
Authors

The ETL paradigm we've grown comfortable with has limitations when it comes to handling the unique challenges of modern AI applications, and it’s starting to show. Traditionally, ETL pipelines were built around structured data with well-defined schemas. You'd extract data from databases or flat files, transform it according to business rules, and load it into data warehouses. The transformations were primarily about data cleaning, aggregation, and standardization. Life was... simpler.
GenAI applications, particularly those involving RAG (Retrieval Augmented Generation), have unique data requirements. In this blog post we explore what makes them special.
Unstructured Data Dominance
Most enterprise knowledge, aka the exact context your LLM-based application requires, lives in unstructured formats - PDFs, Word documents, PowerPoint presentations, internal wiki pages, emails, and chat messages. Traditional ETL tools weren't designed to handle these formats effectively. They are not built for unstructured data.
Handling a plethora of file formats
Each file type - whether it's a PDF, DOCX, PPT, or some other format - has its own internal structure and encoding. You need different parsers and extraction strategies for each format, significantly increasing complexity and maintenance overhead.
Unstructured Platform addresses this challenge by providing comprehensive data transformation capabilities that can handle over 60 different types of unstructured data formats. The platform employs a multi-layered approach: rule-based parsers efficiently handle structured documents like HTML, markdown, and Word files; custom fine-tuned OCR and document understanding models process image-based content from PDFs and PowerPoint presentations; and for the most challenging documents like noisy scans, handwritten notes, and complex tables and forms, the platform leverages state-of-the-art models such as, for example, Claude Sonnet and GPT-4o. The combination of parsing strategies ensures reliable content extraction across a wide range of document types while remaining cost-effective. Unstructured intelligently routes documents through the appropriate strategy, optimizing both processing speed and cost.
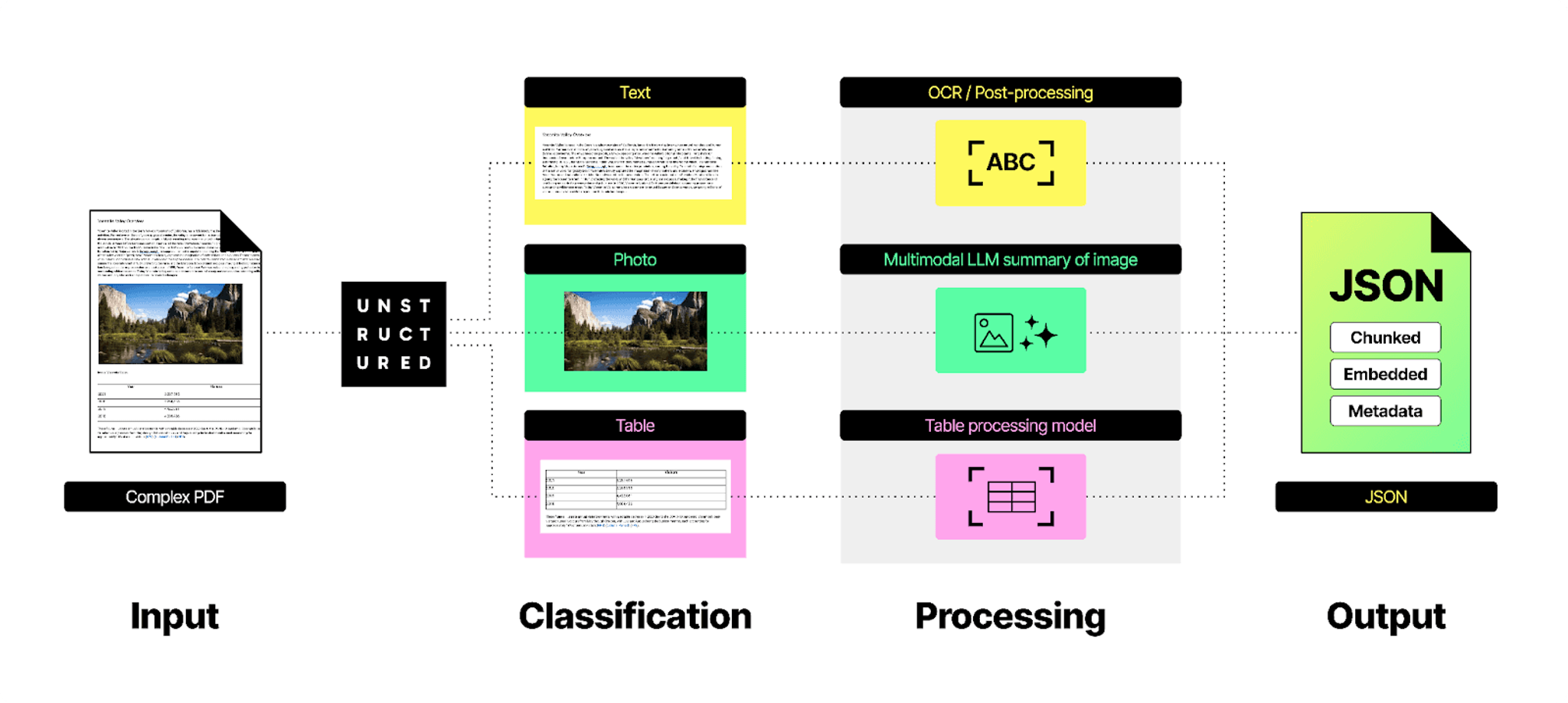
Extracting text while preserving document structure
Unlike structured databases where data fits neatly into predefined fields, documents contain rich formatting that carries meaning - headers indicate topic hierarchy, font styles emphasize key points, and spacing or bullet points define logical groupings. On top of that, business documents frequently use multi-column layouts, sidebars, footnotes, and nested tables to present information. Traditional ETL tools often strip this crucial context away, leaving behind a flat stream of text that loses the intended organization, emphasis, and topic separation. Tables are particularly problematic - what a human easily recognizes as rows and columns often gets misinterpreted as unrelated text blocks, destroying valuable structured data within unstructured documents.
Unstructured takes a more sophisticated approach by converting documents into document elements that preserve their semantic structure. These elements - which include types like Title, Header, NarrativeText, ListItem, Table, and more - maintain the original document's organization while normalizing content from different file formats into a consistent schema. The platform also captures crucial metadata like parent-child relationships in document sections through parent_id fields, hierarchical depth through category_depth indicators derived from native document structures like HTML heading levels, and even preserves emphasized text formatting through dedicated metadata fields. This rich preservation of document structure and metadata enables more nuanced downstream use while also providing a unified interface across all supported document types.
Processing embedded images and diagrams
Modern documents are highly visual, containing charts, graphs, screenshots, and explanatory diagrams. These visual elements often contain critical information that complements the surrounding text. Traditional ETL tools typically either ignore these elements completely or extract them as separate files, breaking the connection between visual and textual information.
Unstructured Platform maintains the integrity of visual content within documents. It preserves images directly in the output JSON through base64 encoding, ensuring that visual elements remain accessible when documents are retrieved in RAG applications. Furthermore, the platform's image enrichment capabilities can generate detailed descriptions of visual content, converting complex visual information into searchable text. This dual approach of preserving both the visual data and providing rich textual descriptions enables more comprehensive document processing and retrieval, ensuring no valuable information is lost in the extraction process.
The limitations of traditional ETL tools don’t let organizations fully utilize the wealth of information contained in their document repositories, while Unstructured Platform ensures all of the valuable rich context is available for your downstream AI application.
Context is King
In traditional ETL, we often focus on extracting specific fields or values. However, GenAI applications require a fundamentally different approach - one that preserves not just the text, but the rich contextual fabric that gives that text meaning. Traditional ETL might grab basic metadata like filenames and dates, but GenAI needs much more. Document metadata tells a deeper story about content authority, recency, relationships, and its place within the business context.
Unstructured Platform automatically extracts a comprehensive set of metadata including page numbers, email communication details, language indicators, and hierarchical relationships. Its ability to capture parent_id and category_depth preserves document structure, while metadata fields like link_url help map connections between documents. This rich metadata foundation makes it possible to build more intelligent retrieval systems, whether through precise filtering or advanced GraphRAG implementations that leverage document relationships and hierarchies.
Chunking Complexity
Traditional ETL doesn't have to worry about text chunking at all - a critical requirement for RAG applications. This process of breaking down documents into smaller, meaningful segments may seem simple at a first glance, however it presents unique challenges that require careful consideration and specialized approaches.
- Choosing a chunk size: Most embedding models have token limits that directly restrict chunk size. Exceeding these limits can lead to truncation or processing failures. Even if the chunk doesn’t exceed the model’s limits, it still represents a trade-off in RAG systems. Larger chunks contain more context but can reduce retrieval precision by including irrelevant information. Conversely, smaller chunks offer better precision but might miss important contextual relationships.
- Maintaining semantic coherence: Creating semantically meaningful chunks involves more than just counting characters or tokens. Effective chunking should respect natural language boundaries, such as paragraphs and sentences, while ensuring that key concepts, definitions, and arguments remain intact. Additionally, the document’s structure—headers, sections, and subsections—should guide chunking decisions to maintain the logical flow of information.
- Preserving context across boundaries: Implementing controlled overlap between adjacent chunks helps maintain context and reduces the risk of losing information at chunk boundaries.
- Handling special cases like tables, lists and code snippets: Certain document elements require specialized handling during the chunking process. These elements often contain structured or non-linear information that can lose meaning if split improperly.
Addressing these challenges ensures that chunking not only maintains the logical flow but also preserves the unique characteristics of different content types.
Unstructured Platform addresses these chunking challenges through its structure-aware approach and versatile chunking strategies. Unlike basic text processing tools, Unstructured Platform preserves the original document structure during the partitioning phase. This means chunking is performed on clearly identified document elements rather than raw text, enabling more intelligent segmentation decisions. Unstructured Platform offers several smart chunking strategies that address a wide range of use cases:
- The "chunk by character" strategy offers a foundational approach for simple use cases, intelligently combining smaller elements such as list items to enhance context while respecting size limits.
- For documents with clear section hierarchies, the "chunk by title" strategy ensures topic integrity by maintaining section boundaries.
- When dealing with page-specific content, the "chunk by page" strategy prevents cross-page content mixing.
- The "chunk by similarity" strategy employs embedding models to identify and group topically related content, particularly useful for documents where structural cues are insufficient.
- Finally, the recently added "contextual chunking" (available to select customers only) offers chunks enrichment with additional document context to improve downstream retrieval performance.
These chunking strategies combined with customizable overlap options, give you all the flexibility to tailor your chunking approach to your particular use case. But we take it one step further! Unstructured Platform can analyze your document collection and recommend optimal chunking strategies and chunk sizes, removing the guesswork from configuration decisions.
Breaking Data Silos
Enterprise data landscapes have become increasingly complex, with valuable information scattered across numerous systems, each with its own authentication methods, data formats, and access patterns. A modern ETL pipeline for GenAI needs to seamlessly integrate with:
- Cloud Storage Solutions (Azure Blob, GCS, S3)
- Collaboration Platforms (SharePoint, Confluence, Box)
- Business Applications (Salesforce, HubSpot)
- Communication Tools (Slack, Discord, Outlook)
- Database Systems (MongoDB, PostgreSQL, Snowflake)
- Development Platforms (GitHub, GitLab)
- Document Management Systems (Google Drive, OneDrive)
- And more
Traditionally, building secure and reliable connections to these diverse systems would require months of development work and ongoing maintenance. However, Unstructured Platform’s rich connector ecosystem can eliminate this complexity through pre-built integrations that enable rapid deployment of RAG-ready pipelines. The real power comes from the ability to:
- Connect multiple data sources simultaneously
- Standardize data preprocessing across all of the data sources and file formats
- Direct processed data to various destinations including vector stores, search services, and traditional databases
- Scale workloads efficiently in production environments
- Maintain flexibility in choosing storage and retrieval solutions that best fit your use case
Bring On The New ETL Stack
GenAI applications heavily depend on the rich context of unstructured data which requires a new approach to ETL, specifically designed for GenAI applications. This is exactly what Unstructured Platform offers. It represents a fundamental shift in how we think about data processing pipelines, moving beyond simple extraction and transformation to intelligent, context-aware document processing.
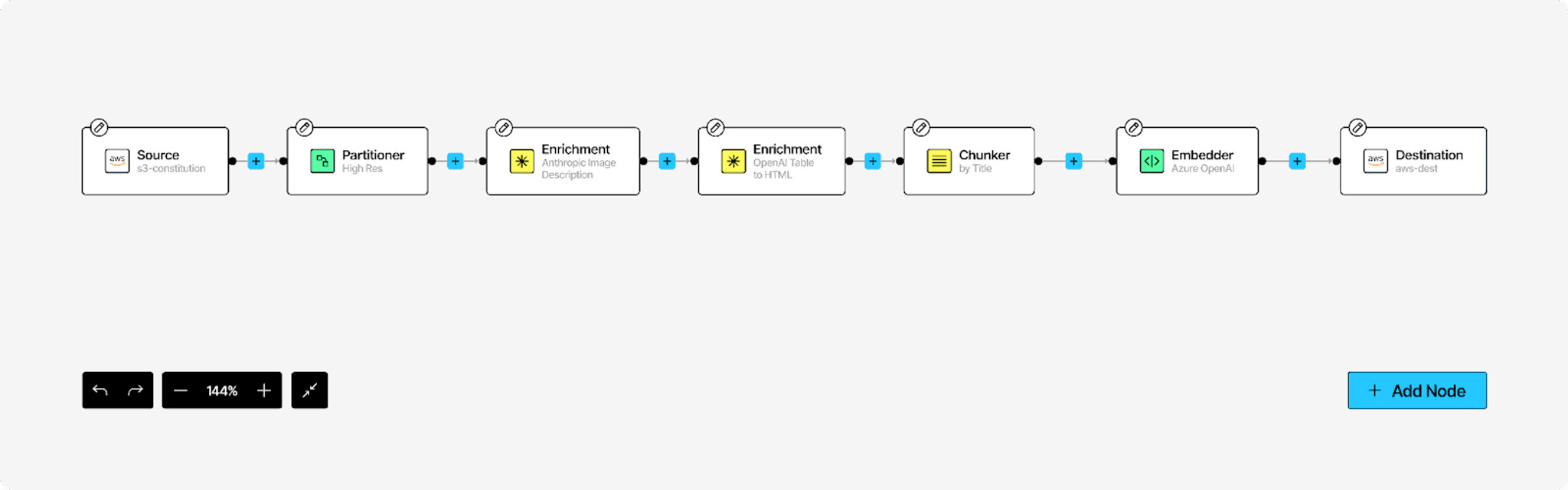
In the DAG image above, you can see an example pipeline from Platform, including GenAI-based steps like enrichment with image description and table to HTML. This pipeline also includes requirements for GenAI applications, of chunking and embedding.
Unstructured Platform combines several key innovations that make it particularly well-suited to prepare data for GenAI applications:
- Advanced document understanding capabilities that preserve structure and meaning across dozens of file formats
- Sophisticated metadata extraction that maintains the rich context needed for effective retrieval
- Intelligent chunking strategies that optimize for different use cases and content types
- A comprehensive connector ecosystem that breaks down data silos
- Production-ready scalability that handles enterprise workloads
Traditional ETL tools, while valuable for structured data workflows, simply weren't designed to handle the complexity of modern document processing needs. The future of ETL lies in platforms that can intelligently process unstructured data while preserving the context and relationships that make that data meaningful.
Whether you're building your first RAG application or scaling an existing one to handle enterprise workloads, having the right foundation for document processing is crucial. The Unstructured Platform provides that foundation.
Contact us to get onboarded to Unstructured. For enterprises with complex needs, we offer tailored solutions. Book a session with our engineers to explore how Unstructured can fit your workflows.


