Building Unstructured Data Pipeline with Unstructured Connectors and Databricks Volumes
Apr 2, 2024

Authors


Introduction
Companies of all sizes face the overwhelming challenge of extracting value from mountains of unstructured data they accumulate. This unstructured data is inherently disorganized and lacks the structure for traditional analysis. Manual processing is time-consuming, prone to errors, and often fails to uncover the hidden insights that could transform a business. Furthermore, complex document processing requires handling diverse file formats and the daunting task of data preparation and cleaning. The result is untapped potential, missed opportunities, and a competitive disadvantage for the companies.
The integration of Databricks and Unstructured provides a potent solution to these problems. Databricks provides scalable computing power, a unified data lakehouse architecture, and a suite of robust machine learning and analytics tools. Meanwhile, Unstructured excels at streamlining the complex process of ingesting, understanding, and pre-processing unstructured data from various sources. Together, they transform raw, chaotic data into a well-structured asset, ready to fuel insights that drive innovation and growth.
Key Features and Benefits
Databricks provides a robust set of features designed to handle data challenges. Its scalable lakehouse architecture efficiently manages data of all sizes while advanced analytics and machine learning capabilities enable deep insights. Unified data governance ensures control, security, and compliance throughout the data lifecycle. Additionally, AI-powered data discovery and monitoring provide visibility and proactive problem resolution. Open data-sharing formats promote collaboration and break down information silos.
Unstructured complements Databricks with advanced document extraction capabilities, accurately pinpointing valuable information within various file types. This adaptability proves crucial in real-world applications. Unstructured also offers core functionalities like partitioning, cleaning, and extracting, ensuring data is ready for analysis. Optimized connectors seamlessly move data into Databricks, creating a smooth and efficient workflow. Together, Databricks and Unstructured offer a powerful solution for organizations seeking to unlock the potential of their unstructured data.
Reference Architecture
This blog post will exemplify how businesses can bridge the gap between unstructured and semi-structured data collection and analysis, thereby unlocking the full potential of their data assets. It will construct a seamless data pipeline integrating Unstructured's robust data processing capabilities with Databrick’s powerful analytical platform.
The blueprint for our build is a two-part connector system where the Dropbox Source Connector serves as the entry point for unstructured data, harnessing Dropbox's vast storage solutions to feed raw documents into Unstructured. Unstructured then acts as the processing powerhouse, utilizing advanced algorithms to parse, partition, and refine raw unstructured data into JSON format. The processed data is transferred through the Databricks Volume Destination Connector, which efficiently ingests the refined data into the Databricks Volumes. This Databricks ecosystem will enable us to leverage sophisticated data analytics, artificial intelligence, and machine learning models to extract actionable insights and drive data-driven decision-making.

Figure 1. Unstructured’s end-to-end data ingestion and processing using Dropbox Source Connector and Databricks Volume Destination Connector
We will use two primary examples to illustrate our point:
- An Excel spreadsheet (XLSX file) containing detailed financial operating segments and revenue results, represented in structured tables and textual notes. This document combines numerical data with text, making it a quintessential example of semi-structured data.
- The second example is a PDF document showing Apple’s condensed consolidated statement of operations, presenting net sales, cost of sales, and earnings per share, among other financial metrics, in a tabular format interspersed with textual information.
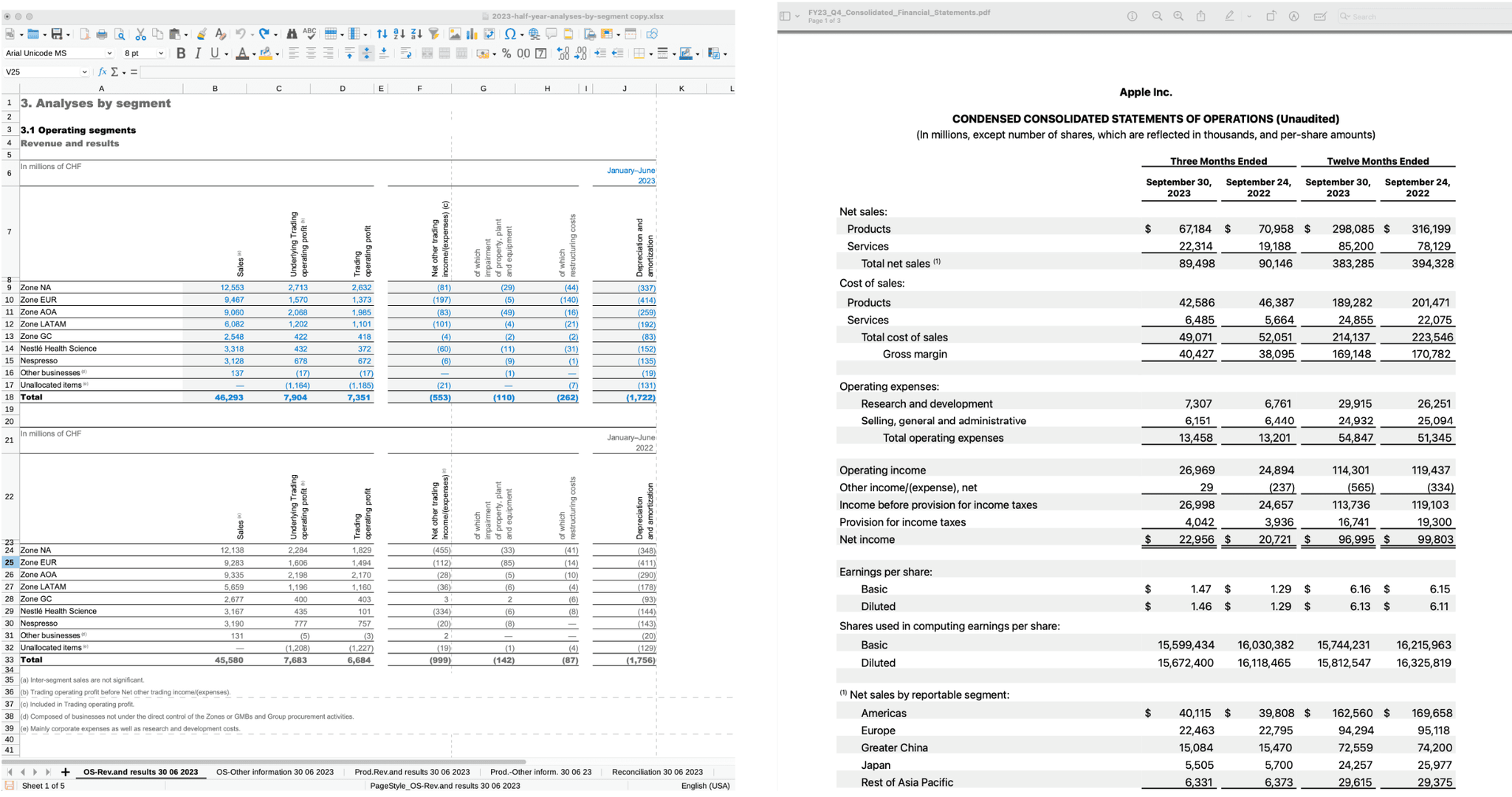
Figure 2. Examples of semi-structured data processing in Excel and PDF files
Streamlining Document Ingestion and Processing with Unstructured's Python Library
In this section, we dive into a Python code example showcasing the power and flexibility of Unstructured's library for document ingestion and processing. We'll explore how to seamlessly connect Dropbox as a source, extract and process documents, and ultimately store the structured output in Databricks Volumes using the destination connector. If you'd like to follow along, the code in this example is available here.
Pre-Requirements
To use the code below, please ensure you have created the following:
- Dropbox: shared folder and API Key
- Unstructured: API Key
Setting the Stage: Environment Variables in Databricks Notebook
The code first starts by importing the following required Python libraries for Unstructured.
%pip install httpx "unstructured[pdf, dropbox, databricks-volumes]"
dbutils.library.restartPython()The code begins by initializing essential variables within a Databricks Notebook. These variables securely store sensitive information like Dropbox and Databricks access tokens, ensuring safe and controlled access to data sources and destinations. Databricks Secrets provides a secure method for storing and referencing credentials (e.g., those required for authenticating to external data sources) without directly entering sensitive information into notebooks or jobs.
# Initialize variables
# We use Databricks secrets to store confidential credentials
DROPBOX_TOKEN = dbutils.secrets.get("prasad_kona", "DROPBOX_API_TOKEN")
DATABRICKS_HOST = "https://" + spark.conf.get("spark.databricks.workspaceUrl")
DATABRICKS_HOSTNAME = dbutils.secrets.get("databricks_secrets_scope_name", "DATABRICKS_HOSTNAME")
DATABRICKS_USERNAME = dbutils.secrets.get("databricks_secrets_scope_name", "DATABRICKS_USERNAME")
DATABRICKS_TOKEN = dbutils.secrets.get("databricks_secrets_scope_name", "DATABRICKS_USER_TOKEN")
UNSTRUCTURED_API_KEY = dbutils.secrets.get("databricks_secrets_scope_name", "UNSTRUCTURED_API_KEY")
# Set the names for the Catalog -> Schema -> Table to be used
catalog_name = "catalog_name"
schema_name = "schema_name"
volume_name = "volume_name"
# The raw source files are stored in the folder here. This is used by UnstructuredIO Source connector
download_dir_name = f"/Volumes/{catalog_name}/{schema_name}/{volume_name}/unstructured_io/raw"
# The volume + folder path used by the UnstructuredIO Destination connector
processed_output_volume_path = f"{volume_name}/unstructured_io"
# The volume + folder path where the processed data files as JSON are stored
processed_output_volume_fullpath = f"/Volumes/{catalog_name}/{schema_name}/{processed_output_volume_path}/structured-output"Configuring and Running the Ingestion Pipeline
Next, the necessary libraries are imported. This includes modules from Unstructured's ingest package, which provide connector configuration, data processing, and writing output functionalities.
The code defines several configuration objects to customize the ingestion pipeline:
- PartitionConfig configures document partitioning, enabling options like API-based partitioning and specifying the Unstructured API key.
- ProcessorConfig configures the overall processing behavior, including verbosity, output directory, and the number of processes for parallel execution.
- ReadConfig specifies the download directory for retrieved documents and controls download behavior.
- ChunkingConfig defines how documents are split into smaller context-aware chunks, which is crucial for tasks like embedding generation.
- EmbeddingConfig specifies the embedding provider and model for generating vector representations of the processed data.
The code leverages Unstructured's connector framework to connect from Dropbox and Databricks Volumes seamlessly:
- DropboxRunner object is configured with the previously defined configurations and a SimpleDropboxConfig object that specifies Dropbox access credentials and the remote directory to access.
- DatabricksVolumesWriter object handles writing the processed data for Databricks Volumes. It utilizes SimpleDatabricksVolumesConfig and DatabricksVolumesWriteConfig objects to specify connection details and the target volume for storing the output.
With all configurations and connectors in place, the run() method of the DropboxRunner object is invoked to initiate the ingestion and processing pipeline. This triggers the following steps:
- Download: Documents are retrieved from the specified Dropbox directory.
- Partitioning: Documents are segmented into logical units based on the chosen partitioning strategy.
- Processing: Each document partition is processed according to the defined configurations, potentially including chunking and embedding generation.
- Writing: The processed data is written in a structured JSON format to the designated Databricks Volume.
import os
from unstructured.ingest.connector.fsspec.dropbox import DropboxAccessConfig, SimpleDropboxConfig
from unstructured.ingest.interfaces import (
PartitionConfig,
ProcessorConfig,
ReadConfig,
)
from unstructured.ingest.runner import DropboxRunner
from unstructured.ingest.connector.databricks_volumes import (
DatabricksVolumesAccessConfig,
DatabricksVolumesWriteConfig,
SimpleDatabricksVolumesConfig,
)
from unstructured.ingest.connector.local import SimpleLocalConfig
from unstructured.ingest.interfaces import (
ChunkingConfig,
EmbeddingConfig,
PartitionConfig,
ProcessorConfig,
ReadConfig,
)
from unstructured.ingest.runner import LocalRunner
from unstructured.ingest.runner.writers.base_writer import Writer
from unstructured.ingest.runner.writers.databricks_volumes import (
DatabricksVolumesWriter,
)
def get_writer() -> Writer:
return DatabricksVolumesWriter(
connector_config=SimpleDatabricksVolumesConfig(
host= DATABRICKS_HOSTNAME,
access_config=DatabricksVolumesAccessConfig(
username=DATABRICKS_USERNAME,
password=DATABRICKS_TOKEN
),
),
write_config=DatabricksVolumesWriteConfig(
catalog=catalog_name,
schema=schema_name,
volume=processed_output_volume_path
),
)
if __name__ == "__main__":
writer = get_writer()
runner = DropboxRunner(
processor_config=ProcessorConfig(
verbose=True,
num_processes=2,
),
read_config=ReadConfig(
download_dir=download_dir_name
),
partition_config=PartitionConfig(
partition_by_api=True,
api_key="YOUR UNSTRUCTURED API KEY",
partition_endpoint="https://YOUR-SAAS-API-URL/general/v0/general"
),
chunking_config=ChunkingConfig(
chunking_strategy="by_title",
),
embedding_config=EmbeddingConfig(
provider="langchain-huggingface",
),
connector_config=SimpleDropboxConfig(
access_config=DropboxAccessConfig(
token=DROPBOX_TOKEN
),
remote_url="dropbox:// /",
recursive=True,
),
writer=writer,
writer_kwargs={},
)
runner.run()By default, the file partition will run on the local machine. To use the Unstructured SaaS API, you can enable partition_by_api parameter in the partition_config and provide your API Key and URL.
Unstructured's Python library provides a powerful and versatile framework for streamlining document ingestion and processing workflows. By leveraging its modular design and diverse connector ecosystem, users can build customized pipelines that efficiently extract valuable information from documents and store it in a structured format for further analysis and utilization.
While the provided code showcases a basic example, Unstructured's library offers extensive flexibility and customization options. Users can tap into various source connectors beyond Dropbox, including local filesystems, S3 buckets, and more. The processing steps can be tailored to specific needs, with options for document parsing, table extraction, and custom data transformations. Additionally, users can choose from different embedding providers and models to generate vector representations that best suit their downstream applications. Finally, Unstructured provides Databricks Unity Catalog Volume destination connector, allowing processed data to be stored in Databricks for further analysis and utilization.
The processed data can then be queried on Databricks using SQL. The processed data is typically inserted into a table backed by Databricks Unity Catalog, which provides all the security and governance one needs.
select * from
json.`{processed_output_volume_fullpath}/030521-2-The-Delta-Lake-Series-Complete-Collection.pdf.json`
insert into catalog_name.schema_name.processed_data_table
select * from
json.`{processed_output_volume_fullpath}/030521-2-The-Delta-Lake-Series-Complete-Collection.pdf.json`Where to Go for More Information
This blog post has demonstrated the transformative power of combining Databricks and Unstructured to tackle the challenges of unstructured data.
By integrating these platforms, you can unlock hidden insights, drive innovation, and gain a competitive edge. But the journey doesn't end here. Databricks offers a compelling opportunity to experience the power and flexibility of a unified data and AI platform. With a free 14-day trial, you can explore the full range of features, from simplified data ingestion and automated ETL to building high-quality generative AI applications. By leveraging the platform's superior price/performance compared to traditional cloud data warehouses, you can unlock new possibilities for data-driven insights and innovation. Sign up today and join the thousands of organizations worldwide that trust Databricks to transform their data into tangible business value.
Obtain your Unstructured SaaS API key and explore our documentation to leverage the power of unstructured data ingestion and transformation fully. We also invite you to join the Unstructured Slack Community. Within this vibrant community, you'll gain direct access to Unstructured experts for personalized guidance, enjoy a collaborative environment for sharing knowledge and best practices with fellow users, and receive early access to new features and updates.


