
Authors

The Unstructured Platform now supports seamless integration with Couchbase, enabling data teams to build more sophisticated preprocessing pipelines for their document processing workflows.
Why Couchbase?
Couchbase serves as a versatile data platform that excels at handling transactions, search operations, and real-time analytics. Its architecture is particularly well-suited for JSON-native applications, making it an excellent choice for teams working with natural language processing, similarity search, and AI applications that require both performance and flexibility.
Understanding the Integration
The integration offers two primary connectivity options:
1) Couchbase destination connector: Upload processed documents and data from your source systems (cloud apps, file storage, databases, vector stores) directly into Couchbase collections. This allows you to centralize your organization's unstructured information in a consistent, structured format.
2) Couchbase source connector: Extract existing data from Couchbase collections for processing through Unstructured, then route it to various destinations like cloud storage, databases, or vector stores in formats optimized for each system.
How It Works
The Couchbase source and destination connectors in the Unstructured Platform are used to upload or download batches of data into or from your Couchbase collections. Here's how it works:
1) The Unstructured Platform ingests information from its original sources, preserving critical metadata along the way.
2) A workflow in the Platform processes your raw information into structured JSON, optionally enriches the content (for example, by generating summaries for tables where they exist), creates chunks, and generates vector embeddings (configurable with your preferred embedding model) for the processed content.
3) The connector efficiently manages batch uploads or downloads into or from your Couchbase collections. You can easily customize the batch size to fit your requirements.
Our Couchbase integration adheres to enterprise-grade security standards including:
- End-to-end encryption for data in transit.
- Authentication via API keys.
- Zero data persistence policy, and more.
You can learn more about the enterprise-grade features of the Unstructured Platform connectors in this blog post.
Configuring the connector
Before you configure the Couchbase source or destination connector, you will need:
1) A Couchbase Capella account.
2) A Couchbase Capella cluster.
3) A bucket, scope, and collection on the cluster.
4) The cluster’s public connection string.
5) The cluster access name (username) and secret (password) for the cluster.
6) Incoming IP address allowance on the cluster.
- To get Unstructured’s IP address ranges, go to https://assets.p6m.u10d.net/publicitems/ip-prefixes.json and allow all of the ip_prefix fields’ values that are listed.
- These IP address ranges are subject to change. You can always find the latest ones in the preceding file.
To configure the source or destination connector by using the Unstructured Platform user interface:
1) Log in to the Unstructured Platform.
2) On the sidebar, click Connectors.
3) Click New or Create Connector.
4) Type some unique Name for the connector.
5) For Type, make sure Source or Destination is selected.
6) Click Couchbase, and then click Continue.
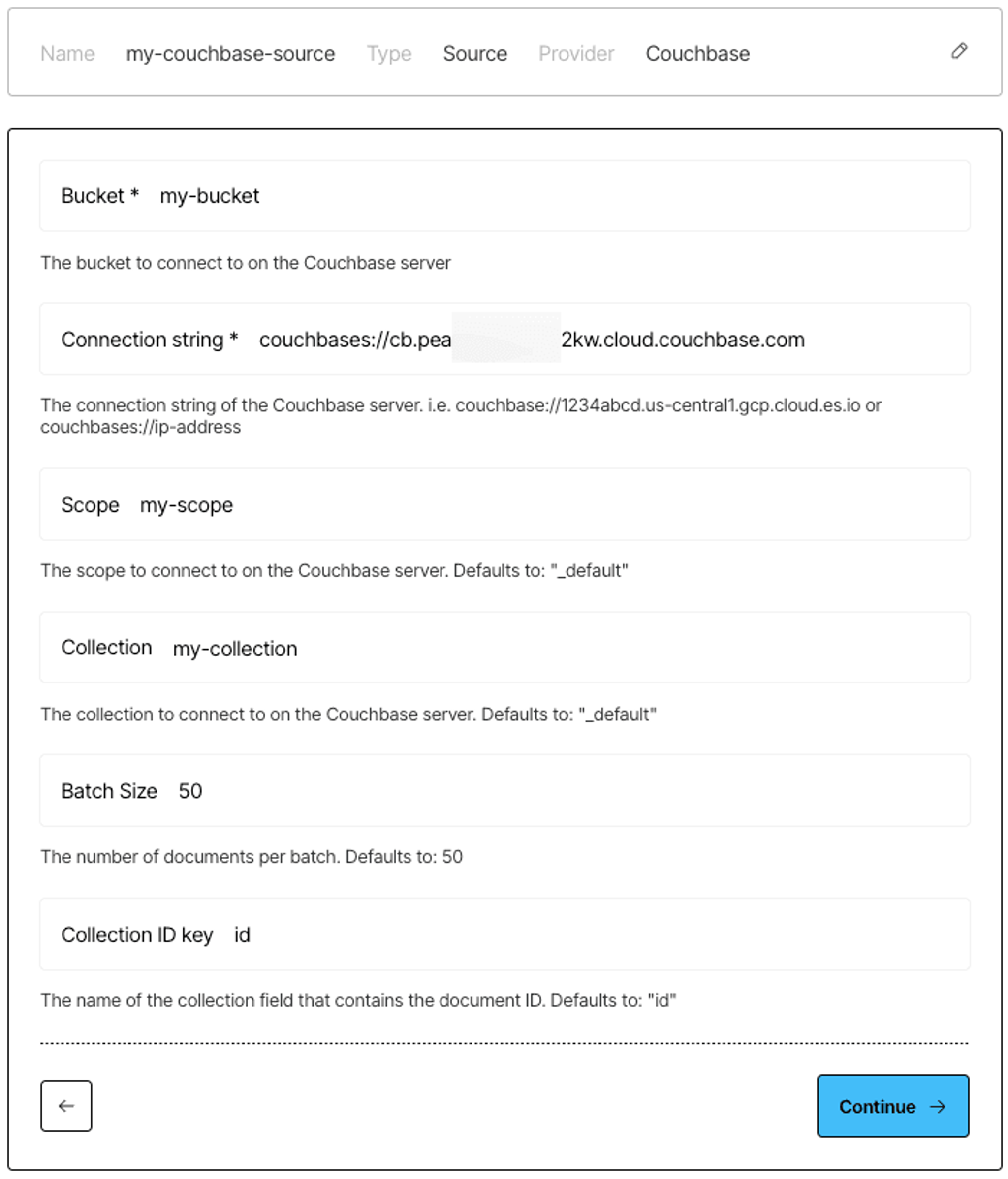
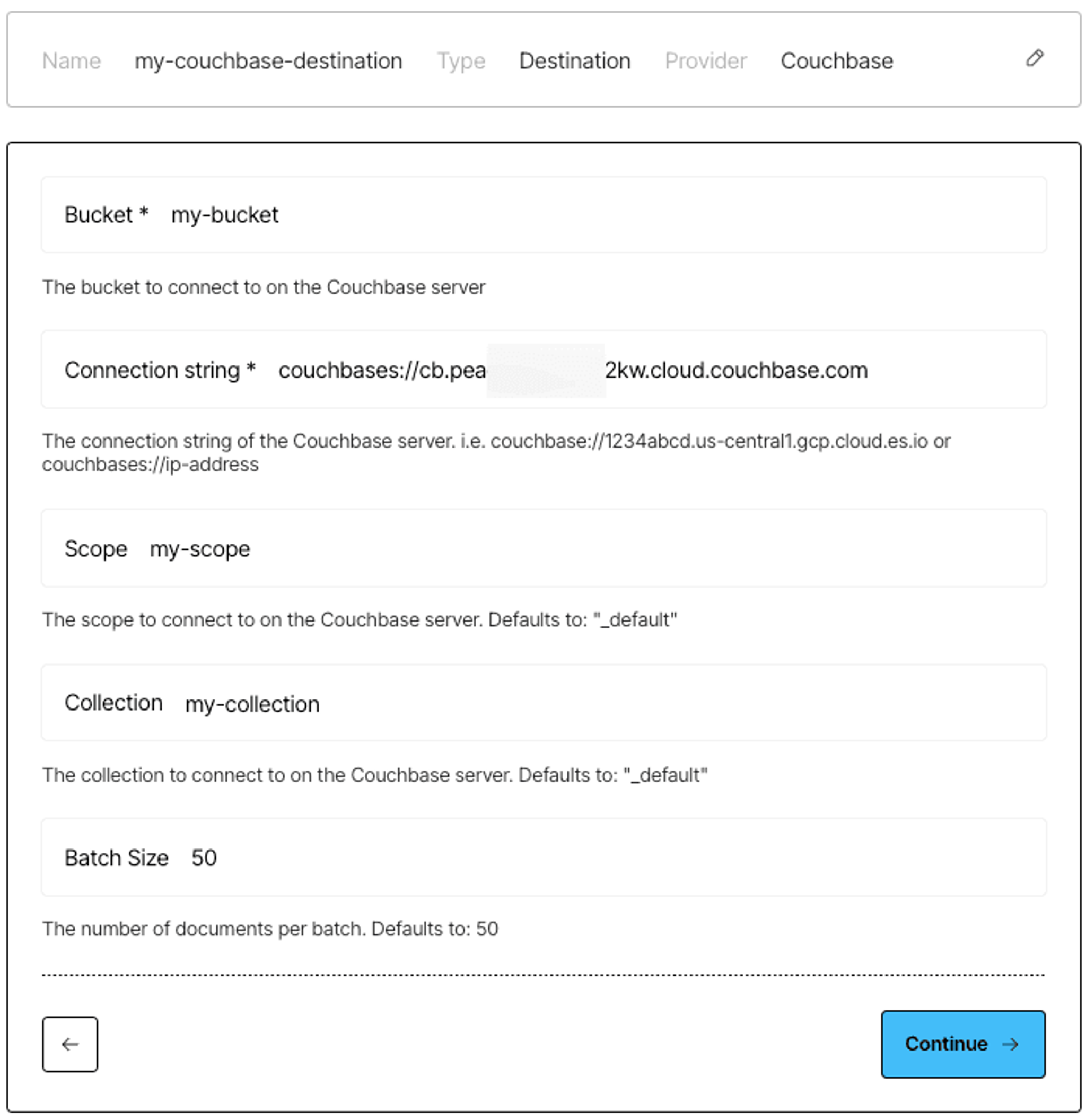
7) Fill in your Couchbase bucket name, connection string, scope name, and collection name. For the source connector, also fill in the name of the field in your collection that contains each document’s unique ID. Then click Next.
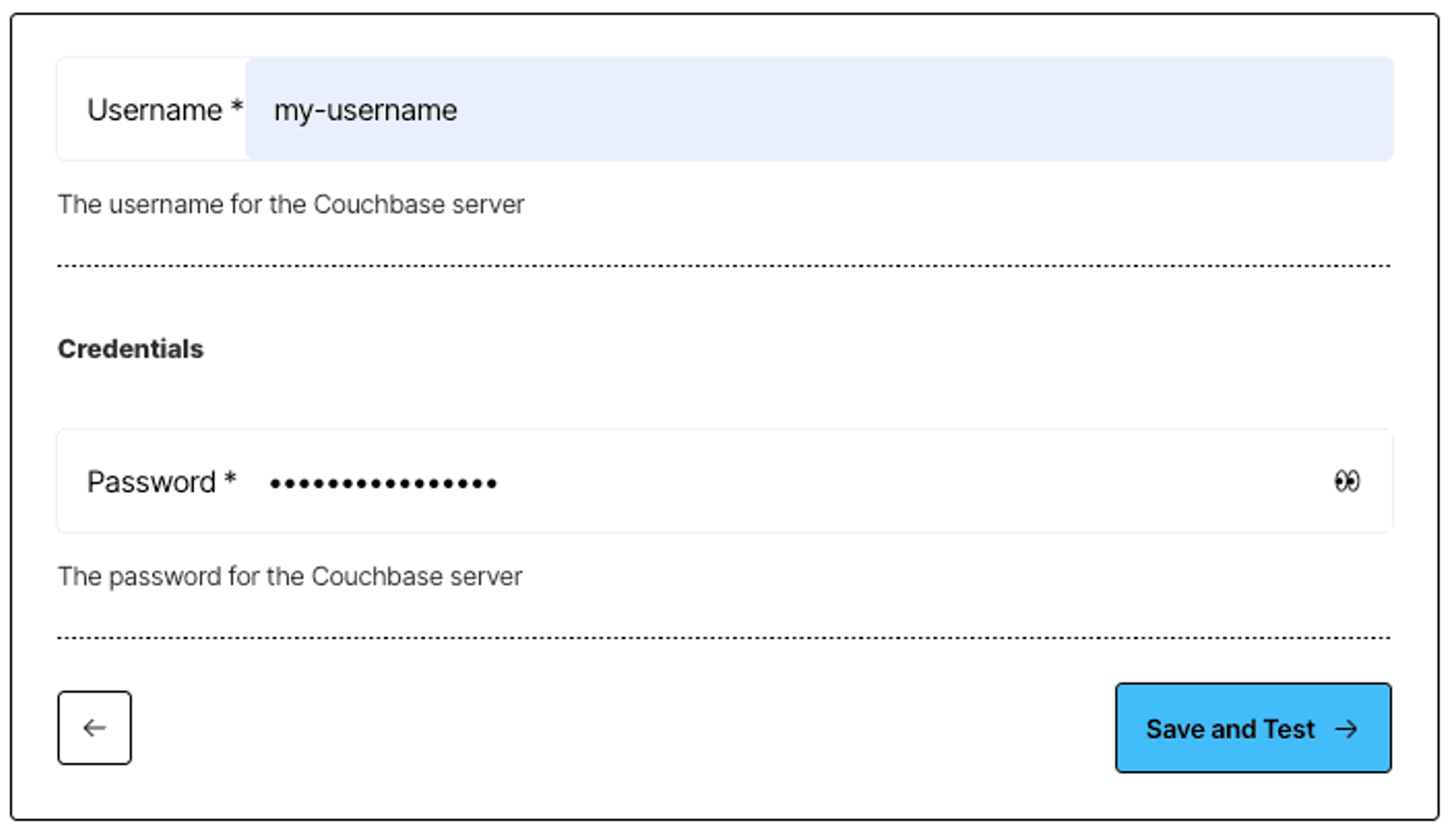
8) On the next screen, fill in your Couchbase instance’s access name (username) and secret (password).
9) Compare your results to the following screenshots, and then click Save and Test.
Bucket name, connection string, scope name, collection name, and the name of the field in your collection that contains each document’s unique ID (source connector only):
Bucket name, connection string, scope name, and collection name (destination connector only):
Cluster access name (username) and secret (password):
To create a workflow for the source or destination connector by using the Unstructured Platform user interface, see Create a workflow in the Unstructured documentation.
To configure the source or destination connector by using the Unstructured Platform API instead, you can run one of the following curl commands. In this command, set the environment variables beginning with UNSTRUCTURED to the Unstructured Platform API URL and your Unstructured Platform API key; and fill in your Couchbase bucket name, connection string, scope name, collection name, your Couchbase access name (username) and secret (password), and optionally a batch size representing the maximum number of records to transmit at a time. For the source connector, also fill in the name of the field in your collection that contains each document’s unique ID.
For the source connector:
For the destination connector:
To create a workflow for the source or destination connector by using the Unstructured Platform API, see Create a workflow in the Unstructured documentation.
Get started!
If you're already an Unstructured Platform user, the Couchbase source and destination connectors are available in your dashboard today!
Expert access
Need a tailored setup for your specific use case? Our engineering team is available to help optimize your implementation. Book a consultation session to discuss your requirements here.


