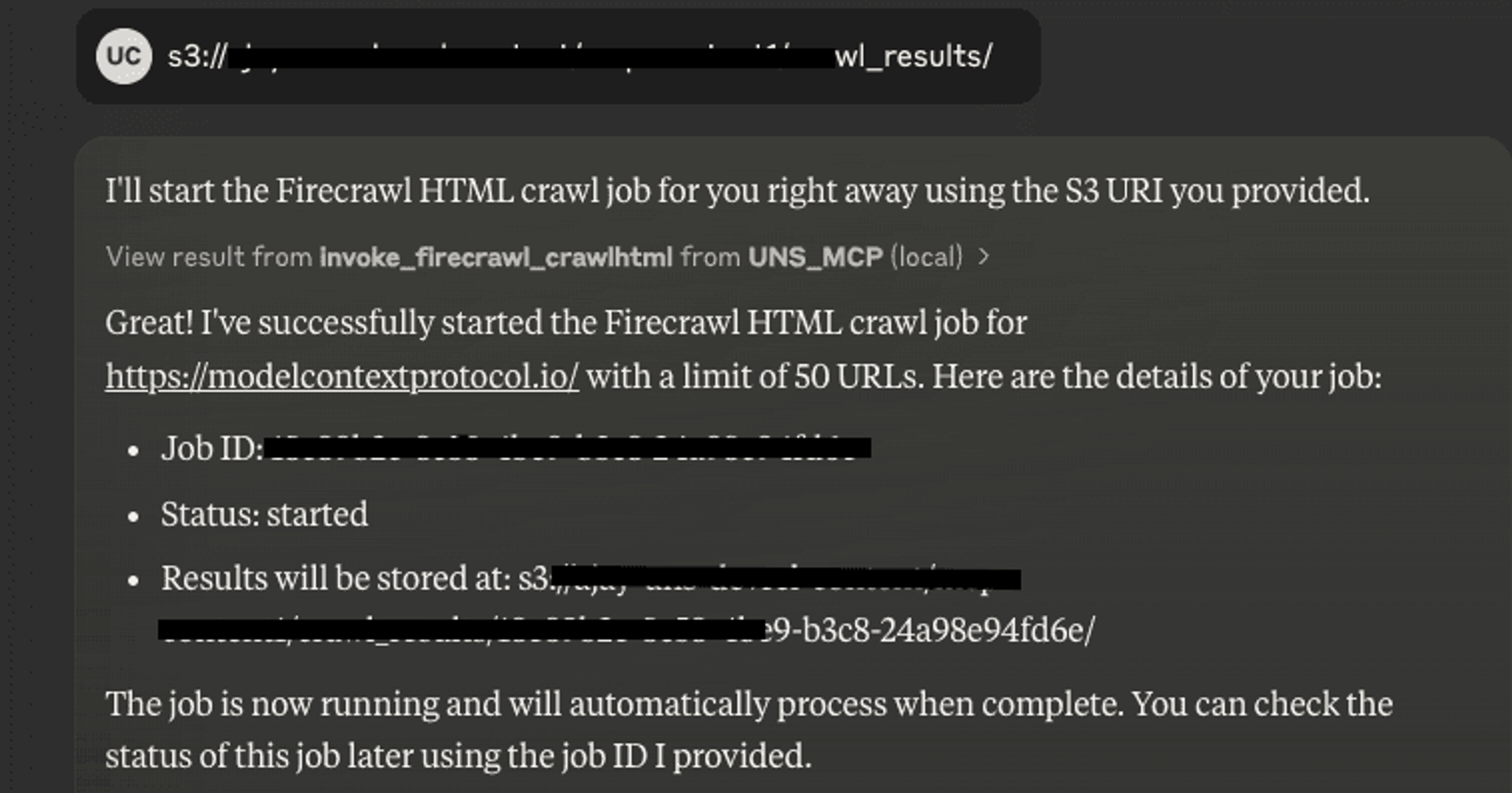
Step 2: Crawl a Website with Firecrawl
Simply ask Claude in English to start crawling your website, for example, https://modelcontextprotocol.io/. Firecrawl handles everything automatically. Here, even though we requested 50 URLs, it smartly fetched 23 pages that actually existed.

Based on the docstrings provided for that particular function you may be prompted to provide values for other parameters.
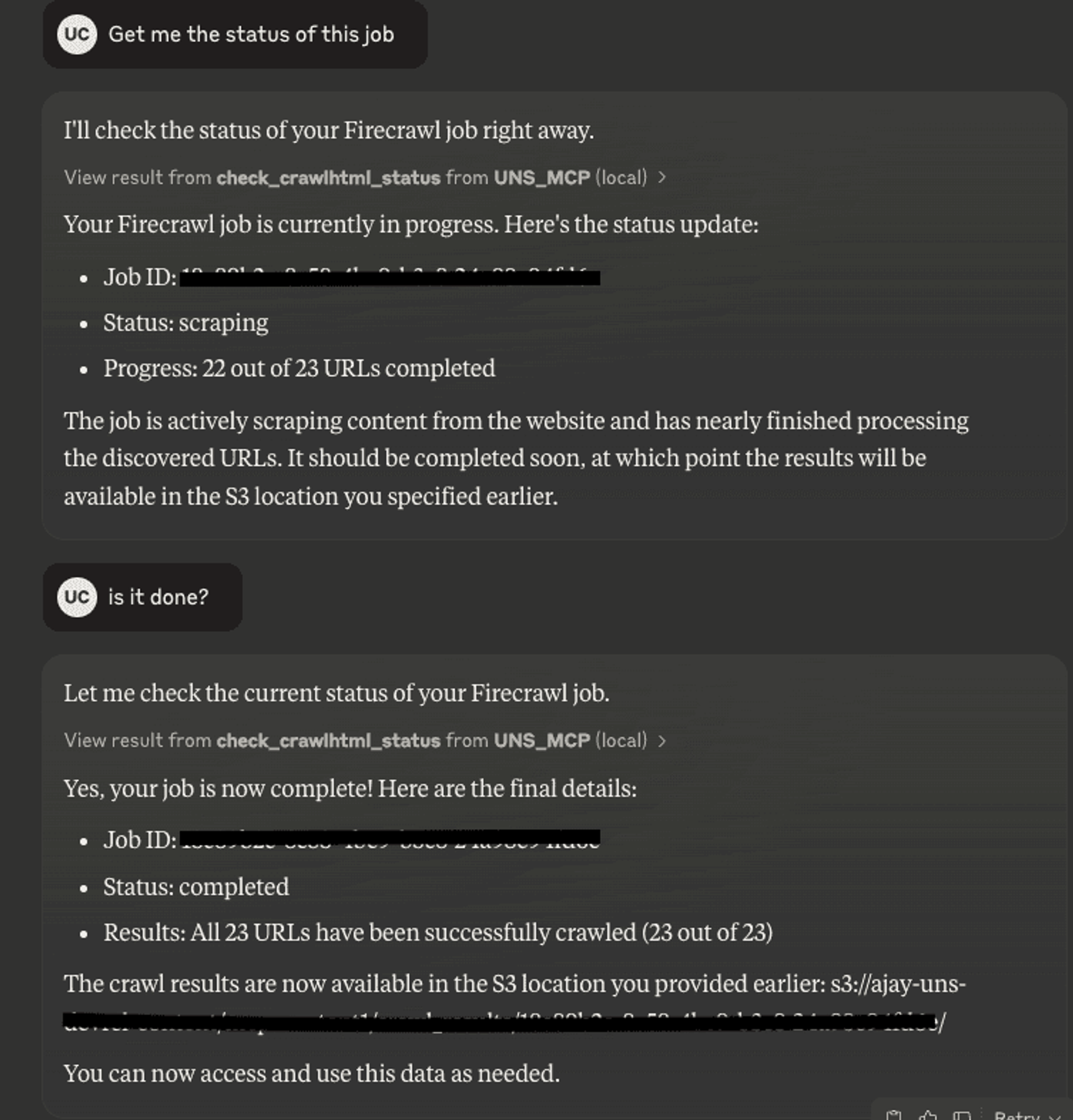
Since the context is maintained, it is very easy for Claude to pick up the right id and query and check for more information, as shown here when I wanted to check the status of my crawl job.
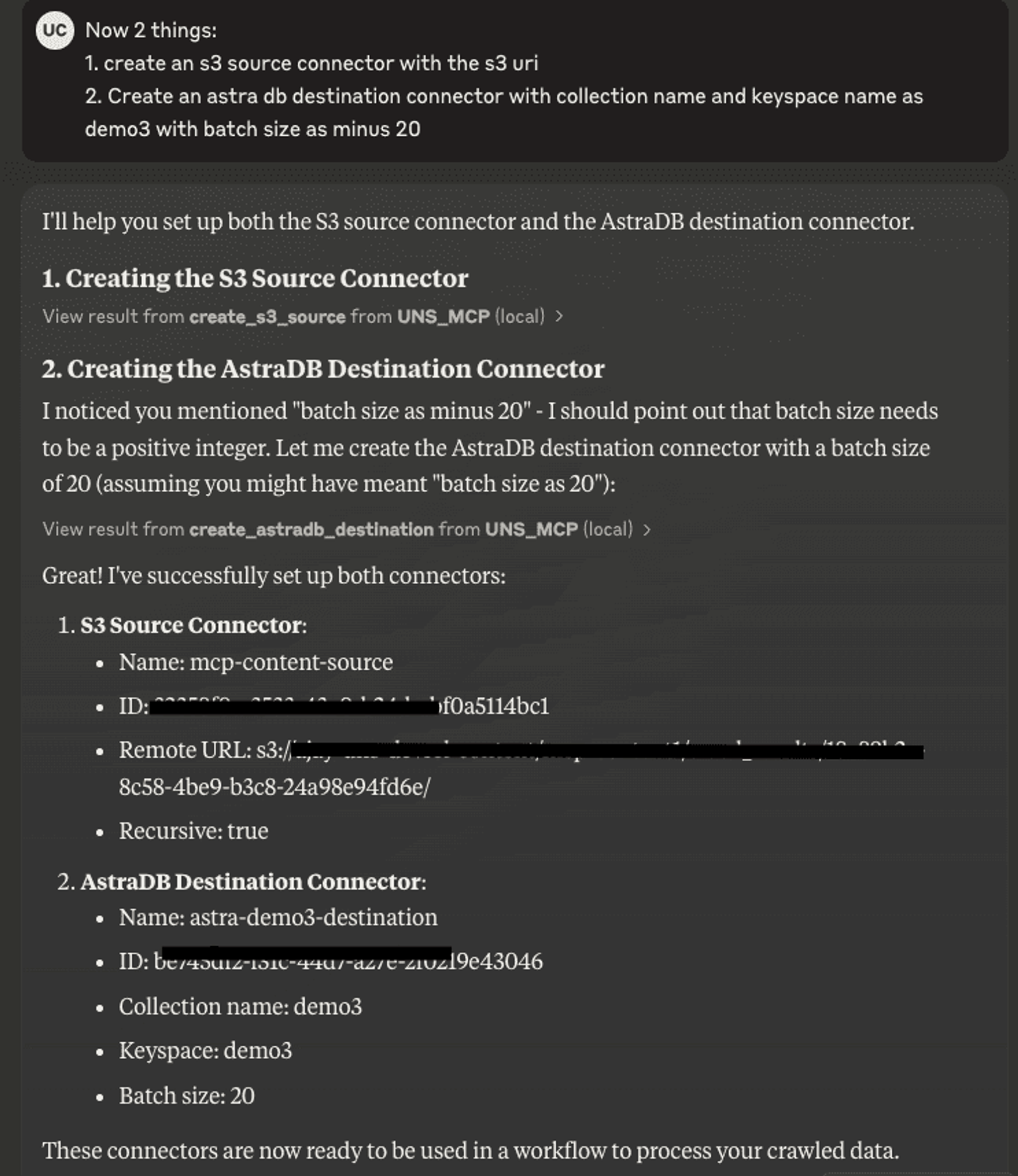
Step 3: Set up Data Connectors for Data Processing
Now we can move on to the next step: using Unstructured API capabilities via MCP. Most other MCP servers tend to connect and access individual data sources. Unstructured, on the other hand, has multiple source and destination connectors built in. The Unstructured MCP server is rapidly catching up with all the source/destination connectors that Unstructured Platform supports - learn more about supported sources here, and destinations - here.
For this demo, let's create a source connector with the S3 bucket, where we've stored our crawled data, and a destination connector for Astra DB to leverage its vector search capabilities.
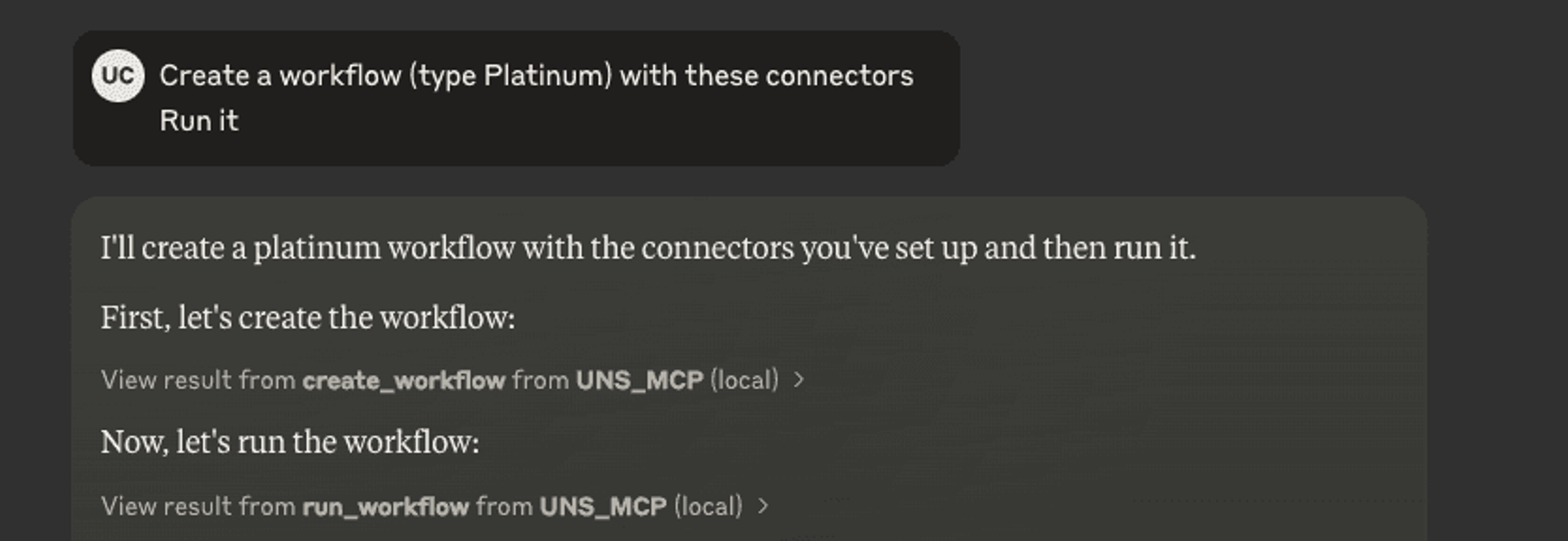
Step 4: Create and Run a Data Processing Workflow
Prompt Claude to create and run a workflow for you with Unstructured and it will handle it.
See how after I set up the source and destination connectors, Claude suggested using them for the workflow, which was exactly what I needed! There were also times when Claude didn't know the correct format for a workflow. When that happened, it searched for existing workflows and then created a working configuration from one all by itself.
Now that the workflow is running, you can login to the Unstructured Platform to see the most recent job for that workflow.
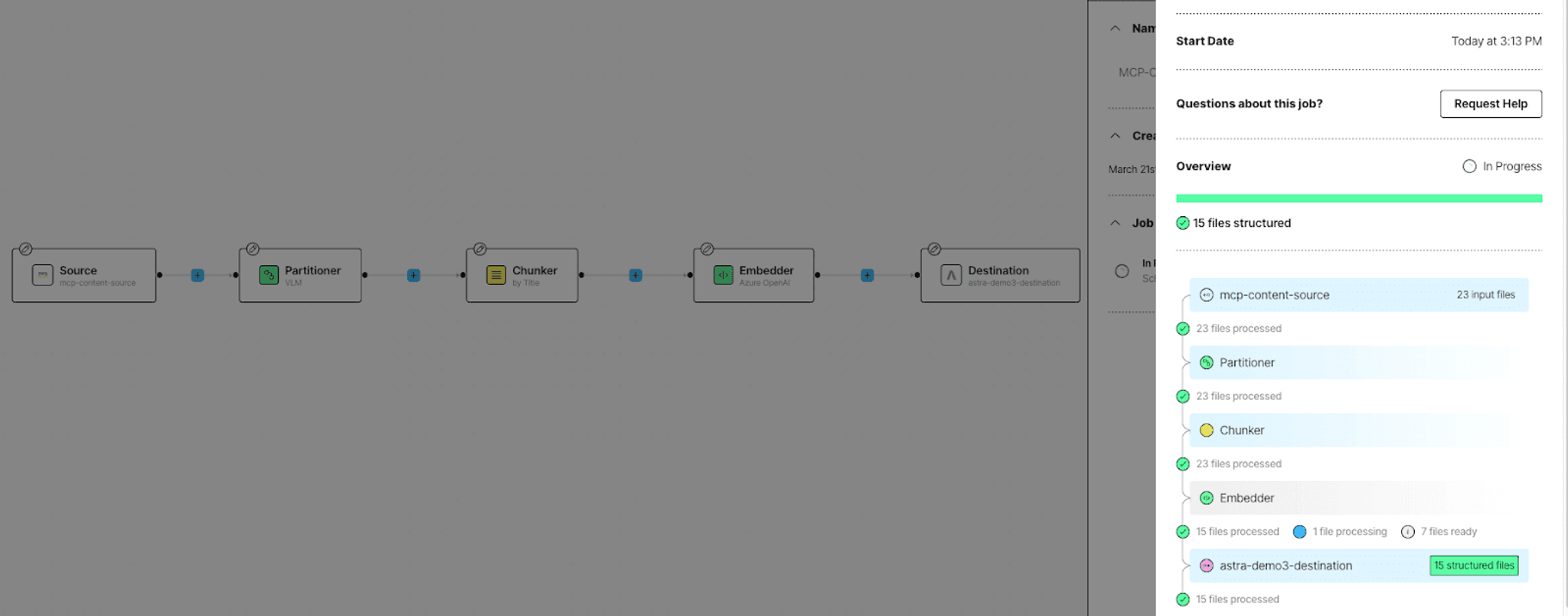
Or you can ask Claude to do this for you:
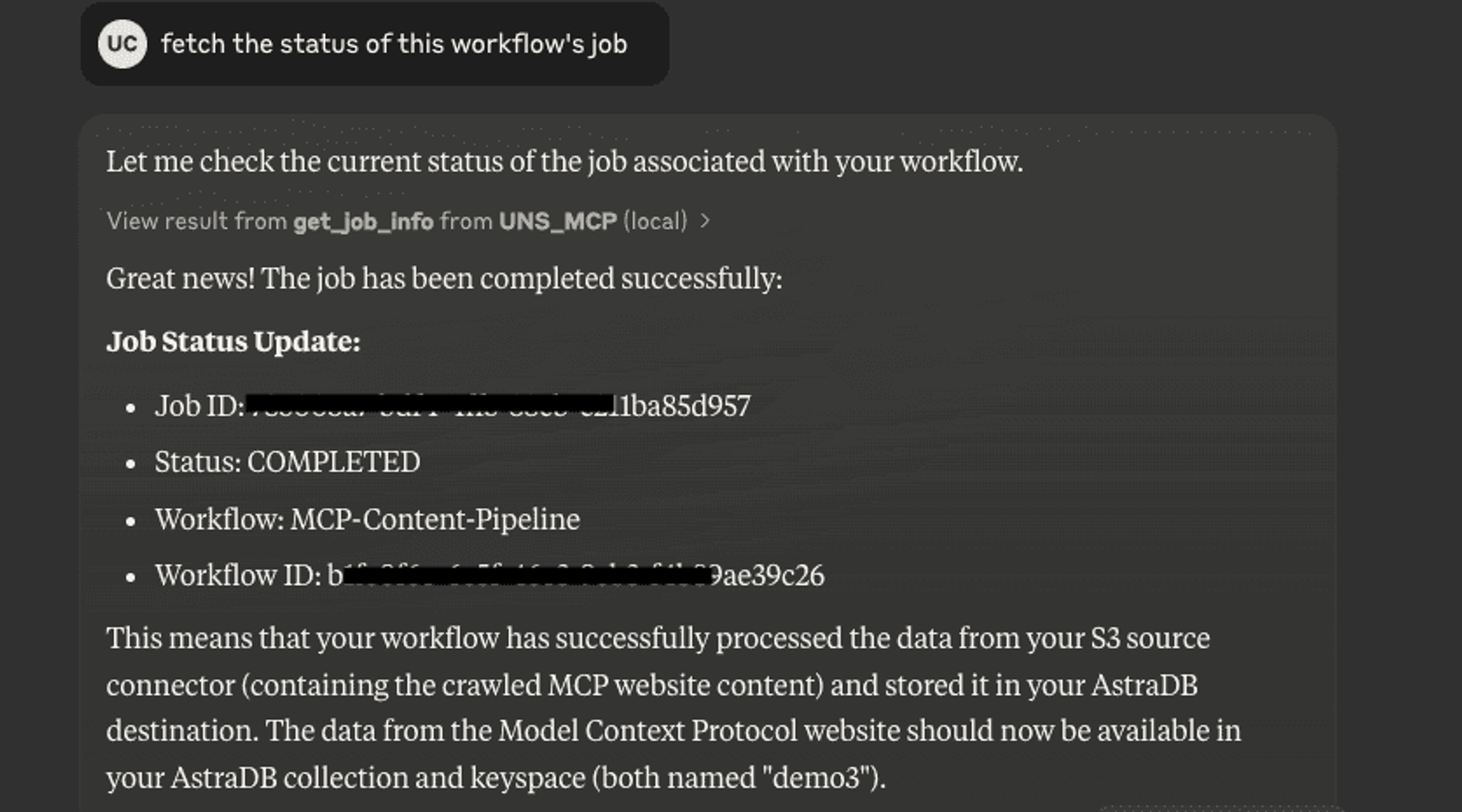
Step 5: RAG over Crawled and Processed Data
The data has been neatly ingested into the AstraDB with practically 0 coding effort and all through natural language text! Lets set up a simple RAG application to learn about MCP (remember, we crawled the MCP documentation 😉).
You can find the full example in this notebook, let’s walk through the snippets here.
Astrapy is our only dependency, we need it to access Astra DB.
Next, we set up the keys for Astra DB and OpenAI for the RAG application.
We need a function to connect to the DB and a function to fetch the embedding for a query.
Lets go ahead with a simple retriever here, which takes the user query, embeds it and calculates cosine similarity to retrieve top 5 documents by default.
Our workflow essentially receives a user query, fetches similar documents from AstraDB, uses the documents as context to answer the user’s question.
Now that we’ve set up a basic RAG, let’s start asking it questions.
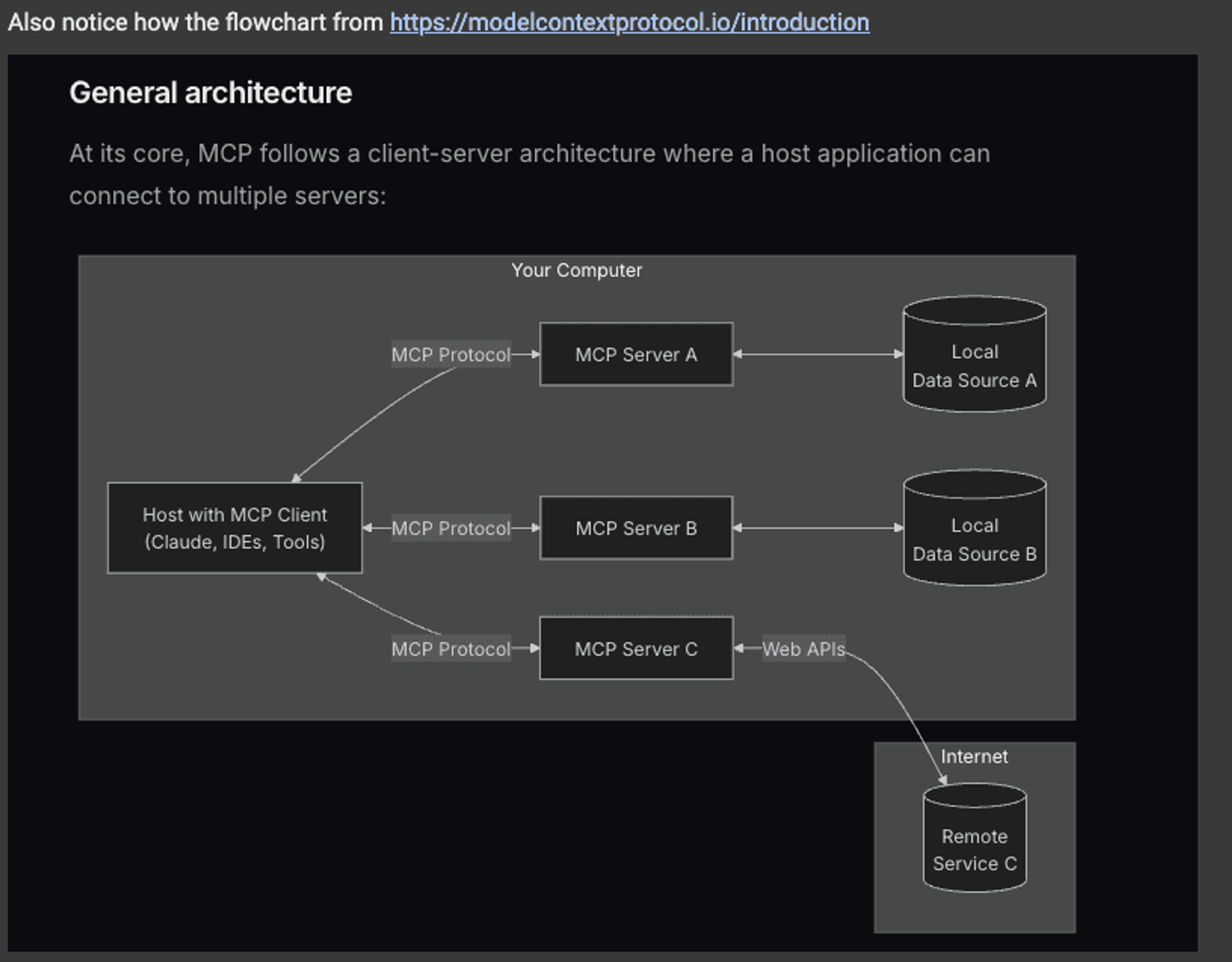
Notice how Unstructured data transformation workflow made sure that image content was also indexed by converting the graph into natural language that could be easily chunked and embedded.
Conclusion
MCP is a new, simple, and useful protocol that streamlines data workflows without unnecessary complexity.
If you followed this blog post end to end, congrats! You've learned the basics of how MCP works, used an MCP server and applied it for document ingestion following it up with RAG!
Ready to learn more? Check out the Unstructured MCP server and start building powerful document processing workflows today!


