
Authors

Prepping unstructured data for GenAI workloads is a hassle. You’ve got PDFs, docs, emails, and scanned files sitting in cloud storage. Turning that into something usable like clean JSON, metadata, or embeddings usually means chaining together OCR tools, file-type parsers, and a bunch of one-off scripts.
Instead, that’s where Unstructured comes in. It gives you a standardized way to connect to cloud data sources, break documents into structured elements, enrich and chunk them if needed, and pass them along to wherever your RAG pipeline lives.
In this walkthrough, we’ll pull files from an Azure Blob Storage container, preprocess them using the Unstructured API, and push the structured output into an IBM watsonx.data table, no manual parsing, no glue code.
End-to-End Workflow Overview
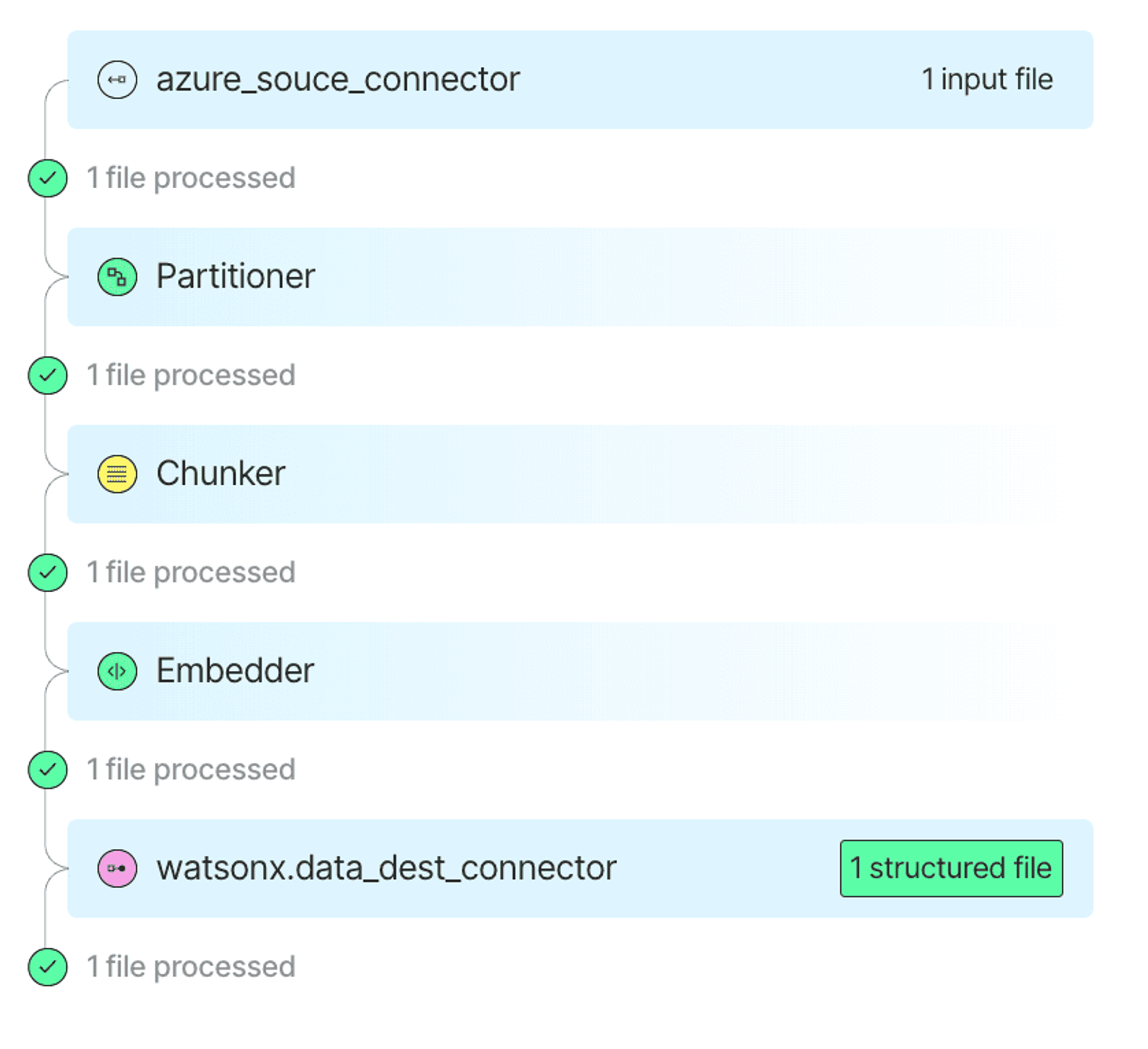
This is what the final workflow will look like:

Once everything is wired up, files in Azure Blob Storage are ingested using the Azure Source Connector. Each file is parsed into structured JSON using Unstructured’s partitioning step, which uses a vision-language model under the hood. You can also add chunking and embedding if your downstream stack needs it.
The processed output is then written to a table in IBM watsonx.data using the destination connector. The whole workflow runs as a job, so you can schedule it and keep your table up to date without building a custom ETL pipeline.
Prerequisites
Unstructured
To start transforming your data with Unstructured, contact us to get access—or log in if you're already a user.
Azure
Unstructured can ingest documents from a wide variety of data sources, and you can ingest data from more than one source in a single workflow, however, to keep this guide simple, we’ll only use one source - Azure.
You'll need an Azure account with access to Azure Blob Storage, along with your storage account name and a shared access signature (SAS) token for authentication. Make sure you've created a container within your storage account and that it has the appropriate access permissions. Upload a few files to your blob container so there's something to play with! 😉 Take a look at this list of supported file types and this video on how you can set yours up.
IBM Watsonx.data
To send processed data from Unstructured to IBM watsonx.data, you'll need the following configuration in place:
IBM Cloud Setup
- IBM Cloud Account: Create one if you don't already have an account.
- IBM Cloud API Key: Generate an API key by going to Manage > Access (IAM) > API Keys and clicking Create.
- Cloud Object Storage (COS):
- Create a COS instance via Create resource > Object Storage
- Within the instance, create a bucket and note the following:
- Bucket name
- Region (e.g., us-east)
- Public endpoint (e.g., s3.us-east.cloud-object-storage.appdomain.cloud)
HMAC Credentials
- HMAC Access Key ID and Secret Access Key:
- Navigate to the COS instance > Service Credentials
- If none exist, create one and enable Include HMAC Credential
- Copy access_key_id and secret_access_key from the cos_hmac_keys block
watsonx.data Setup
- watsonx.data Instance: Create one by searching for watsonx.data in Create resource
- Apache Iceberg Catalog:
- Open the watsonx.data web console
- Navigate to Infrastructure Manager > Add Component > IBM Cloud Object Storage
- Provide:
- Display name
- Bucket name, region, and public endpoint (with https:// prefix)
- HMAC credentials
- Test the connection and associate the catalog
- Ensure the catalog is linked to a compute engine (e.g., Presto)
- Catalog Details:
- In the web console > Infrastructure Manager, select your catalog
- Note the:
- Catalog name
- Metastore REST endpoint
Schema and Table
- Namespace (Schema):
- Go to Data Manager > Browse Data
- Select your catalog, then create a new schema if needed
- Table:
- In Query Workspace, create a table with a schema compatible with Unstructured’s output.
Here’s a recommended schema based on typical partitioned output:
CREATE TABLE <catalog>.<schema>.elements (
type VARCHAR,
element_id VARCHAR,
text VARCHAR,
file_directory VARCHAR,
filename VARCHAR,
languages ARRAY(VARCHAR),
last_modified DOUBLE,
page_number VARCHAR,
filetype VARCHAR,
url VARCHAR,
version VARCHAR,
record_locator VARCHAR,
date_created DOUBLE,
date_modified DOUBLE,
date_processed DOUBLE,
filesize_bytes BIGINT,
points VARCHAR,
system VARCHAR,
layout_width DOUBLE,
layout_height DOUBLE,
id VARCHAR,
record_id VARCHAR,
parent_id VARCHAR
)
WITH (
delete_mode = 'copy-on-write',
format = 'PARQUET',
format_version = '2'
);- Record Identifier:
- Make sure the table includes a record_id or equivalent column used as the primary identifier.
Metadata Cleanup (Recommended)
To improve performance, configure the table to regularly remove old metadata. This requires running a Python script using pyiceberg, requests, and pyarrow. See the Unstructured's IBM watsonx.data destination docs for the script and setup.
Building the Workflow
Step 1: Create an Azure Source Connector
Log in to your Unstructured account, click Connectors on the left side bar, make sure you have Sources selected, and click New to create a new source connector. Alternatively, use this direct link. Choose Azure, and enter the required info about your bucket.
If you’re not sure how to get the necessary credentials, the Unstructured docs include step-by-step instructions and videos that walk you through configuring your Azure Blob Storage for ingestion and retrieving the credentials you'll need.
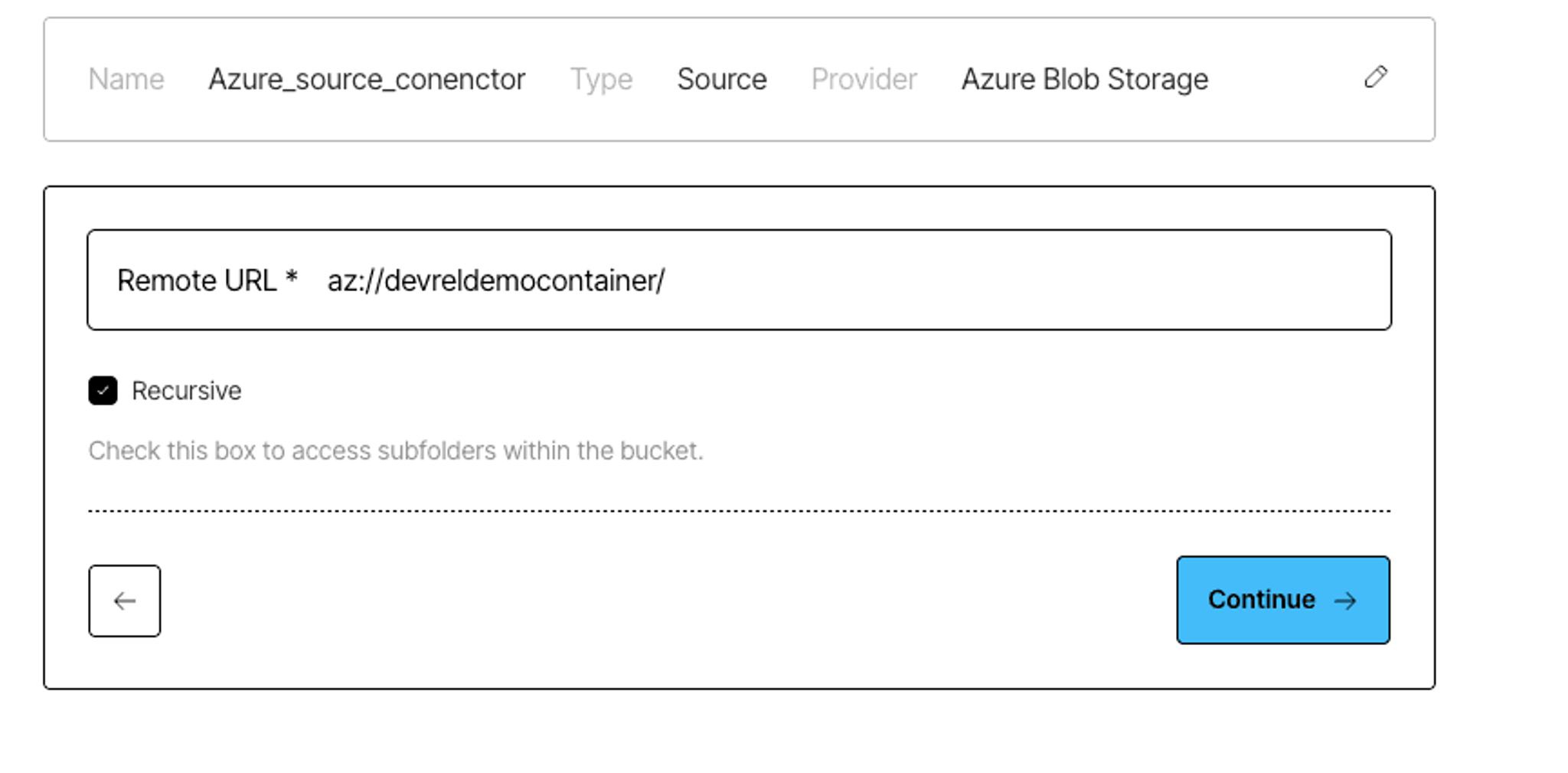
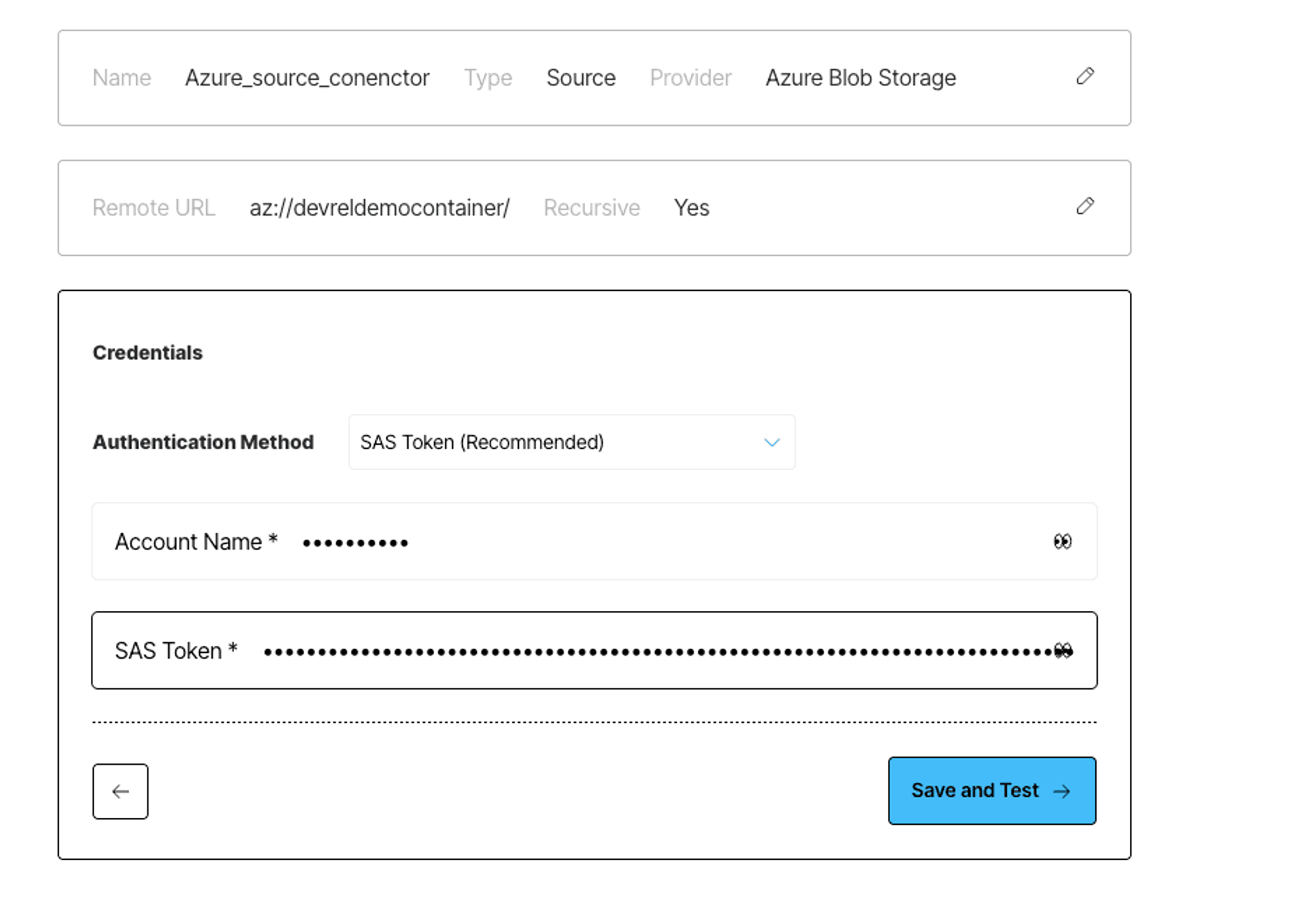
Once the connector is saved, Unstructured will check to make sure it can successfully connect to your container.
Step 2: Create an IBM watsonx.data Destination Connector
To create a destination connector, head to the Connectors tab in the Unstructured UI, switch to Destinations, and click New. You can also use this direct link.
Give your connector a descriptive name, and choose IBM watsonx.data as the provider.
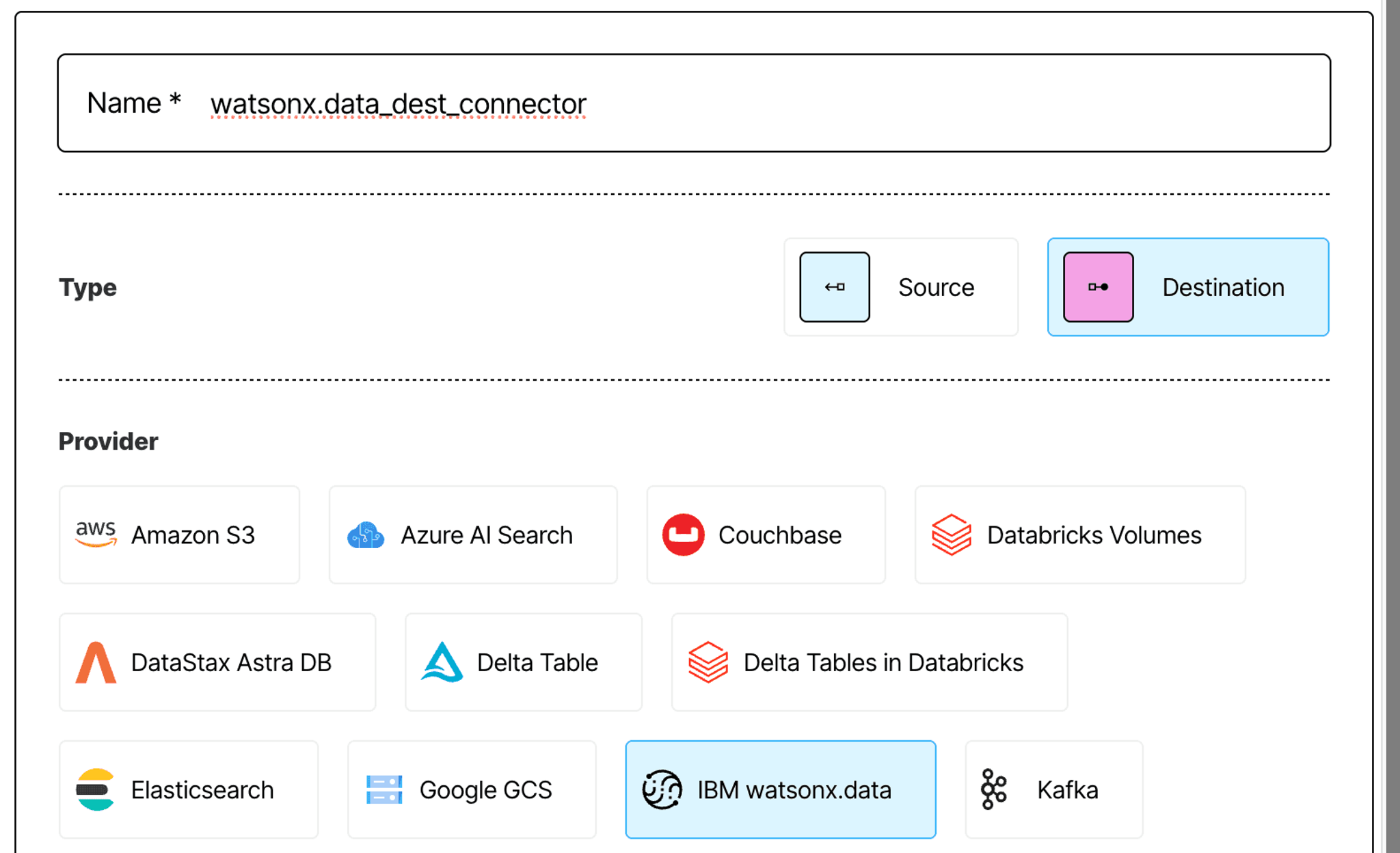
Next, fill in the following configuration fields:
- Iceberg Endpoint – e.g., metastore-api.us-south.dataplatform.cloud.ibm.com (This is the Metastore REST endpoint, without https://)
- Object Storage Endpoint – e.g., s3.us-east.cloud-object-storage.appdomain.cloud (COS public endpoint, no https://)
- Object Storage Region – e.g., us-east
- IAM API Key – Your IBM Cloud account API key
- Access Key ID – HMAC access key ID for your COS instance
- Secret Access Key – HMAC secret access key paired with the access key ID
- Catalog – e.g., unstructured_catalog
- Namespace – e.g., documents_schema (equivalent to schema)
- Table – e.g., elements
Optional fields:
- Max Retries – e.g., 150 (Defaults to 50. Accepts 2–500.)
- Max Connection Retries – e.g., 15 (Defaults to 10. Accepts 2–100.)
- Record ID Key – e.g., record_id (Name of the unique identifier column. Defaults to record_id.)
Once the fields are filled out, click Continue to validate the connection and save the destination connector.
You’re now ready to wire it into a workflow.
Step 3: Configure Your Processing Workflow
Now that you’ve set up your Azure source and IBM watsonx.data destination connectors, it’s time to create the data processing workflow that ties them together.
Head to the Workflows tab in the Unstructured UI and click New Workflow. Choose the Build it Myself option to get a clean slate. Your workflow graph will start with three default nodes: Source, Partition, and Destination.
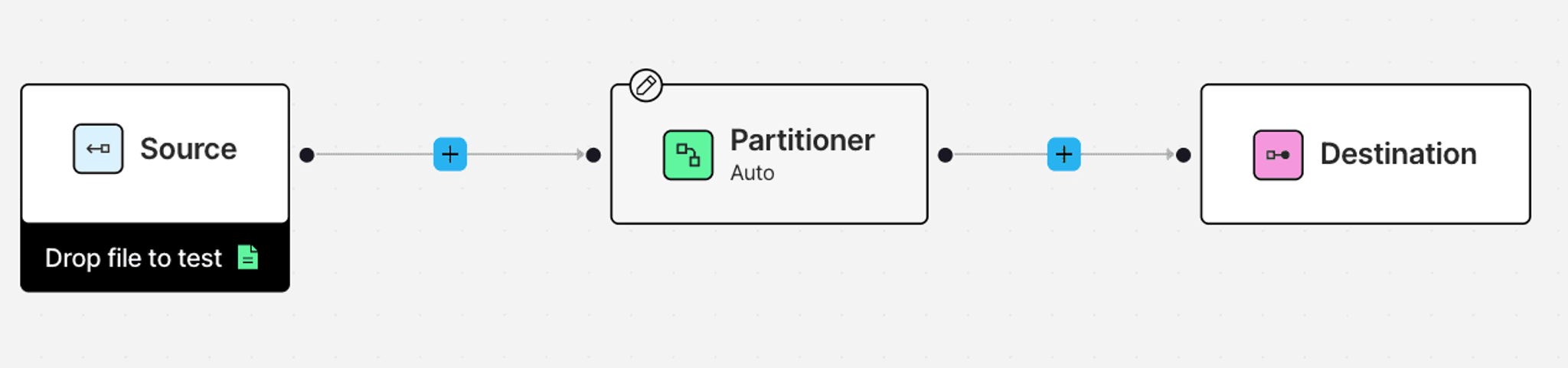
Click into the Source and Destination nodes, and select your Azure Blob Storage and IBM watsonx.data connectors, respectively.
The Partition node is required in every workflow. It’s responsible for parsing the raw files into structured JSON—extracting clean text, layout info, and metadata. Unstructured offers several partitioning strategies depending on your use case:
- VLM: Uses vision-language models for high-accuracy parsing of scanned documents, forms, or anything messy that traditional OCR can’t handle well.
- High Res: Combines OCR and document structure analysis, good for image-based PDFs and scanned pages with tables.
- Fast: Optimized for speed, best for well-structured digital files like Word docs, markdown, or HTML.
- Auto (default): A smart strategy that picks between VLM, High Res, and Fast automatically, based on the file’s content and layout.
For this guide, we’ll go with the VLM partitioner. You can also choose a specific model for parsing—for example, Claude Sonnet 3.7.

Next, click the plus icons between the nodes to add optional transformations. For a typical RAG setup, we’ll add:
- A Chunker node, which breaks large document elements into coherent chunks optimized for embedding.
- An Embeder node, which uses a model like OpenAI’s text-embedding-3-small to turn those chunks into vectors.
This combination—partitioning, chunking, and embedding—is a great default for preparing unstructured text for retrieval.
Each document element created by the partitioner represents a specific piece of content, such as a paragraph, table, or header. Some elements are large, like full sections of text or tables. Others might be smaller, like bullet points or image captions. The chunking step groups them into logical segments that preserve meaning while staying within token limits.
The embedding step then transforms each chunk into a vector, ready for similarity search or indexing downstream.
Once your DAG looks good, open the right panel to configure general workflow settings like:
- Workflow name
- Schedule (e.g. daily, weekly)
- Whether to reprocess all documents or only new/modified ones
Give your workflow a name, choose when it should run, and save it. Back on the Workflows page, toggle it to Active, then hit Run to trigger your first job.
Just like that, you’ve built a fully automated pipeline to preprocess unstructured files and land structured, searchable data in IBM watsonx.data.
Step 4: Track Job Progress
Navigate to the Jobs tab to track the progress. Here you can click on your jobs to explore what they are doing. Once the job completes, you’ll find the details here, including error logs, if any:
Check the Output in watsonx.data
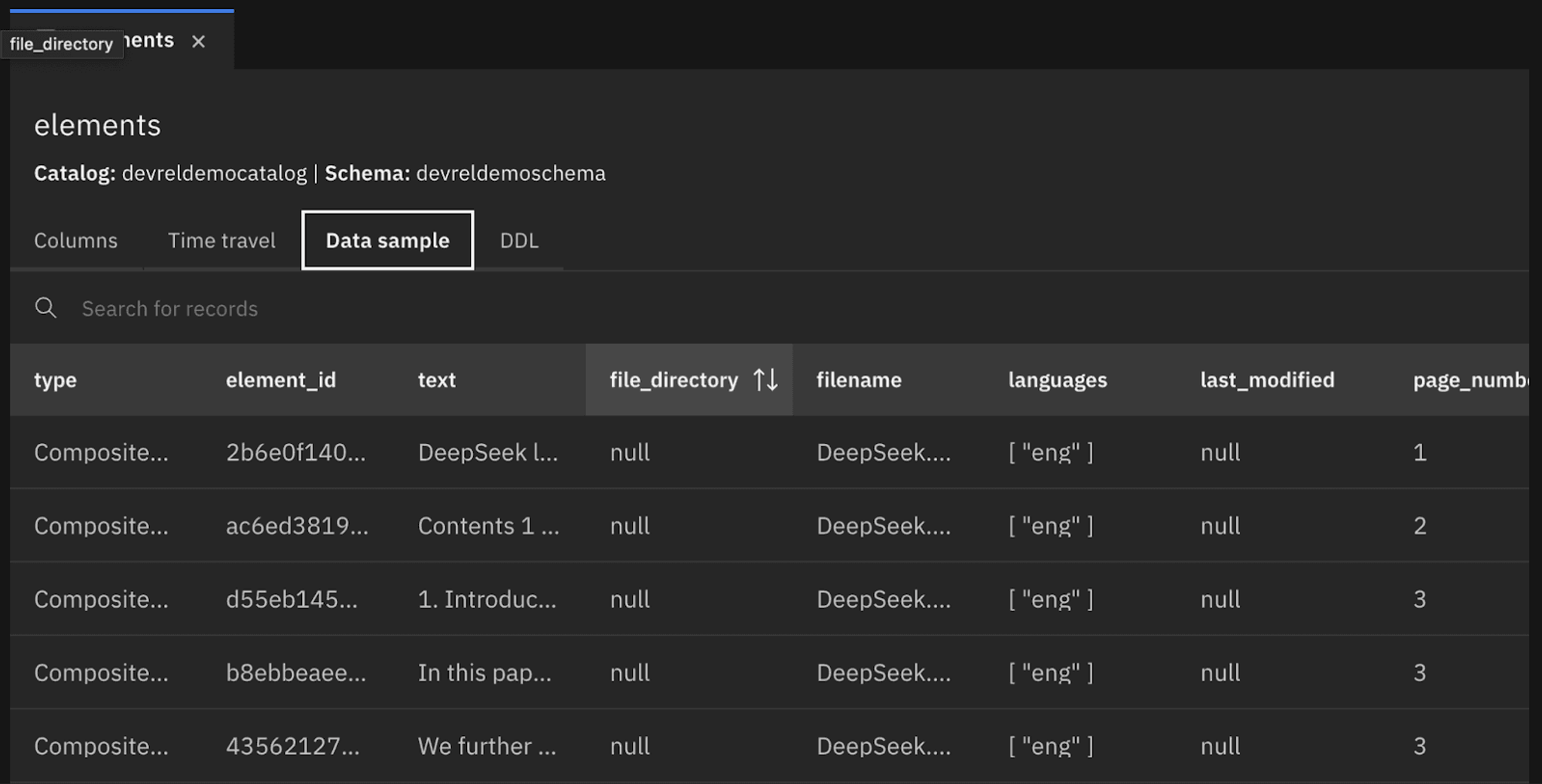
Once the workflow finishes running, open up the watsonx.data web console and navigate to your target catalog and schema.
You’ll find your table populated with structured document elements—text, metadata details, and embeddings—derived from the files in your Azure Blob Storage container. You can now query that data directly or plug it into downstream retrieval workflows.
What You’ve Built
You just set up an end-to-end data pipeline using Unstructured. Starting with raw files in Azure Blob Storage, you configured connectors, defined a processing workflow, and transformed unstructured content into structured rows with optional chunking and embeddings.
That structured data now lives in a watsonx.data table, ready to support RAG pipelines, LLM-powered tools, or anything else you build on top.
Want help going deeper or scaling this out? Reach out to our team, we’re happy to walk you through more advanced use cases or integration options.
FAQ
What connectors does Unstructured use to move data between Azure Blob Storage and IBM watsonx.data?
Unstructured provides a native Azure Blob Storage source connector and an IBM watsonx.data destination connector that can be configured directly in the platform UI. Once both connectors are set up, you wire them together in a workflow alongside partitioning, chunking, and embedding nodes to create a fully automated pipeline without writing custom ETL code.
Can Unstructured handle both digital and scanned documents when preparing data for IBM watsonx.data?
Yes. Unstructured offers multiple partitioning strategies to handle different document types. The VLM strategy uses vision-language models for complex or scanned files, High Res combines OCR with document structure analysis, Fast targets clean digital files, and Auto selects the best approach based on the file's content and layout automatically.
What is a data lakehouse, and why is it relevant for AI workloads?
A data lakehouse combines the scalability and low cost of a data lake with the structure and query performance of a data warehouse. This architecture is well suited for AI workloads because it allows teams to store large volumes of raw and processed data while still supporting fast, structured queries needed for retrieval and model training.
What file formats can be stored in IBM watsonx.data, and how does Apache Iceberg fit in?
IBM watsonx.data supports open table formats including Apache Iceberg, which provides features like schema evolution, time travel, and efficient metadata management on top of object storage. Iceberg tables stored in formats like Parquet allow structured data to be queried across multiple compute engines without vendor lock-in.
What is retrieval-augmented generation (RAG), and why does data preprocessing matter for it?
RAG is a technique where a language model retrieves relevant documents or passages from an external knowledge base before generating a response, improving accuracy and grounding. The quality of that retrieval depends heavily on how well source documents have been parsed, chunked, and embedded, making preprocessing a critical step before any RAG pipeline can perform reliably.


