Authors

These models, however, come with a trade-off — they are expensive and slow to run. Over the past several months, the team at Unstructured has focused on optimizing Vision Transformers (ViTs) as encoders and transformer decoders for text generation. Our goal is to convert PDFs and images to structured formats, such as JSON, fast enough for industrial use cases.
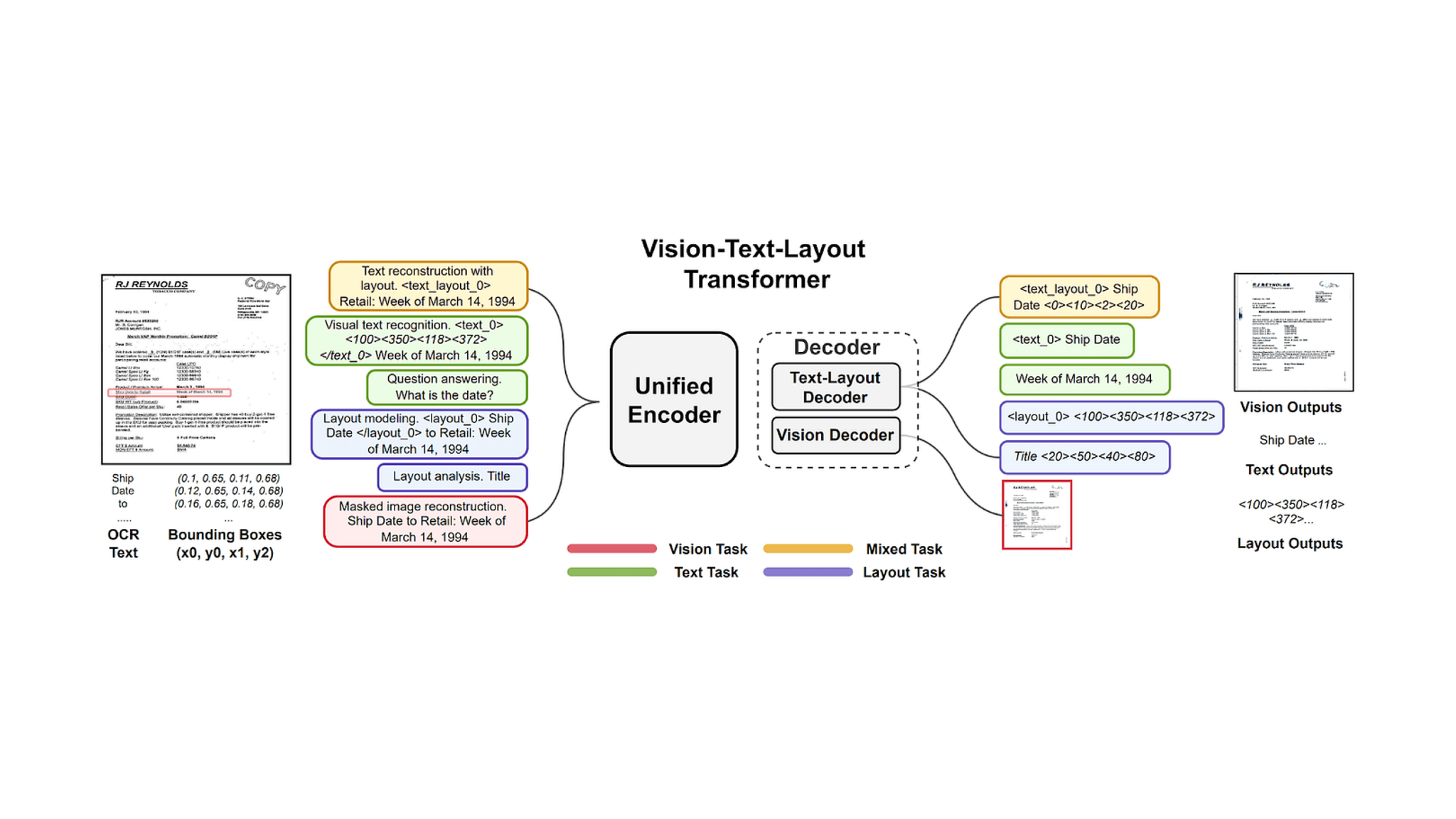
Example Visual encoder decoder for document understanding [Tang, Zineng, et al. “Unifying Vision, Text, and Layout for Universal Document Processing.” arXiv preprint arXiv:2212.02623 (2022).]
Currently, ViTs rely on autoregressive language models for text generation using transformers. Autoregressive models generate text one token at a time starting with an initial set of tokens, as shown on the left of the figure below. These models generate tokens in sequence and the next token is generated taking into account the previous tokens. Tokens are generated one at a time until the end-of-sentence (EoS) token ([eos]) is generated. In some cases, context related to the text generation task is provided by an encoder as shown above.
This autoregressive text generation process is expensive. The cost of processing the previously predicted tokens to generate the next one by existing transformer based methods has a quadratic cost with respect to the length of the number of tokens. So the longer the text being generated, the higher the computational cost.
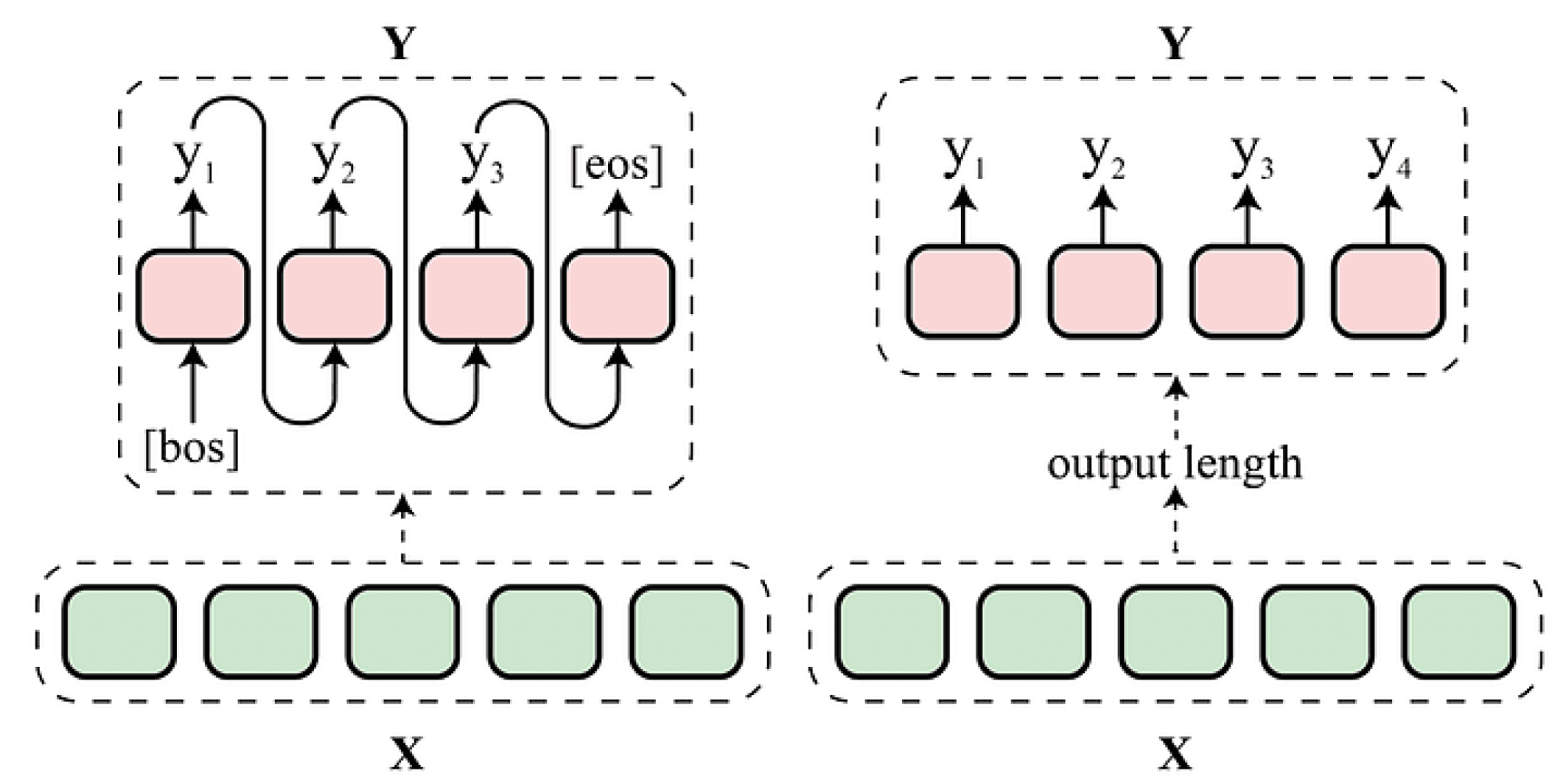
The figure above shows an autoregressive language model example vs non-autoregressive on the right [Su, Yixuan, et al. “Non-Autoregressive Text Generation with Pre-trained Language Models.” Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021]. Green boxes represent the encoder while the salmon boxes represent the decoder.
One way to reduce the cost of text generation is to generate text in a non-autoregressive fashion, i.e. overcoming the dependency on previously generated tokens while generating new tokens, as shown on the right of the figure above. To achieve non-autoregressive text generation there are two issues that we need to address. The first one is to identify the length of the text we need to generate. In autoregressive language models the generation stops once the model predicts the EoS token. The second one is how to model the dependency between the generated tokens.
The figure below shows a method that solves both of these problems using a neural conditional random field (CRF) at the output of a BERT encoder model. The CRF constrains the token generation output and encodes the transition from the EoS token to EoS token transition, so the model does not predict any additional tokens after the EoS token. The solution incorporates optimizations to deal with the large transition space defined by the size of the vocabulary of the tokens used for text generation. Using this method, text generation does not require a decoder transformer.
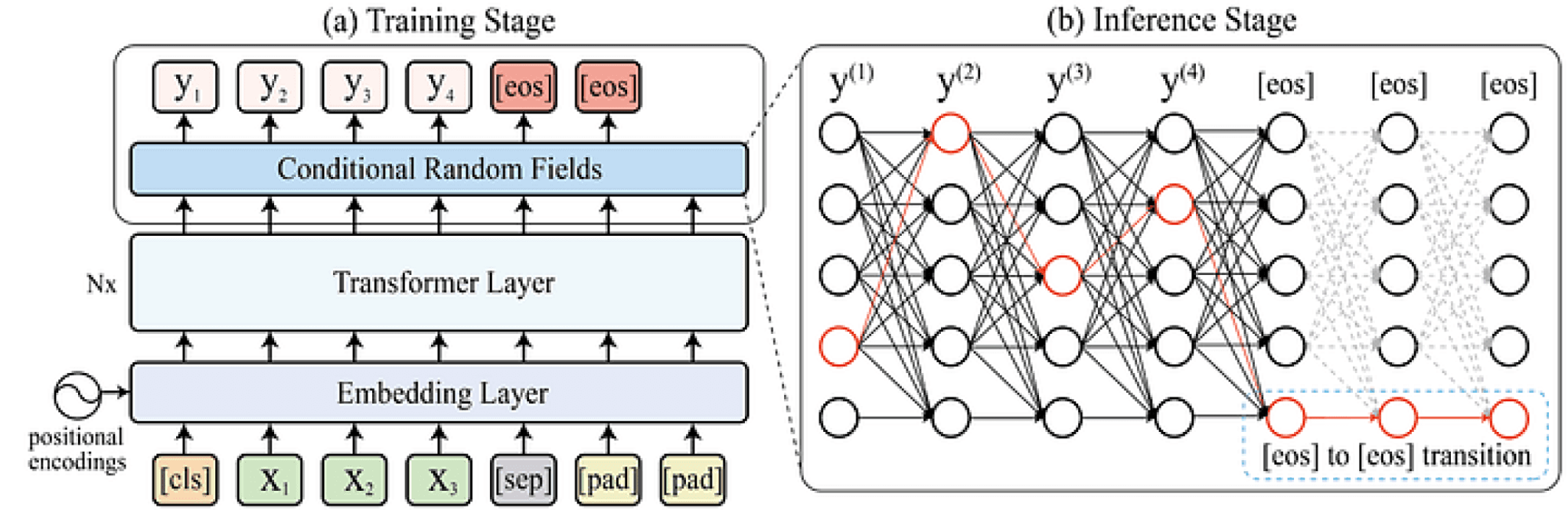
Text generation system by (Su, Yixuan, et al. 2021) in which a neural CRF generates text using the information provided by the transformer layer.
A paper at EMNLP 2022 proposed a method called ELMER [Li, Junyi, et al. “ELMER: A Non-Autoregressive Pre-trained Language Model for Efficient and Effective Text Generation.” arXiv preprint arXiv:2210.13304 (2022)] that uses a decoder transformer to generate text in a non-autoregressive fashion. The model identifies the length of the sequence by predicting the EoS token as in the previous method, but the decoder transformer predicts dependencies among the tokens the model is generating. Typically, models predict tokens in the last layer.
In this approach, the model predicts tokens at different layers of the decoder using an early exit strategy. The decode transformer is modified to allow the prediction of tokens not only at the last layer, but at any previous layer. In this way, the dependencies can be modeled. The early exit is a trainable component and the training encourages that tokens are predicted at different layers using a permutation mechanism.
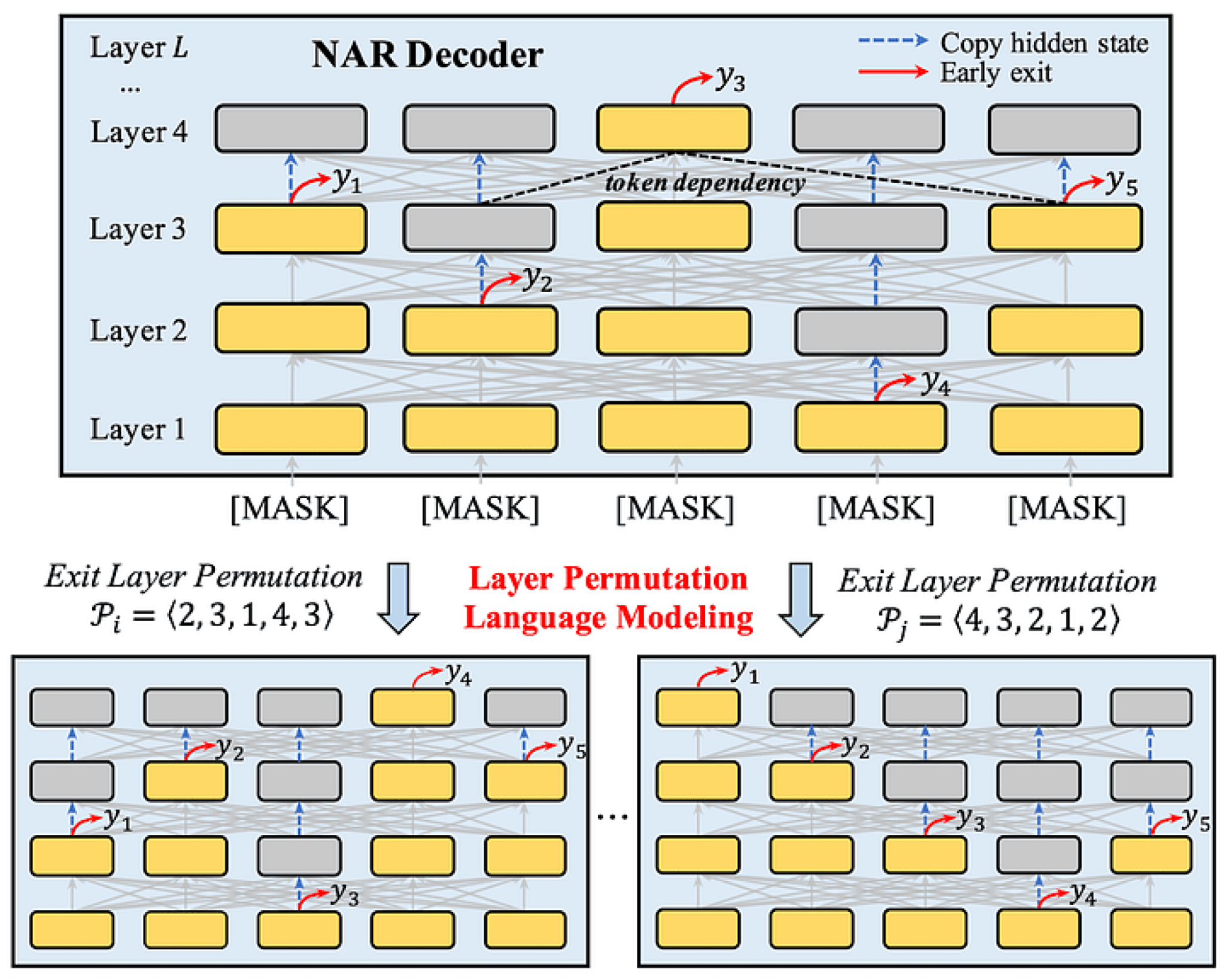
ELMER (Li et al., 2022) non-autoregressive decoder text generation proposal.
A similar approach called CALM was presented at NeurIPS 2022 named CALM [Schuster, Tal, et al. “Confident adaptive language modeling.” arXiv preprint arXiv:2207.07061 (2022).] This method implements early exit to finish generation earlier. While still being an auto-regressive language model, it is interesting to see strategies applied to speeding up text generation.
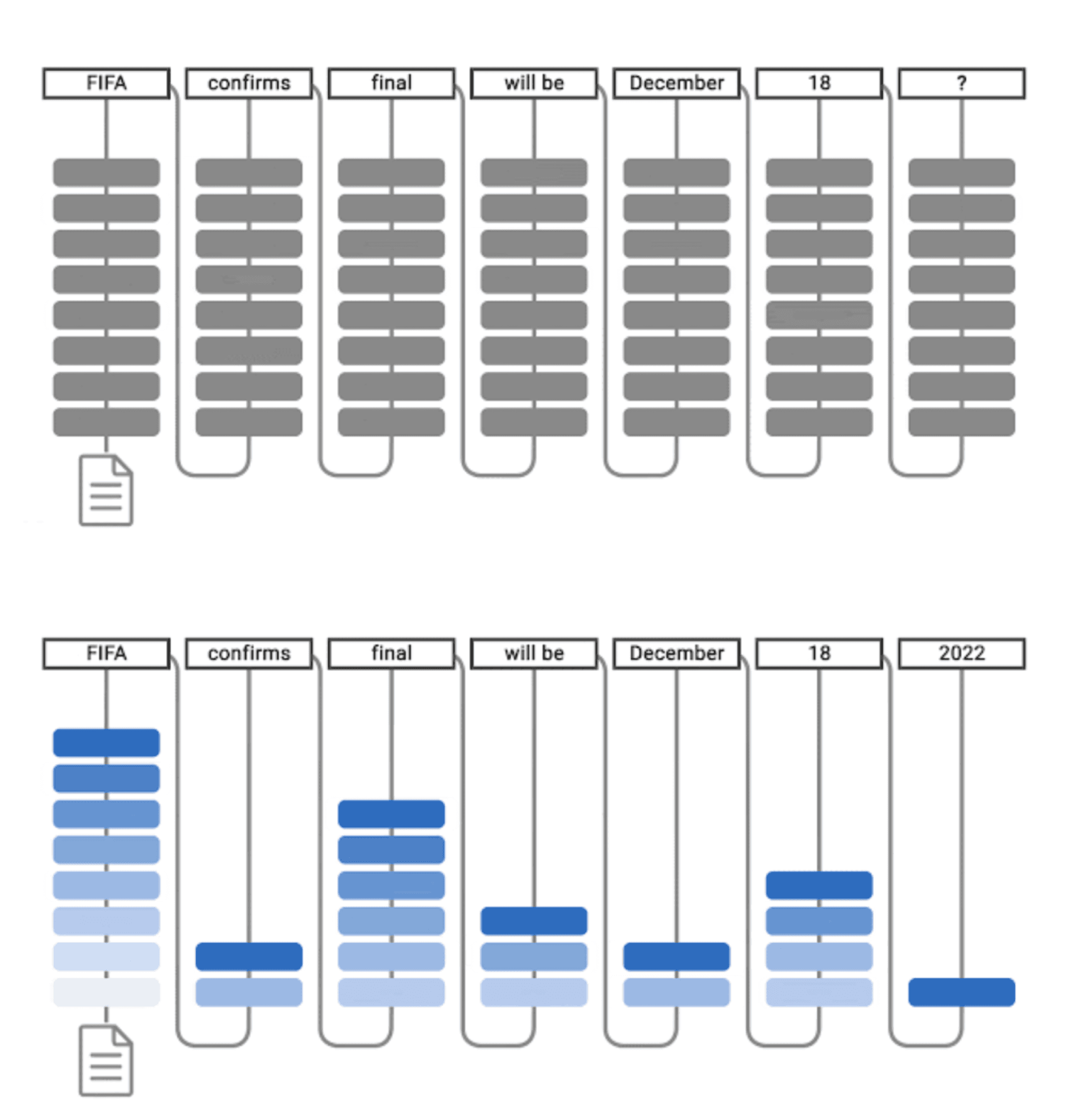
Traditional text generation (above) vs CALM method (below) (Schuster et al., 2022).
The methods presented in this blog achieve significant speed ups in text generation in several tasks with no significant degradation in accuracy or even improving the performance of autoregressive state-of-the-art approaches. Typically, text tokens are generated from left to right. CALM relies on early exit from the transformer decoder, which might speed up the generation of text. On the other hand, ELMER is able to generate text bi-directionally, which has a positive impact on the speed of text generation, and could improve the accuracy of the models.
The Unstructured team is experimenting with both of these and other approaches to develop documenting understanding ViTs that are fast enough for real-world document preprocessing applications. If you’d like to keep up with our latest research, follow us on LinkedIn and Huggingface and give our GitHub library a star!


