
Authors

Your RAG system works. It retrieves the right documents, chunks them properly, and generates accurate answers. But here's the problem: it treats every user the same.
Ask it to explain a complex concept, and it gives you the same technical explanation whether you're an expert or a beginner. Query it again the next day about a related topic, and it's forgotten your knowledge level and preferences.
RAG systems are great at retrieval but they can be terrible at personalization.
The issue isn't with the documents or the vector search, it's that RAG has no memory of who's asking. Every query starts from scratch. Users have to re-establish their preferences every single time.
What if your RAG system could remember not just the documents it processes, but the users it serves. What if it could adapt its responses based on what it's learned about each user over time?
That's what we're building today: a RAG system with memory, and along the way, we'll explore the concept of agentic memory that's been gaining traction in the AI community.
We'll take Unstructured's document processing capabilities and layer in Mem0's intelligent memory system. The result? A RAG application that doesn't just retrieve information, it personalizes how that information gets delivered to each user.
By the end of this walkthrough, you'll have a system that remembers user preferences, adapts explanations to individual knowledge levels, and improves with every interaction all without users having to repeat themselves.
Let's build it.
What You'll Build
Here's the scenario: you have research papers stored in S3, and you want to build an AI assistant that can answer questions about them. But not just any assistant, you’re building one that adapts to each user's knowledge level and communication preferences.
The system has two layers:
The RAG foundation handles document processing and retrieval. Unstructured connects to your S3 bucket, processes the PDFs (extracting text, summarizing tables and images, chunking content, generating embeddings), and lands everything in Weaviate for semantic search.
The memory layer sits on top. Mem0 captures user preferences from conversations (preferred format, knowledge level, learning style) and uses them to personalize responses. When a user asks a question, the system retrieves relevant chunks from Weaviate and generates an answer tailored to what it knows about that specific user.
We'll build this using Unstructured's API to create a processing workflow and Mem0's platform to manage user memory. The code lives in a Colab notebook, but the document processing runs through Unstructured's infrastructure.
You'll see the difference immediately. Ask a question without memory, and you get a generic response. Ask the same question after the system has learned your preferences, and you get an answer formatted how you like it, explained at your level, bridging from concepts you already know.
Prerequisites
Setting Up Unstructured
Before we can process documents, we need to authenticate with Unstructured's API.
If you don't already have an account, sign up for free here. Once you're in, navigate to the API Keys section in the platform to generate your key.
Setting Up Mem0
We'll need a Mem0 account to add the memory layer to our RAG system.
Create a Mem0 account here. Once you're logged in, open the dashboard and navigate to API Keys. Generate a new key and save it - you'll need it when we build the RAG query system later.
Setting Up the S3 Source Connector
Source connectors tell Unstructured where your documents live. For this demo, we're using AWS S3 to store research papers.
You'll need three things from AWS:
- AWS Access Key ID
- AWS Secret Access Key
- S3 Remote URL (the path to your bucket, formatted as
s3://your-bucket-name/folder-path/)
These credentials allow Unstructured to securely access and read files from your S3 bucket. When you create the source connector, you'll specify whether to include subfolders (recursive option) and which specific path to pull from.
Setting Up the Weaviate Destination Connector
Destination connectors tell Unstructured where to send your processed data. We're using Weaviate, a vector database that will store our chunked documents and their embeddings for semantic search.
You'll need a Weaviate Cloud account with a database cluster. If you don't have one yet, create a WCD account here and set up a cluster.
From your Weaviate cluster, grab three things:
- Cluster URL: The host URL for your database instance
- API Key: The authentication key for accessing your cluster
- Collection Name: The name of the collection where data will be stored
Before you create the destination connector in Unstructured, you need to set up your Weaviate collection with a minimum schema. Weaviate requires at least a record_id property before it can accept data.
In the Weaviate UI, add this schema to your collection:

Weaviate will automatically generate additional properties based on the incoming data from Unstructured.
If you need help with the setup process, this video walkthrough covers the steps.
Building the Workflow
Now that we have our source and destination configured, we need to define how the documents get processed. This is where Unstructured's workflow system comes in.
A workflow is a pipeline of processing nodes. Each node performs a specific transformation on your documents, and data flows through them sequentially. For our memory-enabled RAG system, we need to transform raw PDFs into structured, enriched, embedded chunks that can be semantically searched and personalized.
Here's what our pipeline does:
Partitioner extracts structured content from PDFs, identifying text blocks, tables, and images. We use the hi_res strategy because we're dealing with research papers that often contain embedded images, complex tables, and figures. Hi-res uses object detection models combined with OCR to understand document layout and accurately classify different elements.
Image Summarizer generates descriptions for any figures or diagrams in the papers using vision models. Instead of losing visual information, we convert charts and diagrams into text descriptions that become part of the searchable content.
Table Summarizer creates natural language summaries of data tables. Research papers are full of experimental results and metrics in table form. These summaries make that structured data queryable in natural language.
Chunker breaks documents into semantically meaningful pieces using the chunk_by_title strategy. This keeps related content together based on document structure (sections under the same heading stay in the same chunk), which preserves context better than arbitrary character splits.
Embedder generates vector representations of each chunk using OpenAI's text-embedding-3-large model. These embeddings enable semantic search in Weaviate.
Once your workflow is configured, running it is straightforward through the API. Here's what happens under the hood:
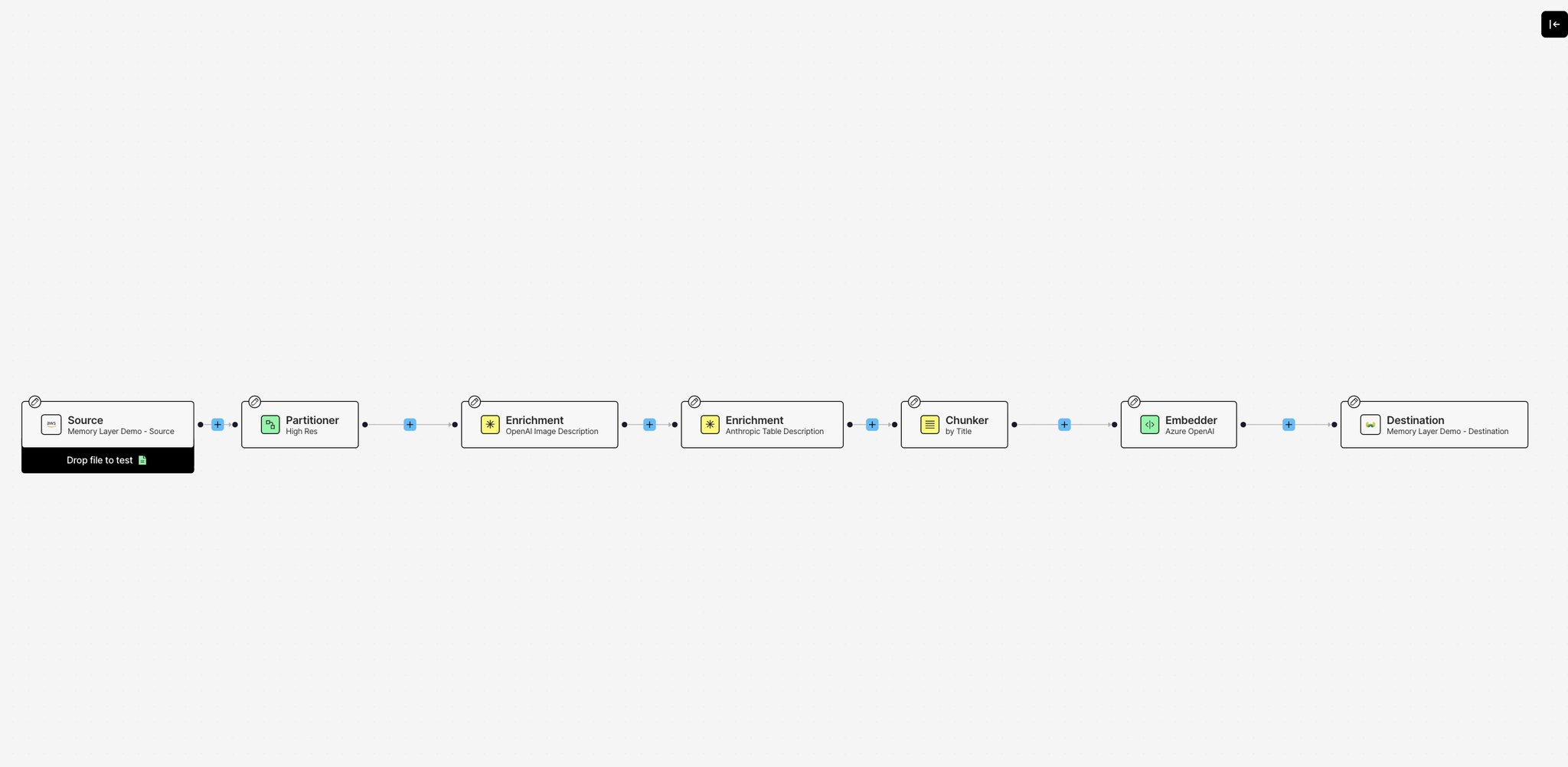
Unstructured connects to your S3 bucket and pulls every PDF from the specified path. Each file flows through your workflow nodes sequentially. The partitioner breaks down the document structure, enrichments add context to images and tables, the chunker splits content into meaningful pieces, and the embedder generates vectors. Finally, everything lands in your Weaviate collection, ready for semantic search.
Once complete, your vector database is populated with structured, enriched, embedded chunks from all your research papers.
The best part? Workflows can run on a schedule. Configure them to execute daily, weekly, or however often new documents hit your S3 bucket. As new research papers get added, the workflow automatically ingests them, processes them through the same pipeline, and keeps your vector store up to date. Your RAG system stays current without manual intervention 😉
Querying with Memory
Your documents are now successfully processed and sitting in Weaviate. Now comes the interesting part: building a query system that doesn't just retrieve information, but learns about each user and adapts to them.
This is where we add Mem0 to create a memory layer on top of our RAG system. You can follow along in the Colab notebook we've set up for this demo.
The architecture is straightforward. When a user asks a question, we:
- Generate an embedding for their query
- Search Weaviate for relevant document chunks
- Check Mem0 for what we know about this specific user
- Generate a response that's grounded in the documents but personalized to the user's preferences
Let's see how this works.
Understanding User Memory
Before we dive into the code, let's talk about what Mem0 actually does and why it matters.
LLMs are stateless. Every time you send a prompt to GPT-4 or Claude, the model has no memory of previous conversations unless you explicitly include that context in your prompt. This works for one-off questions, but it breaks down for personalized applications. Users end up repeating themselves constantly. "I prefer bullet points." "Explain it simply." "I'm a beginner in this topic." Every single conversation starts from zero.
RAG doesn't solve this either. RAG is great at retrieving relevant documents, but it retrieves the same documents for everyone. It has no concept of who's asking or how they prefer information delivered.
That's where user memory comes in.
Mem0 adds a memory layer that sits alongside your RAG system. It doesn't replace retrieval, it augments it with personalization. Here's how it works:
As users interact with your AI application, Mem0 automatically extracts and stores information about them. Not the full conversation history (that would be expensive and noisy), but the important bits. Things like:
- Preferences: "I prefer responses in markdown format"
- Knowledge level: "I only know about basic attention mechanisms"
- Learning style: "Explain new concepts by comparing them to things I already know"
- Context: "I'm working on a computer vision project"
This extracted memory persists across sessions. When the same user returns days later and asks a new question, Mem0 retrieves what it knows about them and uses that to shape the response. The AI doesn't just answer accurately, it answers in a way that matches how this specific user likes to learn and receive information.
The system gets smarter over time. Each interaction adds to what Mem0 knows about the user. Their preferences become more refined. The personalization becomes more accurate. It's a learning loop that happens automatically in the background.
Setting Up the Query System
The following Colab notebook sets up connections to Weaviate, OpenAI, and Mem0, then implements a single flexible query function that can operate with or without memory.
Here's how query_papers() works:
def query_papers(question: str, use_memory: bool = False):
# Retrieve from Weaviate
query_vector = get_embedding(question)
results = collection.query.near_vector(
near_vector=query_vector,
limit=TOP_K
)
retrieved_docs = []
for item in results.objects:
retrieved_docs.append({
'content': item.properties.get('text', ''),
})
context = "\n\n".join(f"{d['content']}" for d in retrieved_docs)First, it embeds the question and searches Weaviate for the most semantically similar chunks. Standard vector search retrieval.
The interesting part is what happens next:
if use_memory:
filters = {"OR": [{"user_id": USER_ID}]}
memory_response = memory.search(query=question, filters=filters, version="v2")
memories = memory_response.get('results', [])
if len(memories) > 0:
memories_text = "\n".join([f"- {m.get('memory', '')}" for m in memories])
system_prompt = f"""You are a helpful AI assistant. Answer based on the context and user preferences.
User Preferences:
{memories_text}
"""When use_memory=True, the function queries Mem0 for stored information about this user. If memories exist, they get injected into the system prompt alongside the retrieved document context. The LLM now has two sources of information: what's in the documents (from Weaviate) and what it knows about this specific user (from Mem0).
After generating the response, there's one more critical step:
if use_memory:
memory.add(
messages=[
{
"role": "system",
"content": "Extract and store ONLY: response output format preferences (which formatting the model response should be in), knowledge baseline (what user knows), and learning style.
Do NOT store anything from the questions user asks, store ONLY from preferences user EXPLICITLY states."
},
{"role": "user", "content": question},
],
user_id=USER_ID,
metadata={"category": "preferences"}
)The conversation gets sent back to Mem0 with specific instructions about what to extract and store. Mem0 uses its own LLM to parse the conversation and pull out the relevant preferences. This is how the memory layer learns and updates over time.
The function is invoked simply:
response = query_papers(question, use_memory=False) # Vanilla RAG
response = query_papers(question, use_memory=True) # RAG with memoryLet's see what the difference looks like in practice.
Seeing Memory in Action
Let's run three queries to see how memory changes the interaction.
Query 1: Baseline without memory
q1 = "What are the key innovations in the Attention Is All You Need paper?"
response_q1 = query_papers(q1, use_memory=False)The response is accurate and well-structured, covering the Transformer architecture, self-attention, multi-head attention, positional encoding, and parallelization benefits. But it's generic. This is what every user gets, regardless of their background or preferences.
Query 2: Establishing preferences
Now a user asks a question but includes their preferences:
preference_question = """Give me response in markdown format. Explain concepts like I only know
about the attention mechanism and nothing else, but I'm willing to learn as long as there
are comparisons and bridges to more complex topics from what I know already.
Now answer: How does sparse attention work compared to standard attention?"""
response_q2 = query_papers(preference_question, use_memory=True)The response completely changes. It's formatted in markdown with clear headers and bullet points. More importantly, the explanation starts by anchoring to what the user knows (standard attention), then builds from there. It uses phrases like "let's bridge from what you know" and draws explicit comparisons.
Here's what Mem0 extracted and stored from that interaction:
- User prefers markdown format
- User knows only about attention mechanism
- User is willing to learn with comparisons and bridges to more complex topics
Query 3: Automatic personalization
If the same user asks a completely different question:
q3 = "What is Flash Attention and how does it improve upon previous mechanisms?"
response_q3 = query_papers(q3, use_memory=True)Without the user mentioning their preferences again, the response automatically comes back in markdown format, starts by connecting to basic attention concepts they already know, and uses comparisons to explain the improvements. The system remembered. Here’s a portion of the response:
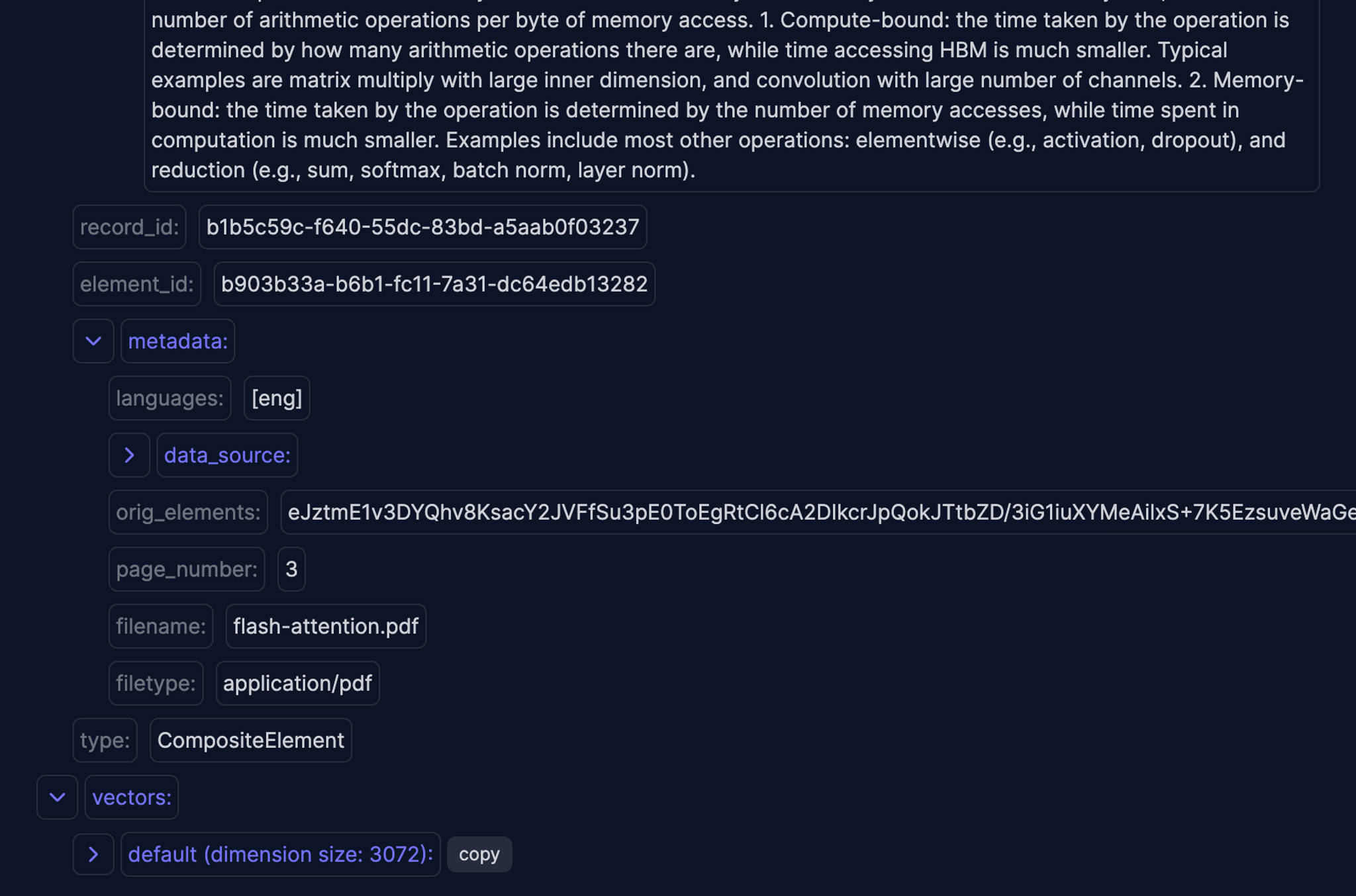
FlashAttention is an advanced attention mechanism designed to optimize the performance of Transformers, particularly when dealing with long sequences. It addresses the limitations of traditional attention mechanisms by focusing on reducing memory accesses, which are a significant bottleneck in computational speed on GPUs. Here's how FlashAttention improves upon previous attention mechanisms:
1. **Memory Access Optimization**: Traditional attention mechanisms require a large number of memory reads and writes, which can slow down processing. FlashAttention reduces these memory accesses by restructuring the computation process. It splits the input into blocks and processes them incrementally, a technique known as tiling. This approach minimizes the need to store and repeatedly access large intermediate data, such as the attention matrix.
2. **Efficient Use of GPU Memory**: By reducing memory accesses, FlashAttention also lowers the overall memory footprint. It avoids storing large intermediate matrices and instead uses techniques like storing softmax normalization factors to quickly recompute necessary data on-chip during the backward pass. This is more efficient than reading from high-bandwidth memory (HBM).
The user didn't have to say "explain it like I'm a beginner" or "use markdown" again. Mem0 retrieved those preferences, injected them into the system prompt, and the LLM adapted accordingly.
That's the difference. Standard RAG retrieves the same information for everyone. Memory-enabled RAG retrieves the same information but personalizes how it's delivered based on what the system has learned about each individual user.
Memory Over Time
The system gets smarter with every interaction. If they ask questions that reveal deeper knowledge, Mem0 adjusts their knowledge baseline. The personalization becomes more accurate as the memory layer learns.
You can check what Mem0 has learned about a user:
memories = memory.search(query="all preferences", filters={"user_id": USER_ID}, version="v2")For our demo user, Mem0 stored:
- User prefers markdown format
- User knows only about attention mechanism
- User is willing to learn with comparisons and bridges to more complex topics
Extending This Pattern
This demo uses research papers and explanation preferences, but the pattern applies anywhere you need personalization:
Educational platforms where the AI tutor remembers each student's learning pace, struggling concepts, and preferred explanation styles. It doesn't just retrieve lesson content, it adapts how that content is presented to each learner.
Code assistants that remember your tech stack, coding style preferences, and experience level. Ask about implementing authentication, and it suggests solutions in your preferred framework with your typical patterns.
The base architecture stays the same: documents in a vector store for retrieval, Mem0 for user context, and an LLM that synthesizes responses with the documents and memory. You just change what memories you extract and how you use them in your system prompts.
You can also extend the memory schema. Instead of just preferences, store user goals, project context, historical decisions, or domain expertise. The more relevant context Mem0 maintains, the more intelligently your system can adapt.
Wrapping Up
You've built a RAG system that does more than retrieve information. It learns about users and adapts to them.
We started with Unstructured's document processing pipeline, pulling research papers from S3, extracting structure from complex PDFs with hi-res partitioning, enriching images and tables with AI-generated descriptions, chunking content semantically, and landing everything in Weaviate with embeddings. That gave us the retrieval foundation.
Then we added Mem0 as a memory layer on top. Now the system doesn't just know what's in the documents, it knows who's asking. It remembers preferences, knowledge levels, and learning styles. It adapts responses automatically without users repeating themselves.
The result is AI that feels more intelligent because it's personalized. Users get answers formatted how they like them, explained at their level, bridging from concepts they already understand. And it gets better over time as the memory layer learns.
This pattern works beyond research papers. Anywhere you're building AI that interacts with users repeatedly, memory turns generic responses into personalized experiences. Education, coding assistants, internal tools to name a few. The architecture is the same: retrieval plus memory.
Ready to build your own memory-enabled RAG system?
Try out the full implementation in our Colab notebook. You can swap in your own documents, customize what memories to extract, and see how personalization changes your AI's responses.
If you're working with enterprise data at scale, sign up for U
nstructured to access the full platform with workflow scheduling, multiple source connectors, and production-grade processing.


