One platform,
packed with performance.
packed with performance.
Unstructured isn’t just one tool, it’s a complete Gen AI data layer solution. Connect, transform, enrich, and deliver unstructured data at scale with a platform designed to power your biggest GenAI projects.
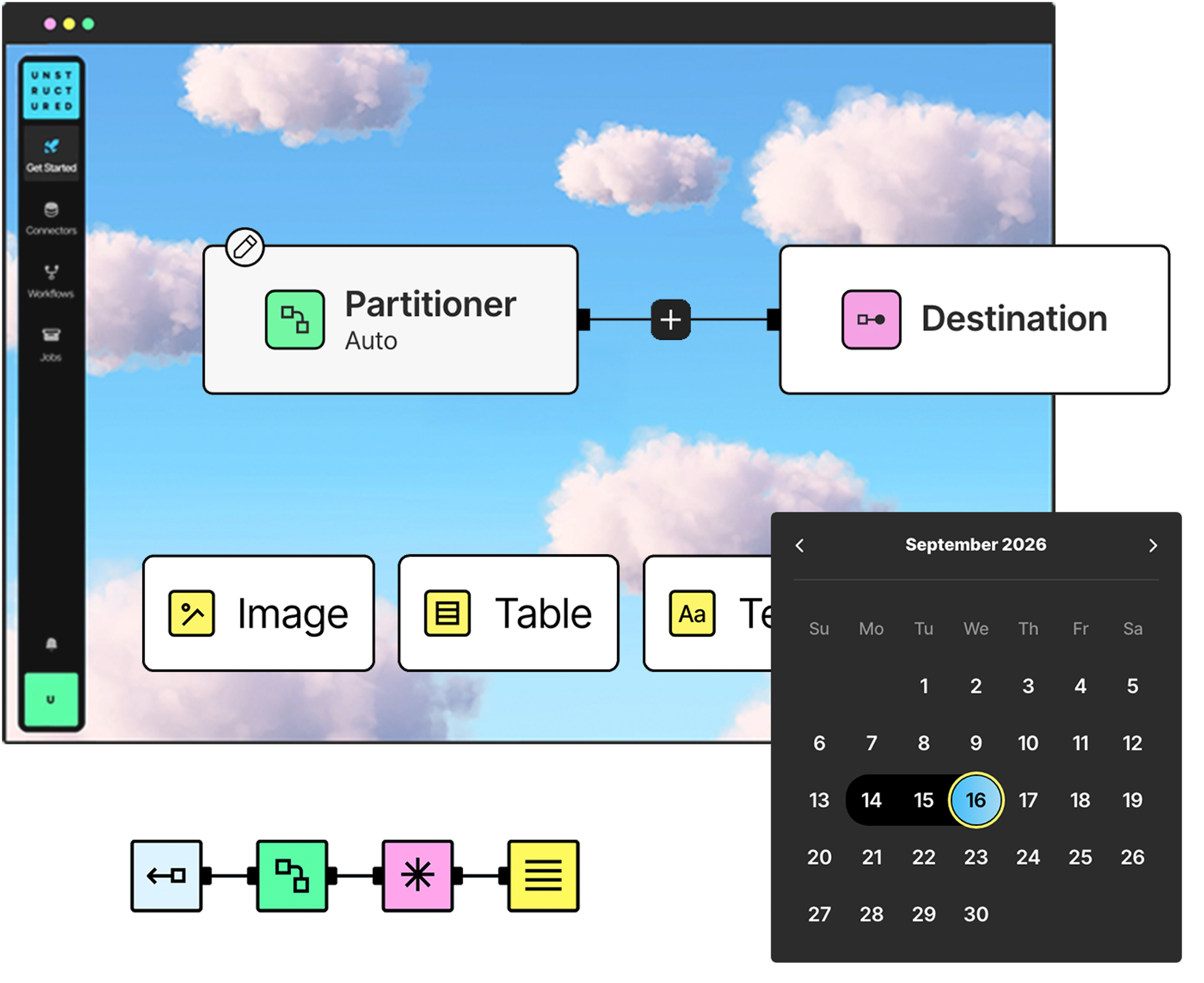
Everything from Azure to Zendesk.
Connecting to unstructured data shouldn’t be complex. With 30+ built-in connectors, Unstructured pulls content from your systems of record and business applications—no custom code required. Every integration works the same way, so your data arrives clean, consistent, and ready to power your AI.
Everything from Azure to Zendesk.
Your data is scattered.We bring it together.
Your unstructured data lives in many places. Our platform lets you extract from multiple sources simultaneously through a single pipeline—standardizing how data is ingested regardless of its origin. Simplify complexity, unify your data, and accelerate your AI projects with consistent, reliable workflows.
Your data is scattered.We bring it together.
No file left behind.
PDFs, spreadsheets, emails, images—you name it, we transform it. Our multi-modal engines seamlessly processes data from 65+ file types, so format limitations are never a concern. Whether it’s a simple Word document or a complex PDF with embedded tables and figures, we handle it all while keeping your data flow smooth and uninterrupted.
No file left behind.
Precise extraction, optimized cost.
Documents vary in complexity, and so should extraction. Unstructured intelligently adjusts its approach for each page, ensuring the highest accuracy while controlling processing costs. The result? Cleaner data, faster processing, and AI-ready content—without the guesswork or unnecessary costs.
Precise extraction, optimized cost.
Optimal chunks for reliable AI outputs.
Chunking is harder than it looks. Too little context, and meaning is lost. Too much, and precision fades. Unstructured helps you find the balance. Our smart chunking strategies create the right chunks for your data, so your AI sees what matters and nothing it doesn’t. This delivers greater accuracy, faster processing, and reliable, actionable insights every time.
Optimal chunks for reliable AI outputs.
More signal, less noise.
Raw data isn’t always ready for AI. Unstructured enriches your content with metadata, structure, and context automatically. From image descriptions to entity recognition and more, we add the signals you need to retrieve and understand your data with precision. No extra tools required. No manual steps. Just smarter inputs, end to end.
More signal, less noise.
Top-tier embeddings à la carte.
Unstructured connects effortlessly with top embedding models so you can choose the one that fits your needs. No fuss. No limits. Just seamless, powerful embeddings that make your data smarter—ready for search, retrieval, and beyond.
Top-tier embeddings à la carte.
Point. Send. Done.
Deliver your enriched data to 30+ destinations—from vector and graph databases to search engines, traditional databases, and blob storage. No custom code. No delays. Just smooth, reliable data flow to the tools that power your AI.
Point. Send. Done.
Multiple destinations, zero extra effort.
Whether it’s production and development databases, blob storage for backups, or specialized vector and graph databases, Unstructured can route your data to multiple destinations in a single workflow. No extra pipelines, no custom code, just seamless, reliable delivery across your entire stack.
Multiple destinations, zero extra effort.
Security, reliability, and compliance baked in.
Built for enterprises from the ground up with organizational accounts, support for role-based access, and fine-grained permissions, our platform It offers deep observability, robust error handling, and built-in compliance support, so teams can move fast without sacrificing control, security, or reliability.
Security, reliability, and compliance baked in.
Set it. Run it. Scale it.
From scheduled workflows to intelligent sync, we automate the entire pipeline. That means you can route documents to the right parsing strategy, skip files you've already processed, and keep everything moving—on time, and on target. No busywork. No bottlenecks. Just efficient, hands-off processing at scale.
Set it. Run it. Scale it.
Interface options for everyone.
Use API for full programmatic control. Use the UI to configure and run pipelines without a single line of code. Or let your AI agents take the wheel via MCP (Model Context Protocol) that connects Unstructured to your autonomous agents. However you work, Unstructured fits right in.
Interface options for everyone.
Built to extend. Ready to scale.
Experience a rich ecosystem of maintained connectors and a modular plugin architecture designed for flexibility. Whether you require an integration with a niche system or need a custom data transformation node, our plugin architecture makes it easy to connect, customize, and keep everything working smoothly at scale.
Built to extend. Ready to scale.
Bare Metal? SaaS? VPC? Yes.
Unstructured fits your infrastructure—not the other way around. Choose fully managed SaaS, hybrid deployments, VPC installs, or even bare metal. Wherever your data lives, Unstructured runs with it—securely, flexibly, and without compromise.
Bare Metal? SaaS? VPC? Yes.

Ready for a demo?
See how Unstructured simplifies data workflows, reduces engineering effort, and scales effortlessly. Get a live demo today.