
Authors

If you're building RAG applications at scale, you know the challenge of processing real-time document streams. Whether it's processing customer support tickets as they come in, analyzing financial reports the moment they're published, or keeping your knowledge base current with the latest documentation updates - handling streaming unstructured data is no small feat.
Today, we're excited to highlight the Unstructured Platform's integration with Apache Kafka. This integration enables seamless processing of document streams for RAG applications, making it easier than ever to keep your vector stores and knowledge bases fresh with the latest information.
Why Kafka?
Apache Kafka is the gold standard for handling real-time data streams. It's a distributed event store and stream-processing platform that can handle trillions of records per day with millisecond latency. For enterprise data teams, Kafka is often the backbone of their real-time data infrastructure, especially when using Confluent Cloud's managed Kafka service.
The integration with Unstructured Platform brings powerful document preprocessing capabilities to your Kafka streams. Now you can:
- Process documents in real-time as they arrive in your Kafka topics
- Transform unstructured data into clean, structured formats perfect for embedding generation
- Stream processed results directly to your vector stores or other destinations
- Handle high-volume document processing with enterprise-grade reliability
How the Integration Works
The Kafka integration works both as a source and destination connector in Unstructured Platform. As a source connector, it can consume documents from Kafka topics, process them through our document transformation workflow, and prepare them for your RAG applications. As a destination connector, it can push processed results back to Kafka topics, enabling seamless integration with your existing data flows.
Setting Up the Integration
Prerequisites
- A Kafka cluster in Confluent Cloud
- Bootstrap server hostname and port
- Topic name for reading/writing messages
- API key and secret for authentication
To help you set up a Kafka cluster in Confluent Cloud and obtain the necessary credentials, we recorded a quick video illustrating all the steps. You can find it on the documentation page.
Using the Platform UI
To set up Kafka as a source:
1) Navigate to Connectors > Sources
2) Click New or Create Connector
3) Name your connector and select Kafka as the provider
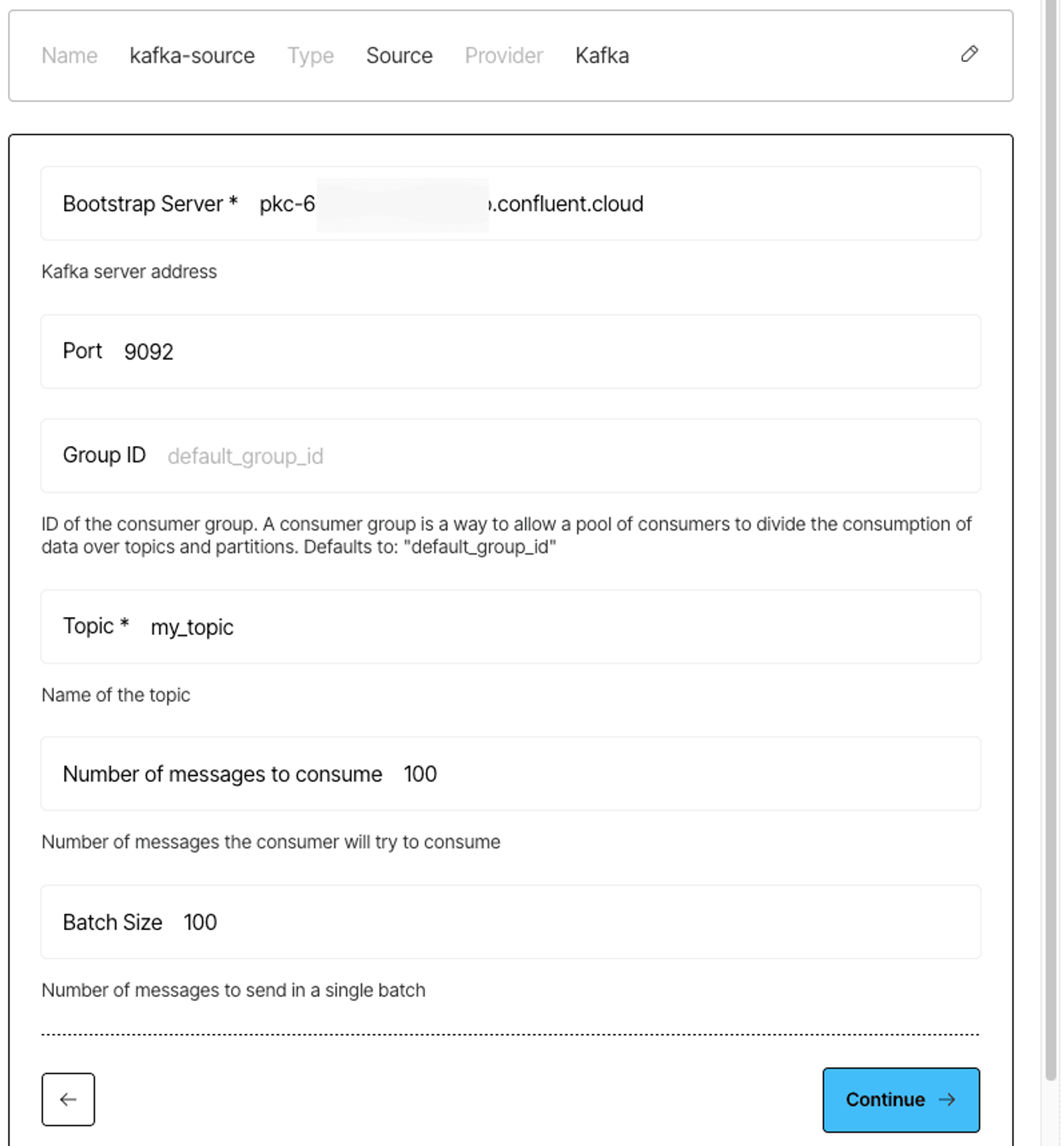
4) Fill in the required fields:
- Bootstrap Server
- Port
- Group ID (optional)
- Topic name
- Number of messages to consume
- Batch Size
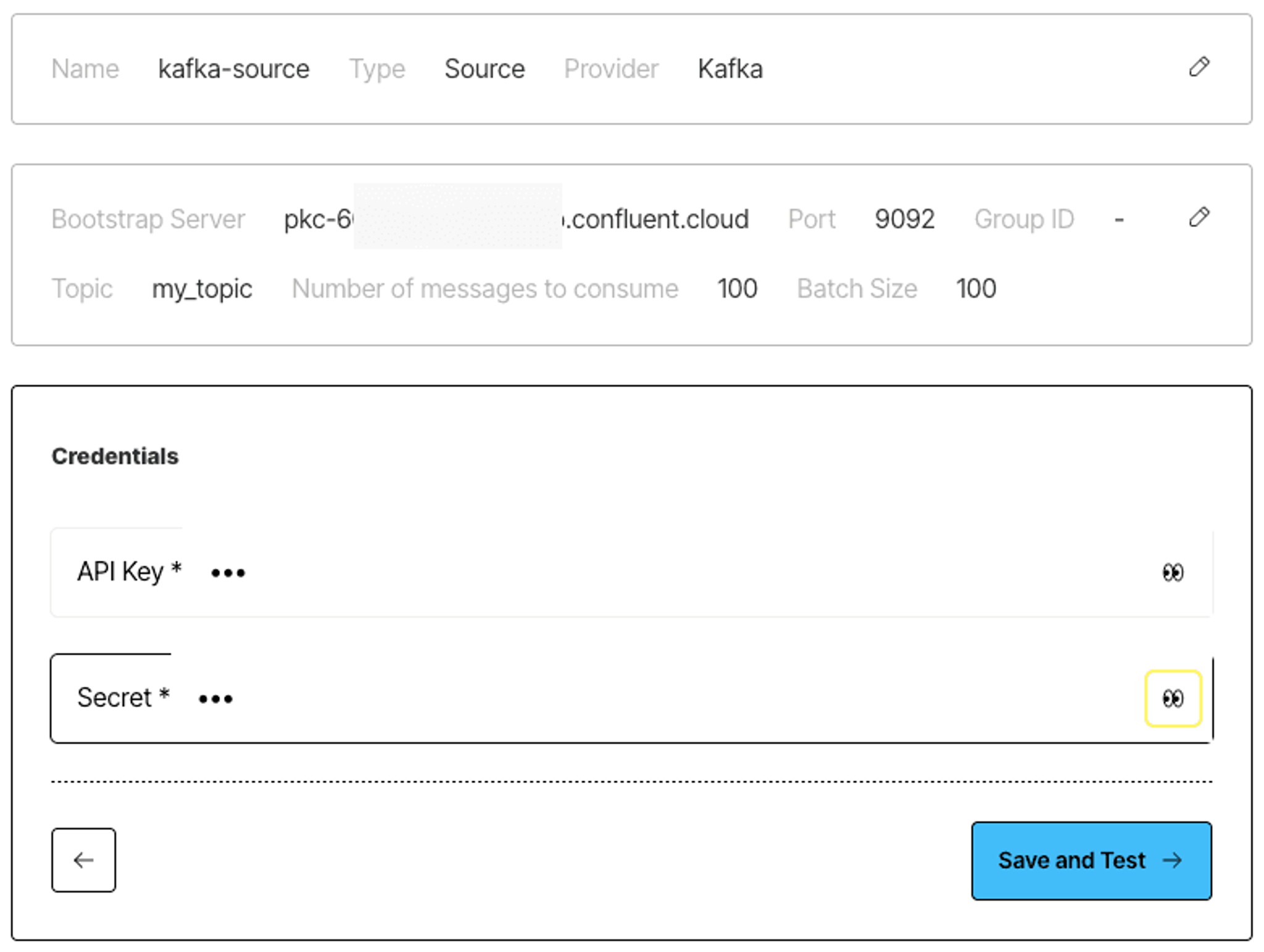
- API Key and Secret
5) Click Save and Test
Setting up a destination connector follows the same steps, but through the Destinations section.
Here’s an example of a Kafka source connector settings:
And here’s an example of the source connector's credentials configuration:
Using the Platform API
To create a Kafka source connector:
For destination connectors, use a similar request to /destinations instead of /sources.
Get started!
If you're already an Unstructured Platform user, the Kafka integration is available in your dashboard today!
Expert access
Need a tailored setup for your specific use case? Our engineering team is available to help optimize your implementation. Book a consultation session to discuss your requirements here.


