
Authors

Complex table extraction has become a proving ground for document AI architecture. Tables with merged headers, nested hierarchies, and spanning cells aren't just vision problems or just reasoning problems, they demand spatial understanding, semantic interpretation, and structural precision all at once.
The conventional approach has been to build increasingly powerful single models that can handle this complexity end-to-end. But our work on table extraction led us to a different conclusion: we believe that composable, multi-model architectures fundamentally outperform monolithic approaches for complex document understanding.
The principle is straightforward: break the problem down, let specialized models focus on what they do best, and compose their outputs. What we've found is that this architectural choice produces dramatically better results on the documents enterprises actually care about.
This isn't just about tables. It's about how we think document AI should work when fidelity and accuracy matter. Here's what we've learned building our agentic table parsing system, and why we think composability is the future of document understanding.
The Architectural Challenge Tables Reveal
Tables became our testing ground because they expose something fundamental about complex document understanding—they require multiple types of reasoning that pull in different directions.
Let's take this ecological survey table for example. The left side has hierarchical row headers, some cells merge across multiple rows, scientific names appear in italics alongside regular text, and the structure creates nested relationships between elevation zones, vegetation types, and site locations.
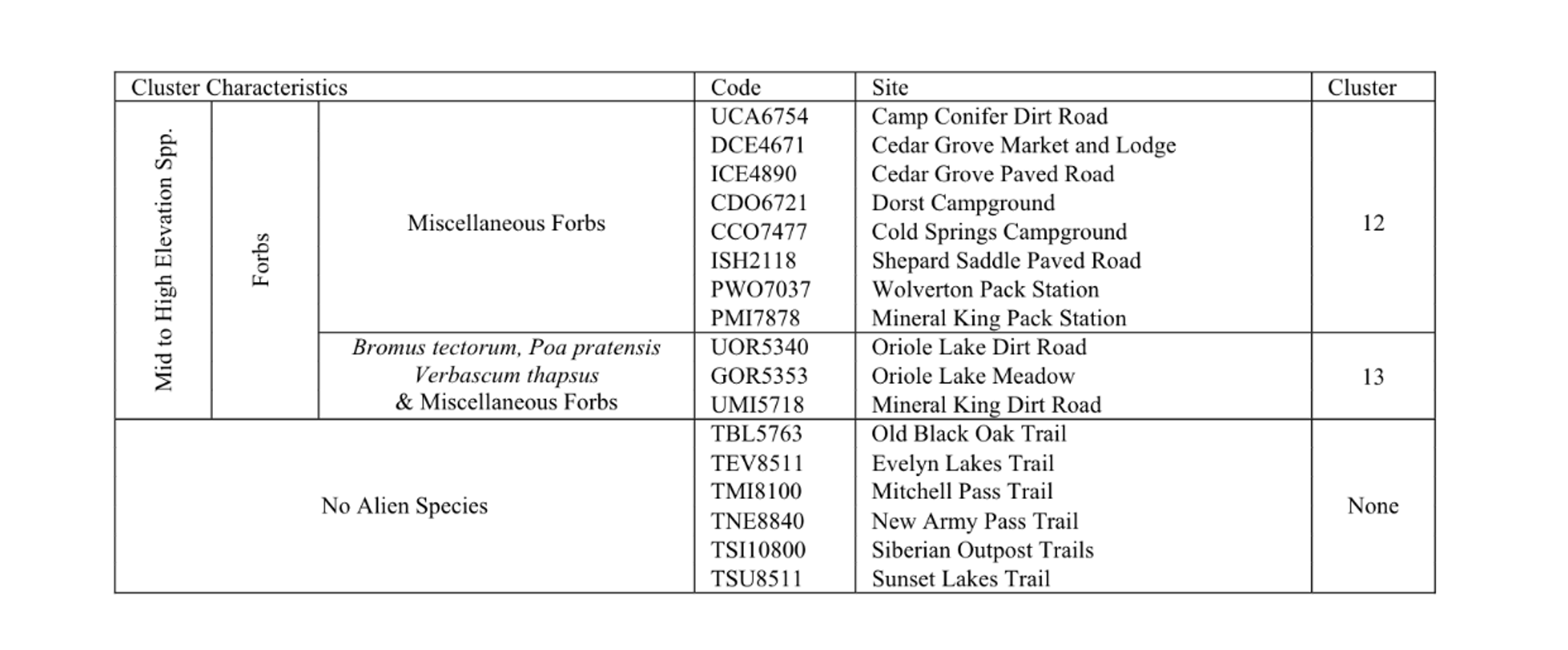
What makes this challenging isn't just accuracy, it's that it simultaneously demands:
Spatial reasoning: Understanding which cells merge, where headers span, how nested structures map to each other across the visual grid.
Semantic interpretation: Distinguishing headers from data, recognizing hierarchical relationships, connecting footnotes to their referenced cells.
Structural precision: Generating HTML that perfectly captures merged cells, spanning relationships, and hierarchical structure where a single misaligned header destroys the table's meaning.
This is why we believe single-model approaches, regardless of scale or capability, hit a fundamental ceiling. When you ask one model to simultaneously "see" the visual layout, "understand" the semantic structure, and "generate" pixel-perfect formatting, you're forcing compromises. Excellence in spatial reasoning might come at the cost of semantic accuracy. Perfect structure generation might mean missing subtle visual cues.
The architectural question became clear: what if we didn't force these compromises? What if we let different models excel at what they're naturally good at, then compose their outputs?
The Composability Principle
Our belief in composable architectures rests on two observations about how models actually perform.
First: models do better work when they can focus. Complex table extraction requires simultaneous spatial reasoning, semantic interpretation, and structural formatting. When one model handles all of this at once, these demands compete. The model balances, compromises. Attention spent on visual precision is attention unavailable for semantic accuracy. Better structure generation might mean missing subtle spatial relationships.
Second: different models have genuinely different strengths. Not just capability differences, but fundamental architectural characteristics. Models are built differently, trained on different data, optimized for different types of reasoning. Some excel at certain kinds of analysis, others at entirely different tasks. These aren't weaknesses to overcome—they're specializations we can leverage.
We believe composability works because it combines both principles. Instead of asking one model to compromise across competing demands, we let specialized models focus on tasks aligned with their natural strengths. A model handling one specific aspect, produces more accurate results on that aspect than a generalist model splitting attention.
The outputs compose together. Each model contributes what it does best. This is orchestrated architecture where task decomposition and model specialization compound each other's advantages.
Agentic Table Parsing: Composability in Practice
We applied these principles to build what we call agentic table parsing—a multi-step, multi-model system that orchestrates specialized models for table extraction.
The "agentic" term describes the architecture: rather than one model handling the entire extraction task, we orchestrate multiple models where each focuses on a specific aspect of the problem. The system decomposes table extraction into focused steps, letting specialized models contribute what they do best.
We believe this architectural approach offers something beyond immediate performance gains. It's extensible. As models improve, as new capabilities emerge, they can be integrated into the system. We're not bound to any single model's limitations. The composable architecture evolves.
This is composability applied: orchestrating specialized models to solve complex document understanding problems that single-model approaches struggle with. The results validate the principle.
Results
We evaluated agentic table parsing on SCORE-Bench, our open benchmark for document parsing.
The results show consistent improvements across all evaluated metrics:
Cell level content accuracy measures how well text is extracted from cells. Cell level index accuracy measures whether the system understands which row and column each piece of text belongs to. Corrected Table TEDS score evaluates how well the extracted table preserves the original hierarchical structure and Shifted cell content accuracy measures robustness to minor positional variations.
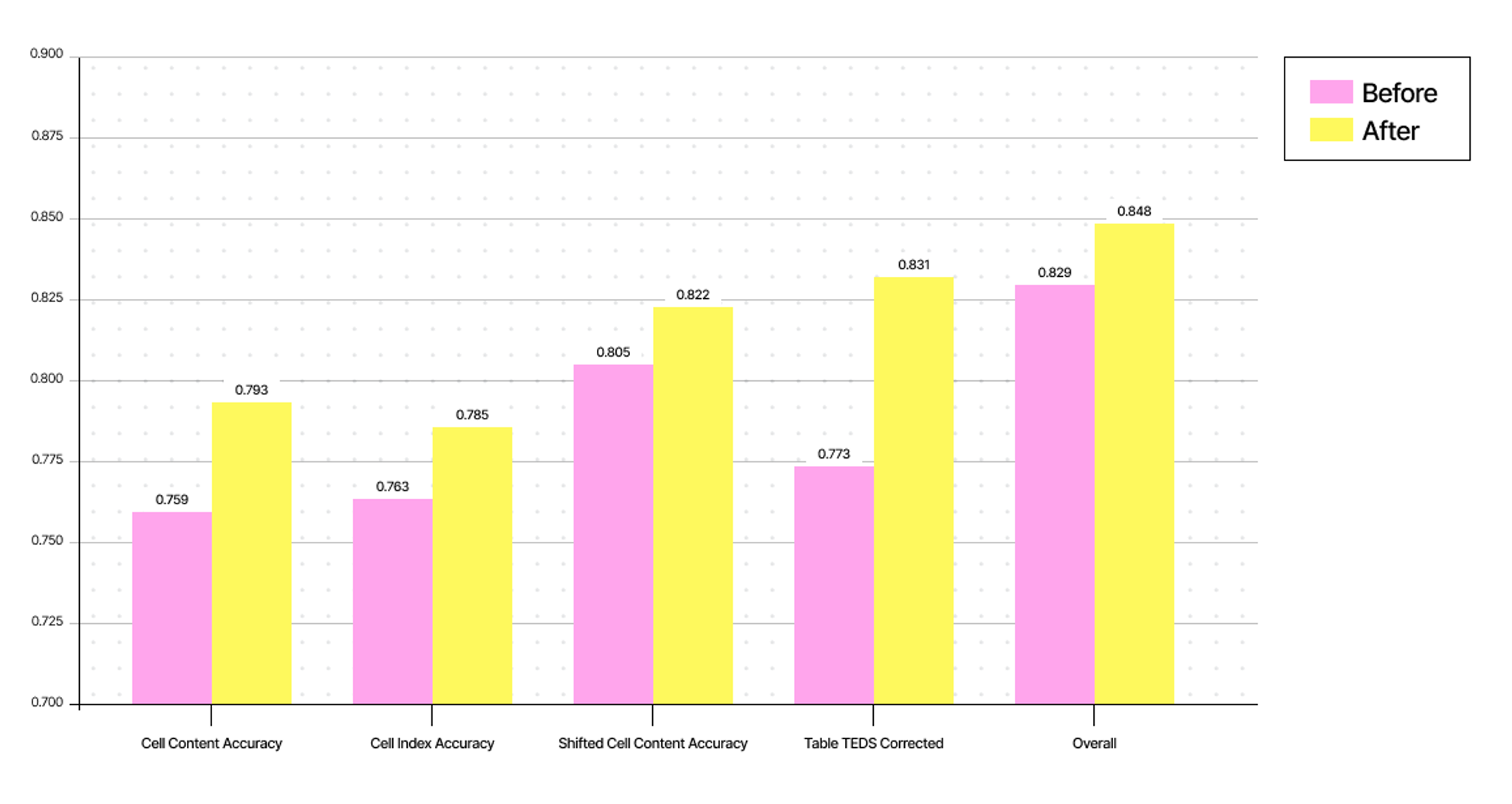
The improvements are particularly notable in structural understanding. Cell level index accuracy—the ability to correctly map content to its position in the table—improved by nearly 3%. Table TEDS Corrected showed a 7.5% improvement, indicating better preservation of table hierarchies and relationships.
Conclusion
We believe complex document understanding requires composable architectures where specialized models work together, each focused on what it does best. Our work on table extraction validates this principle: the results on SCORE-Bench show that orchestrating models outperforms asking any single model to handle everything.
Agentic table parsing demonstrates how this architectural approach delivers on real-world documents.
Try It Yourself
Agentic table parsing is now available on Unstructured. Sign up for free to test it on your documents, or reach out to our team to discuss your document processing needs.


