

Authors

In image classification or segmentation, typically smaller images are used (e.g. 224x224 or 384x384). In document understanding larger images need to be processed or information might be lost. There are possible optimizations, some depending on the hardware architecture in which these solutions might be run, but these might make the solutions less portable. At Unstructured, we are considering possible solutions that are not dependent on a particular hardware platform and instead focus on algorithmic improvements.
In vision transformers, images are split into patches and linearized before they are provided to a transformer. After several processing layers the output is used as input to a transformer decoder for text generation. One of the issues is that transformers have a quadratic cost with respect to the length of the input. In this post, we explore possible solutions to increase the processing speed of ViTs (vision transformers), with an application in document understanding.
There are standard optimization techniques that are already available, which include quantization and pruning. These techniques can already provide a 2x boost in processing speed.
Other techniques have arisen from adapting vision transformers to environments with limited computing capabilities, like mobile phones. An example of a mobile network is named EfficientFormer, which combines CNNs with transformer blocks. Despite the network being faster, the performance is below more costly networks.
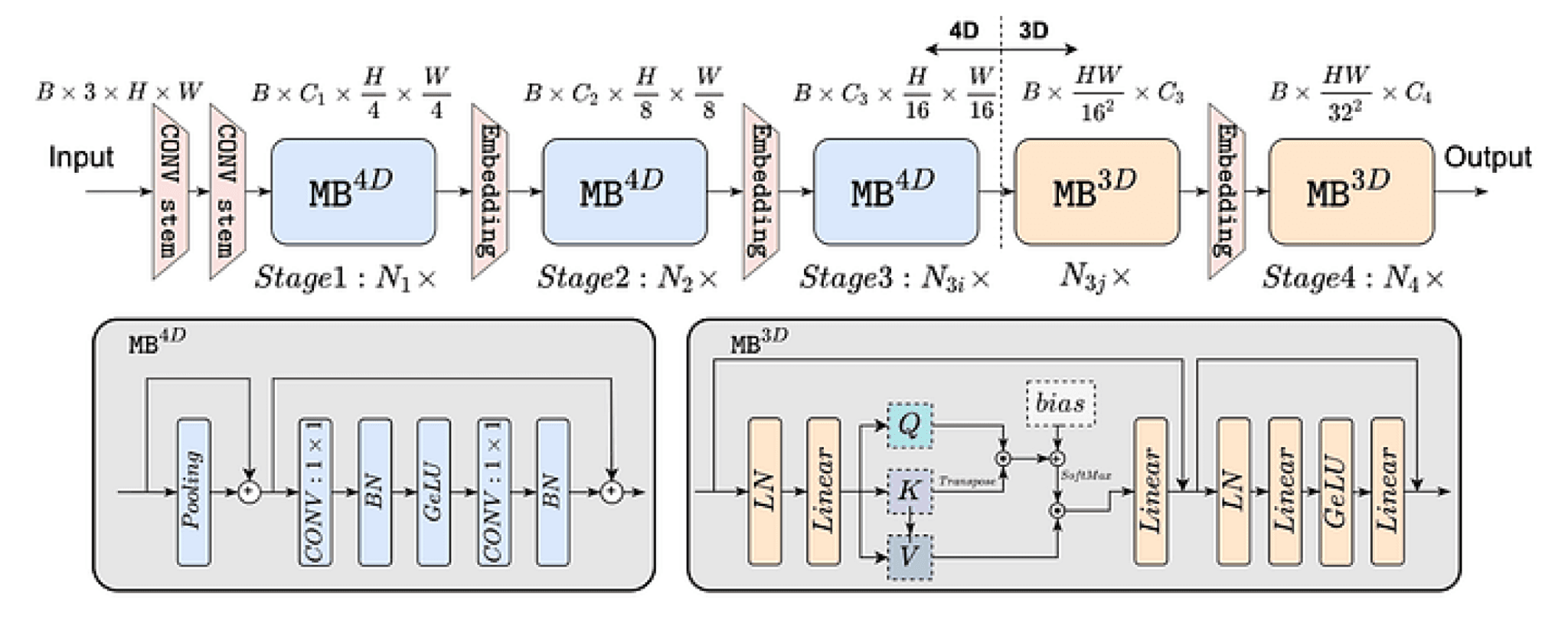
Li, Yanyu, et al. “EfficientFormer: Vision Transformers at MobileNet Speed.” arXiv preprint arXiv:2206.01191 (2022).
Swin ViT splits the images into patches in a more efficient way compared to the original vision transformer implementation. In this case, the cost is still quadratic but applied to smaller patches, which minimizes the impact.
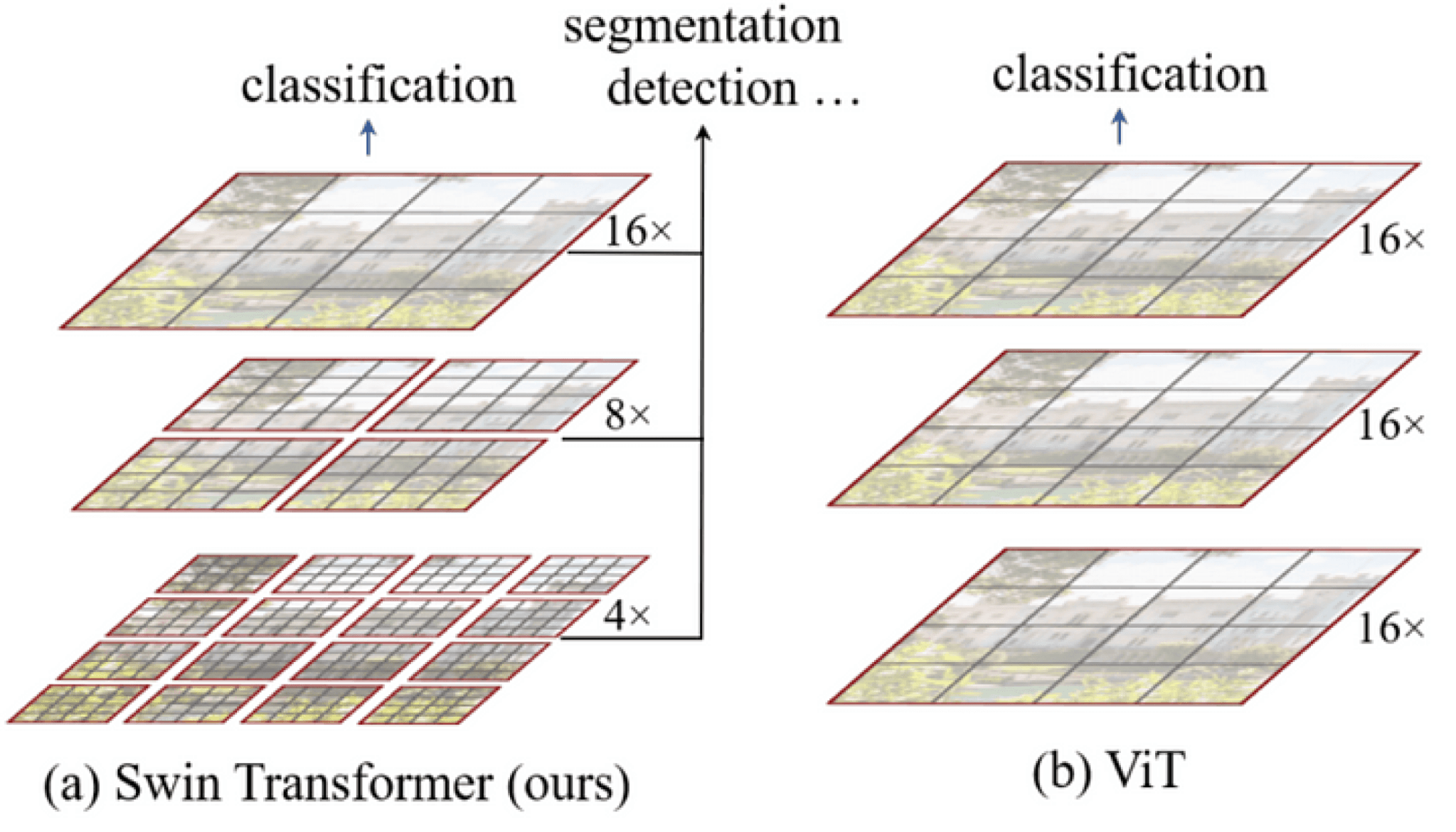
Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
There are approaches that use sparse representation of the attention matrices. For instance, by applying specific patterns, the quadratic cost of the transformer can be reduced to a much smaller complexity (e.g. O(N * sqrt(N))), which is a significant improvement when dealing with longer image sequences. An example of a sparse attention matrix is presented in the figure below. On the other hand, it is unclear in which scenarios sparse attention might train effectively or even run effectively since some implementations of GPU sparse matrices might not have an improved cost compared to full attention matrices.
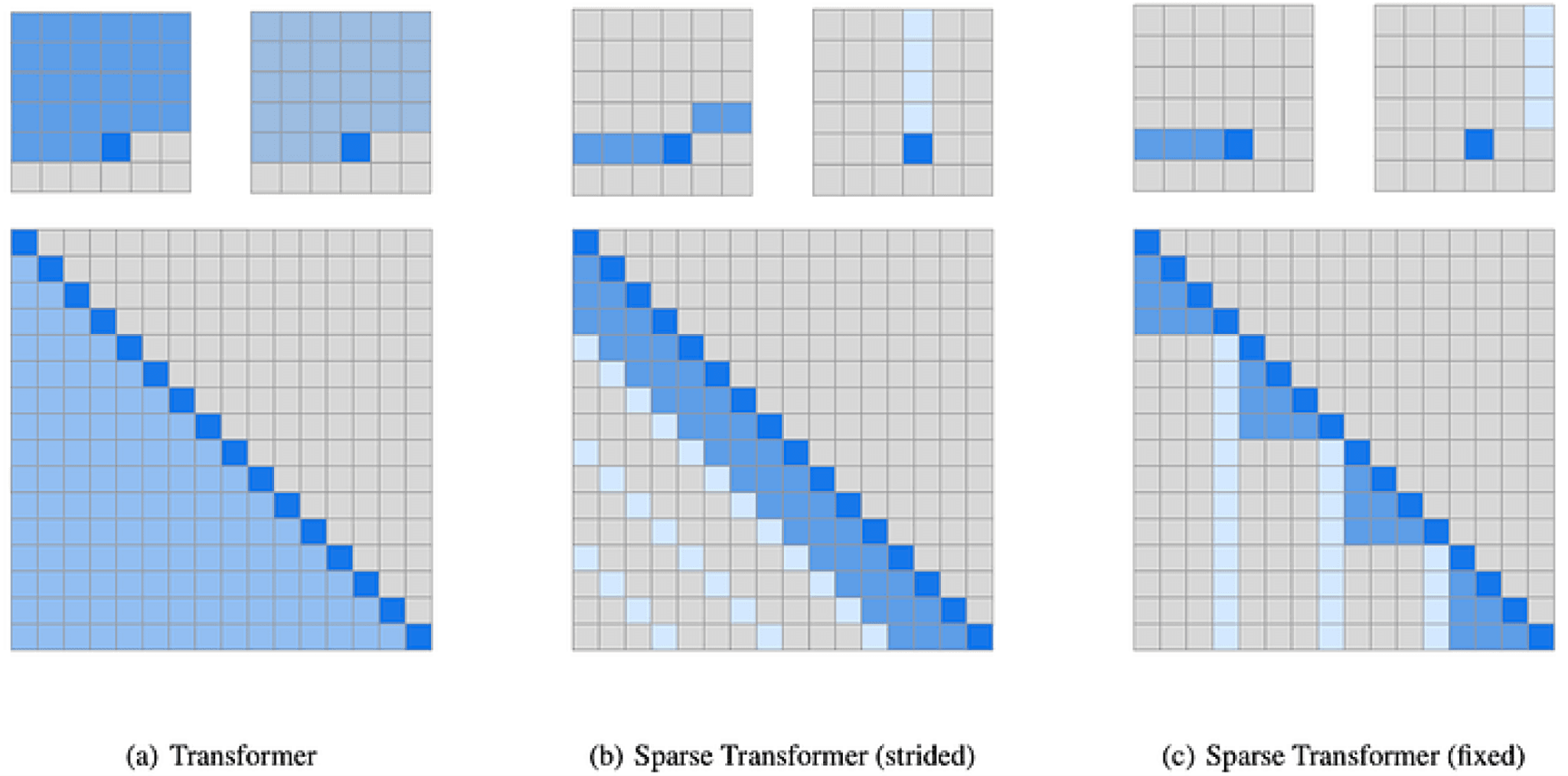
Attention matrix (a) vs proposals for sparse attention. Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509.
Another approach to reduce the size of the attention matrix is to find a decomposition that would allow reducing the cost of the calculations, an example of this decomposition for self-attention includes Linformer or random feature attention. Other approaches such as Performer, achieves linear performance rearranging the matrices used in the calculation of attention and works both in self-attention and cross-attention (Swin vision transformer was evaluated against an implementation of the Performer. Swin vision transformer showed better performance compared to the Performer, even though the improvements proposed in the Performer were not implemented within the attention of the Swin transformer). Some of these methods have not been evaluated yet in document understanding and there could be benefits combining vision transformer approaches and the recent development in reducing the cost of attention calculation.
Some of the network architectures that we have mentioned are not as performant as more complex and costly ones. In some cases, teaching the less costly networks using a trained version of one of the more costly networks using knowledge distillation might bridge the gap between computing cost and efficiency. Additional work is required to identify benefits using these methods.
On the other hand, document understanding uses vision transformers to obtain a representation of the document ready to be processed by a decoder to generate the text output. Simpler models with a lower cost could be used to identify the main text areas considered by the decoder transformers. In object detection and classification, vision transformers and CNNs could take a more relevant role in the final prediction.
The Unstructured team is experimenting with these and other approaches to develop documenting understanding ViTs that are fast enough for real-world document preprocessing applications. If you’d like to keep up with our latest research, follow us on LinkedIn and Huggingface and give our GitHub library a star!


