
Authors

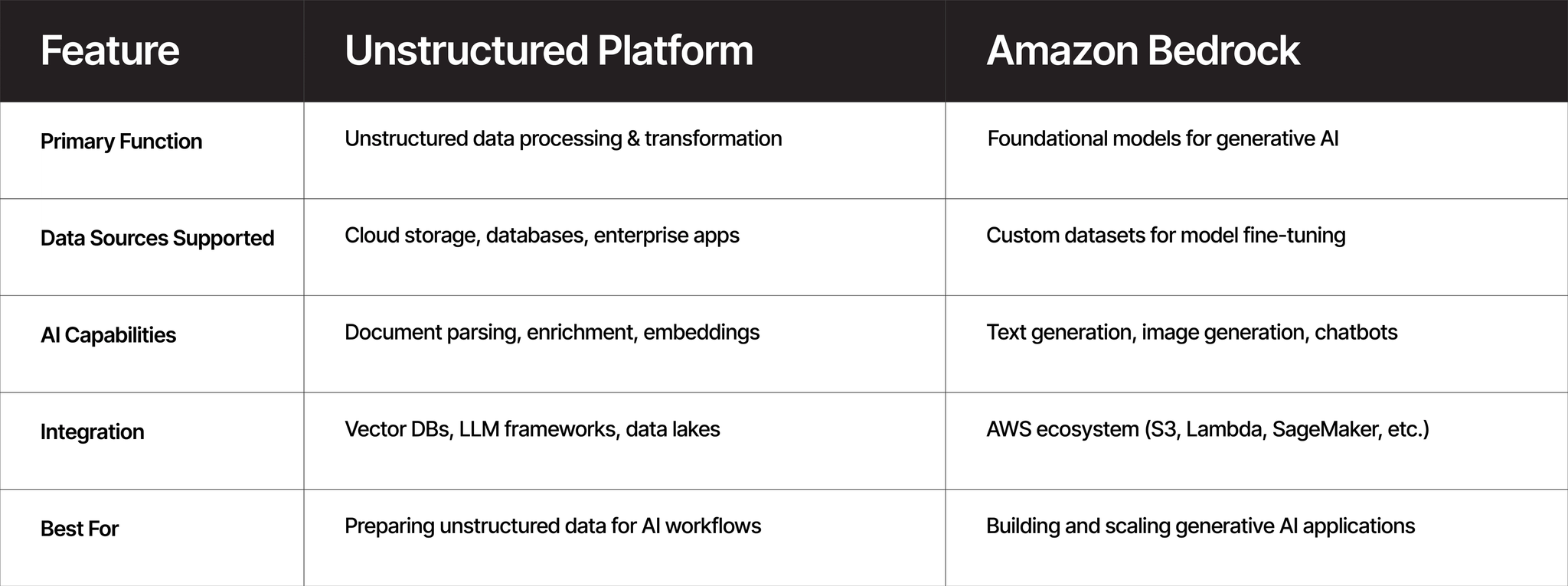
If your primary goal is to prepare unstructured data for AI applications, the Unstructured Platform is the ideal choice. It offers a no-code solution for converting raw documents like PDFs, emails, and scanned files into structured, machine-readable formats, making it perfect for Retrieval-Augmented Generation (RAG) systems and enterprise data pipelines.
Try out the Unstructured Platform today. Learn more here.
What is Unstructured?
The Unstructured Platform is a specialized solution designed for transforming unstructured data—such as PDFs, emails, and scanned documents—into structured, machine-readable formats. It supports various document processing workflows, making it an ideal choice for AI applications, Retrieval-Augmented Generation (RAG) systems, and enterprise data pipelines.
Key Features of Unstructured
- No-Code Data Processing: Enables users to convert raw unstructured data into a structured format without writing custom code.
- Diverse Data Source Support: Connects to cloud storage services (AWS S3, Azure Blob, GCP), databases (Databricks, Elasticsearch, OpenSearch), and enterprise platforms (Salesforce, Google Drive, SharePoint).
- Advanced Partitioning & Chunking: Uses multiple partitioning strategies (Fast, HiRes, Auto) and intelligent chunking methods (By Title, By Page, By Similarity) to optimize content extraction.
- AI-Powered Enrichment: Generates metadata, captions, and embeddings for AI-driven document retrieval and analysis.
- Vector Database Integration: Seamlessly integrates with Pinecone, Weaviate, Chroma, Elasticsearch, OpenSearch, and other storage destinations.
- Scalability for Enterprise AI: Designed to handle high-volume ETL workloads.
Workflow Orchestration Engine
The platform’s orchestration layer manages complex scheduling, automatic retries, and parallel processing of over 53,000 documents per job while maintaining millisecond latency between processing steps. Unlike limited frameworks that focus solely on specific tasks, Unstructured provides end-to-end orchestration capabilities, including:
- Real-time document detection with automated triggering of processing pipelines.
- Intelligent incremental updates that reprocess only modified content.
- Horizontal scaling across multiple data planes in hybrid cloud environments.
- Embedded metadata governance tracking data lineage from source to vector store.
Enterprise Scalability
Performance benchmarks indicate that the hosted SaaS deployment processes over 15 million pages per hour per workflow, with proven scalability to petabytes of unstructured data. For organizations requiring full control, the in-VPC deployment model eliminates data egress costs while providing unlimited scaling based on private infrastructure capacity. This architecture supports multi-region processing with centralized governance, essential for global enterprises managing localized data residency requirements.
Enterprise Integrations
With over 71 pre-built connectors spanning storage systems, LLM providers, and vector databases, Unstructured Platform acts as the central nervous system for GenAI data pipelines. Current production integrations include direct access to OpenAI and Anthropic models for embeddings and enrichment, with expanded model support scheduled for Q2 2025. The platform’s API-first design allows custom integration with any third-party service while maintaining SOC 2 Type 2 compliance across all data flows.
Read more about how Unstructured can help you do Production-Ready data processing for GenAI here.
What is Amazon Bedrock?
Amazon Bedrock is a fully managed service by AWS that provides access to foundational models (FMs) from leading AI companies, such as Anthropic, Stability AI, and AI21 Labs. It enables developers to build and scale generative AI applications by offering pre-trained models for tasks like text generation, image generation, and conversational AI.
Key Features of Amazon Bedrock
- Foundational Models: Provides access to state-of-the-art models like Claude (Anthropic), Jurassic-2 (AI21 Labs), and Stable Diffusion (Stability AI).
- Custom Model Fine-Tuning: Allows users to fine-tune foundational models using their own data for domain-specific applications.
- Serverless Architecture: Fully managed service that eliminates the need for infrastructure management.
- Integration with AWS Ecosystem: Seamlessly integrates with other AWS services like S3, Lambda, and SageMaker.
- Scalability: Designed to handle large-scale generative AI workloads with ease.
Unstructured vs. Amazon Bedrock: A Feature Comparison
Choosing the Right Data Processing Tool for Your Use Case
While Amazon Bedrock provides powerful foundational models for building generative AI applications, the Unstructured Platform is purpose-built for transforming raw documents into structured, AI-ready data. For organizations deploying GenAI at scale, Unstructured provides critical infrastructure that foundation models like the ones available on Amazon BedRock rely upon for accessing enterprise knowledge.
Key differentiators include:
- Comprehensive ETL vs. Limited Processing: While foundation models focus on narrow transformation steps, Unstructured manages the entire pipeline including credential rotation, error handling, and compliance auditing.
- Enterprise-Grade Security: With in-VPC processing and zero-data retention policies, Unstructured meets strict regulatory requirements that general AI models cannot address.
- Model Agnosticism: Direct integration with leading LLMs (OpenAI, Anthropic) today, with flexible architecture to incorporate new models as they emerge.
At Unstructured, we're committed to simplifying the process of preparing unstructured data for AI applications. Our platform empowers you to transform raw, complex data into structured, machine-readable formats, enabling seamless integration with your AI ecosystem. To experience the benefits of Unstructured firsthand, get started today and let us help you unleash the full potential of your unstructured data.
Title

Unstructured

Unstructured

Unstructured