
Authors

Step 1: Prepare your data for RAG
About 90% of the data most companies have is unstructured data—not numerical, not in a database, but documents, emails, manuals, slide decks, contracts and the like. Preprocessing this type of data to make it available for retrieval can be a challenging task. Unstructured Platform significantly simplifies this process - it can connect to any data sources you may have in your organization, preprocess the data from those sources making it RAG-ready, and upload the results into your database of choice so that your enterprise knowledge can be retrieved when needed.
We’ll be preprocessing data with Unstructured Platform’s no-code UI. To start, you’ll need to sign up on the Unstructured For Developers page. Once you have signed up, you can log into the Platform and start using it for free for the first 14 days and up to 1000 pages per day. Learn more in the documentation.
Data Source: PDFs in AWS S3
In this tutorial, we’ll work with annual 10-K SEC filings from Walmart Inc., Chevron Corporation, and Costco Wholesale Corporation for the 2023 fiscal year. These reports offer a deep dive into a company's financial performance, including financial history, statements, earnings per share, and other crucial data points. The documents are originally in PDF format and we have them stored in an Amazon S3 bucket.
If you’re new to Amazon S3, Unstructured Platform’s documentation offers videos that teach you how to:
Follow the instructions in the videos to create an AWS account, get your authentication credentials, and create an S3 bucket, if you don’t already have a bucket that you could use.
Upload your documents into your S3 bucket. For example, you can grab some SEC filings for the same companies that we used in this tutorial:
S3 Source Connector in Unstructured Platform
To make the documents in your S3 bucket RAG-ready, we need to preprocess them with Unstructured Platform, and the first step is to connect Unstructured to the source of the documents by creating a source connector.
Click Connectors on the left side bar, make sure you have Sources selected, and click + New to create a new source connector.
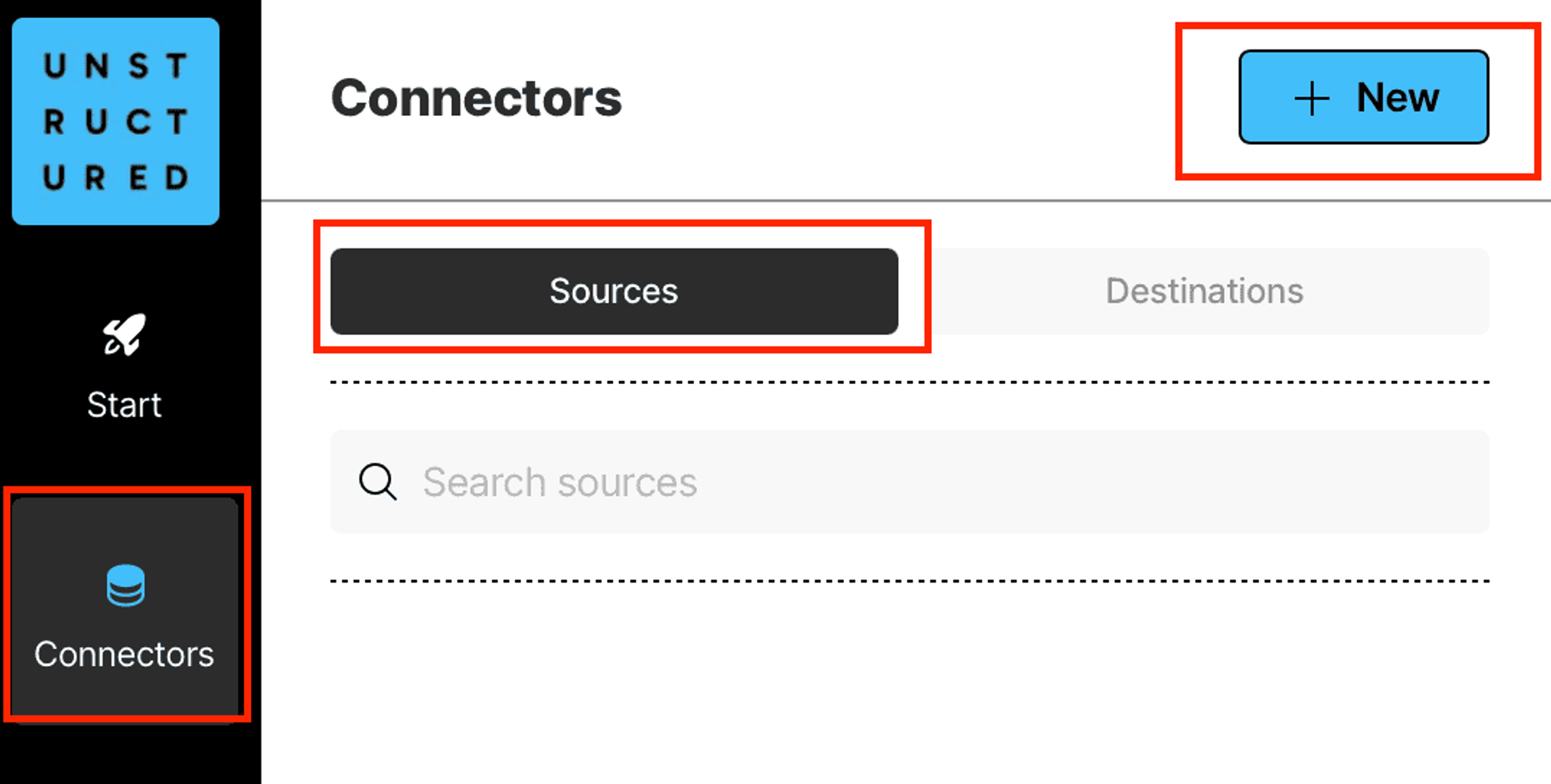
On the next page, give your source connector a name, and select Amazon S3 as a type:
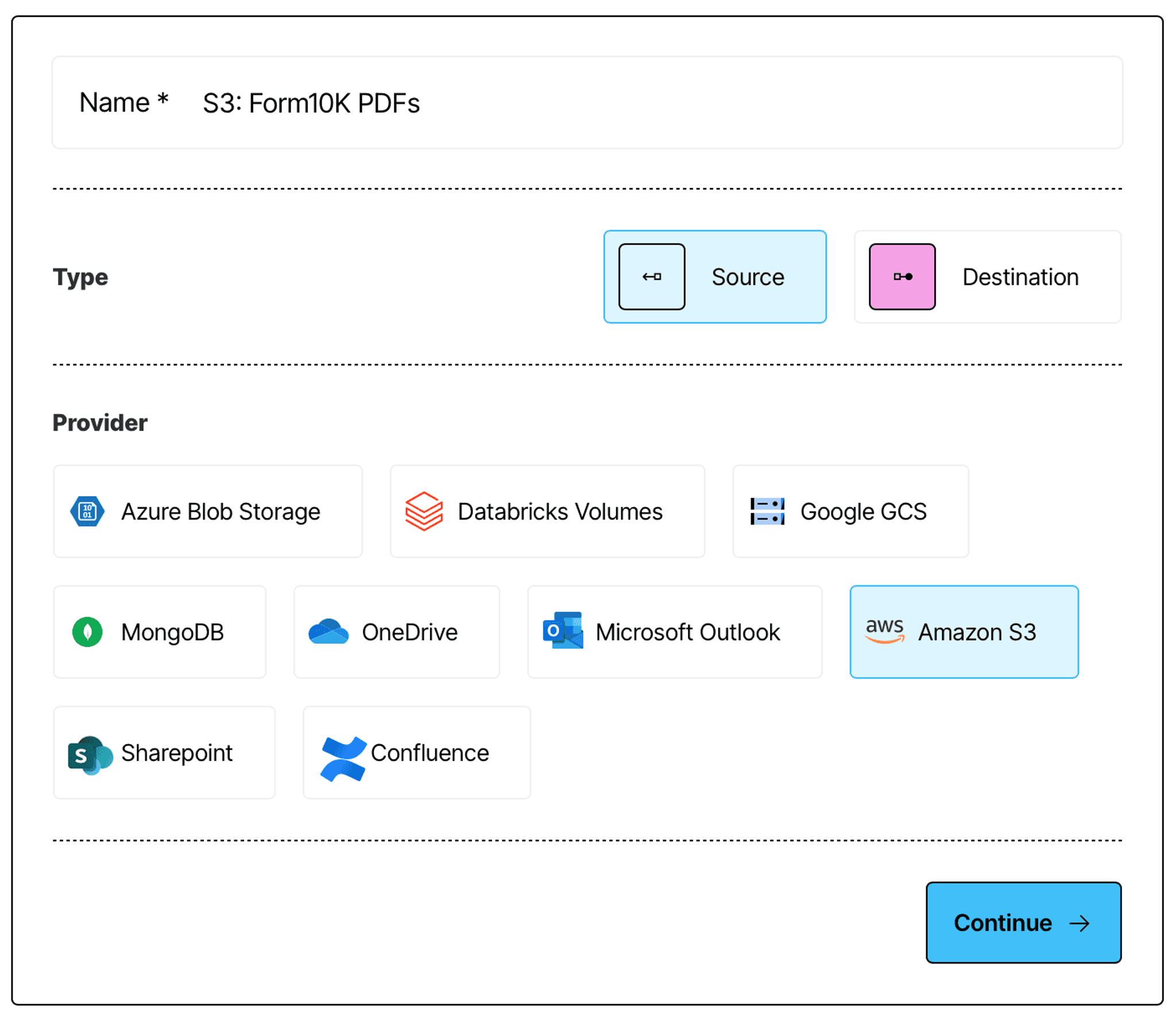
Finally, provide the name of the S3 bucket you want to connect to, and your authentication credentials to complete the connector setup:
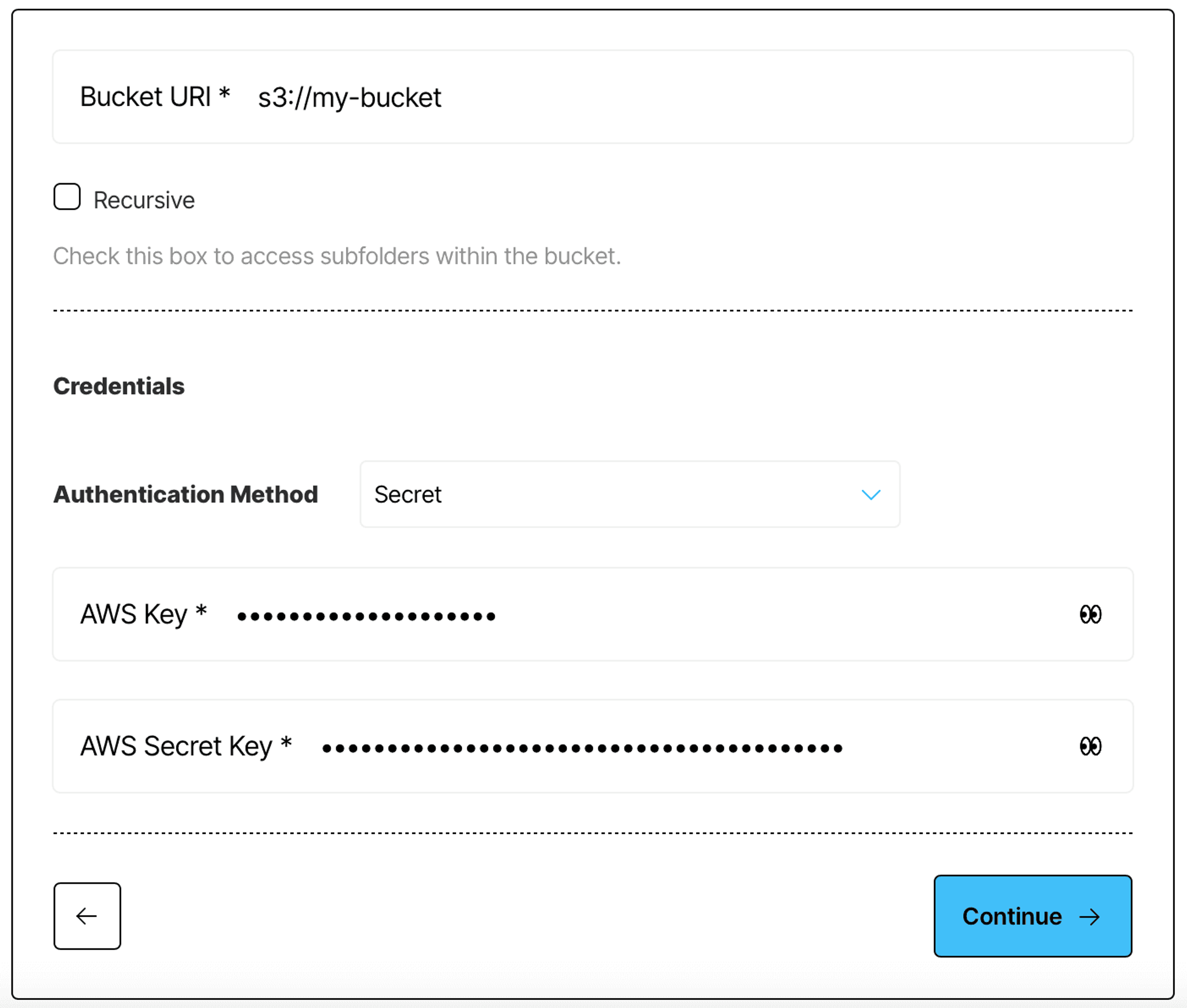
Once the setup is complete, Unstructured will check if it can access your S3 bucket, and will indicate it in the UI, you should see Success label next to your source connector. Now that we have a source connector, we need a destination connector - a database that will be used as a retriever in the RAG application. In this tutorial, we’ll use AstraDB by DataStax for this.
AstraDB Setup
Before we can write RAG-ready documents into AstraDB, we first need to create it.
Begin by creating an account on datastax.com by clicking Sign up for free. Log in to your account, and navigate to the Databases section:
Click Create Database to configure your new AstraDB database - choose Serverless (Vector) type, give it a name, and choose a region that is the closest to you:
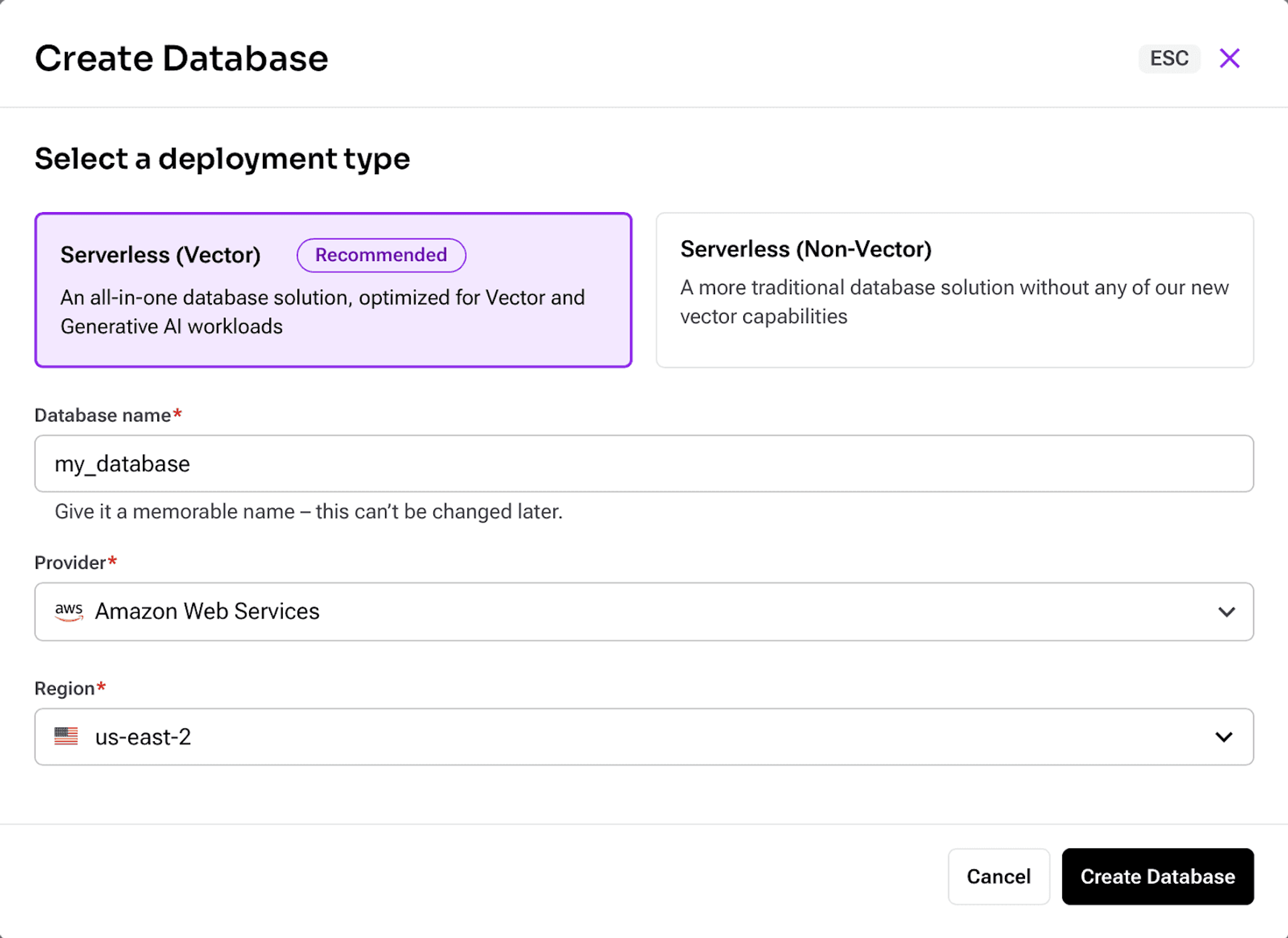
It will take a few minutes to initialize the database. Grab a cup of tea or coffee while you wait.
Once the database is finished initializing, locate your authentication details on the same page:
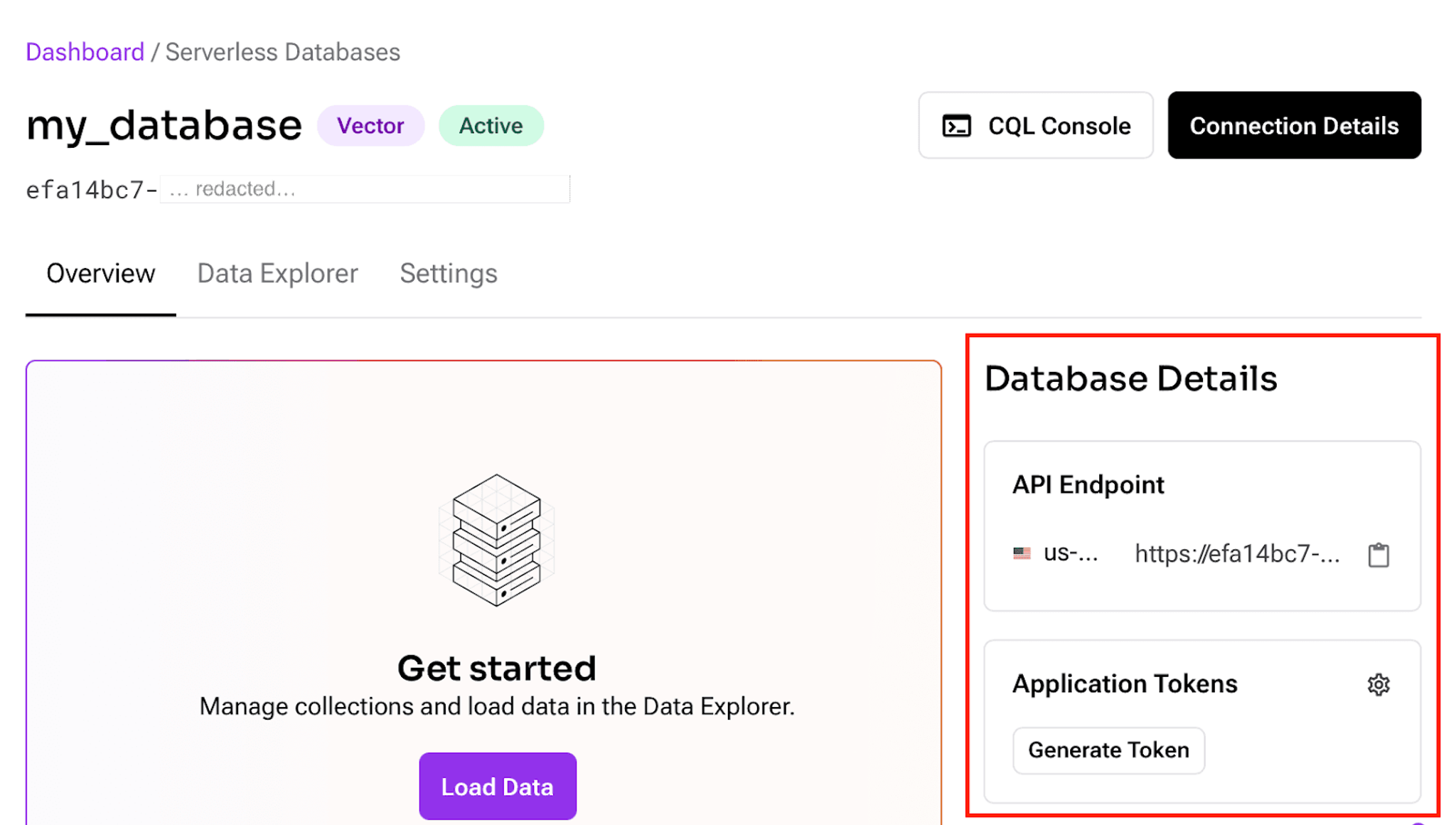
Copy the API endpoint and save it somewhere, then click Generate Token under Applications Tokens. In a popup that opens, copy your unique application token and save it as you won't have access to it after closing this dialog.
As a final step, you need to create a collection within your AstraDB database. To do so, navigate to the Data Explorer tab, and click Create Collection:
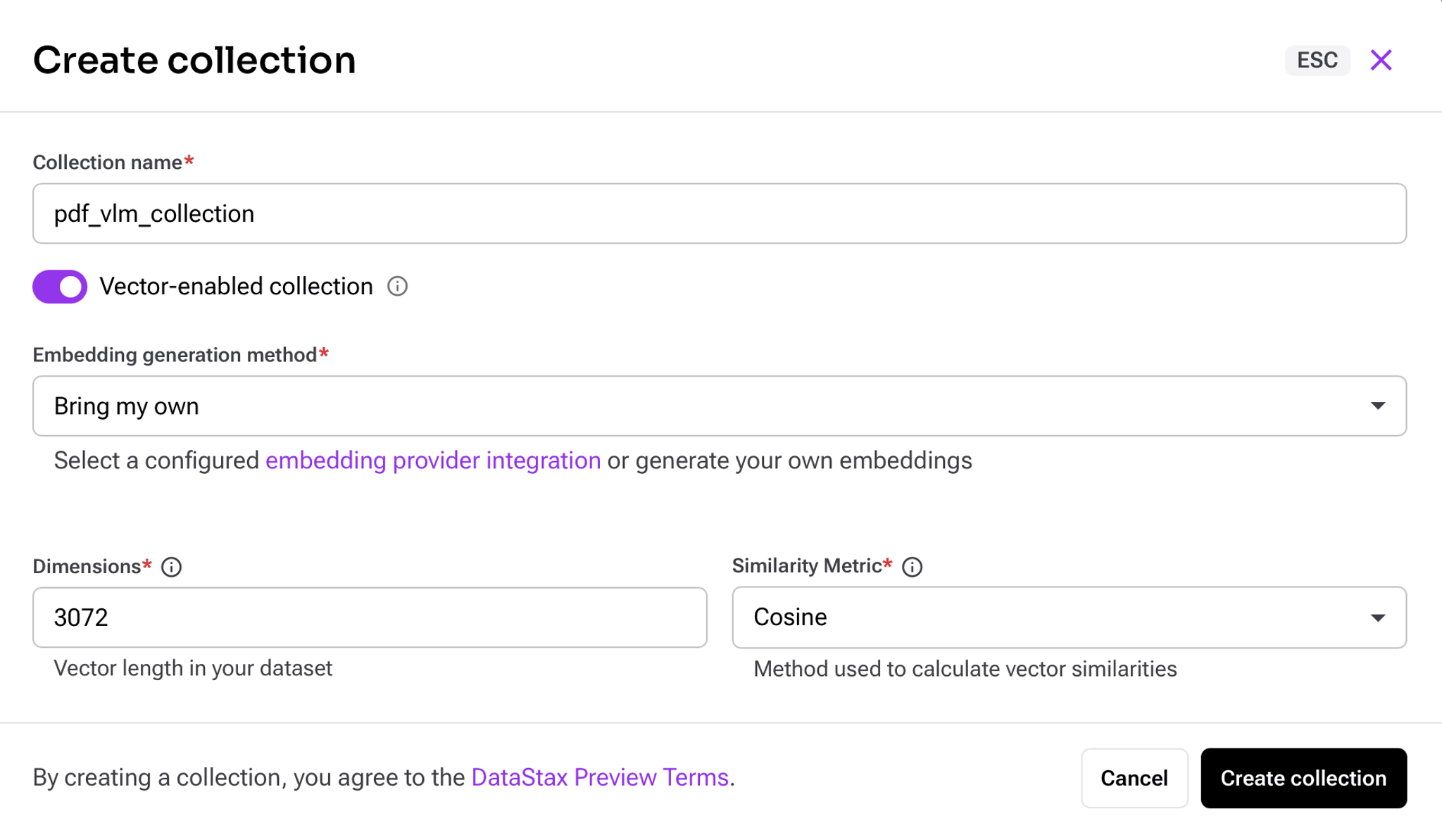
Give your collection a name, then in the embedding generation method choose Bring my own as we will generate the embeddings automatically with Unstructured Platform. The vector embeddings will be used to perform similarity search in the RAG application to find documents that have their embeddings the closest to the embedding of the user question.
Another important field here is Dimensions. Different embedding models generate outputs of different dimensions. When we set up a data processing workflow in Unstructured, we’ll go with a pre-configured setup that produces embedding vectors that have a dimension of 3072, so that is the number you’ll need to specify here.
Creating a collection will take a few seconds. Once it’s done, we can add it as the destination in the Unstructured Platform.
AstraDB Destination Connector in Unstructured Platform
Setting up a destination connector in Unstructured Platform is very similar to how you set up your S3 source connector. Navigate to the Connectors tab on the left side bar, this time make sure you have Destinations selected, and click + New to create a new destination connector.
Give your destination connector a name, and select AstraDB as the destination type:
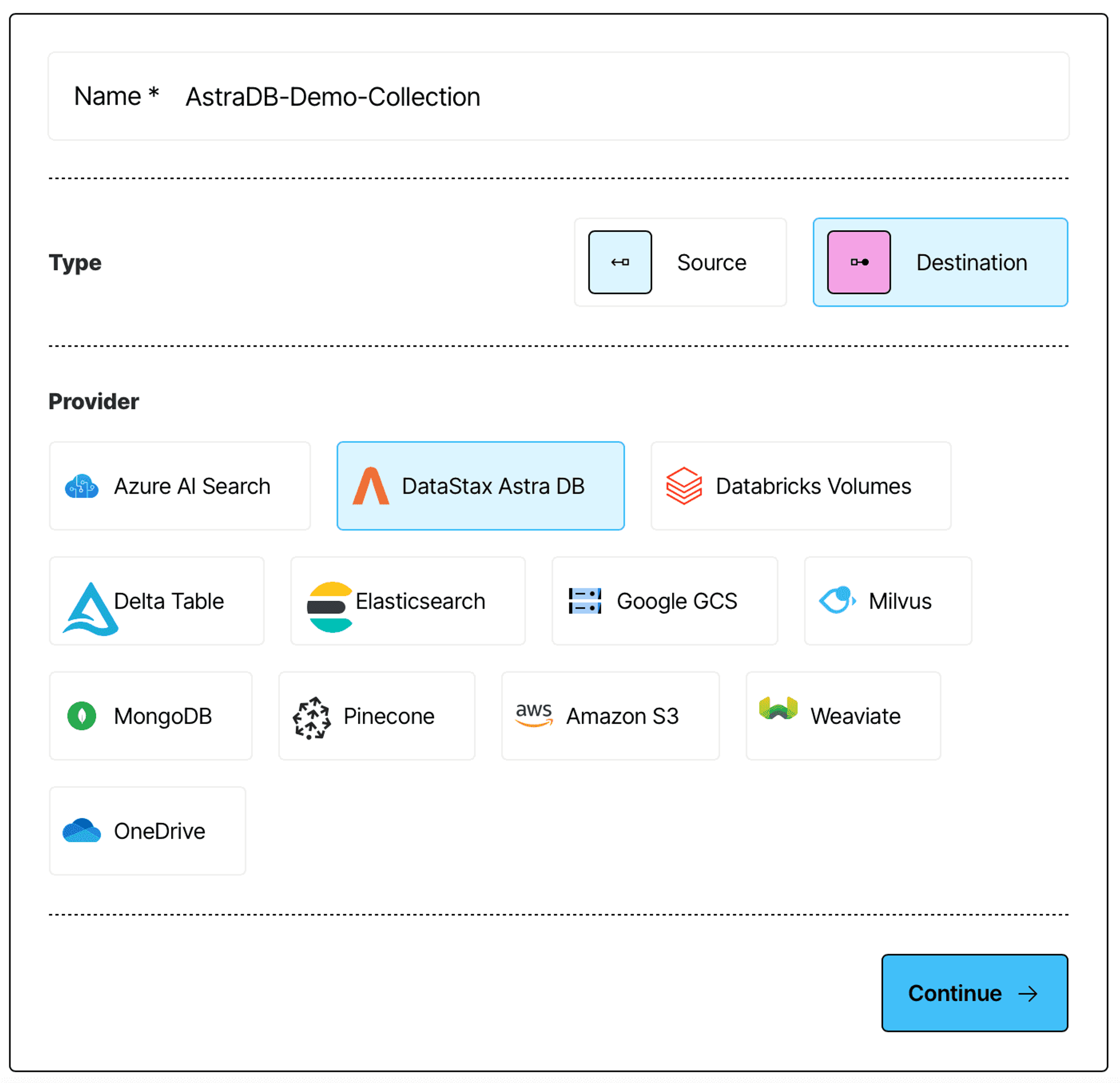
Next, provide the name of the collection you have just created (you can leave the rest as is):
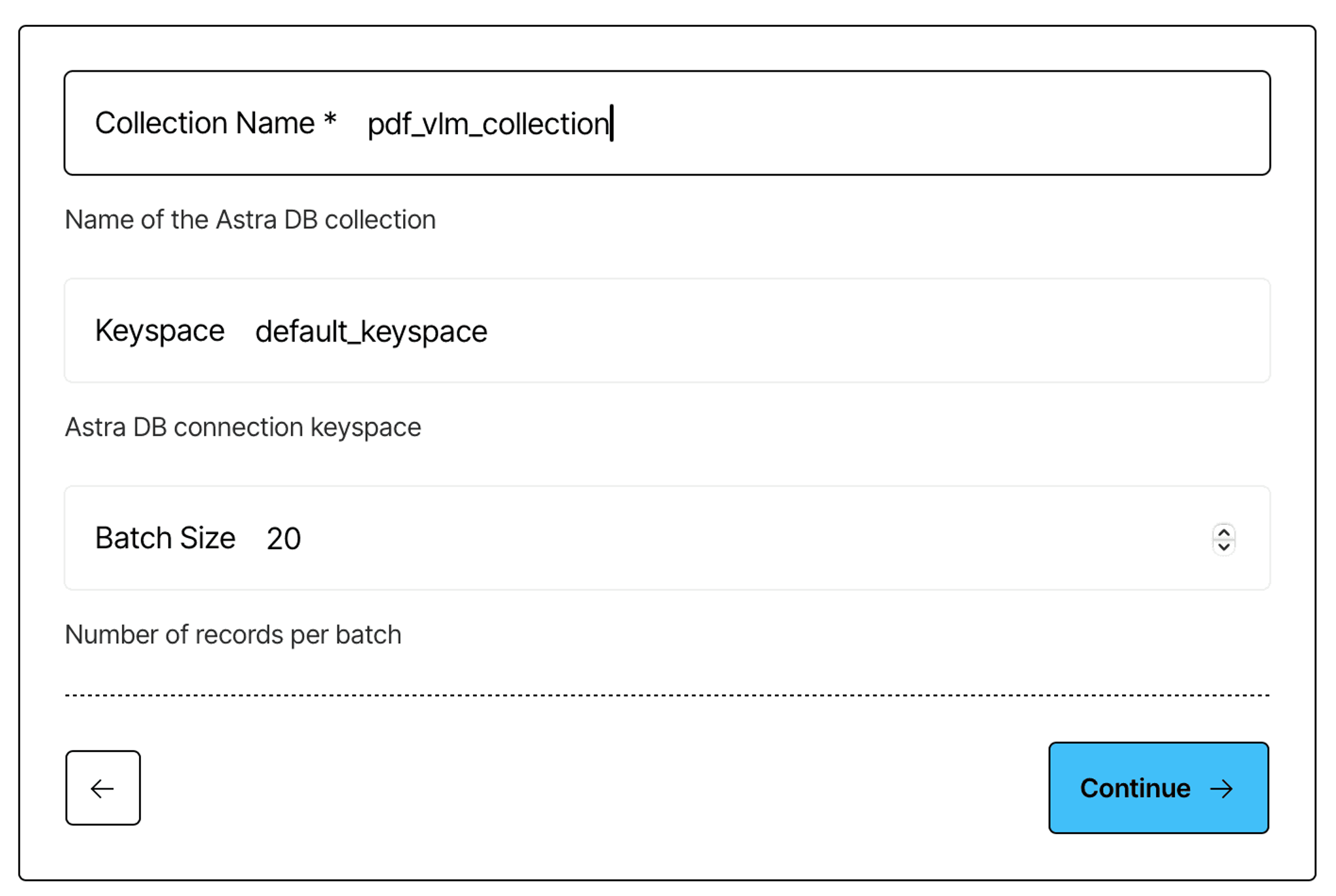
Finally, provide your authentication credentials that you should’ve saved when configuring your database:

Once you click Save and Test, Unstructured Platform will confirm that it can indeed write documents into your collection, and you should see a Success label next to your new destination connector.
Data Processing Workflow in Unstructured Platform
Now that you have your documents in an Amazon S3 bucket, and Unstructured Platform can connect to it, and you have an AstraDB collection, and Unstructured Platform can write into it, the only thing that’s left to do is to configure a data processing workflow that will grab PDF documents from your S3 bucket and make them RAG-ready in AstraDB. To do so, navigate to the Workflows tab on the left side bar, and click New workflow.
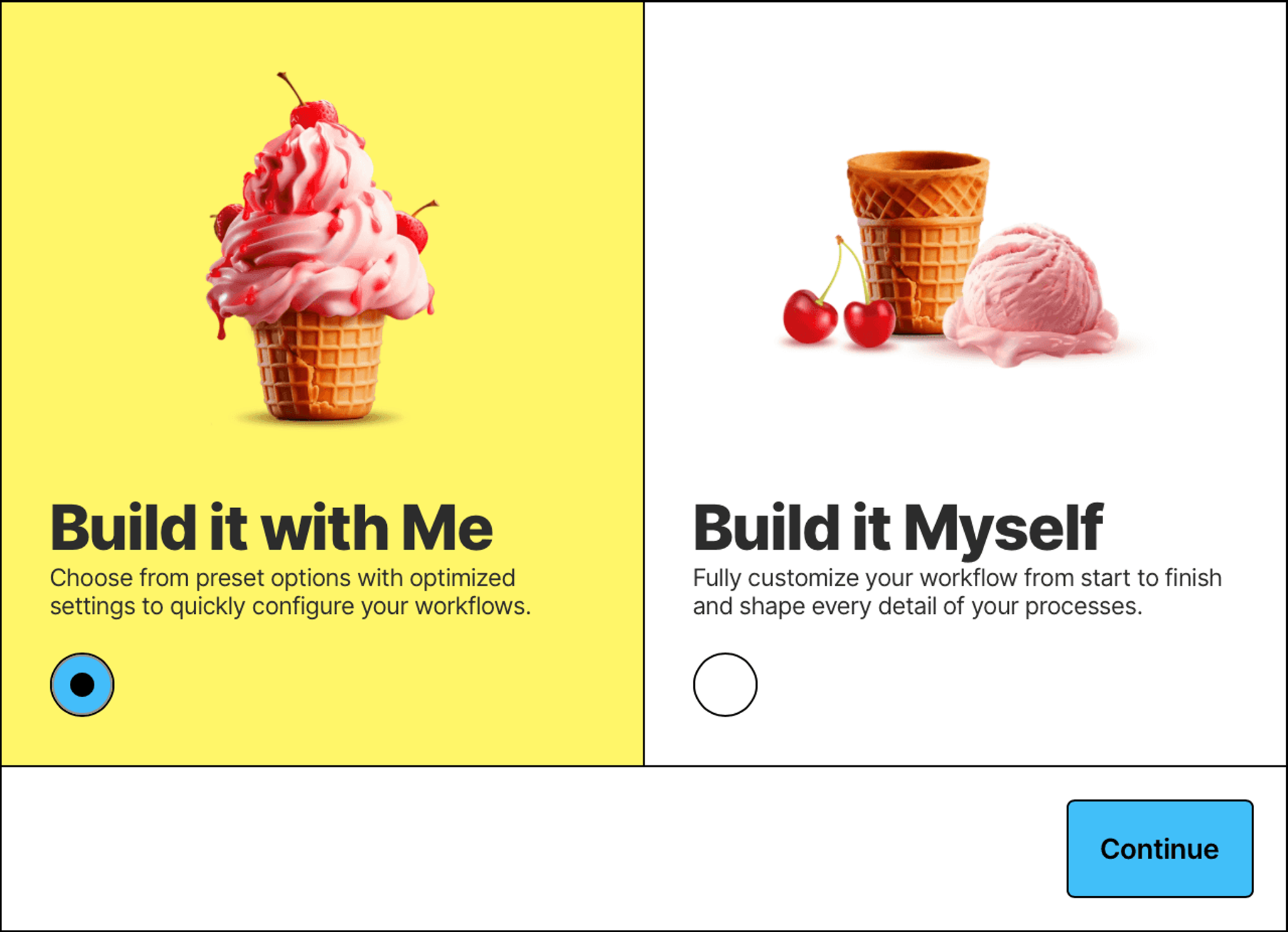
Switch to the Build it with Me option to set up the workflow with pre-configured options that are optimized to fit a wide range of use cases:
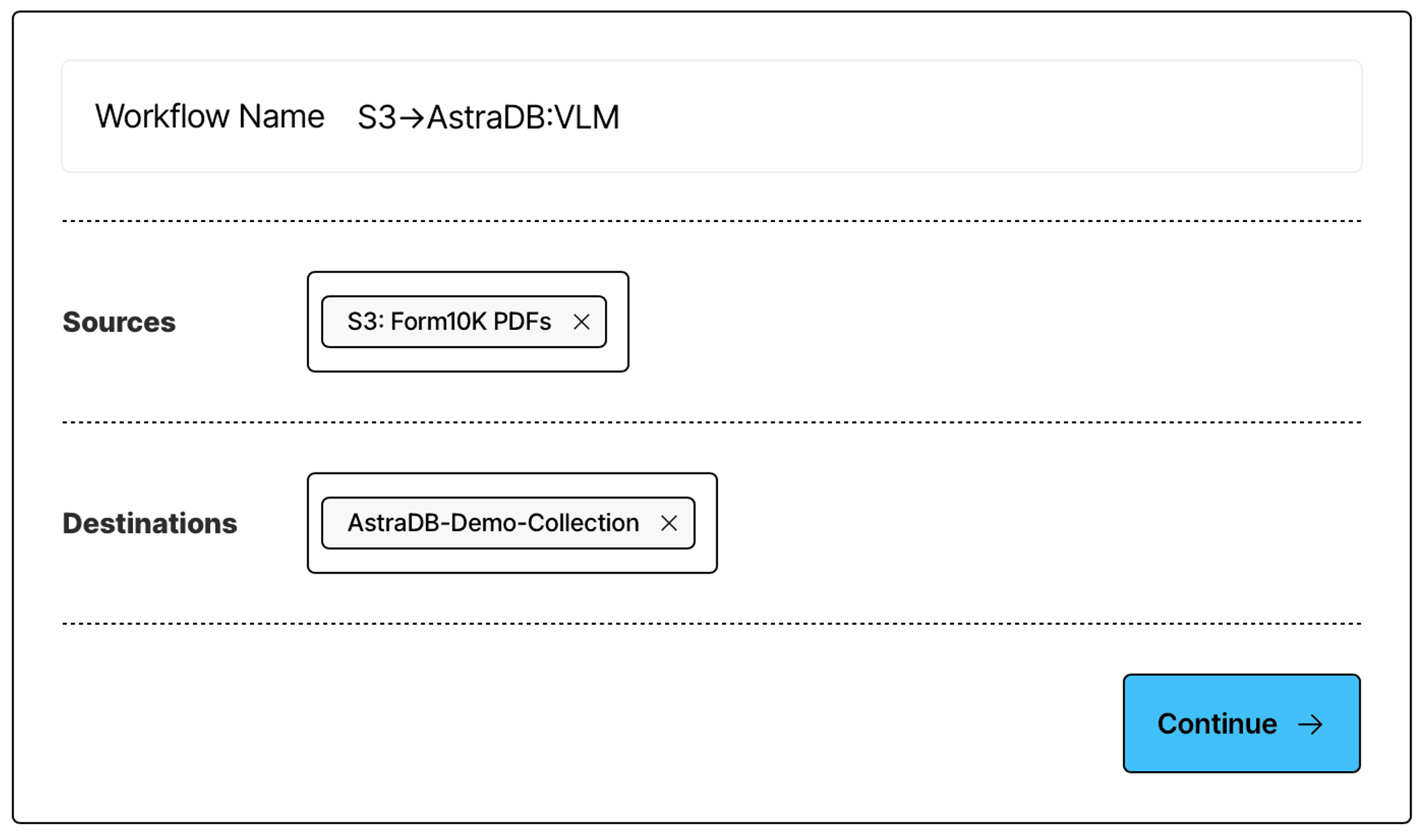
Give your workflow a name, and specify the source and destination connectors that you have just created:
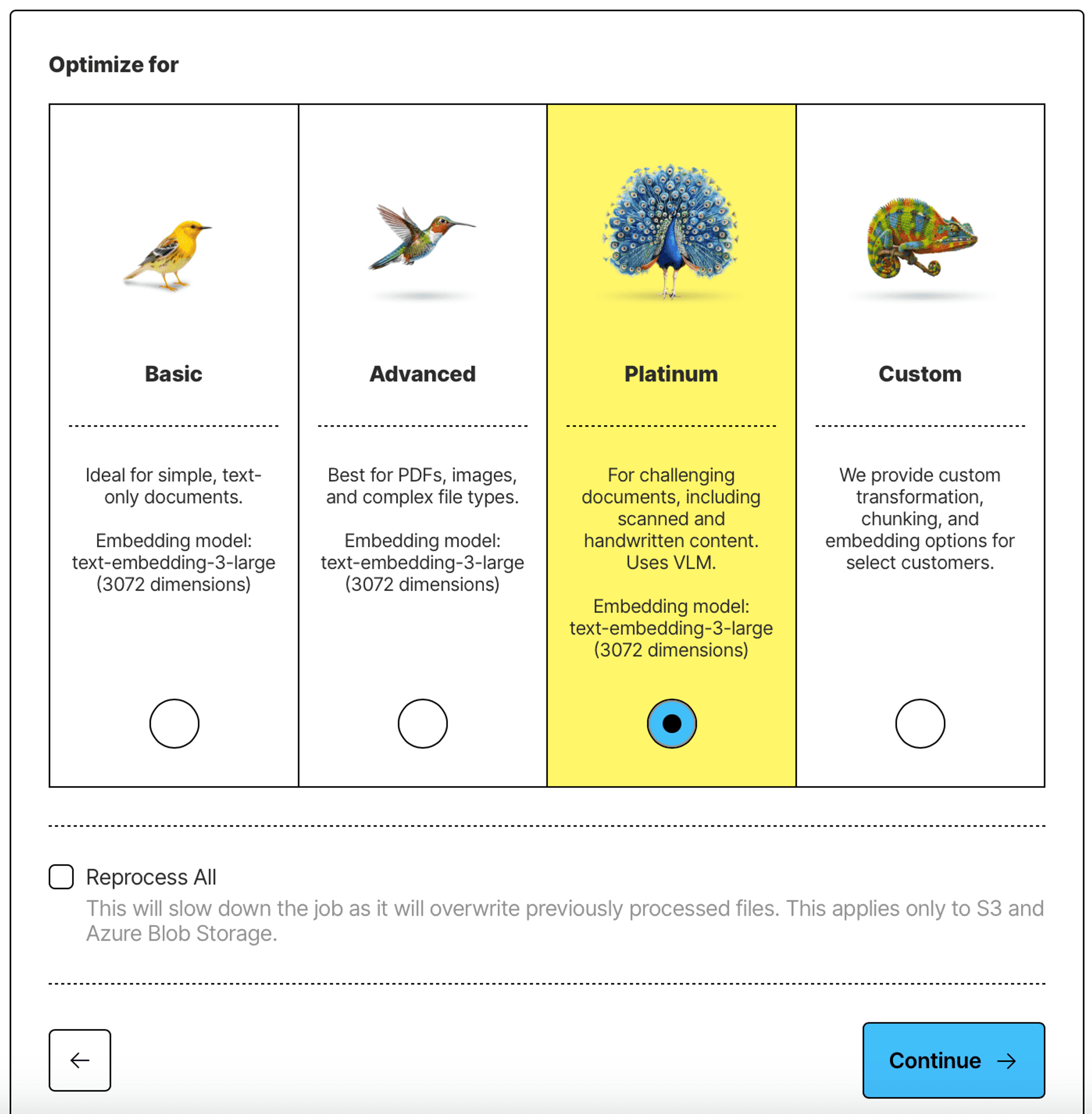
Choose the Platinum strategy to make sure that all of the content is extracted from your PDFs, no matter how complex the documents may be:
Optionally, set up a schedule for the workflow, if you intend to continuously add documents to your S3 bucket, and want the AstraDB collection to stay up to date. In this tutorial, we don’t add any schedule:

Once you finish creating your workflow, find it in the list of workflows, and click Run.
This will launch a data processing job that will ingest documents from your Amazon S3 bucket, extract all of the content from those documents, chunk them into smaller pieces using Unstructured smart chunking strategies, generate a vector embedding for each of the chunks, and upload the results into AstraDB collection, so that you can build your RAG application on top of it.
Wait for the job to complete - this may take a few minutes, depending on how many documents you have in your S3 bucket, and how large and complex they are.
Once the job is finished, you can build your own custom RAG application, no code required.
Step 2. Create a Langflow RAG Application
Before we build a RAG application, we need to do one more thing.
Obtain OpenAI API key
We’re going to need an API key from OpenAI. There are two reasons for this:
- We’ll be using an LLM from OpenAI to generate answers to user questions
- We’ll be generating vector embeddings for user questions to do similarity search and find documents to provide the LLM as context. Unstructured Platform has generated vector embeddings for your data with an embedding model from OpenAI, specifically text-embedding-3-large. We’ll need to use the exact same model to embed user queries for the similarity search.
To get an OpenAI API key, follow the instructions in the OpenAI Developer QuickStart.
Once you get the OpenAI key, you’re ready to build!
Langflow Application
Go back to datastax.com, log in, if you need to, and switch from AstraDB to Langflow:
Click New Flow, and choose a pre-configured Vector Store RAG. This should create an application flow like the one below:
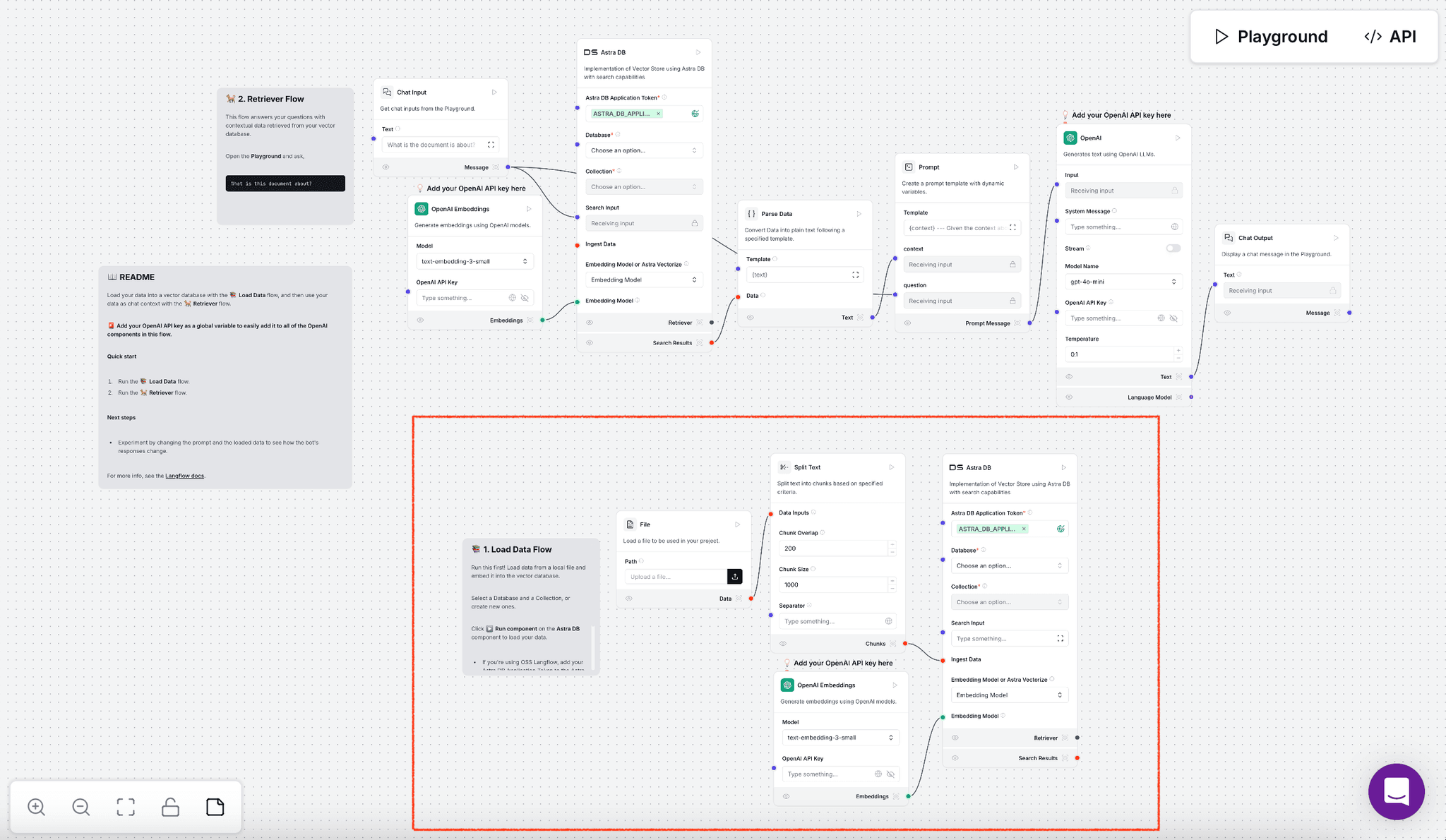
Delete the part that is highlighted in red - this is the data processing workflow that we have already set up in Unstructured Platform, so you don’t need to repeat it here.
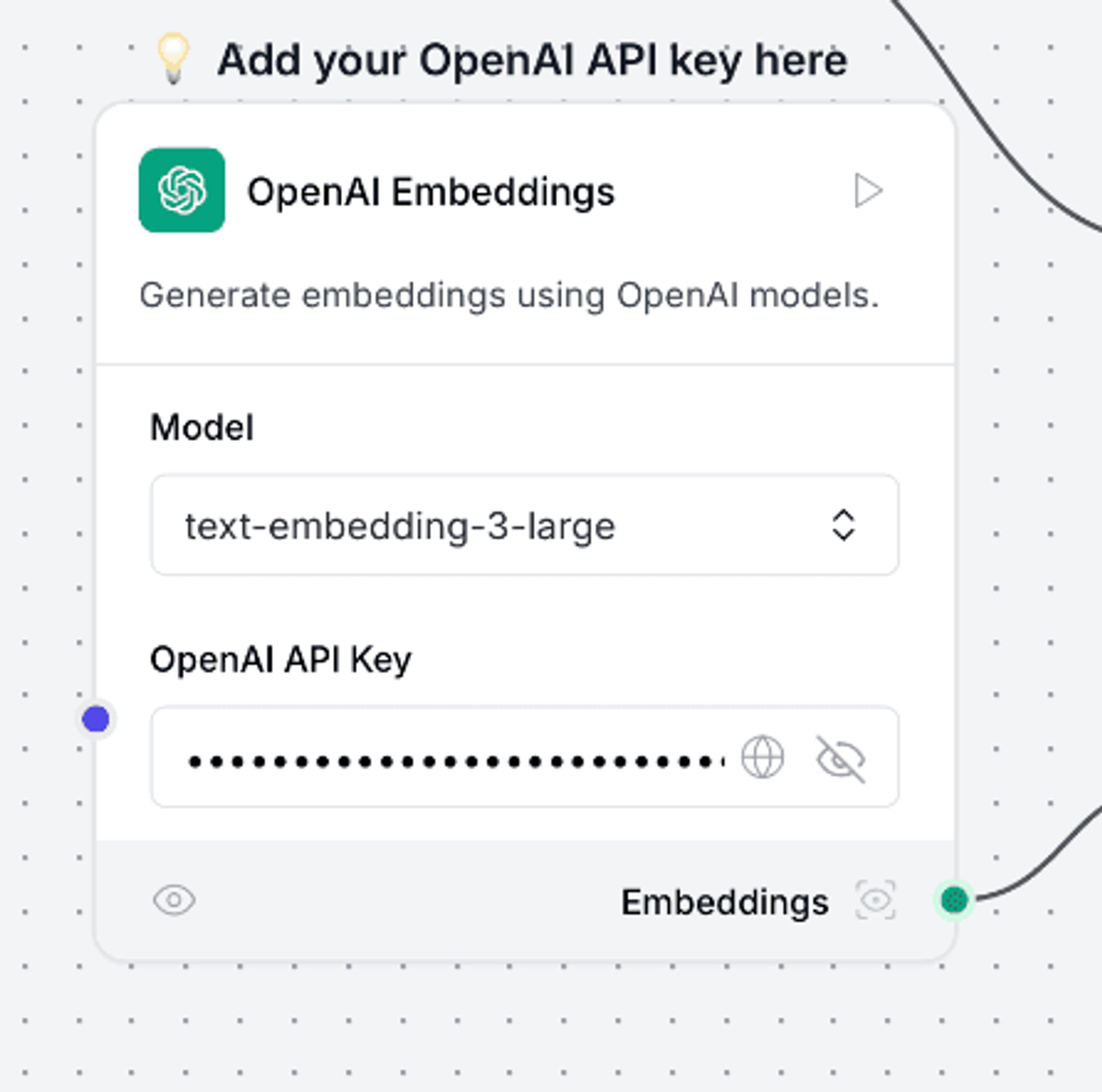
Add your Open AI API key to the step that generates an embedding for a user query, and change the model to text-embedding-3-large:
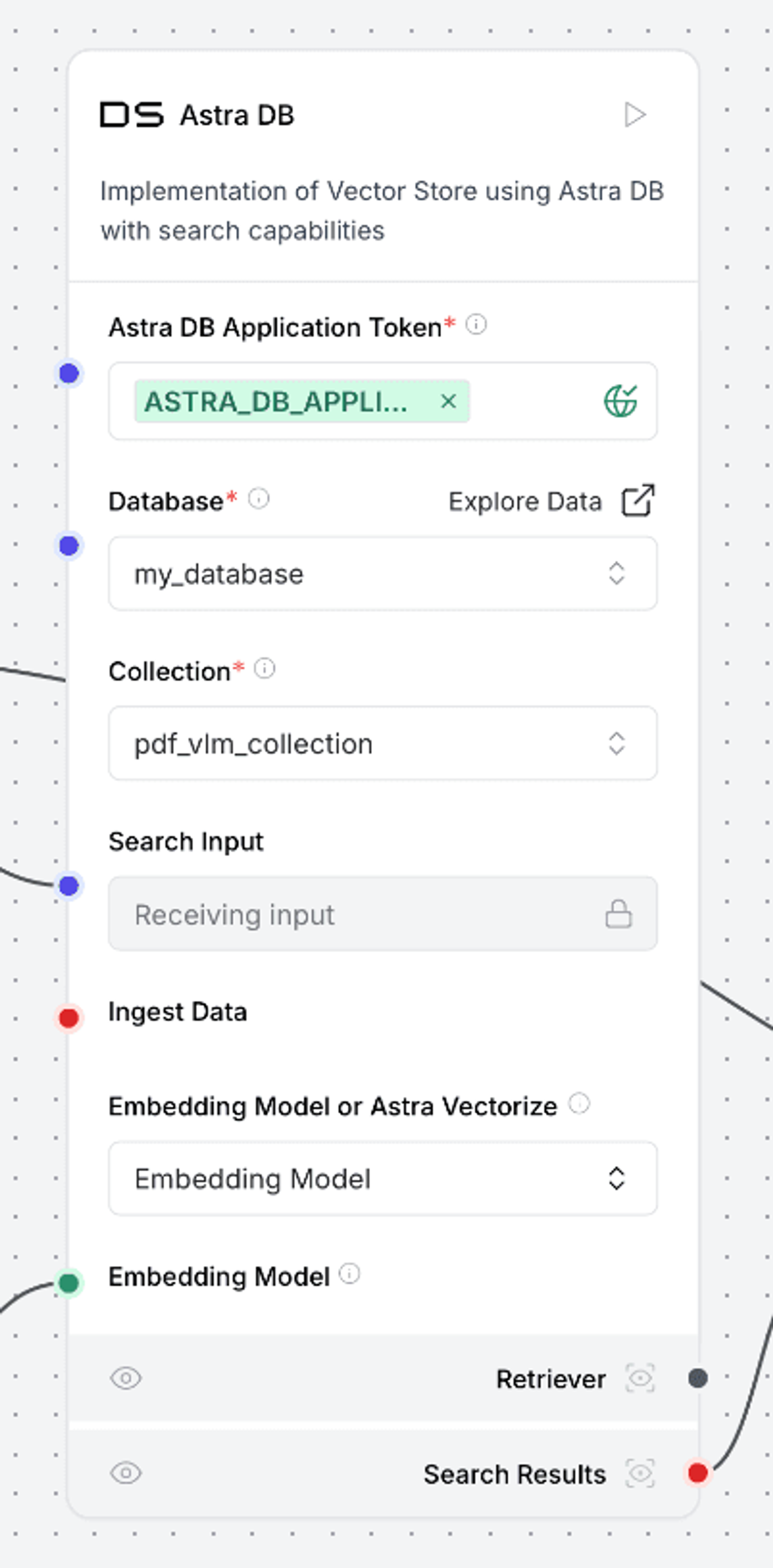
In the AstraDB step, specify your database and collection names:
Finally, provide your OpenAI API key once more to the step in the flow that generates the answer:
That’s it! You have now built a fully functional RAG AI assistant with absolutely no code. Let’s try it out!
Step 3: Talk to your data
To chat with your data, simply go to the Playground in your Langflow application:

This will open a chat UI where you can ask a question about your documents, and get a comprehensive answer, just like this one:
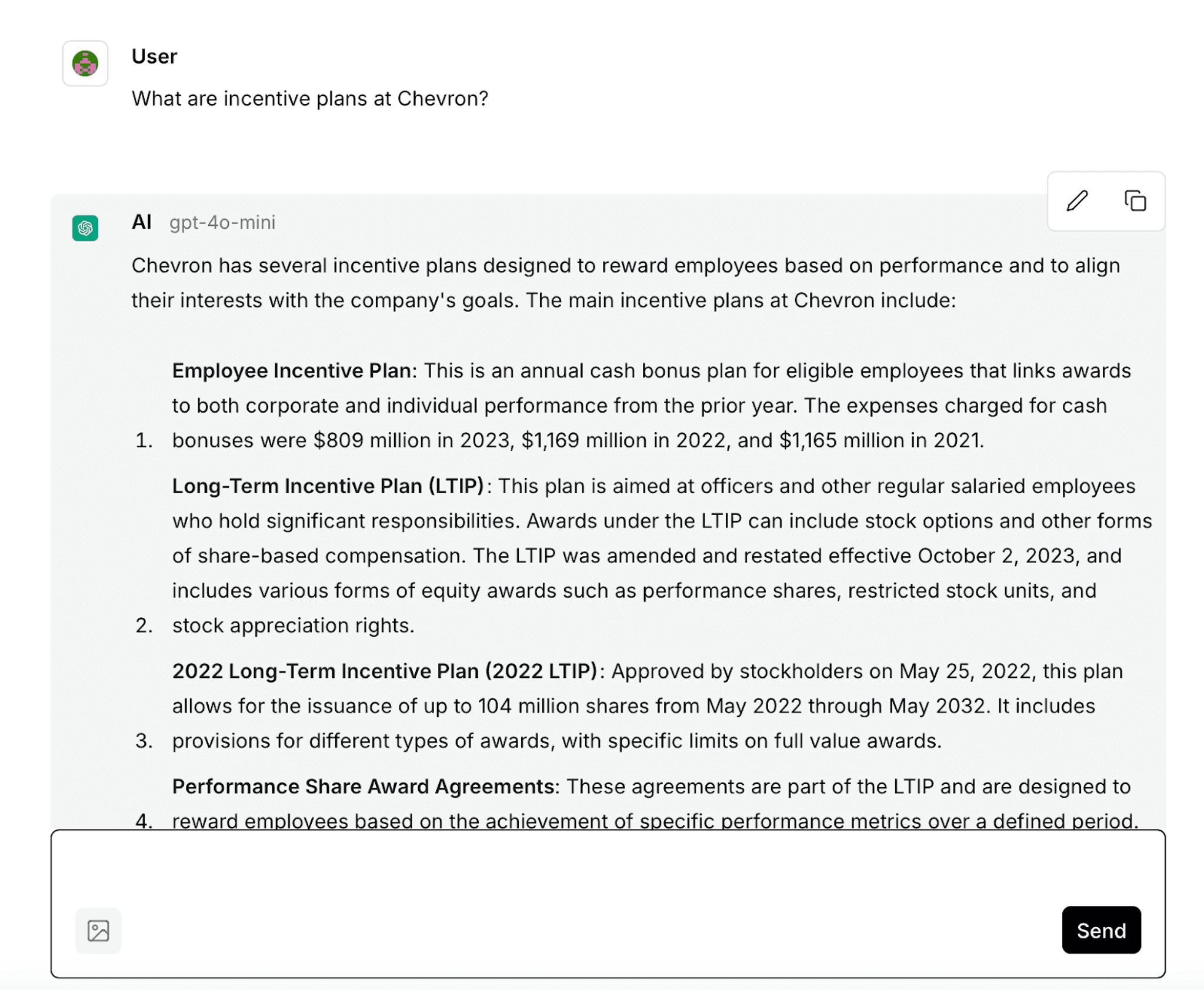
Congratulations on making it all the way through and building your own AI assistant for your data. Here are some next steps for you to consider:
- Customize the prompt template in Langflow to give more detailed instructions to the LLM. Make sure to preserve the {context} and {question} variables intact, as these are filled in automatically with the actual user question and retrieved documents.
- Try ingesting documents from a source other than Amazon S3. Unstructured Platform supports other source connectors, such as Azure Blob Storage, OneDrive, Confluence, SharePoint, and more! Find the full list of supported source connectors and detailed instructions on how to set them up in Unstructured documentation.
Need a more complex setup tailored to your unique enterprise needs? Book a session with one of our engineers to discuss how we can optimize Unstructured for your use case.


