Using Onyx (formerly Danswer) with Unstructured for Production RAG Chat With Your Docs
Aug 22, 2024

Authors

Note: There is a newer integration with Onyx (fka Danswer) described in https://www.onyx.app/blog/danswer-unstructured and available at https://github.com/onyx-dot-app/onyx
This blog post can still help you integrate Unstructured's Serverless API into a repo of your choice
Introduction
RAG is increasingly moving from pilot to production, and there are a lot of tools out there to help with the deployment process. Danswer is an open source AI assistant for chatting with your enterprise documents. In this blog post, we talk about how we added an Unstructured integration to Danswer to process documents saved in your Google Drive via our Serverless API, and how this augmented the results from the original extraction implementation. In just 5 easy steps, you can integrate Unstructured into any production-ready system! All of the code is integrated in our fork, which expands the available file types for parsing by adding 13 additional file types!
Danswer is an AI Assistant that connects to your company’s docs, apps, and people. Danswer provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. The system also comes fully ready for production usage with user authentication, role management (admin/curators/basic users), chat persistence, and a UI for configuring AI Assistants and their Prompts. Check out our fork with the Unstructured pre-processing, and read below (or check out the PR) to see what we changed, and why we made these updates!You can also check out our video walk through: Integrating Unstructured with Danswer: A Step-by-Step Guide.
Codebase integration in 5 easy steps:
- Added two new functions to danswer/backend/danswer/file_processing/extract_file_text.py:
After importing Unstructured Client and other functions, we are setting up SDK partition requests, and the function read_any_file to read files via the Unstructured API. This theoretically enables parsing of any of the file types we support, but we have only set up a few in the Google Drive connector. We would also recommend using our Ingest pipeline for processing large files or multiple files, but used the SDK in this implementation as a proof of concept.
from unstructured_client import UnstructuredClient
from unstructured_client.models import operations, shared
from unstructured.staging.base import dict_to_elements
def _sdk_partition_request(file: IO[Any], file_name: str, **kwargs) -> operations.PartitionRequest:
logger.info(f"Creating partition request for file: {file_name}")
try:
request = operations.PartitionRequest(
partition_parameters=shared.PartitionParameters(
files=shared.Files(
content=file.read(), file_name=file_name
),
**kwargs,
),
)
logger.info(f"Partition request created successfully for file: {file_name}")
return request
except Exception as e:
logger.error(f"Error creating partition request for file {file_name}: {str(e)}")
raise
def read_any_file(file: IO[Any], file_name: str) -> str:
logger.info(f"Starting to read file: {file_name}")
try:
UNSTRUCTURED_API_KEY = os.getenv('UNSTRUCTURED_API_KEY')
if UNSTRUCTURED_API_KEY is None:
raise ValueError("UNSTRUCTURED_API_KEY is not set")
logger.info("Initializing UnstructuredClient")
client = UnstructuredClient(api_key_auth=UNSTRUCTURED_API_KEY)
logger.info("Creating partition request")
req = _sdk_partition_request(file, file_name, strategy="auto")
logger.info("Sending partition request to API")
response = client.general.partition(req) # type: ignore
logger.info("Converting response to elements")
elements = dict_to_elements(response.elements)
if response.status_code == 200:
logger.info(f"Successfully read file: {file_name}")
return "\n\n".join([str(el) for el in elements])
else:
logger.error(f"Received unexpected status code {response.status_code} from the API.")
raise ValueError(
f"Received unexpected status code {response.status_code} from the API.",
)
except Exception as e:
logger.exception(f"Failed to read file {file_name}: {str(e)}")
return ""We also added these additional PLAIN_TEXT_FILE_EXTENSIONS:
".rst",
".org",and additional VALID_FILE_EXTENSIONS:
".bmp",
".doc",
".heic",
".jpeg",
".png",
".msg",
".odt",
".p7s",
".ppt",
".rtf",
".tiff",
".xls",- Updated the Google drive connector at danswer/backend/danswer/connectors/google_drive/connector.py to use our new read_any_file function by changing the extract_text function. Note that this currently works for Unstructured's supported file types, but not Google Drive sheets/slides/docs – we will share an update shortly with those.
from danswer.file_processing.extract_file_text import read_any_file
def extract_text(file: dict[str, str], service: discovery.Resource) -> str:
mime_type = file["mimeType"]
if mime_type not in set(item.value for item in GDriveMimeType):
return UNSUPPORTED_FILE_TYPE_CONTENT
if mime_type == GDriveMimeType.DOC.value:
response = service.files().export(fileId=file["id"], mimeType="text/plain").execute()
elif mime_type == GDriveMimeType.SPREADSHEET.value:
response = service.files().export(fileId=file["id"], mimeType="text/csv").execute()
elif mime_type == GDriveMimeType.PPT.value:
response = service.files().export(fileId=file["id"], mimeType="text/plain").execute()
else:
response = service.files().get_media(fileId=file["id"]).execute()
return read_any_file(file=io.BytesIO(response), file_name=file['name'])- Update backend/requirements/default.txt as per the linked .txt – this took a bit of trial and error, and changing the required versions for some of Danswer’s requirements, but this is a stable configuration that builds.
- Update Dockerfile with additional dependencies for the Unstructured library:
- UNSTRUCTURED_API_KEY=${UNSTRUCTURED_API_KEY:-} As a background variable, and save the actual value of your Unstructured API key in a .env file in that same directory!
These are the main changes we made to integrate Unstructured! This is how little code it took to enable Unstructured in a production-ready chat application – feel free to copy this code to try it out yourself, and reach out at our community Slack if you have any questions.
How to run
To run this, we used the local Docker deployment setup from Danswer’s quickstart, with our fork:
- Clone the our fork of the Danswer repo:
git clone https://github.com/unstructured-io/danswer.git- Navigate to danswer/deployment/docker_compose
cd danswer/deployment/docker_compose- Bring up your docker engine and to build the containers from source and start Danswer, run:
docker compose -f docker-compose.dev.yml -p danswer-stack up -d --build --force-recreate- Danswer with the Unstructured parser for Google Drive will now be running on http://localhost:3000
Results
Here are a few comparisons, before and after, using the lines from the first episode of the office as a stand in for a call transcript:
Before Unstructured integration:
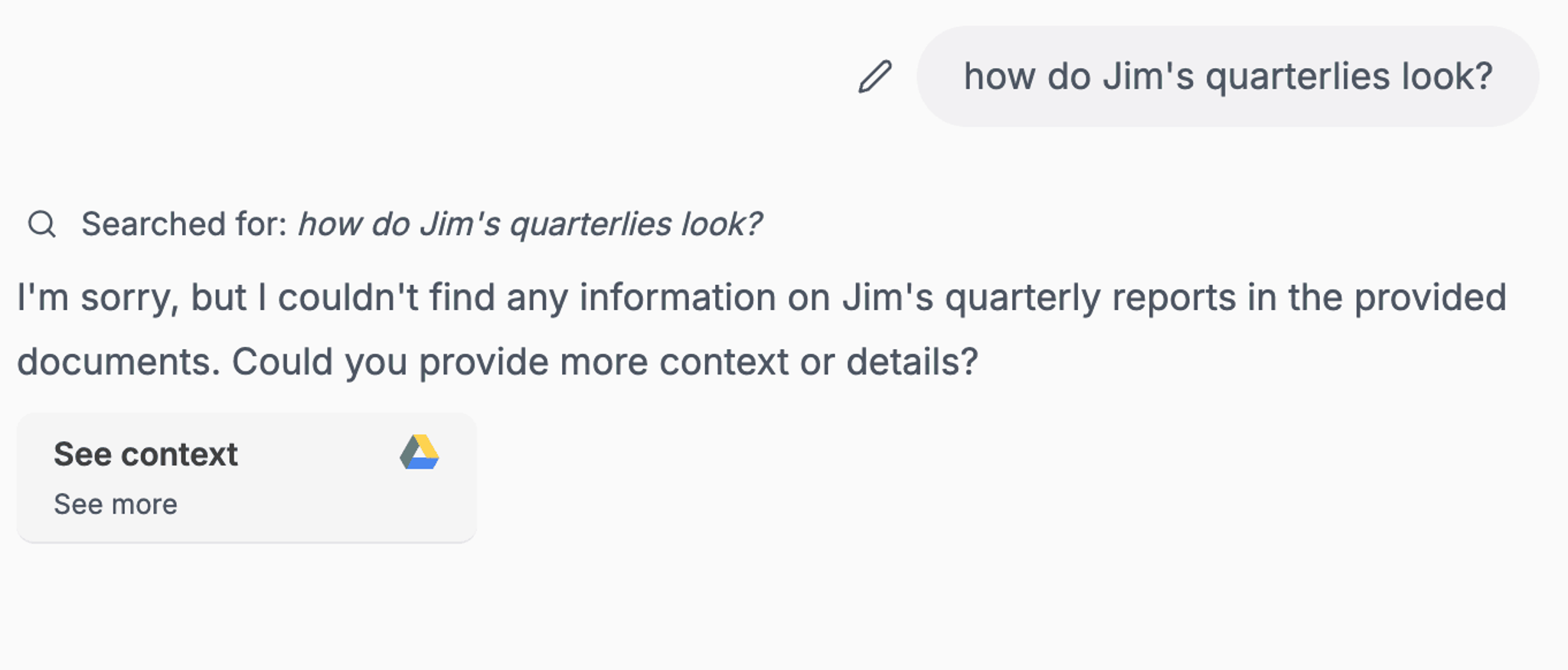
Danswer does not have inbuilt support to process this file as a .xlsx or .csv directly from Drive, the file would need to be uploaded directly in to the chat
After Unstructured integration:
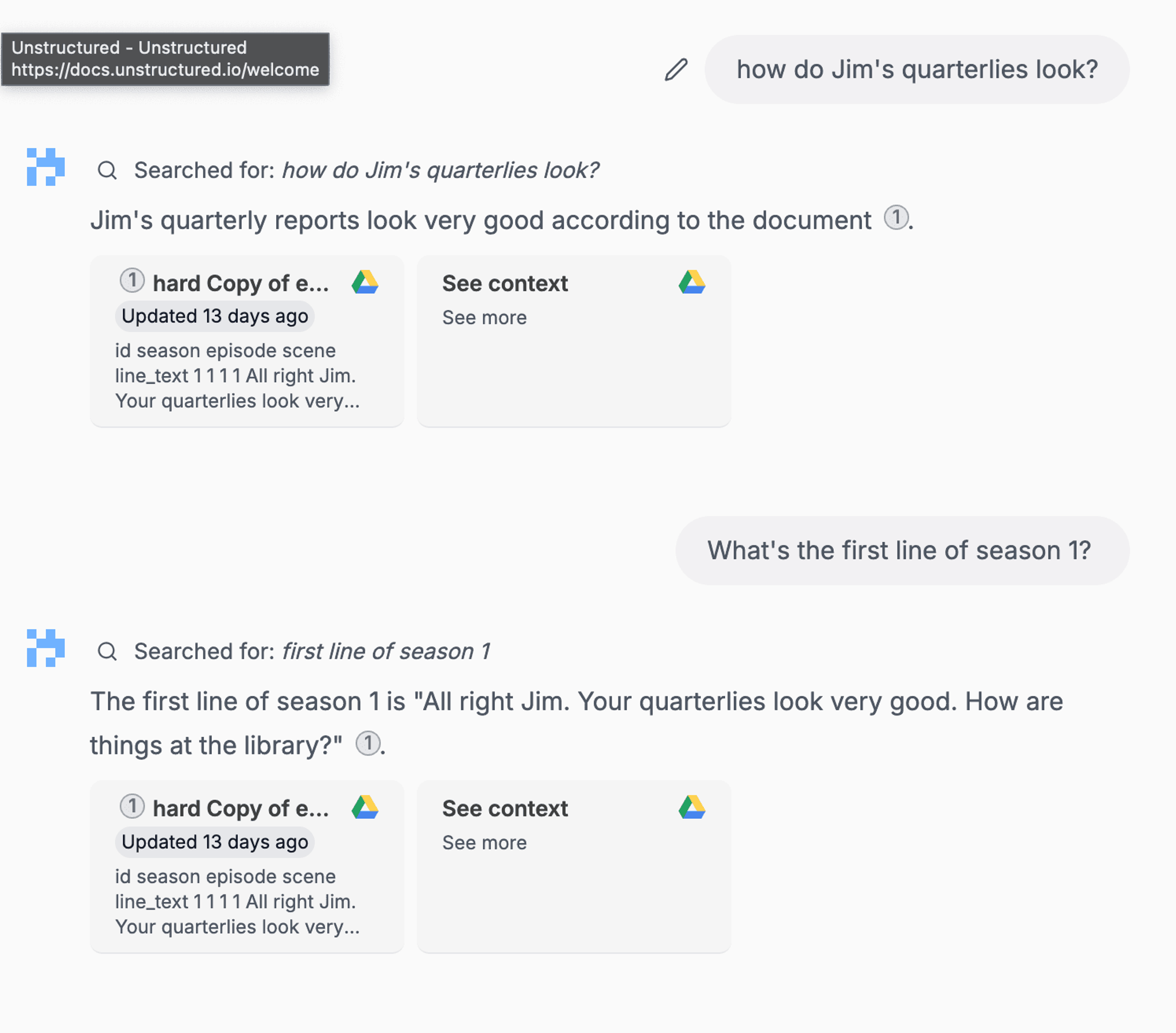
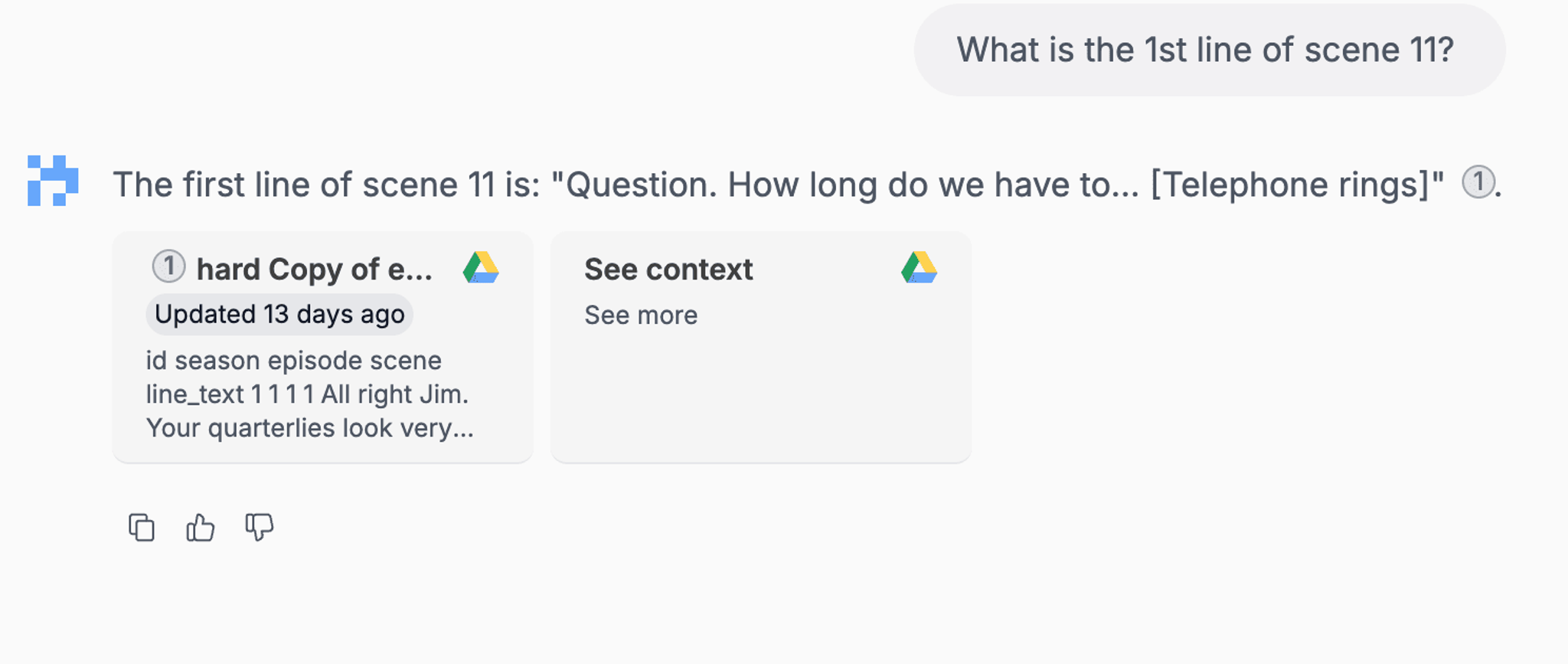
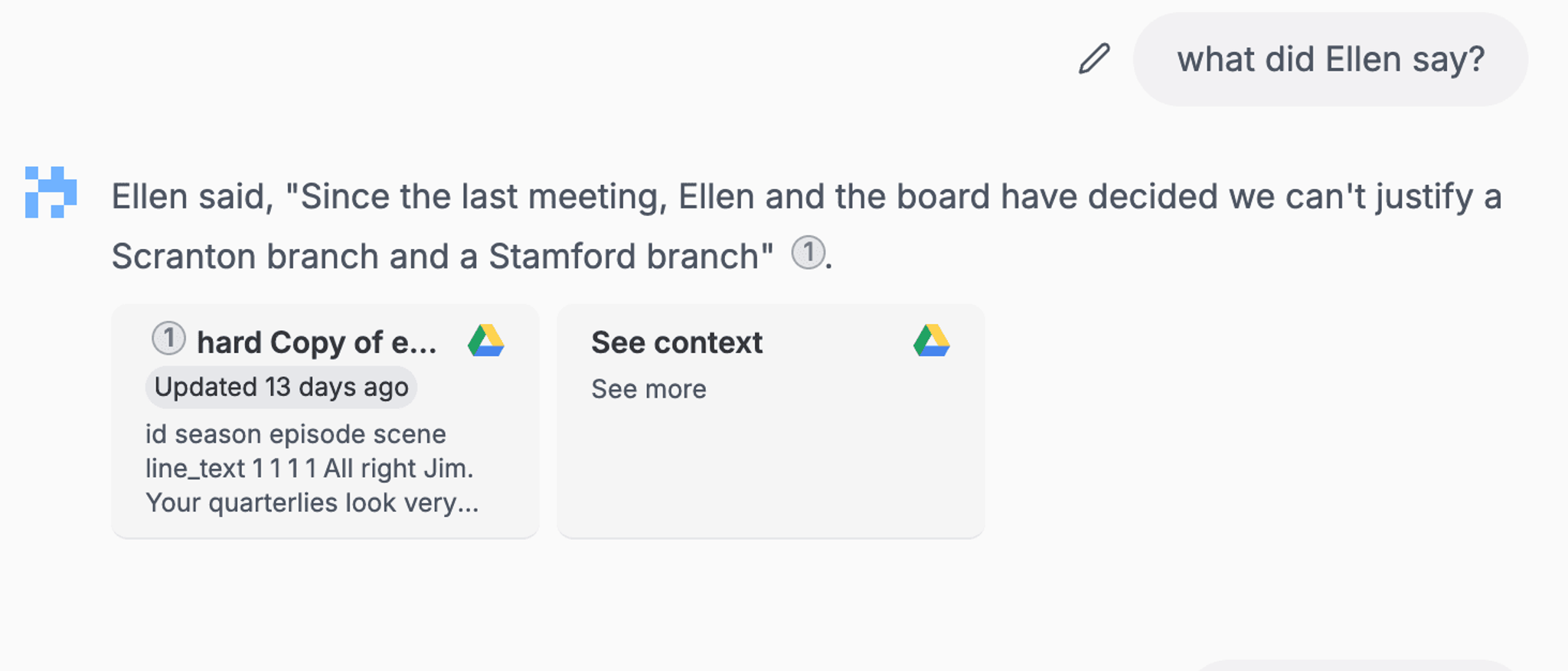

Conclusion
This is just a quick step to get started using the Unstructured API with Danswer, we are looking forward to further collaboration with the Danswer team for a deeper integration. This lightweight integration is missing Ingest pipelining for faster speed, metadata extraction (since that is handled elsewhere), and processing from additional sources besides Google Drive. But now you can process 13 additional file types in Danswer! Let us know if you’re interested in seeing more!


