
Authors

Document parsing sounds straightforward until you try to measure it fairly. How do you know if your document preprocessing pipeline is actually working well? What metrics matter for downstream tasks like RAG or search? And how do you evaluate systems that might produce semantically correct but structurally different outputs?
At Unstructured, we've learned that traditional evaluation approaches often miss the mark. A system that gets penalized for representing a table in HTML instead of plain text might actually be providing richer, more useful output. Another might score near perfectly on character matching but introduce subtle hallucinations that break downstream applications.
This post shares how we think about evaluation, why we developed our own framework, and what we've learned about measuring what actually matters in production document processing.
Why Standard Metrics Fall Short
Most document parsing evaluations assume there's one "correct" way to extract content from a document. But modern generative systems often produce outputs that are semantically accurate yet structurally different from ground truth annotations.
Consider a simple quarterly revenue table:
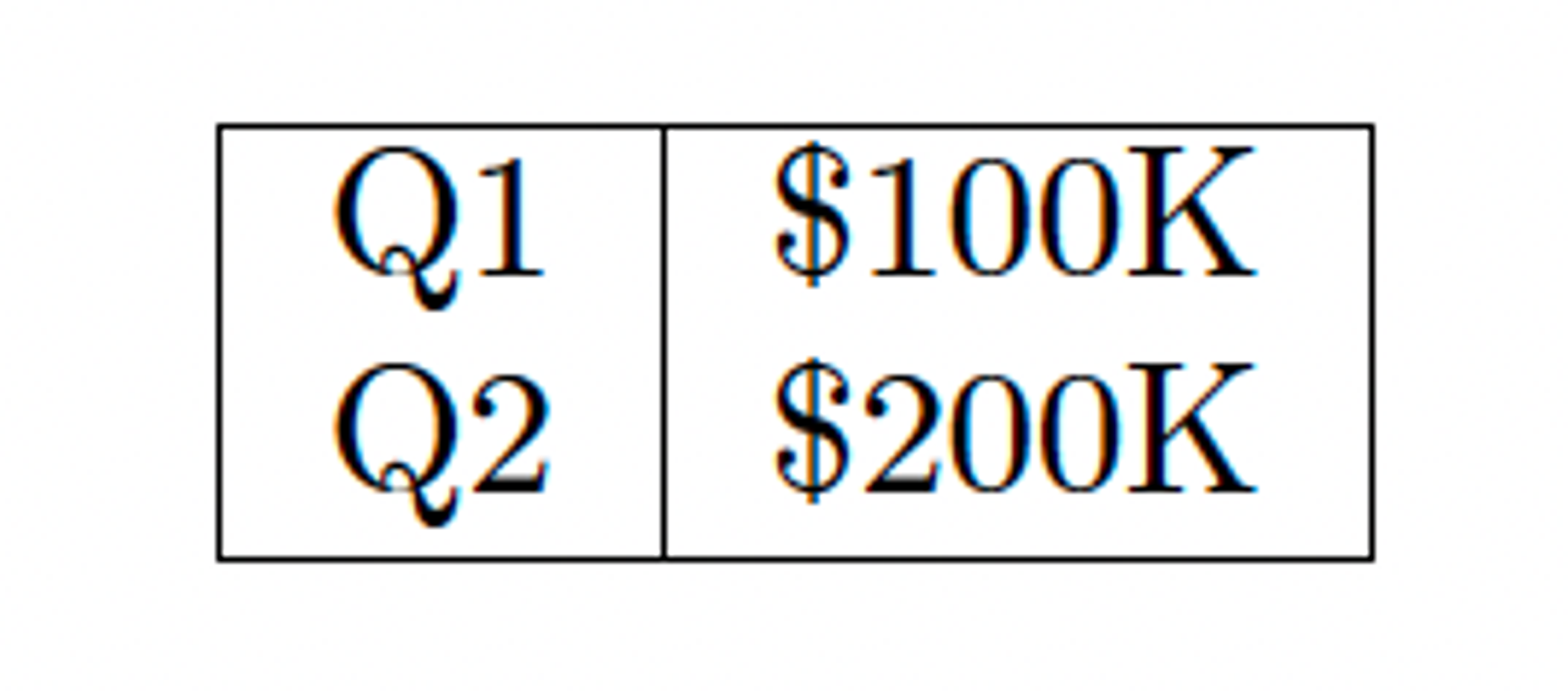
One system might extract it as:
Q1 $100K Q2 $200KAnother might output:
<table>
<tr><td>Q1</td><td>Q2</td></tr>
<tr><td>$100K</td><td>$200K</td></tr>
</table>Traditional metrics would penalize the HTML version heavily, despite it capturing the same semantic content with additional structural information that can be valuable for downstream processing.
This mismatch creates systematic biases in evaluation, potentially misleading research directions and deployment decisions.
Our Evaluation Philosophy: SCORE Framework
We recently developed SCORE (Structural and COntent Robust Evaluation), an interpretation-agnostic framework that addresses four fundamental limitations of current evaluation approaches:
1. Moving Beyond Deterministic Assumptions
Traditional metrics assume single correct outputs. Our framework recognizes that document parsing naturally yields multiple valid interpretations, especially for complex layouts.
A quarterly revenue table with Q1=$100K, Q2=$200K could be extracted as "Q1 $100K Q2 $200K" (row-wise) or "Q1 Q2 $100K $200K" (column-wise). Both preserve the same information, but traditional metrics would penalize one as "wrong."
What we do differently: we use adjusted edit distance that tolerates structural reorganization while maintaining semantic rigor. If two systems represent the same table data differently but preserve all the key-value relationships, we treat them as equivalent.
2. Format-Agnostic Evaluation
Legacy approaches can't meaningfully compare HTML vs. JSON vs. plain text outputs. Our framework normalizes diverse formats into unified representations for fair comparison.
For example, whether a parser outputs <td>Revenue</td><td>$100K</td>, {"cell": "Revenue", "value": "$100K"}, or "Revenue: $100K", we convert them to a common semantic form that captures content, structure, and relationships consistently.
3. Semantic-Aware Scoring
Character-based metrics miss semantic equivalence. A system that correctly interprets "Table 1" as "Tab. 1" receives an identical penalty to one that completely misrecognizes content, despite vastly different implications.
In our approach, we separate content accuracy from formatting differences, using fuzzy matching for legitimate variations while maintaining strict standards for actual content errors.
4. Spatial Intelligence for Tables
Traditional table evaluation relies on bounding box overlap (IoU), but generative systems don't produce explicit coordinates. We developed semantic-first table detection that scores based on content similarity rather than boundary matching.
Our table evaluation includes spatial tolerance for legitimate structural variations (like merged headers) while still catching genuine layout errors. We measure both content accuracy (did we get the text right?) and index accuracy (are the relationships preserved?) separately.
Our Evaluation Metrics in Practice
Multi-Dimensional Assessment
Rather than single-number scores, we evaluate across complementary dimensions:
Content Fidelity (Adjusted NED)
Measures semantic preservation while tolerating format differences. For example, a quarterly revenue table extracted as "Q1 $100K Q2 $200K" versus "Q1 Q2 $100K $200K" contains identical information despite structural differences. High adjusted NED with lower raw NED indicates benign formatting variations rather than content errors.
Hallucination Control (Tokens Added %)
Tracks spurious content introduction. When a system outputs ”{Q1, Q2, $100K, $300K, $100K}” where the original document showed ”{Q1, $100K, Q2, $200K}”, that represents fabricated content. Measuring these issues is critical for downstream applications where precision matters as much as recall.
Coverage Assessment (Tokens Found %)
Measures completeness. If ground truth contains {Q1, $100K, Q2, $200K} but the system only captures {Q1, $100K, Q2}, the missing "$200K" token represents a knowledge gap that can increase hallucination risk in RAG applications.
Structural Understanding (Hierarchy Consistency)
Evaluates whether systems maintain coherent document organization across similar contexts. For example, system labels such as "title," "sub-title," and "sub-heading" all map to the functional category "TITLE," enabling semantic-level comparison across different labeling schemes.
Table-Specific Metrics
- Semantic-first detection: Content-based rather than boundary-based scoring
- Granular cell analysis: Separate content accuracy from spatial relationships
- Spatial tolerance: Accommodates legitimate structural variations
- TEDS (Tree Edit Distance-based Similarity) integration: Captures hierarchical relationships
Our Evaluation Dataset: Real-World Complexity
We built our evaluation dataset to reflect the chaos of real enterprise content. It includes documents totaling hundreds of pages, spanning multiple enterprise verticals and presenting a variety of technical challenges.
- Domains: Healthcare documentation, financial reports, internal policies, manufacturing manuals, and more
- Content types: Tables, forms, multi-column layouts, charts, footnotes, handwritten annotations, etc.
- Quality spectrum: Clean originals, photocopies, fax-quality scans, mobile captures
This isn't a curated showcase of perfect documents. It's the messy reality of what most organizations actually process: partially scanned invoices, presentation slides with multi-column layouts, financial reports with deeply nested tables, and claims filled out by hand.
Why Dataset Matters
The document processing space is full of impressive benchmark claims, but most evaluations test on clean, academic datasets that don't represent real-world complexity. A parser that excels on research papers might struggle with your scanned invoices. One optimized for financial reports might miss critical information in your technical documentation.
Our dataset deliberately includes edge cases and challenging documents because that's where parsing systems either prove their worth or reveal their limitations. The difference between 95% accuracy on pristine PDFs versus 85% accuracy on real-world scanned documents often separates production-ready systems from those that break down on real-world inputs.
Dataset Limitations and Transparency
While we'd love to open-source the complete dataset for full transparency, a significant portion consists of real enterprise documents provided by customers under confidentiality agreements. These include sensitive information that cannot be publicly shared.
However, the evaluation methodology itself is the valuable contribution that can be adapted to any document collection. The principles we've developed work regardless of domain or document type.
What We've Learned
Through extensive evaluation using the SCORE framework across 1,114 pages from diverse document sources, we've uncovered several critical insights that challenge conventional wisdom about document parsing evaluation and system performance.
Traditional Metrics Create Systematic Ranking Distortions
Our analysis revealed that conventional evaluation approaches systematically misclassify valid interpretations as errors, leading to distorted system rankings. In 2-5% of pages containing ambiguous table structures, raw NED scores diverged by 12-25% between systems, completely altering competitive standings.
For example, traditional metrics initially made GPT-4o Mini appear weaker than Gemini 2.5 Flash (0.888 vs. 0.891 unadjusted NED), despite the systems achieving near equivalence once interpretation differences were properly accounted for (0.896 vs. 0.895 adjusted NED). This wasn't a minor statistical fluctuation but a fundamental measurement problem that could lead to incorrect technology choices.
TEDS exhibited similar inconsistencies, with system rankings reversing across different datasets due to sensitivity to representational variance rather than actual extraction quality. These findings demonstrate that single-metric evaluation can be dangerously misleading for system selection.
Multi-Dimensional Performance Reveals System Profiles
When we separated evaluation into complementary dimensions, distinct system characteristics emerged that single scores completely obscured:
- Content Fidelity Leaders: Gemini 2.5 consistently achieved the highest adjusted NED scores (0.895 on our primary dataset, 0.883 on industry documents) and superior token coverage (TokensFound = 0.955), making it optimal for high-fidelity content extraction tasks.
- Hallucination Control Champions: GPT-4o Mini demonstrated the lowest hallucination rates across two datasets (TokensAdded = 0.043/0.039), though with less consistent content fidelity. This makes it ideal for applications where precision is paramount, like legal document processing where spurious content could have serious consequences.
- Structural Understanding Specialists: Claude Sonnet 4 emphasized structural accuracy over raw coverage, excelling in hierarchy-aware consistency (0.403 vs. industry average of 0.352) while maintaining competitive content extraction. This profile suits complex document workflows requiring reliable structural interpretation.
- Deterministic Reliability: Traditional OCR-based methods (our hi_res strategy) performed predictably well for hallucination control, as expected, but revealed surprising inconsistencies in content fidelity across different document types.
These profiles matter because they indicate fundamental architectural differences that affect production behavior, not just benchmark scores.
The "Good Enough" Problem in Document Parsing
One of our most significant findings was that performance differences among top-tier VLM systems are often negligible for real-world applications. Differences of 0.1-0.5% in adjusted NED between leading systems disappear entirely in downstream task performance.
This suggests that system selection should prioritize operational characteristics (API reliability, cost, latency, integration complexity) over marginal accuracy improvements. A system that's 2% more accurate but 10x more expensive rarely delivers proportional business value.
Format Rigidity Masks System Capabilities
Our format-agnostic evaluation revealed that many apparent system weaknesses were actually evaluation artifacts. Systems generating semantically rich HTML output with proper hierarchical structure and visual context were being penalized by metrics designed for plain text extraction.
Consider this concrete example from our evaluation: A ground-truth table encoded as coordinate-based cells received a TEDS score of 0.34 when compared to a model's semantically rich HTML output, falsely suggesting significant error. Our cell content accuracy metric correctly recognized semantic preservation (0.68), revealing the model's actual performance.
This pattern appeared repeatedly: systems optimized for downstream task success were punished by metrics optimized for surface-level matching. Format-agnostic evaluation corrected these biases and revealed systems' true capabilities.
Cross-Dataset Consistency Predicts Production Reliability
Systems showing stable relative performance across our primary dataset and industry documents proved more reliable in production deployments. Those with high variance between datasets often had hidden dependencies on document characteristics not obvious in single-dataset evaluation.
Gemini 2.5 maintained consistent leading performance (0.895→0.883 adjusted NED), while other systems showed larger performance swings, indicating potential brittleness in real-world conditions with varied document quality and formatting.
The Interpretive Diversity Paradox
We discovered that systems capable of greater interpretive diversity—those that could represent the same content in multiple valid ways—were systematically penalized by traditional metrics, despite often providing richer, more useful output for downstream applications.
This creates a measurement paradox: the more sophisticated a system becomes at understanding document semantics and providing contextually appropriate representations, the more traditional evaluation frameworks punish it. Our adjusted metrics corrected this bias, revealing that interpretive flexibility often correlates with better downstream task performance.
Consistency Challenges Reveal Evaluation Limits
Across all systems, consistency scores remained relatively low (0.195-0.474) due to the inherent ambiguity in document structure interpretation. Multiple plausible reading orders and segmentation strategies often exist for the same document, making high consistency scores inherently difficult to achieve.
This finding reinforced a critical insight: perfect consistency may not be a reasonable evaluation goal. Instead, we should measure whether systems maintain coherent interpretations within reasonable bounds of human judgment.
The Production Reality Gap
Perhaps most importantly, we learned that laboratory performance metrics often fail to predict production success. Systems with impressive benchmark scores sometimes failed in production due to factors unmeasured by traditional evaluation: edge case handling, computational efficiency, integration complexity, and operational reliability.
Our framework addresses this by focusing on metrics that correlate with downstream task success rather than abstract measures of extraction completeness. When evaluation aligns with actual use case requirements, system selection becomes far more reliable.
The Future of Document Parsing Evaluation
As generative document parsing systems become more sophisticated, evaluation frameworks must evolve beyond rigid string matching. Accuracy alone is no longer enough. We need approaches that:
- Embrace interpretive diversity while enforcing semantic accuracy — recognizing that different models may structure information differently while still preserving meaning.
- Provide actionable diagnostics rather than single scores — going beyond “how well did it do” to uncover why a parser succeeds or fails, and what trade-offs it makes.
- Incorporate operational metrics — measuring not just correctness, but also latency, throughput, cost efficiency, and robustness to noisy real-world inputs.
- Align evaluation with downstream application success — ensuring that the signals we measure actually predict performance in retrieval, search, or agentic workflows.
- Enable fair comparison across architectural approaches — accounting for the fact that structured extractors, LLM-based systems, and hybrids often produce semantically equivalent but structurally distinct outputs.
The shift is clear: evaluation is moving away from static benchmarks and toward continuous, multi-dimensional frameworks that reflect real enterprise needs. Our SCORE framework represents one step in this direction. By making evaluation methodology as important as the parsing technology itself, we can make more informed decisions about which approaches work best for specific use cases.
Conclusion
Document processing isn’t a one-size-fits-all problem. The best outcomes come from having the flexibility to choose approaches that align with your data, workflows, and business needs.
That’s why Unstructured doesn’t limit you to a single parser or model. Our platform provides multiple parsing strategies and integrates with leading vision-language models, from Claude to GPT-4o to Gemini, with more added as the field evolves.
Every option is rigorously benchmarked against real-world scenarios. When new models and techniques emerge, we evaluate, optimize, and make them available through the platform if they improve results. This way, you’re never locked into today’s capabilities. Instead, you continuously benefit from tomorrow’s advancements.
Get started with Unstructured or book a call to discuss document preprocessing strategies that would fit your specific document processing scenarios best.
FAQ
What is the SCORE framework, and why was it developed?
SCORE (Structural and COntent Robust Evaluation) is an interpretation-agnostic document parsing evaluation framework designed to address four core limitations of traditional metrics: single-output assumptions, format rigidity, character-based scoring, and boundary-dependent table evaluation. It was developed because existing approaches systematically penalized valid outputs, such as HTML-formatted tables, even when they preserved the same semantic content as plain text alternatives.
Why do standard document parsing metrics produce misleading results?
Most traditional metrics assume there is one correct way to extract content from a document, which means structurally different but semantically equivalent outputs get penalized as errors. This creates ranking distortions where a system generating richer, more structured output can appear weaker than one producing bare text, even when the former is more useful for downstream tasks like retrieval or search.
What should teams actually measure when evaluating a document parsing pipeline?
Rather than relying on a single accuracy score, teams should evaluate across multiple dimensions: content fidelity (are the right tokens preserved?), hallucination rate (is the system adding content that was not in the source?), coverage (is anything missing?), and structural consistency (are document hierarchies coherent?). Each dimension reveals different failure modes that matter differently depending on the downstream application.
How does Unstructured evaluate document parsing quality across different models and strategies?
Unstructured benchmarks parsing strategies and vision-language models, including GPT-4o, Gemini, and Claude, using the SCORE framework across a dataset of real enterprise documents spanning healthcare, finance, manufacturing, and other verticals. Results are broken down by content fidelity, hallucination control, coverage, and structural understanding so that users can select the approach that best fits their specific use case rather than relying on a single composite score.
Does Unstructured lock users into a single parsing model or strategy?
No. The Unstructured platform supports multiple parsing strategies and integrates with leading vision-language models, allowing teams to choose the approach that aligns with their document types, accuracy requirements, and cost constraints. As new models and techniques emerge, Unstructured evaluates and incorporates them into the platform, so users continuously benefit from improvements without needing to rebuild their pipelines.


