
Authors

Imagine triggering a full ETL pipeline with a single sentence—no code, just conversation. In this blog, we show how Claude Desktop can take your data from S3, process it using Unstructured, and store it in a Databricks Delta Table—all through the Model Context Protocol (MCP). It’s a no-code, natural language workflow powered by three modular tools working seamlessly together.
Here’s a quick look at how this all works behind the scenes.
What Is MCP?
Model Context Protocol (MCP), introduced by Anthropic in late 2024, standardizes how AI applications interact with external data sources, acting as a "USB-C port" for AI integrations. Its client-server architecture—comprising MCP Hosts (applications like Claude Desktop that need data access), MCP Servers (which expose capabilities via standard protocols), and MCP Clients (which maintain 1:1 server connections)—enables tool creators and application developers to build modular, reusable components. MCP enables three core functions: Tools (functions invoked by the model), Resources (application-controlled data like files), and Prompts (server-defined templates that help standardize model behavior). Since launch, it has seen rapid adoption across major AI platforms, creating a unified integration layer across model providers. For a more in-depth explanation, check out our earlier blog post here.
Unstructured API: Making Unruly Data LLM-Ready
Unstructured provides a developer-friendly platform for preprocessing unstructured data—an essential prerequisite for any GenAI application. MCP’s role in this is making Unstructured’s advanced capabilities available to LLMs, LLM Agents, and LLM-based applications like Claude Desktop via Unstructured API.
With that context in mind, here’s how you can start talking to your data processing workflows, step by step.
Prerequisites
Unstructured Account
To start transforming your data with Unstructured, contact us to get access—or log in if you're already a user. In the Unstructured UI, click on "API Keys" in the sidebar, then click "Generate API Key", and follow the instructions. You’ll need this to call the Unstructured API.
Amazon S3
While Unstructured can ingest documents from multiple sources, for this example, let’s just stick to Amazon S3.
You’ll need an AWS account, along with your AWS secret key and AWS secret access key for authentication. You'll also need an Amazon S3 bucket with the correct access settings applied.
Refer to this to set up an S3 Bucket and make sure you throw in files of these types for Unstructured to process!
Databricks
We'll be storing the results in a Delta Table in Databricks. If you are creating a new Databricks account, make sure to complete the cloud setup and note the URL of your workspace. Also, ensure that Unity Catalog is enabled within the workspace. For more detailed setup instructions, refer to the documentation page.
Within your Unity Catalog, you will need the following:
- A catalog (e.g., "workspace")
- A schema (e.g., "workspace.default")
- A volume (e.g., "workspace.default.my_volume")
- A SQL warehouse to create and manage tables in your schema
- A table (e.g. “workspace.default.elements”, in this example, we create a table ourselves but you can also let Unstructured create one for you)
After you create and start your SQL warehouse, click on it and go to the Connection Details tab. Copy the values for Server Hostname and HTTP Path.The Unstructured MCP uses Databricks managed service principal for authentication. If you don't have one, create it and grant the service principal the required permissions. Check out this quick tutorial on how you can go about fetching your Service Principal ID and Secret.
Your service principal also needs these permissions:
- In your catalog: USE CATALOG, USE SCHEMA, READ VOLUME, WRITE VOLUME, CREATE TABLE.
- In your SQL warehouse: Can Use permissions.
Integrate Unstructured MCP with Claude Desktop
Step 1: Clone the Repository
git clone https://github.com/Unstructured-IO/UNS-MCP.git
cd UNS-MCPStep 2: Set Up Your Environment
Create a .env file in the root directory of the repository with the following keys:
UNSTRUCTURED_API_KEY="YOUR_API_KEY"
AWS_KEY="<key-here>"
AWS_SECRET="<key-here>"
DATABRICKS_CLIENT_ID="<Service-Principal-ID>"
DATABRICKS_CLIENT_SECRET="<Service-Principal-Secret>"Step 3: Configure Claude Desktop
Navigate to the directory ~/Library/Application Support/Claude/ and create a file named claude_desktop_config.json. The content of this file should define the Unstructured MCP server and its execution parameters. Below is an example of the configuration:
{
"mcpServers": {
"UNS_MCP": {
"command": "ABSOLUTE/PATH/TO/.local/bin/uv",
"args": ["--directory", "ABSOLUTE/PATH/TO/uns-mcp", "run", "server.py"],
"env": {
"UNSTRUCTURED_API_KEY": "<your key>"
},
"disabled": false
}
}
}Restart Claude Desktop to apply the changes. You should now see a hammer icon indicating the tools available to you.
Talk to Claude to build your ETL workflow
With an MCP-enabled client, you can now use natural language prompts to create and run complex workflows. Let’s get started.
Don’t know where to start? Just ask Claude. The tools in the MCP Server give Claude enough context that you do not have to read the docs yourself. 😉
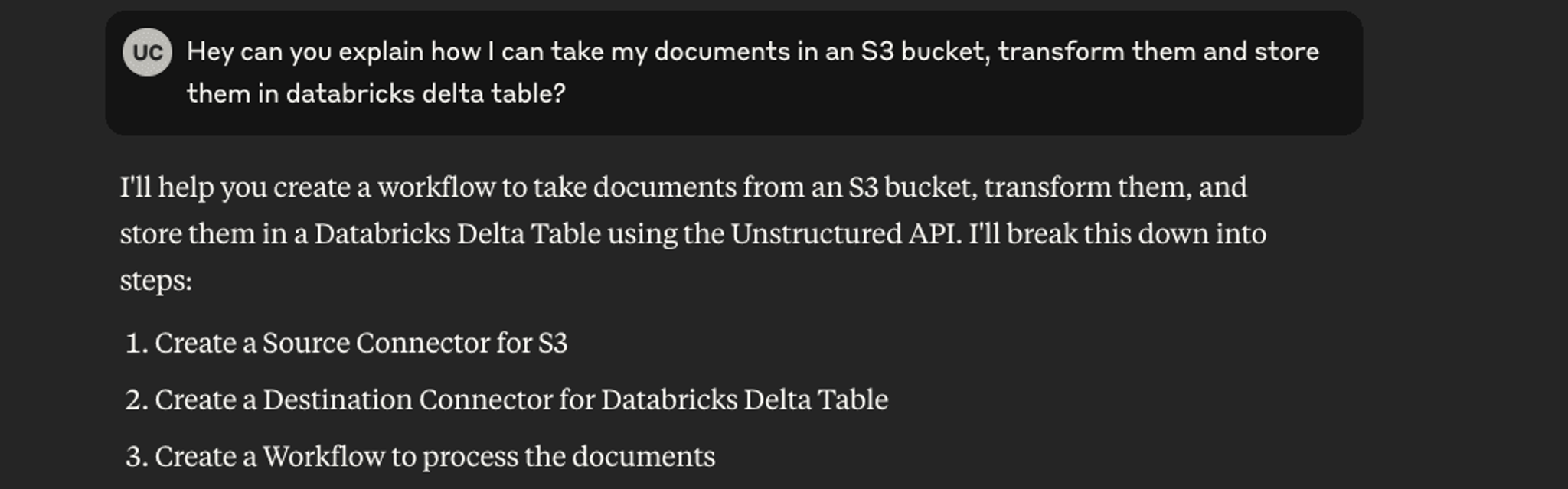

Unstructured MCP Server exposes the functionality to manage Connectors and Workflows. Connectors define how Unstructured connects to data sources and destinations—they don’t store data themselves, but configure the connection to where raw or processed data lives. Workflows define a set of nodes that transform your data from its raw state to an LLM-ready format. Now, let’s set them up.
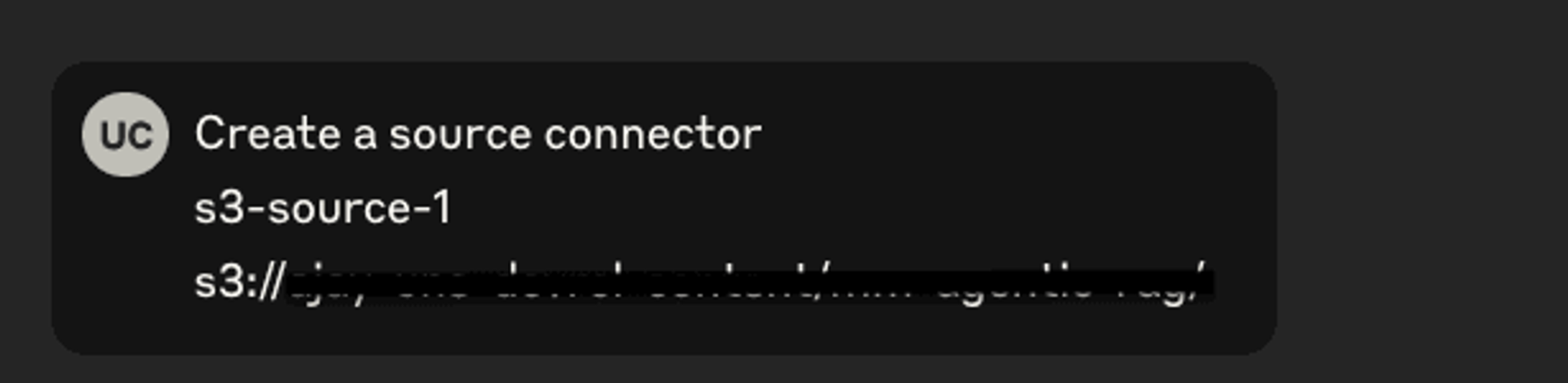
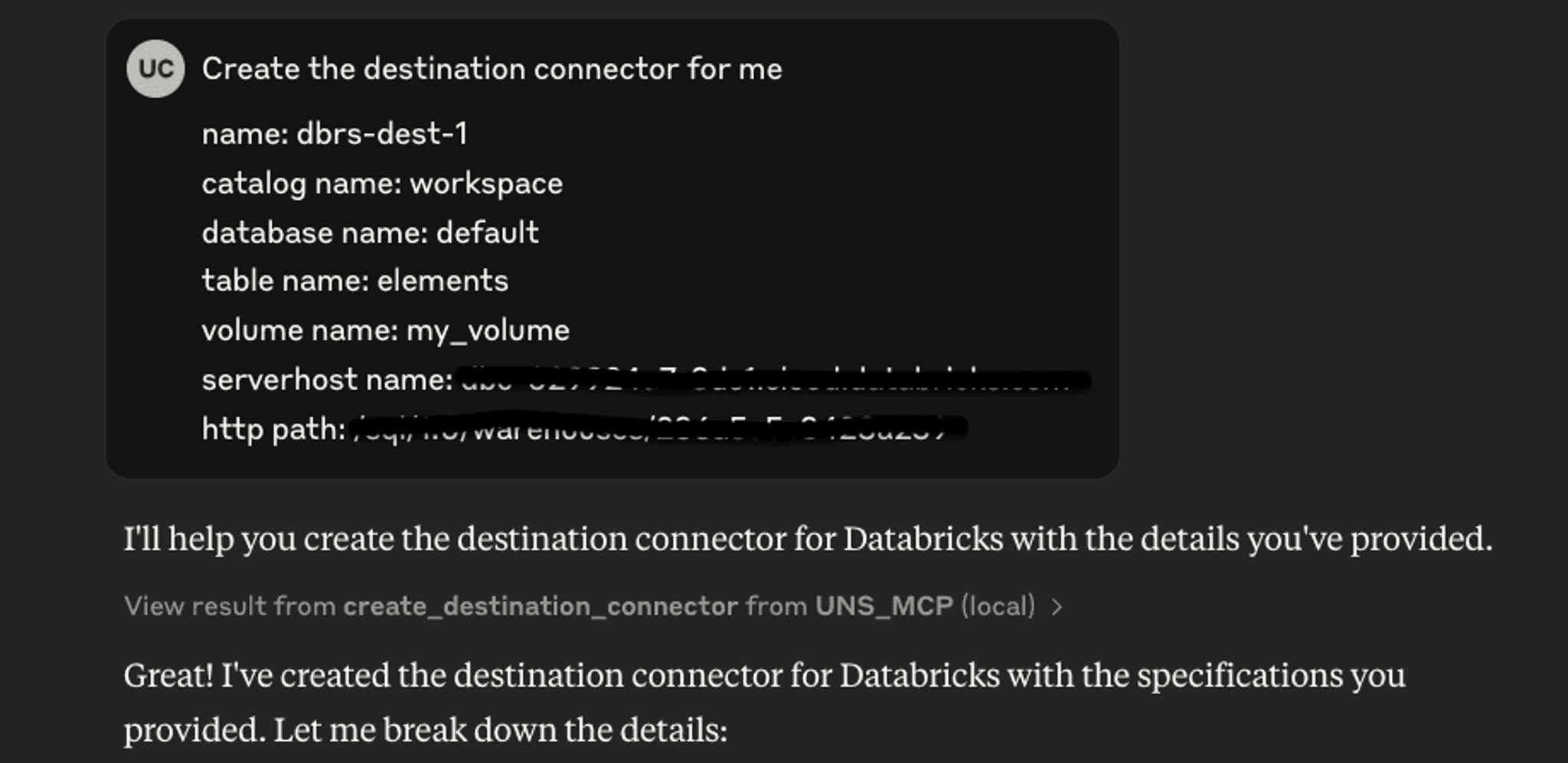
Creating the S3 Source and Delta Tables Destination Connector
To create your connectors, all you have to do is provide the information Claude asked for. Once given, it automatically invokes the necessary tools and creates the connectors for you.
Creating a Workflow
Now that your connectors are ready, let’s define a workflow. A Workflow in Unstructured is a DAG consisting of data transformation and enrichment nodes that automate the data processing from source to destination. There are many different types of nodes available to you, you could either read all about them here or ask Claude to get you enough information to get started.

Let's build a Workflow with our newly created S3 Source and Delta Tables Destination connectors, a Partitioning Node to extract information from documents, and a Chunking Node to convert them into manageable chunks.

The workflow configuration serves as the central orchestrator, connecting the various components of the data pipeline, including the data source, the processing nodes, and the final destination for the processed data. Claude understood what we asked for and created the workflow configuration all by itself. You can also supply your own workflow config for it to create a workflow.
{
`workflow_config`: {
`name`: `s3-to-databricks-fast-workflow`,
`source_id`: `<source connector id>`,
`workflow_type`: `custom`,
`destination_id`: `<destination connector id>`,
`workflow_nodes`: [
{
`name`: `Fast-Partitioner`,
`type`: `partition`,
`subtype`: `unstructured_api`,
`settings`: {
`strategy`: `fast`,
`xml_keep_tags`: false,
`exclude_elements`: [],
`include_page_breaks`: true,
`extract_image_block_types`: [
`image`,
`table`
],
`pdf_infer_table_structure`: true
}
},
{
`name`: `Text-Chunker`,
`type`: `chunk`,
`subtype`: `chunk_by_title`,
`settings`: {
`overlap`: 50,
`max_characters`: 1000,
`multipage_sections`: true,
`combine_text_under_n_chars`: 100
}
}
]
}
}Since Claude understands what tools were available through the MCP Server connection, it automatically asked me if it should execute the next logical step after creating a workflow - running it. Here’s what that looked like in our setup:
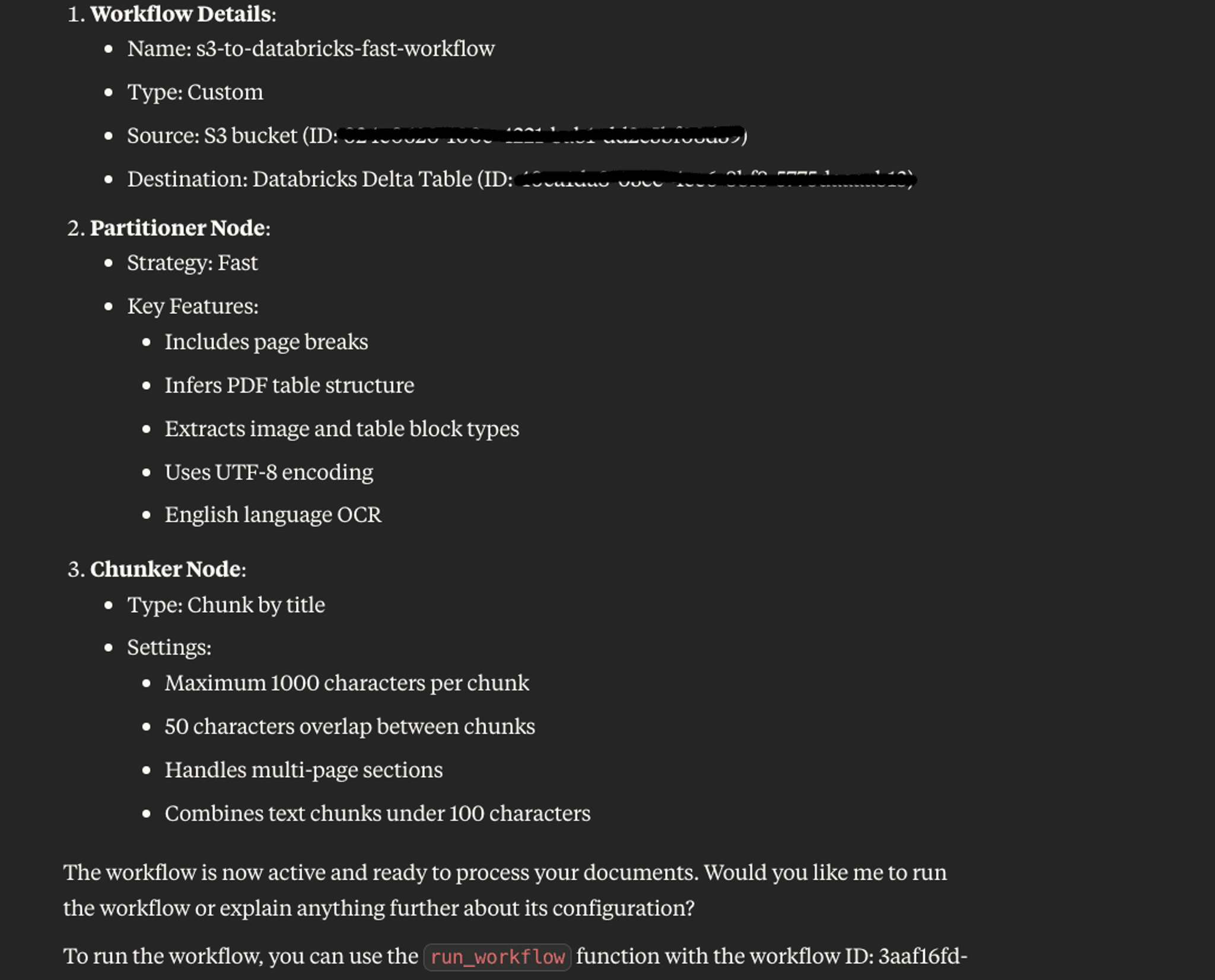
Running and Tracking the Workflow
To track the progress and status of the running workflow, you can simply ask Claude for the status.
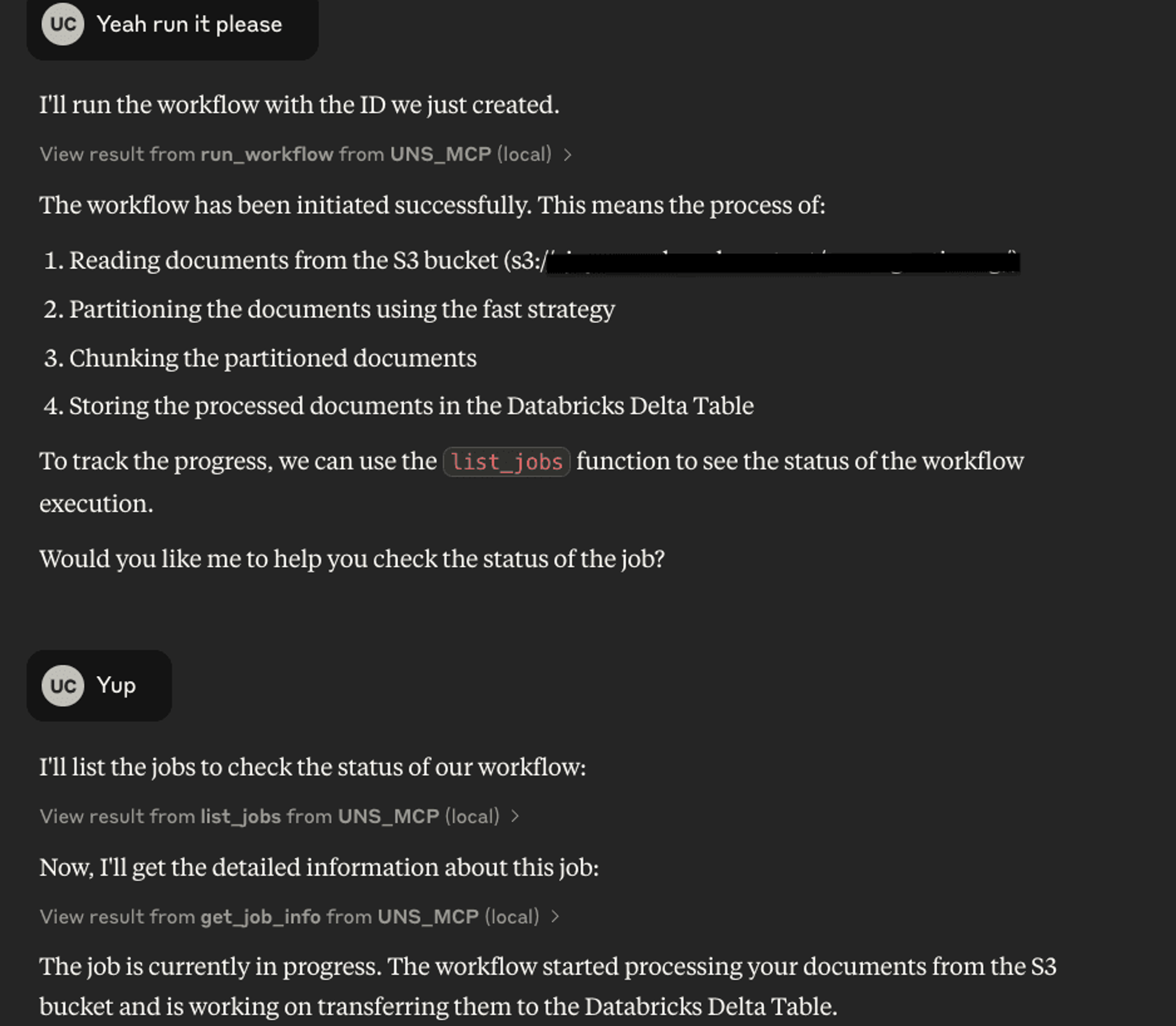
This uses the get_workflow_info MCP tool to retrieve the current status of the workflow. In my demo, it confirmed that the workflow was currently processing my data.
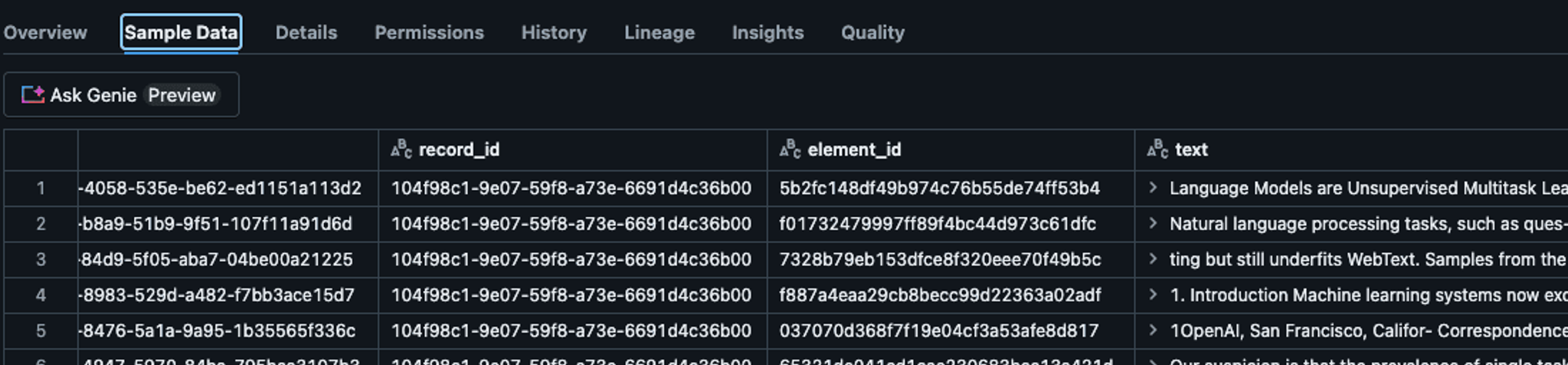
Step 3: View Processed Results
Once the workflow has been completed, it means the results have been processed. You can review the processed data under Sample Data in the catalog you’ve used.
Conclusion
What started as a simple idea—talking to your AI to move and process data—turned into a fully operational ETL pipeline, all without writing a single line of traditional code. By combining MCP’s plug-and-play architecture with the Unstructured platform and Databricks Delta Tables, we built something that feels less like engineering and more like collaboration.
With just a few conversational prompts, we now have an enterprise-grade pipeline processing documents from S3 and feeding structured outputs into Delta Tables. And that’s just the beginning.
This workflow could easily be extended for named entity extraction, summarization, classification, or insight generation—whatever your use case demands.
Ready to try it yourself?
Head over to the Unstructured MCP GitHub repo and make it your own. Share your workflows, experiments, or questions—we're always looking for great community examples to highlight.


