Authors


Be honest: your document processing pipeline is a mess. Most enterprises diving into generative AI have cobbled together a series of point solutions, custom scripts, and manual processes to handle unstructured data. Unstructured calls this the "Rat’s Nest" and it's silently sabotaging your GenAI initiatives.
The Uncomfortable Truth About Your Document Processing
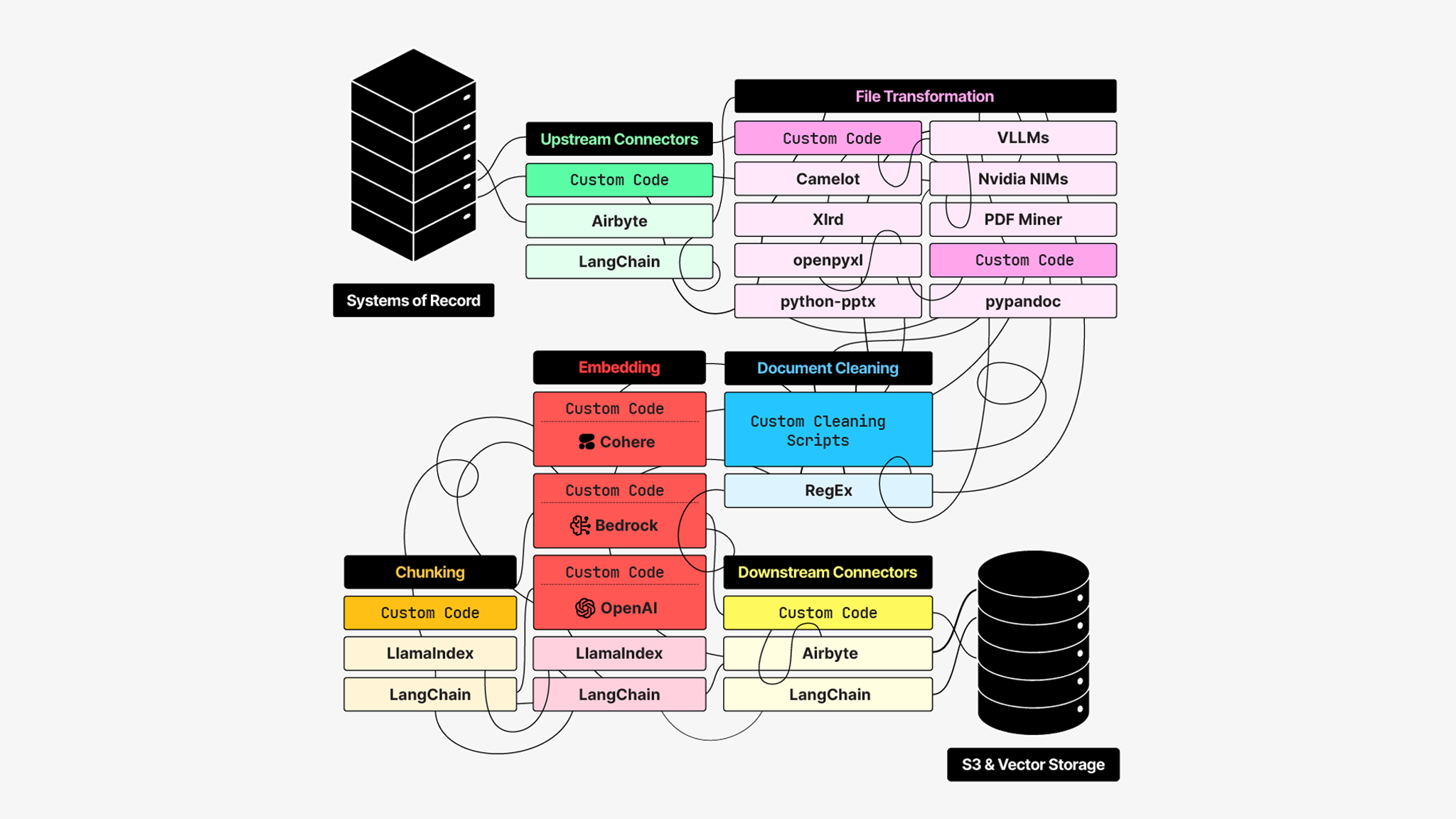
You thought building a data processing pipeline would be straightforward. You have your system of record, a few upstream connections, maybe some Airbyte connectors and a database. Data moved from point A to point B. Clean. Simple. Done.
But it’s really not that simple. Your document processing wasn’t purpose-built for novel use cases like RAG, GraphRAG, and whatever comes next. So engineers are learning on the fly to transform multi-modal data by tuning and prompting the latest VLMs. You must now create a canonical consistent schema because it has to be joined to your structured data otherwise it has no meaning from a query perspective. You then want to chunk it. Your team never knew that they needed chunking; they didn't know that they needed document cleaning; they didn't know that embeddings were incredibly important to provide the vector dimensional space so that your array application can actually search and find that information at a faster retrieval time.
The Rat’s Nest is Not Your Fault.
A wild amount of change has happened really fast. The data just keeps coming and you’re reacting in real time. However, that means building each of these components in isolation which results in each team, each project and each use case getting a bespoke solution. Knowing what you know now, this isn’t how you’d design it. It’s time to reassess.
The Real Cost of the Rat’s Nest
Your current approach works to prove the value of your science fair GenAI prototypes. Success! But here's what ad-hoc data processing is costing you in production:
Engineering Talent Misallocation
Let’s break this down: You’d need about four full-time engineers just to build and maintain these pipelines at scale. That’s roughly a million bucks a year in salaries alone — not to mention 160 hours of your team’s brainpower every week not spent on your actual product. Instead, they’re stuck doing what we call “grunt work” — the kind of behind-the-scenes lifting that keeps the lights on but doesn’t move the needle. And here’s the kicker: these numbers assume the tech world stays frozen in time. Spoiler alert: It won’t. The second a new tool, framework, or trend pops up, your team’s back to square one, scrambling to rebuild and retool.
That’s where we come in. At Unstructured, we’ve got a full squad of engineers and researchers geeking out daily on one mission: making these pipelines bulletproof, scalable, and future-proof. While we’re obsessing over the nitty-gritty, our customers get to redirect their A-team toward what actually grows their business. In fact, most folks who switch to Unstructured see a 3x return on investment just by reassigning their talented engineers to core projects instead of pipeline babysitting.
Why pour time and money into reinventing the wheel when the race is already moving? Let us handle the heavy machinery — you keep building what matters.
Technical Debt Accumulation
Each bespoke solution adds to technical debt. Every new file format, new use case, new requirement means more custom code, maintenance, complexity — it’s a Jenga-like data stack that’s brittle and unsustainable.
Innovation Bottleneck
The Rat’s Nest isn't just a technical problem — it's an innovation killer. You’re not just building apps, you’re architecting GenAI systems that support your internal and external users. While your teams are wrestling with document processing infrastructure, akin to “turning on the water” for your systems, your competitors are building next-generation features and capabilities.
The GenAI Multiplier Effect Strains Data Teams
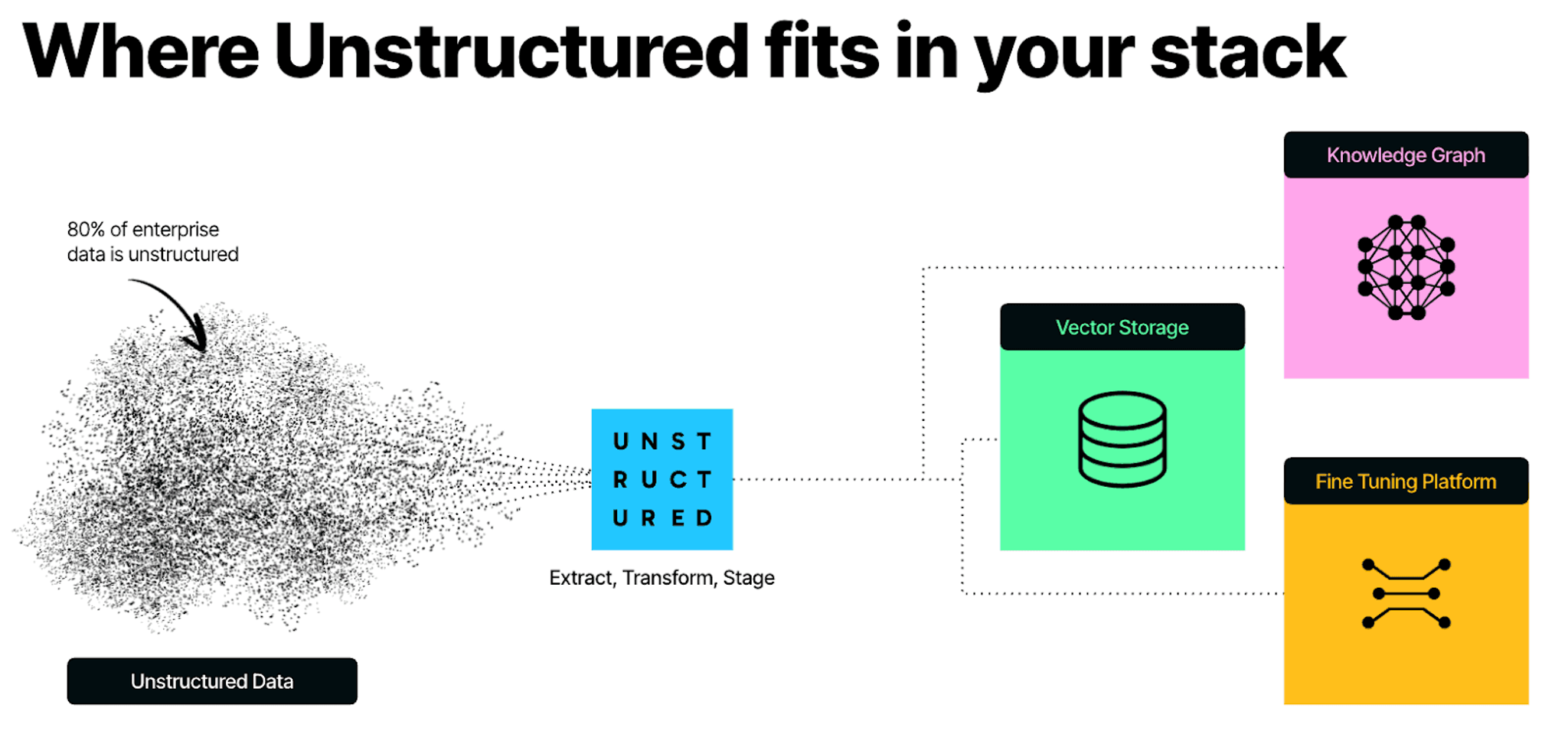
At least 80% of data is locked up in unstructured file formats — think PDFs, PowerPoint decks, Excel sheets, images, and HTML files. That corpus of human-generated data is ballooning with the help of LLMs. As one life sciences leader told us: "With generative AI, we've generated 10 years worth of research docs in the last year."This puts a major strain on your data teams, and your investments in GenAI initiatives hang in the balance. Data science and ML teams are unlocking huge value potential in RAG apps and tuning/training models. Data engineering teams are tasked with a monumental endeavor to productionize the data and realize that value.
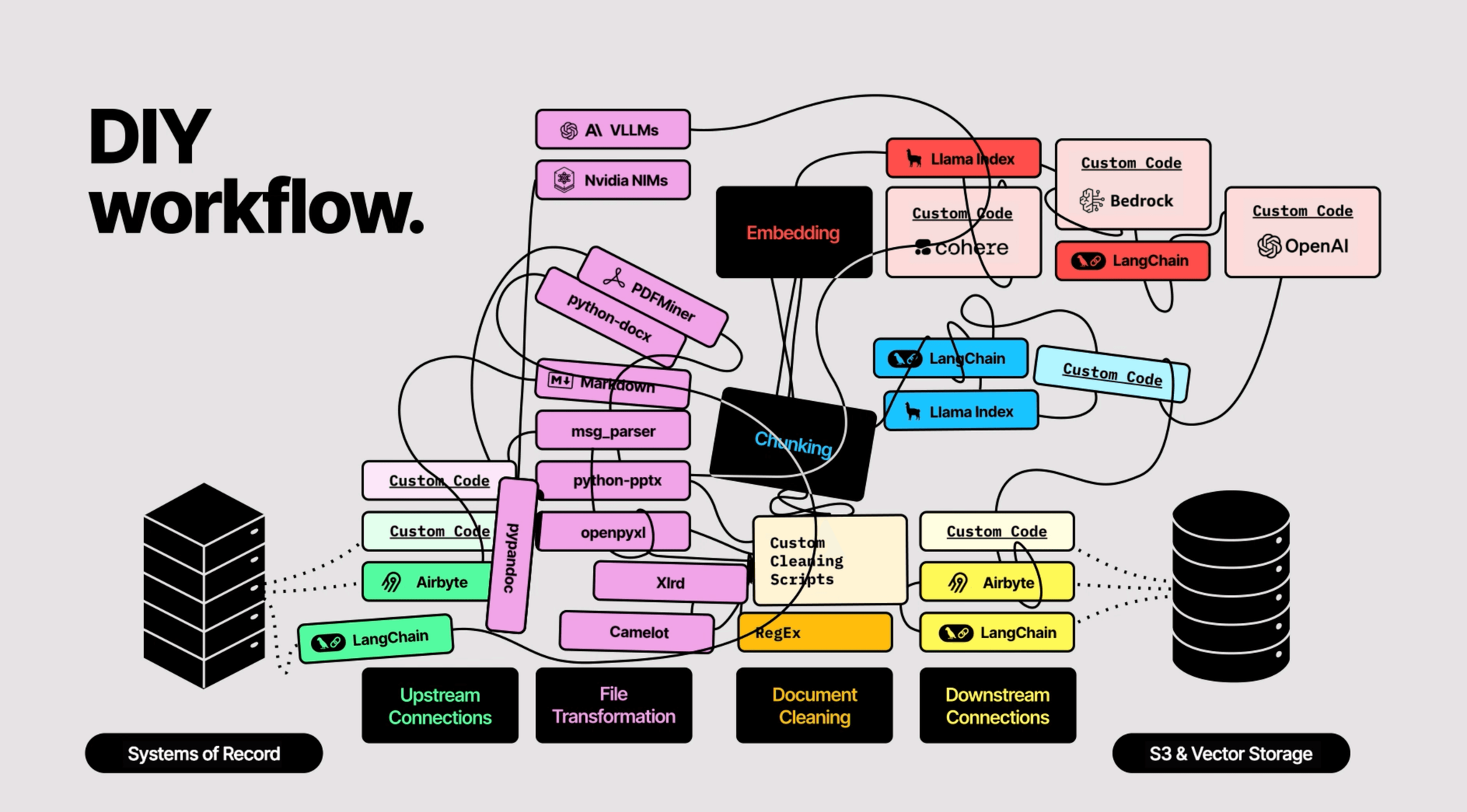
Breaking Free from the Rat’s Nest With Unstructured
The solution isn't to build more infrastructure — it's to fundamentally rethink how you handle document processing within your existing stack. Here's what a GenAI native approach looks like using Unstructured:
Intelligent Processing Pipelines
- Ensemble parsing that routes content to the appropriate processing pipeline
- Smart partitioning that optimizes for both cost and performance
- Automatic handling of complex documents without manual intervention
Consistent Output Schema
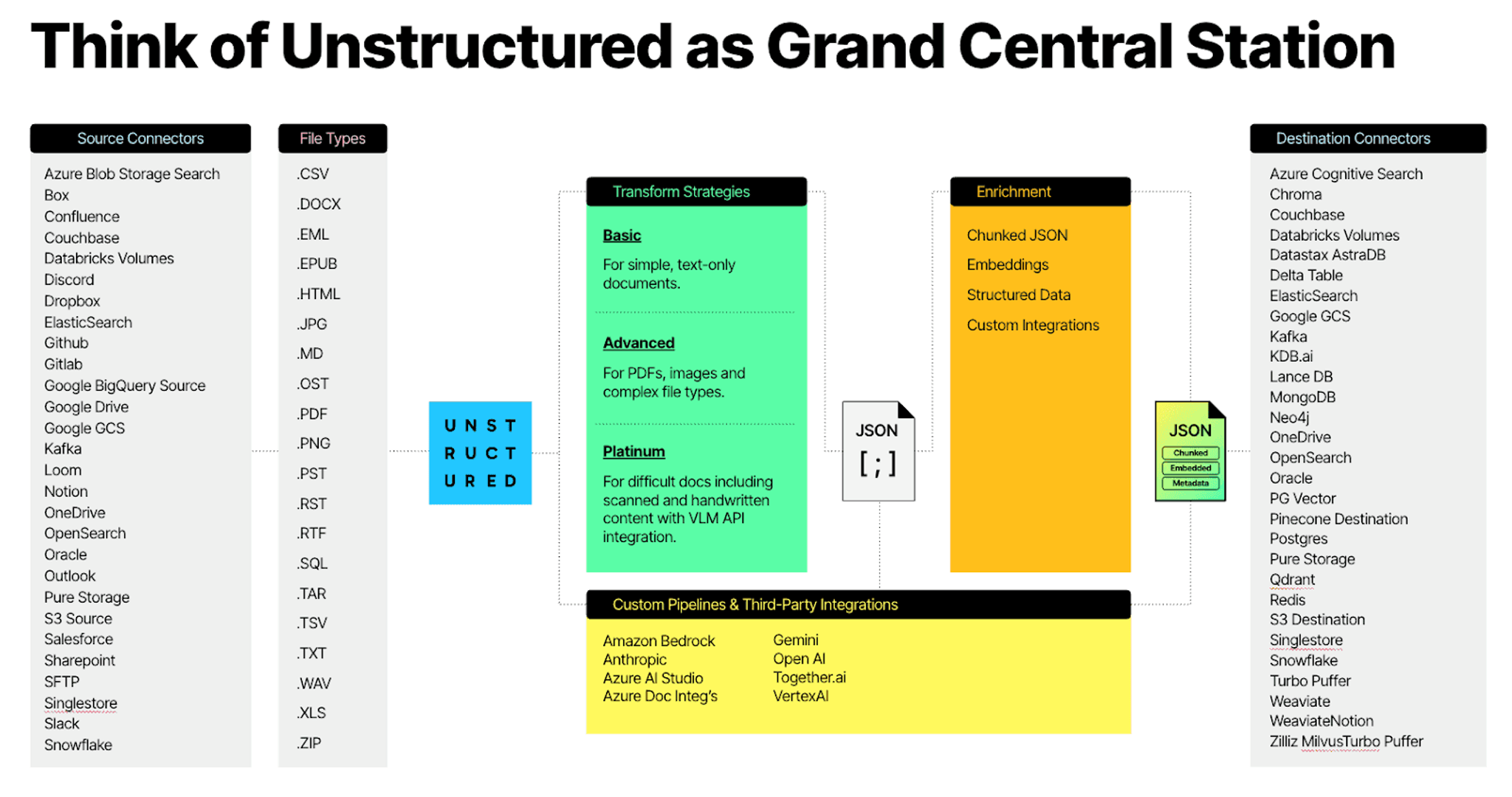
- Canonical JSON output that works across 67 document types
- Standardized embedding generation with models from OpenAI, Together.ai, and more
- Schema that integrates seamlessly with existing structured data
Enterprise-Grade Performance
- SaaS processing capacity of 15M+ pages per hour per workflow
- Horizontal scalability through multiple data planes
- Change detection and incremental processing
- Production-grade security and compliance features
Seamless Orchestration
- A "Grand Central Station" for handling multiple data sources and file types
- Effortlessly partners with your existing ETL stack
- Consumed as SaaS, any in-VPC environment, or air-gapped on-prem environment that supports Kubernetes
The Time to Change Was Yesterday. Today is Also Good.
There are two choices:
1. Continue building and maintaining your own document processing infrastructure, accepting the costs and limitations of the Rat’s Nest approach.
2. Adopt a purpose-built document processing platform that handles the infrastructure complexity, freeing teams to focus on building features that actually matter to your business.
The second is the most ideal, of course. The reality is that unwinding the Rat’s Nest takes a crawl-walk-run approach because leveling up your data layer isn’t an overnight project for you to tackle alone. Unstructured supports our largest clients bringing in their data, centralizing, and operationalizing it. Our experts can embed with business teams deploying specific GenAI use cases one at a time.
The pressure to deliver value from your GenAI initiatives is only increasing; the exponential growth of unstructured data isn't slowing down and the complexity of document processing isn't going away. You know you need to address your document processing infrastructure so the question isn't whether you need to. The question is: how much longer can you afford to wait? Connect with our Team to get onboarded to Unstructured and learn about our no-cost guided Enterprise proof of concept.
FAQ
What is a "Rat's Nest" in the context of data pipelines?
A Rat's Nest refers to the tangle of custom scripts, point solutions, and manual processes that teams build when handling unstructured data without a unified strategy. It typically emerges when engineers solve document processing challenges in isolation, resulting in bespoke pipelines for every project or use case that are difficult to maintain and impossible to scale cleanly.
Why is unstructured data harder to process than structured data for AI applications?
Structured data fits neatly into rows and columns, making it straightforward to query and transform. Unstructured data, which includes PDFs, presentations, images, and HTML, requires additional steps like document parsing, cleaning, chunking, and embedding generation before it can be used effectively in AI applications. Each of these steps introduces complexity that traditional ETL tools were not designed to handle.
What does chunking mean in document processing, and why does it matter for RAG?
Chunking is the process of splitting a document into smaller, semantically meaningful segments before indexing them in a vector store. In retrieval-augmented generation (RAG) applications, chunk quality directly affects retrieval accuracy. Poorly chunked content can cause a model to miss relevant context or return irrelevant results, making chunking strategy one of the more consequential decisions in building a RAG pipeline.
How does Unstructured handle documents across different file formats without requiring custom code for each one?
Unstructured uses ensemble parsing to automatically route content to the appropriate processing pipeline based on file type and document structure, supporting over 67 document types. This means teams do not need to write or maintain separate parsers for PDFs, PowerPoint files, HTML, images, and other formats. The output is a canonical JSON schema that integrates consistently with downstream structured data systems.
What kind of throughput and deployment flexibility does Unstructured support for enterprise workloads?
Unstructured can process more than 15 million pages per hour per workflow and scales horizontally through multiple data planes to meet high-volume production demands. It can be deployed as SaaS, within a customer's own VPC, or in an air-gapped on-premises environment that supports Kubernetes, giving enterprises the flexibility to meet their security and compliance requirements without sacrificing performance.


