Authors

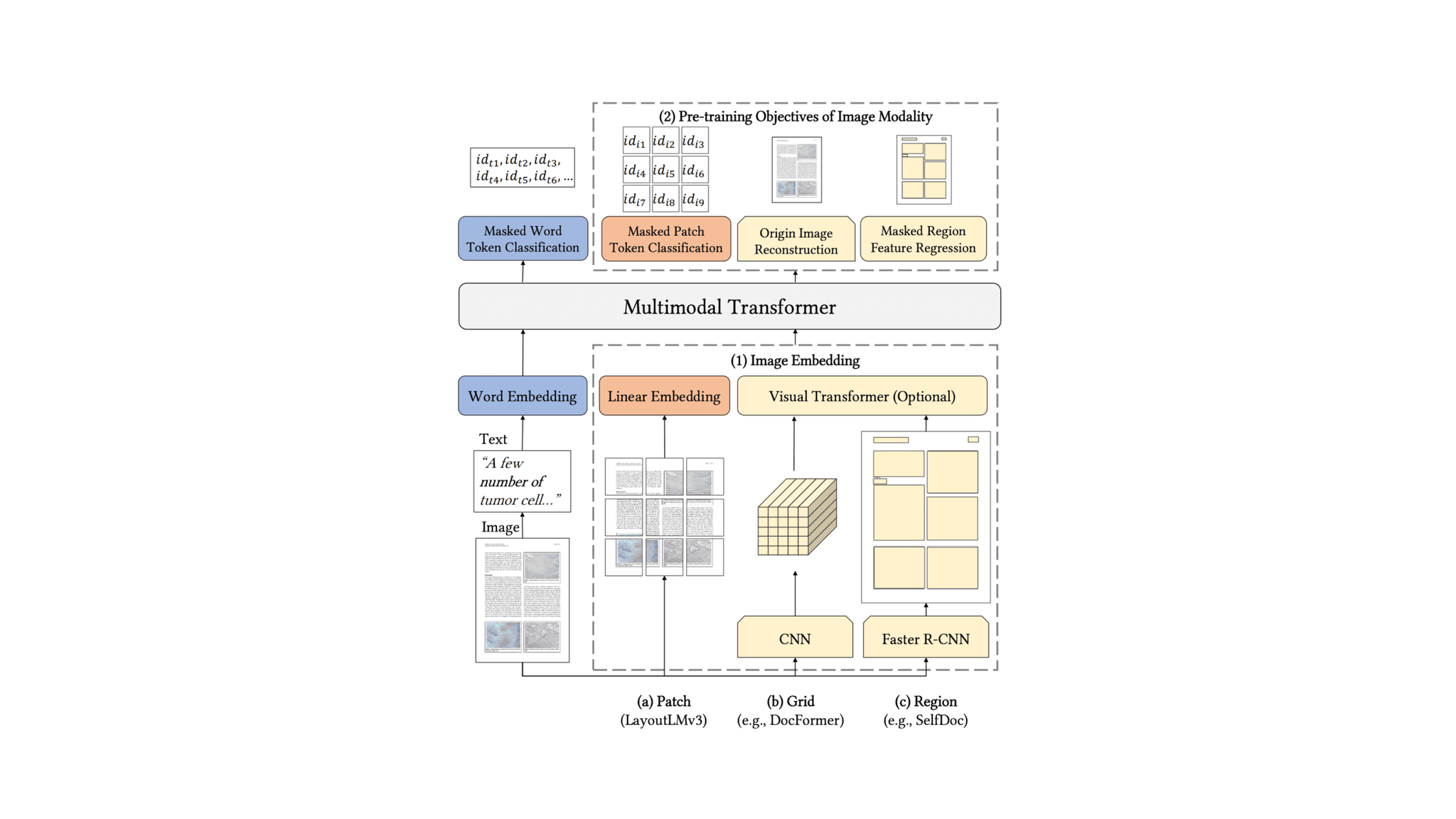
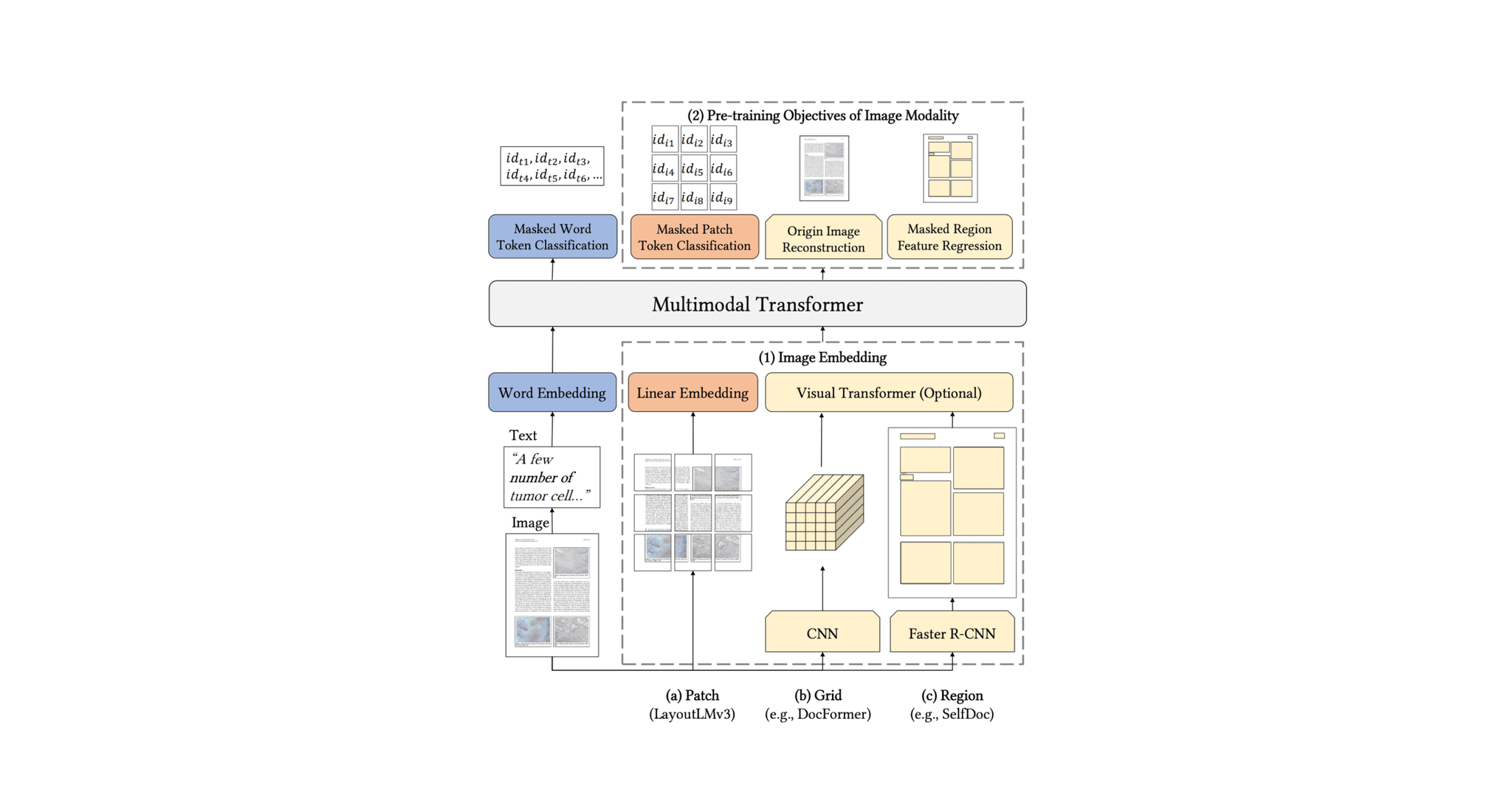
Document understanding algorithms analyze the content of documents with an encoder-decoder pipeline that combines computer vision (CV) and natural language processing (NLP) methods. The CV part of the pipeline analyzes the document as an input image to produce a representation that a transformer can process, similar to how an NLP model processes tokens. In the figure below, the CV model generates an image embedding that is fed into a multimodal transformer.
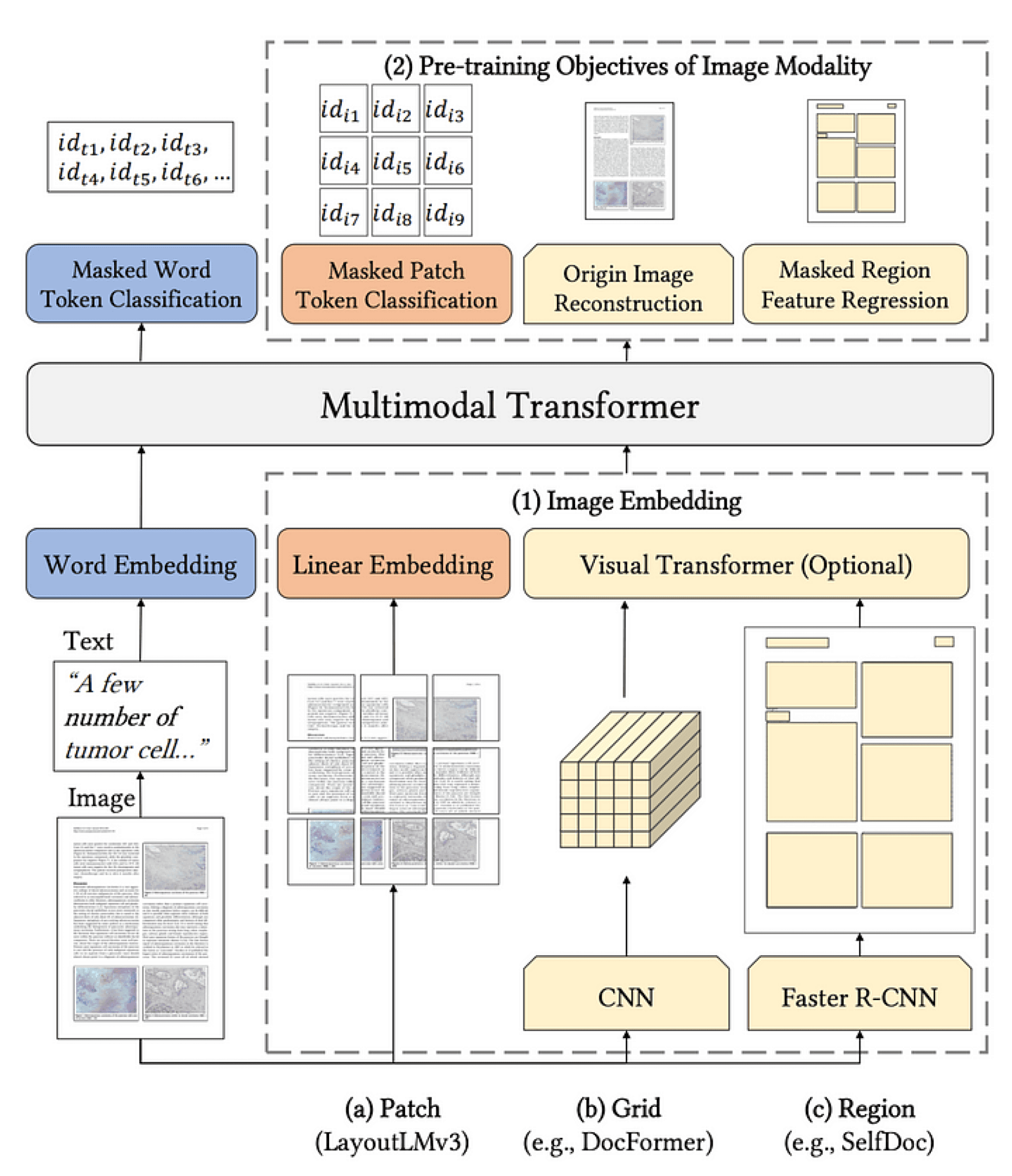
Figure 1. Diagram LayoutLMv3 [1] pre-training, which includes similar approaches.
Traditionally, convolutional neural networks (CNNs) such as ResNet have dominated the CV field. Recently, however, vision transformers (ViTs) similar to NLP architectures such as BERT have gained traction as an alternative approach to CNNs. ViTs first split an input image into several patches, convert the patches into a sequence of linear embeddings, and then feed the embeddings into a transformer encoder. This process is depicted in Figure 2. The linear embeddings play a role similar to tokens in NLP. As with NLP models, the output of the transformer can be used for tasks such as image classification.
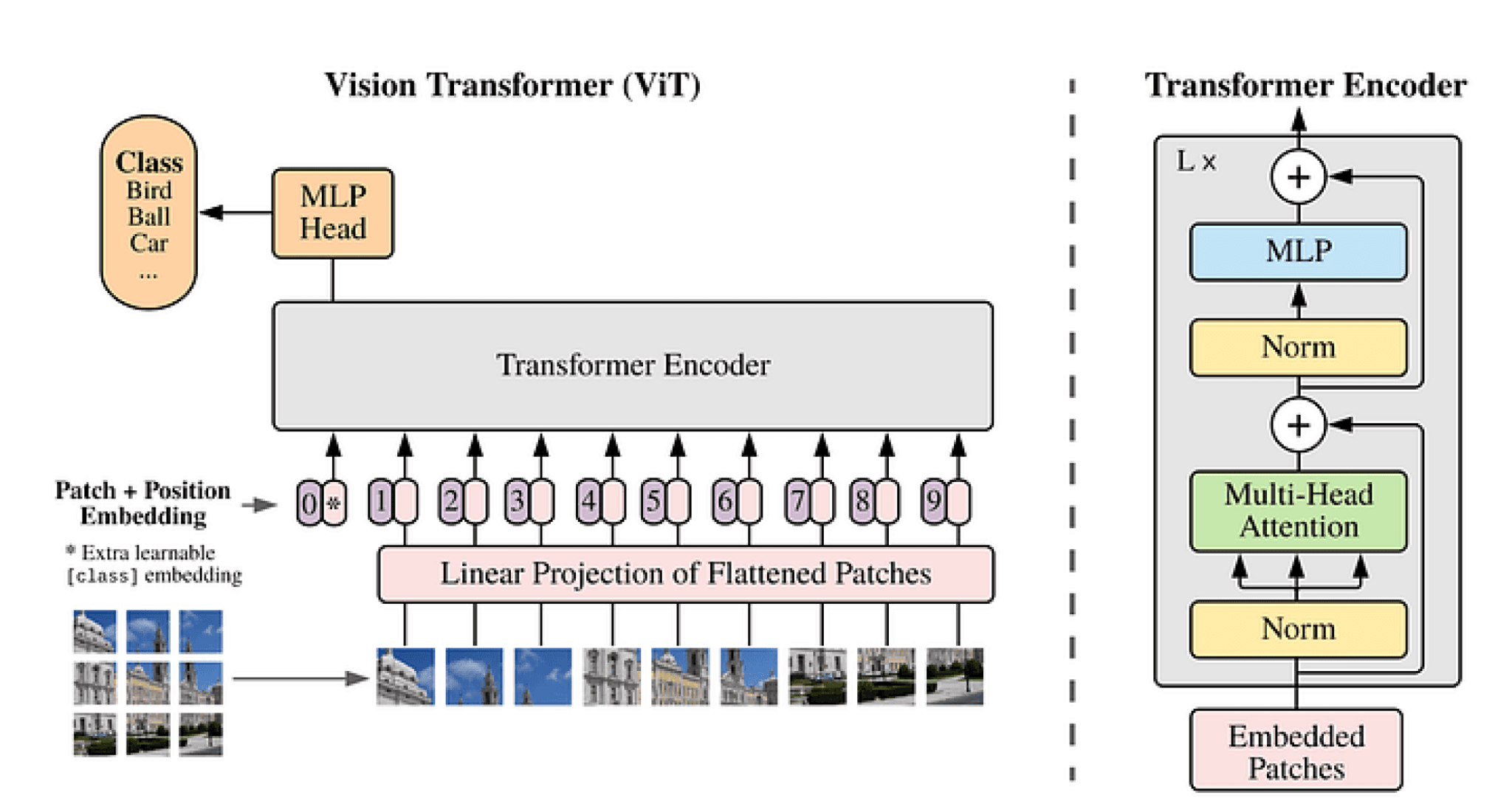
Figure 2. Vision Transformer example architecture [2]
ViTs have several advantages over CNNs. ViTs can grasp global relations and appear more resilient to adversarial attacks. A disadvantage is that more examples are needed for training ViTs because CNNs have inductive biases that allow training them with fewer examples. However, we can mitigate this issue by pre-training vision transformers with large image data sets. ViTs are also compute intensive — the amount of compute required to run transformers grows quadratically with the number of tokens. Vision Transformers are now available as part of HuggingFace Vision Encode Decoder models, as shown in the snippet below.
from transformers import BertConfig, ViTConfig, VisionEncoderDecoderConfig, VisionEncoderDecoderModelconfig_encoder = ViTConfig()config_decoder = BertConfig()config = VisionEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)model = VisionEncoderDecoderModel(config=config)
Vision Encoder Decoders provide the foundation for many document understanding models. The Donut [3] model first processes an input image with an an image transformer and then feeds it to a decoder to generate a structured representation of the input document. In the example below, we provide the image of a receipt and output a structured JSON containing containing the line items of the receipt.
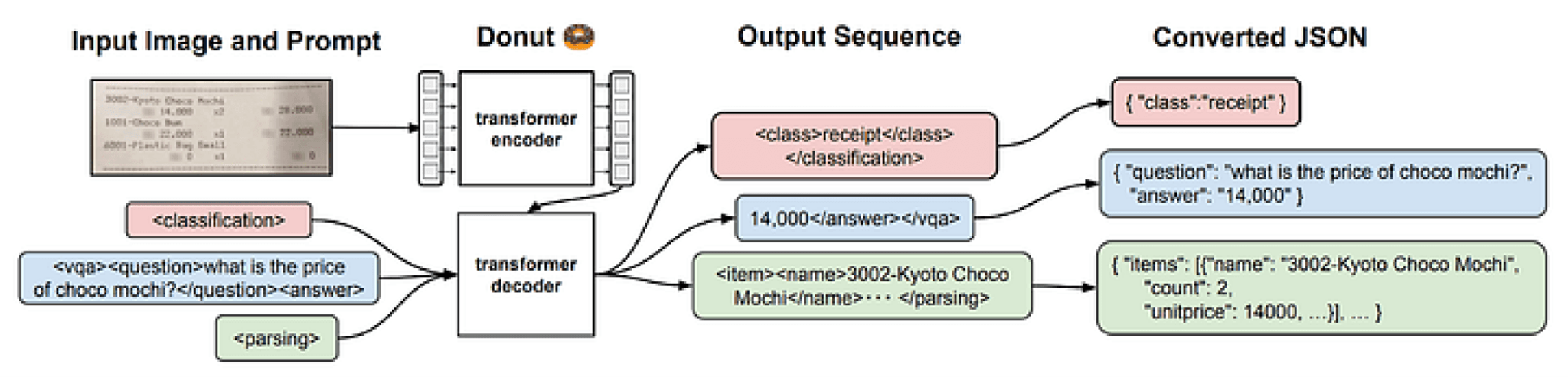
Figure 3: The Architecture for the Donut model
Whereas some document understanding models such as LayoutLMv3 [1] require preprocessing to identify bounding boxes and perform OCR, Donut converts the input image directly into the target JSON, as shown in the code below. A downside to this approach is that the output does not include the bounding box, and therefore does not provide any information about where in the document the extraction came from.
from donut.model import DonutModelfrom PIL import Imagemodel = DonutModel.from_pretrained("./custom-fine-tuned-model")prediction = model.inference( image=Image.open("./example-invoice.jpeg"), prompt="<s_dataset-donut-generated>")["predictions"][0]print(prediction)
{ "InvoiceId": "# 560578", "VendorName": "THE LIGHT OF DANCE ACADEMY", "VendorAddress": "680 Connecticut Avenue, Norwalk, CT, 6854, USA", "InvoiceDate": "4/11/2003", "AmountDue": "Balance Due:", "CustomerName": "Eco Financing", "customerAddress": "2900 Pepperrell Pkwy, Opelika, AL, 36801, USA", "items": [ { "Description": "FURminator deShedding Tool", "Quantity": "5", "UnitPrice": "$8.09", "Amount": "$40.46" }, { "Description": "Roux Lash & Brow Tint", "Quantity": "5", "UnitPrice": "$68.61", "Amount": "$343.03" }, { "Description": "Cranberry Tea by Alvita - 24 Bags", "Quantity": "1", "UnitPrice": "$42.30", "Amount": "$42.30" } ], "InvoiceTotal": "$425.79"}
The Unstructured team is currently working on pipelines that use Donut to extract structured information from receipts and invoices. Stayed tuned in the coming weeks as we prepare to release these models on GitHub and Huggingface. Follow us on LinkedIn and Medium to keep up with all of our latest work!


