

Authors

In this post, we’ll show how RAG support features within Unstructured help natural language applications produce more focused, detailed responses that are easier to source. Specifically, content-aware chunking within Unstructured produces higher quality RAG outputs than standard character-based chunking, especially when the relevant content is split across multiple sections within a document, or multiple documents in a collection. As a bonus, RAG systems that use Unstructured’s chunking will produce more precise citations for an LLM response.
The Challenge: Getting Good Chunks
When building a RAG application, developers typically split the source documents into chunks before embedding them and loading them into a vector database. There are a couple of reasons for doing this:
- Chunking documents results in more granular embeddings, making retrieval more accurate.
- Tighter chunks produce more focused prompts for the LLM.
- Documents are often too big for the context window of the LLM. Even when the context window is big enough, processing the full document is expensive and LLMs often give sub-optimal responses if the context is too big.
A standard strategy for chunking documents is to split the document into equally sized sections based on character length. This is not ideal, because logical groupings of text within a document do not always have the same length. As a result, you wind up with mismatched content within chunks and similar content in separate chunks.
Unstructured addresses this problem through content-aware chunking. Because Unstructured identifies document elements such as titles, body text, and bulleted lists, we can break documents into more coherent segments. This provides us with more distinct vectors for similarity search and more focused prompts for the LLM. The figure below shows how Unstructured chunks differ from character splitting.

Figure 1: Unstructured Chunks vs. Character Splitting
Testing It Out
The connection between more sophisticated chunking and higher quality RAG outputs makes sense in theory, but can we prove it? To test the hypothesis, we used GPT-4 to compare LLM outputs when using Unstructured versus character based chunks. The diagram below outlines the testing workflow, which Ryan Ngyuen explains in more detail on the Better Programming blog.
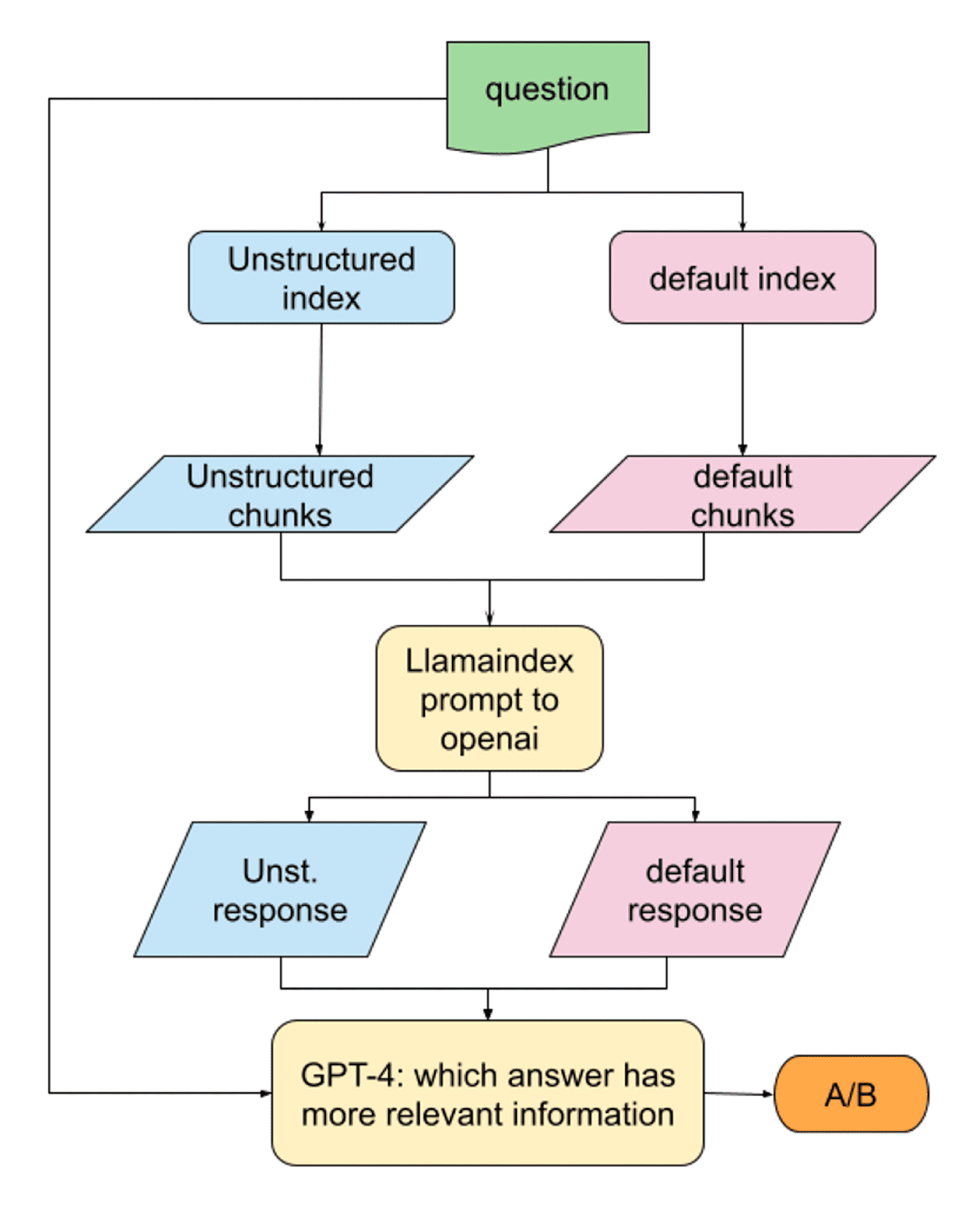
Figure 2: RAG Evaluation Workflow
The Results
Based on an evaluation of 68 documents, GPT-4 concluded that the response with Unstructured chunking was more relevant two-thirds of the time. The following example illustrates how Unstructured chunking improves the response:
Question: What is the purpose of the Fresno-Merced Future of Food (F3) coalition?
Unstructured Chunking:
The Fresno-Merced Future of Food (F3) coalition aims to integrate technology and skills into the region’s agriculture industry to improve productivity and job quality for existing farmworkers, and foster a more resilient and sustainable food system. The coalition brings together various stakeholders, including universities, industry leaders, regional philanthropy groups, and local government, to support the economic development and transformation in one of the nation’s most significant food-producing regions. It also seeks to drive change towards a more innovative, equitable, and resilient agricultural industry, particularly focusing on underserved communities, including those identifying as Black, Indigenous, and people of color (BIPOC).
In order to achieve these goals, the F3 coalition aims to accelerate the pace of agrifood tech innovation in the region. Some of its expected outcomes include attracting $250M in private investment, creating or filling approximately 10,000 jobs with an average wage increase of 60%, thereby lowering the unemployment rate in the five related counties by 1.2%, and employing approximately 7,000 BIPOC community members, which would represent 70% of total created jobs. Additionally, the coalition expects to contribute approximately $500M to GDP annually after four years, increasing the annual GDP growth rate from ~2.1% to up to 3.0% after four years.
Sources: F3_Fresno_Merced_Future_of_Food.pdf.json (pg. 1, 2, 6, 8, 9); Build-Back-Better-Awardee-Digital-Booklet.pdf.json (pg. 5).
Standard Chunking:
The goal of the Fresno-Merced Future of Food (F3) coalition is to develop and commercialize climate-adaptive food production approaches that are needed both locally and across the globe. By catalyzing the growth of small-scale farm and food industries and bolstering innovative talent development, the F3 Coalition aims to increase the overall regional GDP, attract substantial private investments, and create or fill more than 10,000 higher-paying jobs within four years.
According to sources, the coalition seeks to promote inclusive innovation and commercialization within the agrifood technology and engineering cluster, aiding small farmers and entrepreneurs alongside multinational companies. A significant number of these opportunities will be targeted towards BIPOC (Black, Indigenous, and People of Color) and underserved community members.
The F3 projects also aim to contribute greatly to economic growth, addressing the long-standing economic, agricultural, and climate challenges of the region. The coalition will gather data from industry leaders, community college faculty, and mobile food vendors to refine their strategies and projects. These initiatives are hoped to attract substantial private investments and potential industry partners.
Sources: F3_Fresno_Merced_Future_of_Food.pdf
In the evaluation output, GPT-4 states “Answer A seems to have more detailed descriptions, includes more specifics, and provides a comprehensive answer to most questions”, further notes that “Answer A often went beyond just stating the goal of many projects to include details on key objectives and citations from multiple sources, indicating comprehensive research”, and concludes that “Answer A consistently provided more specifics, relevant data, and broad details, making it the better answer more often”.
The RAG system produces higher fidelity responses with Unstructured chunking because the chunks have more consistent semantic meaning, resulting in more relevant query results. This is especially useful when information the user is querying is scattered in multiple places in the same document or across multiple documents in a collection. Chunks that are tighter semantically means less of the results are wasted on overlapping character-based chunks, allowing the query results to pull in content from different parts of the document. An additional benefit of this is that the RAG system can compile more citations for a response. In the example above, the RAG output with Unstructured chunking has six citations, whereas the standard output has only one citation.
Try It Out!
Ready to give our chunking a try? Grab an API key and pass in -F 'chunking_strategy=by_title' to your API request to try out our title-based chunking strategy. And, as always, jump into our Community Slack if you have questions or feedback.


