Authors

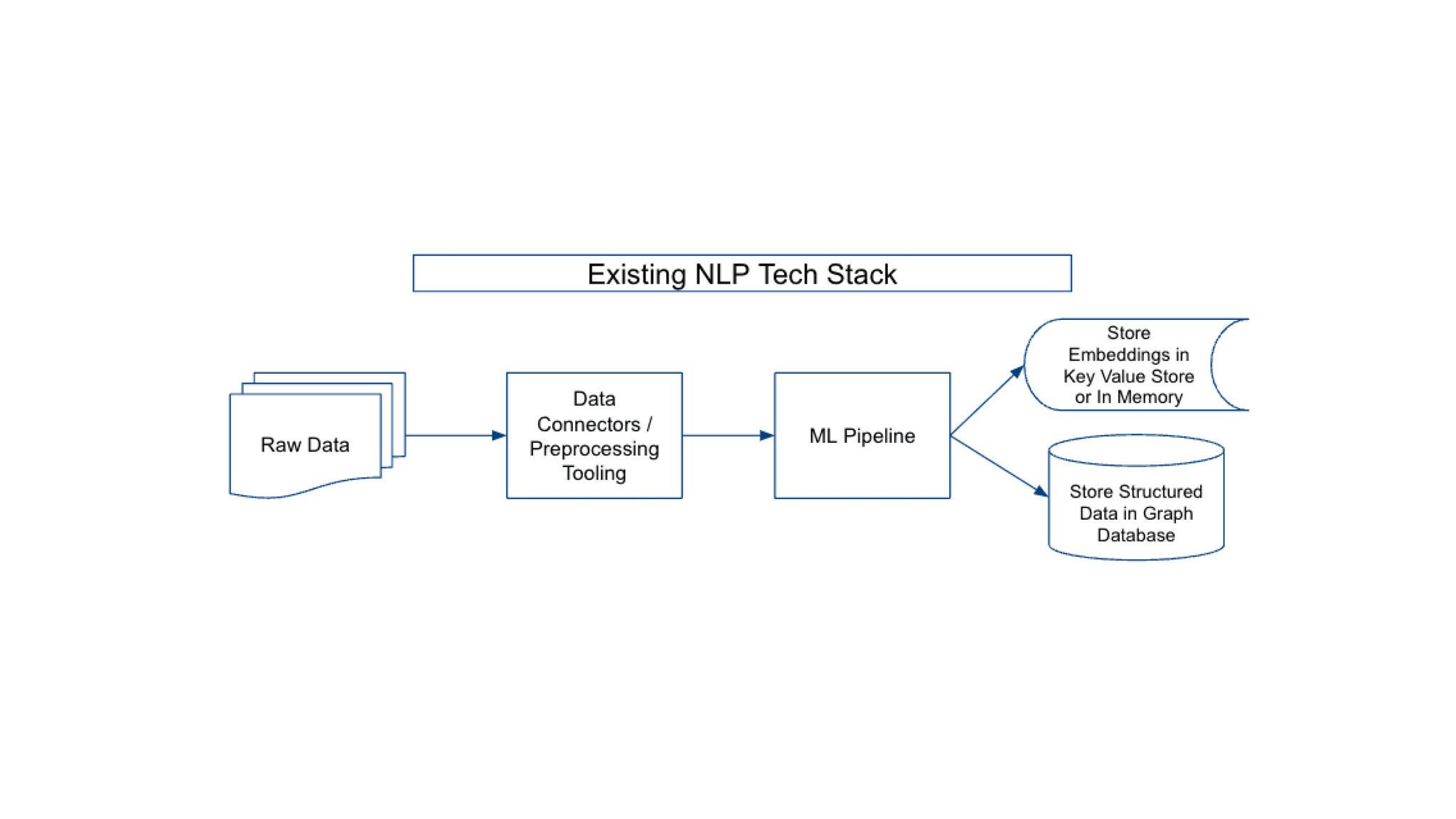
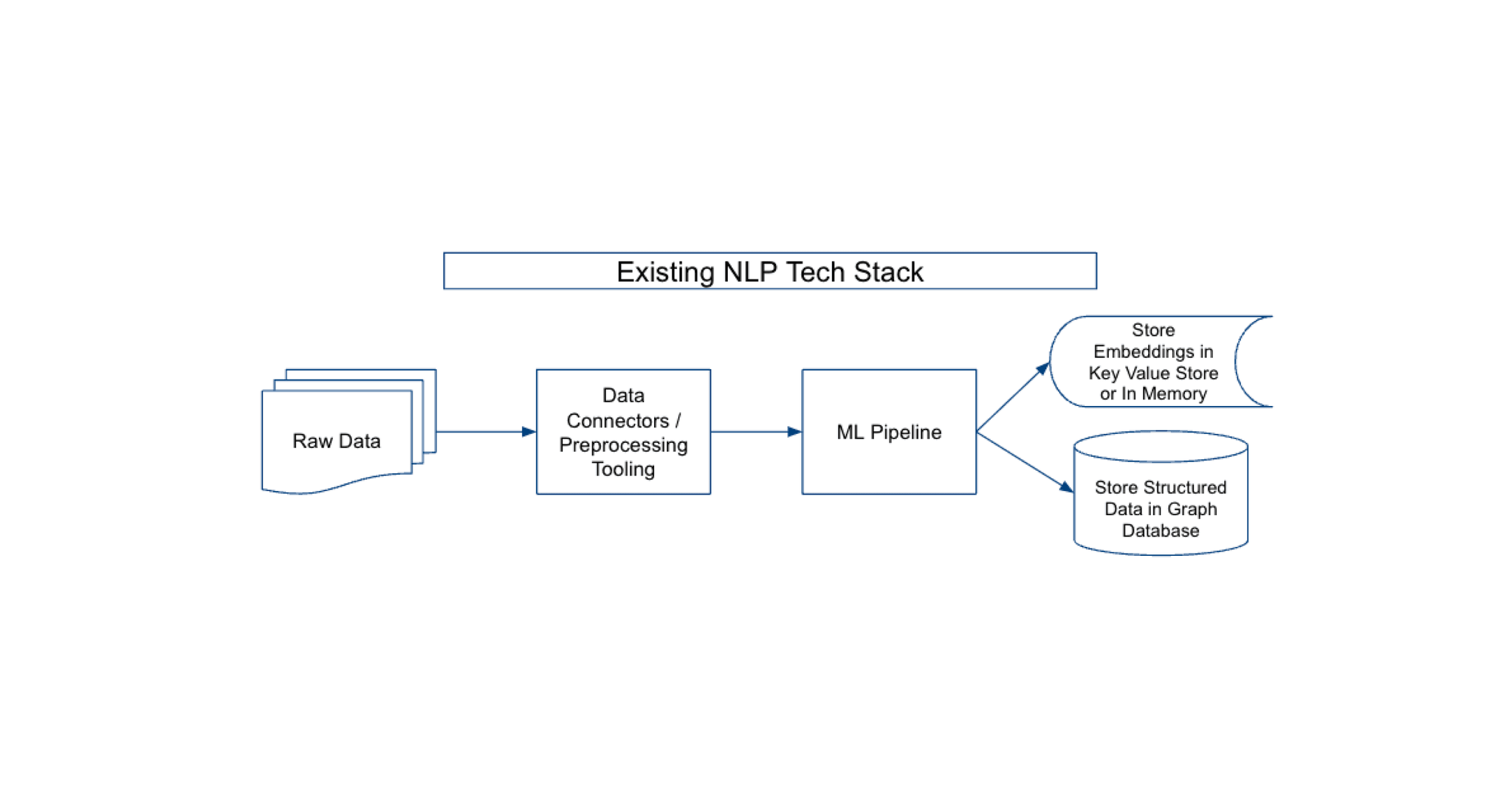
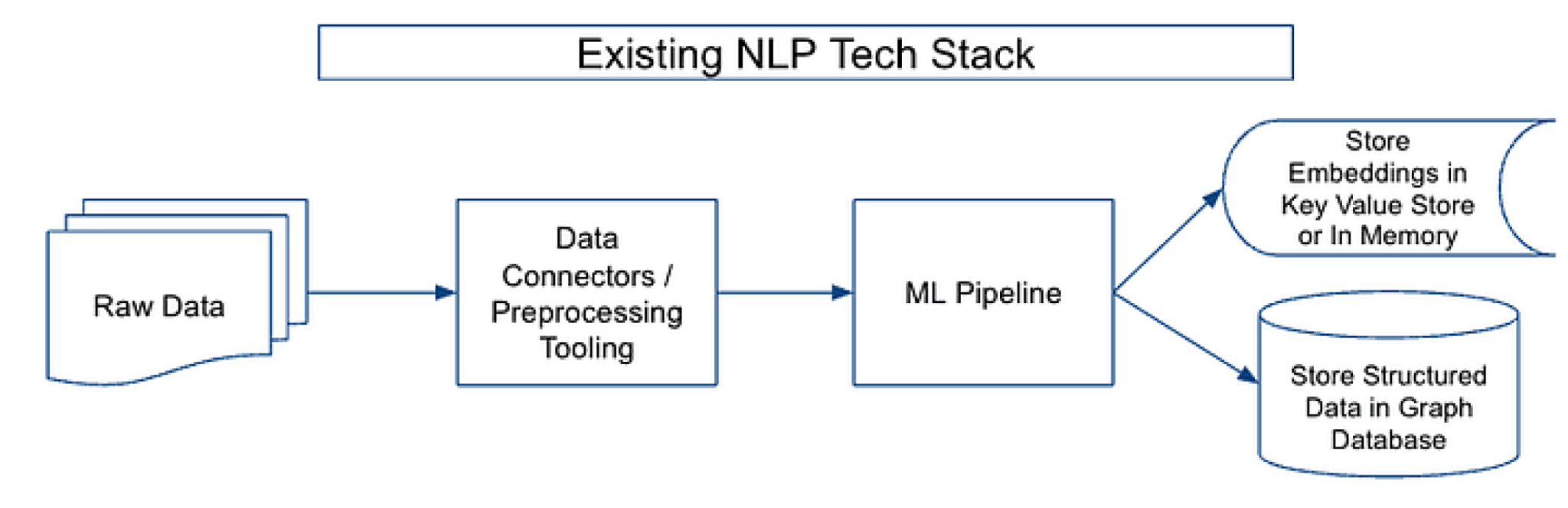
The Existing NLP Tech Stack
Until recently, NLP developers have relied on a tech stack optimized for NLP tasks like text classification, Named Entity Recognition, Named Entity Disambiguation. This tech stack generally consists of a data preprocessing pipeline, a machine learning pipeline, and various databases to store embeddings and structured data. This architecture worked well to generate vast amounts of triples, word embeddings, sentence embeddings, sequence-to-sequence outputs, language model probabilities, attention weights, and more. Developers typically would store these structured outputs in ElasticSearch, Postgres, or Neo4j databases, which they would utilize as a knowledge graph that users (or services) could query.
This architecture worked well for producing highly reliable structured data that could be deployed within enterprise systems to automate key processes (e.g. classify documents, find entities and the relations among entities, etc.). However, they struggled to gain widespread adoption because they were slow to stand up (required large amounts of labeled data and quite a bit of model fine tuning); expensive to run (often these architectures would have more than three dozen models in a pipeline/system); and the ingestion and model pipelines were brittle to new document layouts and data types.
The Emerging LLM Tech Stack
Since the fall of 2022, a new tech stack has begun to emerge that’s designed to exploit the full potential of LLMs. In contrast to the previous tech stack, this one is aimed at enabling text generation — the task that modern LLMs are most notably good at compared to earlier machine learning models. This new stack consists of four pillars: a data preprocessing pipeline, embeddings endpoint + vector store, LLM endpoints, and an LLM programming framework. There are several large differences between the older tech stack and the new one. First: the new tech stack isn’t as reliant on knowledge graphs that store structured data (e.g. triples) because LLMs such as ChatGPT, Claude, and Flan T-5 have far more information encoded into them than earlier models such as GPT 2. Second: the newer tech stack uses an off-the-shelf LLM endpoint as the model, rather than a custom built ML pipeline (at least to get started). This means that developers today are spending far less time training specialized information extraction models (e.g. Named Entity Recognition, Relation Extraction, and Sentiment) and can spin up solutions in a fraction of the time (and cost).
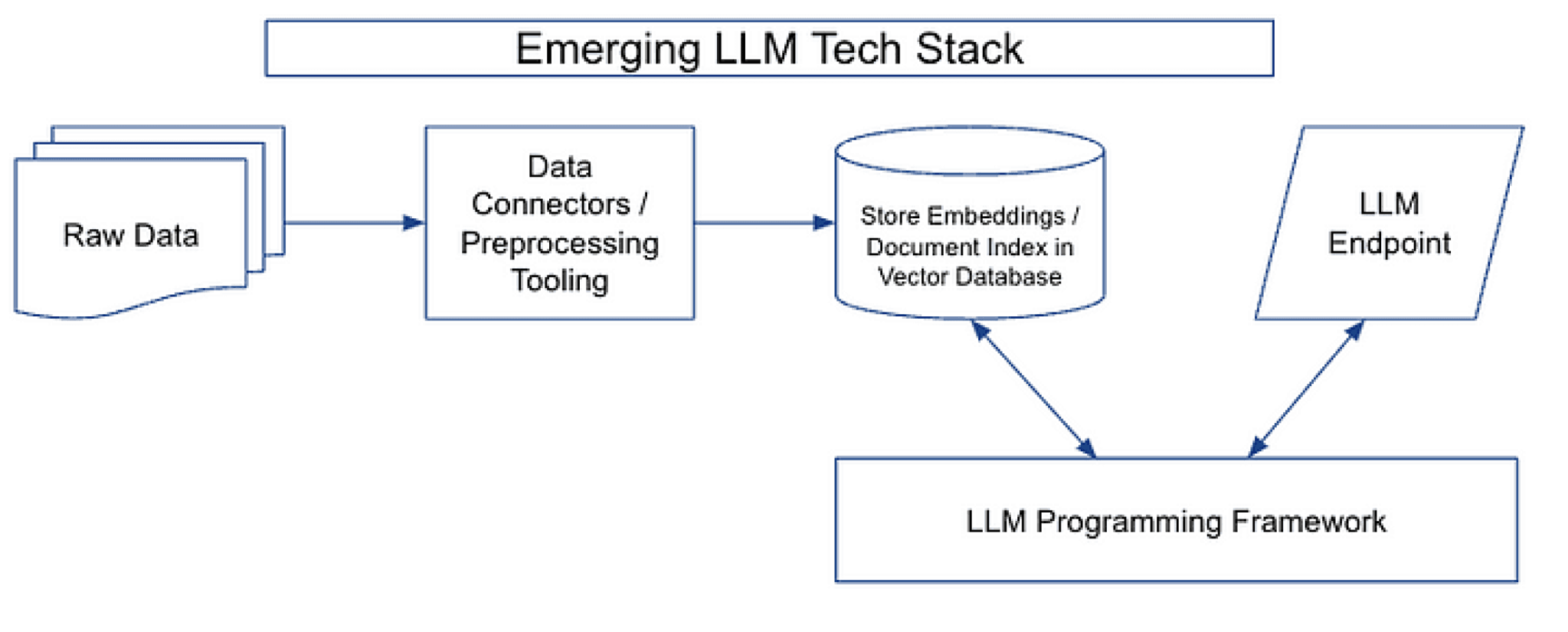
Data Preprocessing Pipeline: The first pillar of the new tech stack is largely unchanged from the older stack: the data preprocessing pipeline. This step includes connectors to ingest data wherever it may reside (e.g. S3 bucket or a CRM), a data transformation layer, and downstream connectors (e.g. to a vector database). Often the most valuable information to feed into an LLM is also the most difficult to work with (PDFs, PPTXs, HTML, etc.) but also documents in which the text is easily accessible (.DOCX, for example) contain information that users don’t want sent to the inference end point (e.g. advertisements, legal boilerplate, etc.).
Historically this step was hand built specific for each application by data scientists. Depending on the types of data involved, they might use off-the-shelf OCR models and dozens to hundreds of custom regular expressions to transform and clean natural language data for processing in a downstream machine learning pipeline. At Unstructured we’re developing open source tools to accelerate this preprocessing step, utilizing a range of computer vision document segmentation models, as well as NLP models, Python scripts, and regular expressions to automatically extract, clean, and transform critical document elements (e.g. headlines, body text, headers/footers, lists, and more). We’re currently working on the next generation of tooling to make it easy for developers to point large and highly heterogeneous corpus of files containing natural language data (e.g. an S3 bucket containing thousands of PDFs, PPTXs, chat logs, scraped HTML, etc.) at a single API endpoint and receive clean JSON ready for an embedding endpoint and storage in a vector database.
Embeddings Endpoint and Vector Store: The use of an embeddings endpoint and vector store represents a significant evolution in how data is stored and accessed. Previously embeddings were largely used for niche tasks such as document clustering. However, in the new architecture, storing documents and their embeddings in a vector database enables critical engagement patterns by the LLM endpoint (more on that below). One of the primary advantages of this architecture is the ability to store raw embeddings directly, rather than converting them to a structured format. This means that the data can be stored in its natural format, allowing for faster processing times and more efficient data retrieval. Additionally, this approach can make it easier to work with large datasets, as it can reduce the amount of data that needs to be processed during training and inference.
Generating and storing document embeddings, along with JSON versions of the documents themselves, creates an easy mechanism for the LLM to interface with the vector store. This is particularly useful for applications where real-time processing is required, such as chatbots. By minimizing the time required for data retrieval, the system can respond more quickly and provide a better user experience. Another advantage of using the embeddings (and document index) and vector store is that it can make it easier to implement techniques such as transfer learning, to enable more efficient fine tuning and better performance.
LLM Endpoint: The third pillar of the new tech stack is the LLM endpoint. This is the endpoint that receives input data and produces LLM output. The LLM endpoint is responsible for managing the model’s resources, including memory and compute, and for providing a scalable and fault-tolerant interface for serving LLM output to downstream applications.
Although most LLM providers offer several different types of endpoints, we use this to refer to the text-generation endpoints. As covered above, this is the new technological unlock that is powering a lot of the emergent applications (compared to more traditional ML pipelines). It’s a bit of a simplification, but the interface these LLM endpoints expose is a text field as an input and a text field as an output.
LLM Programming Framework: The final pillar of the new tech stack is an LLM programming framework. These frameworks provide a set of tools and abstractions for building applications with language models. At LangChain, this is exactly the framework we are working on building. These frameworks are rapidly evolving, which can make them tough to define. Still, we are converging on a set of abstractions, which we go into detail below.
A large function of these frameworks is orchestrating all the various components. In the modern stack so far, the types of components we’ve seen emerging are: LLM providers (covered in section above), Embedding models, vectorstores, document loaders, other external tools (google search, etc). In LangChain, we refer to ways of combining these components as chains. For example, we have chains for doing QA over a vector store, chains for interacting with SQL databases, etc.
All of these chains involve calling the language model at some point. When calling the language model, the primary challenge comes from constructing the prompt to pass to the language model. These prompts are often a combination of information taken from other components plus a base prompt template. LangChain provides a bunch of default prompt templates for getting started with these chains, but we’re also focused on building out the LangChainHub — a place for users to share these prompts.
Open Questions:
The Best Way to Index Data: Right now, everyone is largely using vectorstores as the primary way to index data such that LLMs can interact with it. However, this is just the first pass at defining how these interactions should work. An area of active exploration is the extent to which knowledge graphs, coupled with document indexes and their embeddings, can further enhance the quality of inferences from LLMs. Additionally, for the foreseeable future most enterprises will continue to require high quality structured data (typically in a graph database) to fuse with existing datasets and business intelligence solutions. This means that for the medium-term, enterprise adopters may actually rely on both vector as well as graph databases to power existing applications and workflows.
What Fine Tuning / Retraining Will Look Like: Right now, LLM programming frameworks like LangChain are being used to combine your own data with a pretrained LLM. Another way to do this is to finetune the LLM on your data. Finetuning has some pros and cons. On the plus side, it reduces the need for a lot of this orchestration. On the downside, however, it is more costly and time consuming to get right, and requires doing it periodically to keep up to date. It will be interesting to see how these tradeoffs evolve over time.
Different ways of using embeddings: Even if the primary usage pattern remains keeping your data in an external database, rather than finetuning on it, there are other ways to combine it with LLMs rather than the current approaches (which all involve passing it into the prompt). Most exciting are approaches like RETRO, which fetch embeddings for documents but then attend directly over those embeddings rather than passing the text in as prompts. While these models have mostly been used in research settings, it will be interesting to see if they make it mainstream and how this affects LLM programming frameworks.
Conclusion
The shift towards this new LLM tech stack is an exciting development that will enable developers to build and deploy more powerful NLP applications. The new stack is more efficient, scalable, and easier to use than the old stack, and it unlocks the full potential of LLMs. We can expect to see more innovations in this space in the coming months and years as developers continue to find new ways to harness the power of LLMs.


