Supercharge your Claude, Cursor, and Codex.
Unstructured Foundation is a single MCP that solves agentic search for enterprise data.
Foundation solves three problems every AI agent faces: it can't see what's inside your files, it can't fit your company's knowledge into a single context window, and it can't search every system where information lives. Foundation fixes all three, giving agents access to the right information at the right time.
- Boost answer accuracy: 14x Higher Retrieval Accuracy
- Get answers faster: 85% Fewer Agent Turns
- Scale without the spend: 10x Lower Costs
Sign up to get early access to Unstructured Foundation.
The next generation of enterprise AI will be built with Unstructured Foundation.
See it.
Claude sees file names. Foundation gives it X-ray vision to see inside them. More than 65 file types—including PDFs, presentations, spreadsheets, scans, audio, and video—are parsed into agent-ready context. And for the formats agents already read, Foundation reads them better: tables stay tables, layouts stay intact, and scanned documents become searchable text.
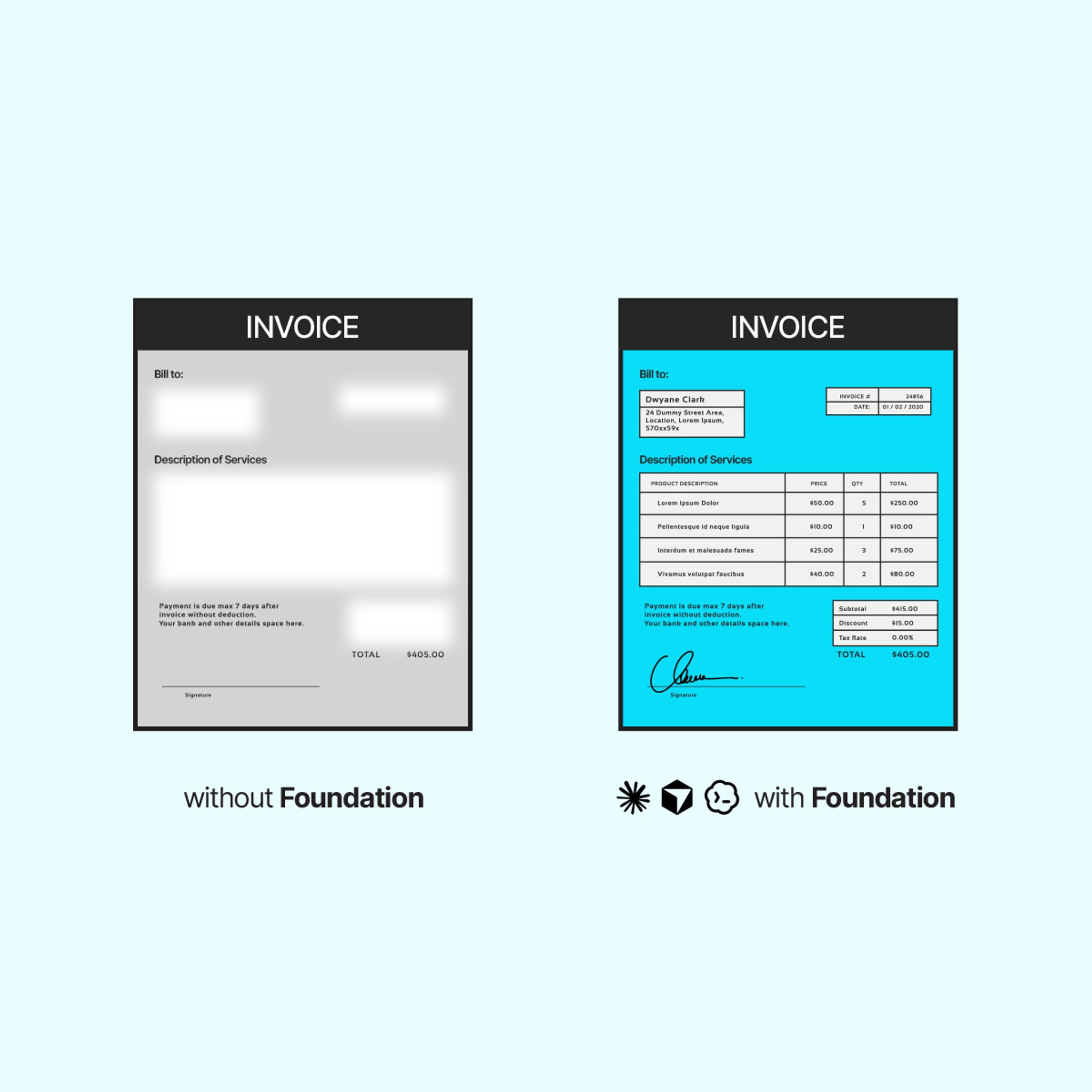
Find it.
A larger context window isn't the answer. The right context is. Foundation continuously indexes your organization's knowledge and delivers the exact spreadsheet, slide, clause, or document needed for the task at hand. Instead of flooding a model with information, it hands over only what matters. A spear, not a net. The result is better answers, fewer tokens, and stronger performance

Use it.
Agents aren't slow because they're thinking. They're slow because they're searching. Every extra turn spent digging through files, opening documents, and calling tools burns both time and tokens. Foundation delivers exactly what's needed up front, so agents spend less time hunting and more time working. The result is faster answers, lower costs, and performance that scales as usage grows.
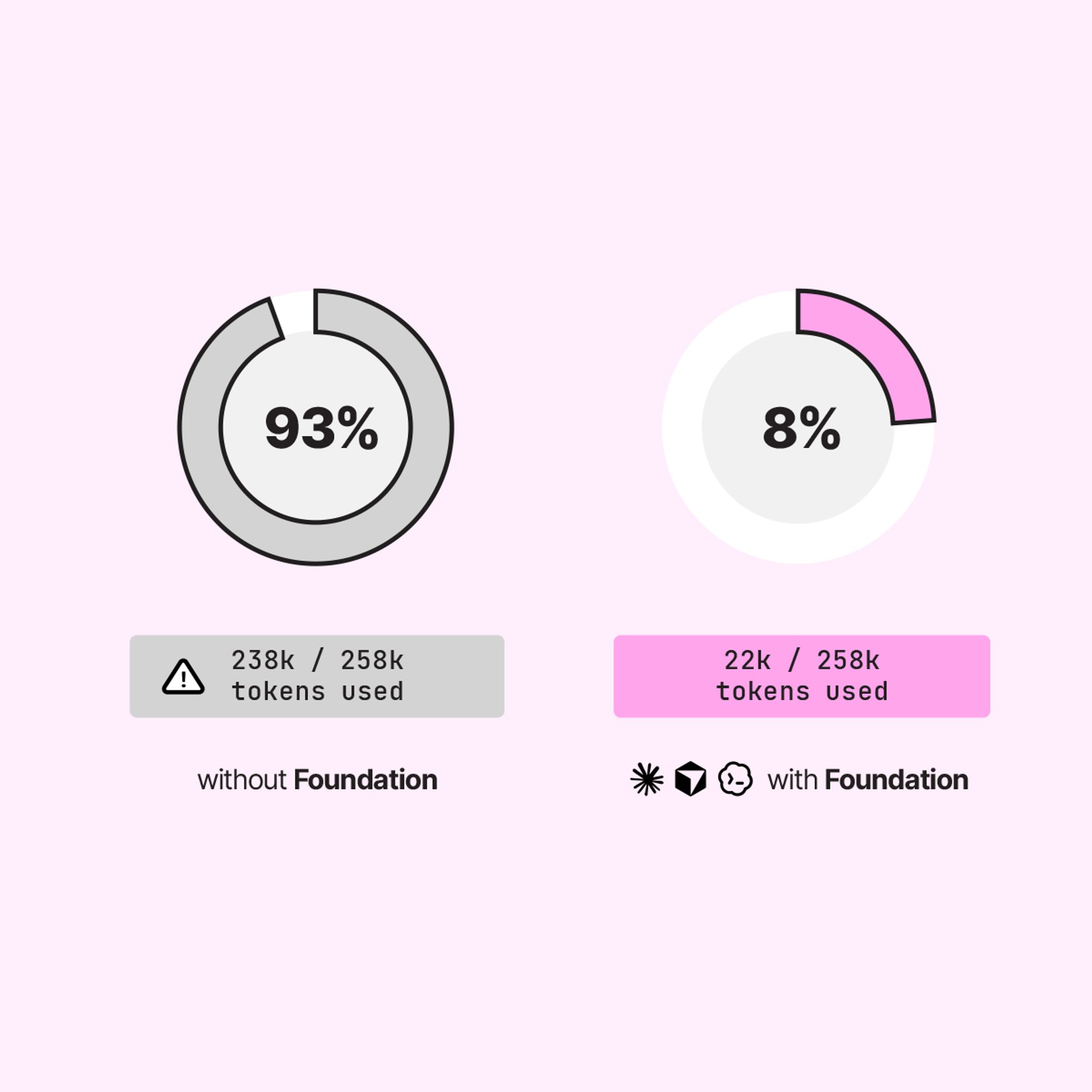
How It Works:
Compatibility:
Claude, Cursor, and Codex
What it connects to:
Astra DB, Azure AI Search, Azure Blob Storage, Box, Confluence, Couchbase, Databricks Volumes, Delta Tables in Amazon S3, Delta Tables in Databricks, Dropbox, Elasticsearch, Google Cloud Storage, Google Drive, IBM FileNet, IBM watsonx.data, Jira, Kafka, Milvus, MongoDB, MotherDuck, Neo4j, OneDrive, OpenSearch, Outlook, Pinecone, PostgreSQL, Qdrant, Redis, S3, Salesforce, SharePoint, Slack, Snowflake, Teradata, Teradata Vector Store, VAST, Weaviate, Zendesk, and more.
File types supported:
.3GP .AAC .ABW .AVI .BMP .CSV .CWK .DBF .DIF .DOC .DOCM .DOCX .DOT .DOTM .EML .EPUB .ET .ETH .FLAC .FLV .FODS .HEIC .HTM .HTML .HWP .JPEG .JPG .M4A .MCW .MD .MPG .MW .ODT .OGG .OPUS .ORG .P7S .PBD .PCM .PDF .PNG .POT .PPT .PPTM .PPTX .PRN .RST .RTF .SDP .SXG .TIFF .TSV .TXT .WAV .WEBM .WMV .XLS .XLSX .XML .ZABW .MOV .MP2 .MP3 .MP4 .MPEG .MPEGS