Authors

Advanced Document Understanding
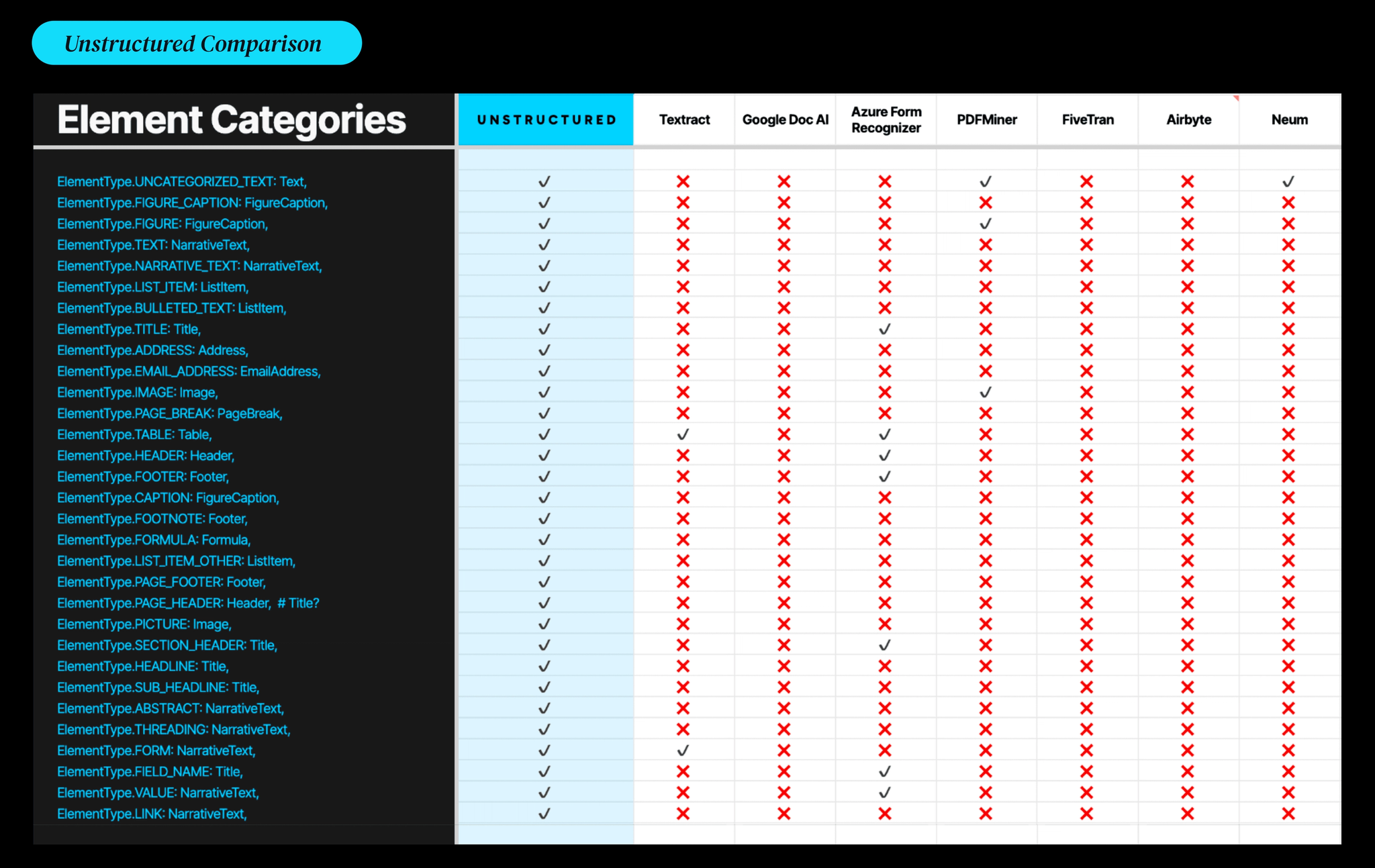
Decomposing a document into smaller chunks is an essential process in RAG.Over the past year most RAG architectures have utilized simpler techniques such as chunking by token size, which is a suboptimal strategy for grouping relevant contextual information. Unstructured’s preprocessing pipelines offer new options to chunk by document element (e.g. title-to-title) to ensure that chunks include only the data that should be considered for retrieval and generation by LLMs and nothing more, suggesting that the element based method demonstrates broader applicability and adaptability to novel document types.
The Need for Advanced Document Understanding
The effectiveness of RAG architectures are closely tied to how well models can retrieve information relevant to a prompt, that is stored in an external database. As RAG has become more widely adopted over the past year, developers typically have treated documents as a stream of text, and not accounted for the nuanced relationships between different types of elements such as titles, tables, and body text. We have found, however, that the performance of these architectures on information retrieval and Q&A generation with more sophisticated document preprocessing.
Unstructured's Approach: Chunking by document element
Unstructured's pipelines decompose documents into discrete structural “document elements'' by leveraging both computer vision and natural language processing pipelines to identify and categorize document elements based on their semantic relationships and structural importance. By doing so, Unstructured aims to enhance the retrieval process, ensuring that the information fed into RAG systems is both relevant and contextually rich.
Performance Improvements
This Winter, researchers at Unstructured sought to evaluate the extent to which preprocessing data based on document elements could enhance information retrieval and Q&A tasks in a RAG architecture. The evaluation utilized the FinanceBench dataset, which contains questions and answers for a set of US SEC financial reporting documents. These documents vary in structural complexities and necessitate reasoning for accurate answers. Different chunking strategies, serving as the baseline, chunk documents into blocks of a specified token size. From the processing strategies developed by Unstructured, Chipper was employed. Chipper, a proprietary vision encoder-decoder model, has been pre trained on a vast array of documents. It effectively identifies diverse elements on a document page and transcribes tables into HTML.
The elements derived from using the Chipper model have been used in the development of the chunking by element(title-to-title) strategy. RAG systems are made of several components, which include the retrieval of chunks relevant to a question and the generation of an answer based on the retrieved chunks. Retrieval is based on the Weaviate vector database and GPT-4 was used for the answer generation.
Implementing chunking based on document elements delivered significant performance improvements for information retrieval tasks. Figure 1 below shows retrieval results. For each chunking strategy, we show the number of chunks for all the documents (Total Chunks), Page Accuracy, and ROUGE and BLEU scores, which are standard metrics in natural language understanding. ROUGE and BLEU are calculated as the maximum score from the list of recovered contexts for a question when compared to the known evidence for that question. Unstructured smart chunking methods proved to be more generalizable and can be applied to new types of documents. Basic chunking strategies lack consistency between page-level and paragraph-level accuracy. We also discovered that when various chunking strategies are combined, it results in enhanced retrieval scores, achieving superior performance.
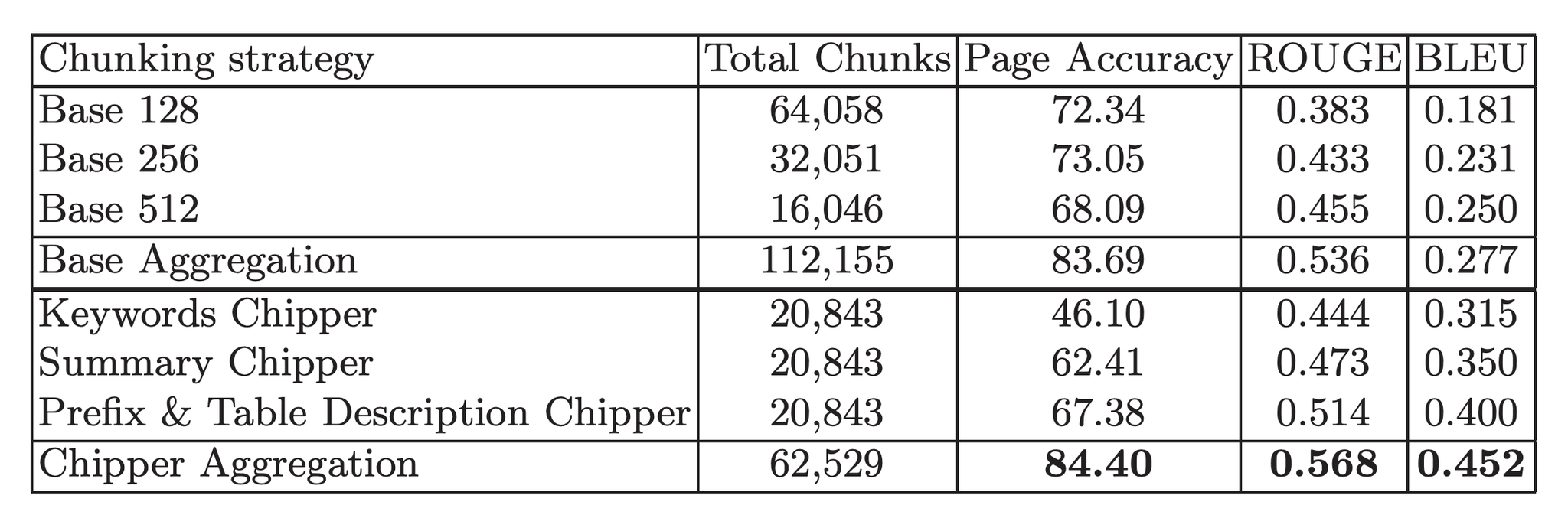
Figure 1. Retrieval evaluation results
Figure 2 below shows the questions and answering (Q&A) results. We show the percentage of questions with no answer and as well the accuracy either estimated automatically using GPT-4 (which supports automating the evaluation) or manually. Compared to the baseline approach, and considering the improvement in retrieval, the generated answers using Unstructured smart chunking strategy largely improves the chunking methods without document element understanding.
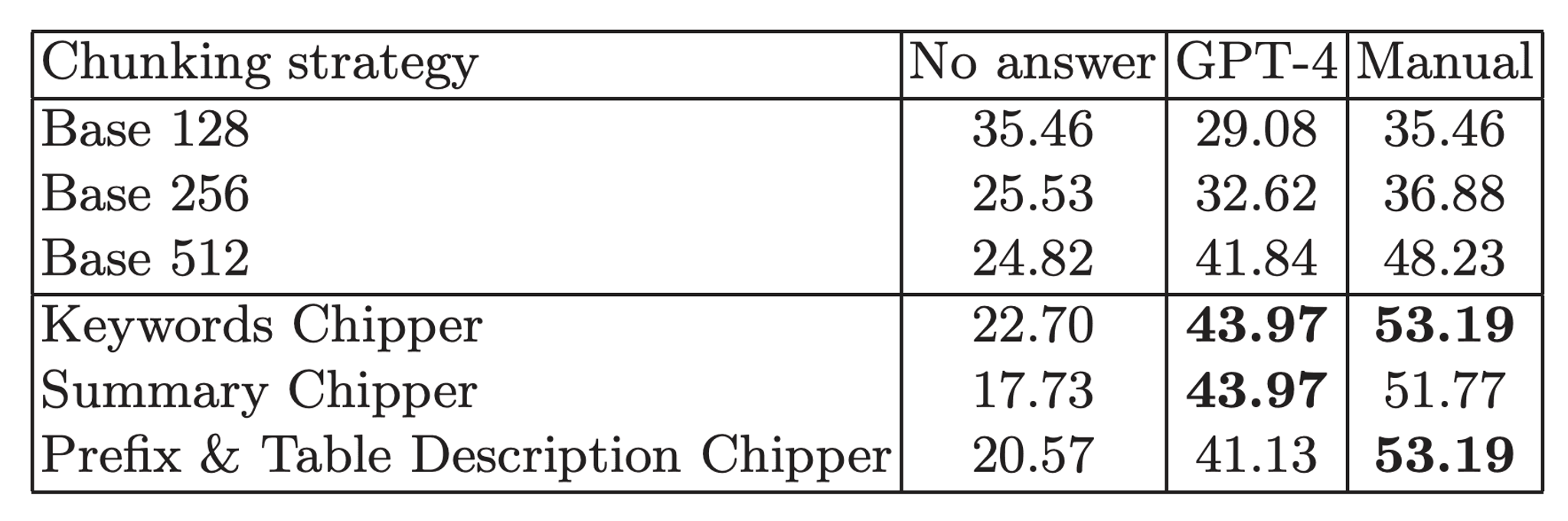
Figure 2. Answer generation results
We demonstrate double digit performance gains, simply from using our technology to ingest unstructured documents. Connect our API or Platform to your data sources and realize these gains today.
Check out our synopsis below or read the full paper on Financial Report Chunking for Effective Retrieval Augmented Generation.
Method
Our method relies on the structural information that is present in the document’s layout to adjust the chunk size automatically. Our technology assesses documents at a granular level, identifying and annotating various elements such as tables, titles, and paragraphs. This allows for a more detailed examination of how these elements contribute to the overall meaning and context of the document. Examples of the benefit of our technology for RAG include awareness of the elements that appear in a document and a better understanding of tables, which ensures that tables are not split, that relevant information about the table is preserved and that the structure of the table is provided to the answer generator. The information provided by our document processing strategies improves the accuracy and relevance of the content for RAG processes.
Future Directions
Unstructured continues to develop and refine our chunk by element approach with the goal of extending its benefits to a wider range of applications beyond financial reporting. Our focus remains on improving the way RAG systems understand and interact with unstructured data, paving the way for more accurate and efficient question-answering capabilities across various domains.
Conclusion
Unstructured's chunk by element(title-to-title) approach represents an easy way to significantly boost the performance of RAG architectures. By providing an easy way to capture document structures and their semantic relations across a range of file types, Unstructured’s preprocessing pipelines improves the accuracy and efficiency of information retrieval and generation processes. Chunk by element (title-to-title) is only available with Unstructured in our API and Platform products.